Click the “Computer Vision Life” above and select “Star”
Quickly get the latest insights
This article is reproduced from Machine Heart
Researchers state that they view edge training as an optimization problem, thus discovering the optimal scheduling to achieve minimal energy consumption given a memory budget.
Currently, deep learning models are widely deployed for inference on edge devices such as smartphones and embedded platforms. Training, however, is still predominantly done on large cloud servers with high-throughput accelerators like GPUs. Centralized cloud training requires the transfer of sensitive data such as photos and keystrokes from edge devices to the cloud, sacrificing user privacy and incurring additional data movement costs.
Figure Caption: Twitter @Shishir Patil
Therefore, to allow users to personalize their models without sacrificing privacy, device-based training methods like federated learning do not require data to be aggregated in the cloud and can perform local training updates. These methods have been deployed on Google’s Gboard keyboard for personalized suggestions and are also used by iPhones to enhance automatic speech recognition. However, current device-based training methods do not support training modern architectures and large models. Training larger models on edge devices is impractical mainly due to limited device memory, which cannot store backpropagation activations. The memory required for a single training iteration of ResNet-50 is over 200 times that of inference.
Previous work proposed strategies such as paging to auxiliary memory and reimplementation to reduce memory usage during cloud training. However, these methods significantly increase overall energy consumption. The data transfer associated with paging typically requires more energy than the computation of the data. As the memory budget shrinks, reimplementation increases energy consumption at a rate of O(n^2).
In a recent paper from UC Berkeley, several researchers demonstrated that paging and reimplementation are highly complementary. By reimplementing simple operations while paging the results of complex operations to auxiliary storage such as flash memory or SD cards, they were able to effectively expand memory capacity with minimal energy consumption. Moreover, through the combination of these two methods, the researchers also proved that training models like BERT on mobile-grade edge devices is possible. By viewing edge training as an optimization problem, they discovered the optimal scheduling for achieving minimal energy consumption given a memory budget.
-
Paper link: https://arxiv.org/pdf/2207.07697.pdf
-
Project homepage: https://poet.cs.berkeley.edu/
-
GitHub link: https://github.com/shishirpatil/poet
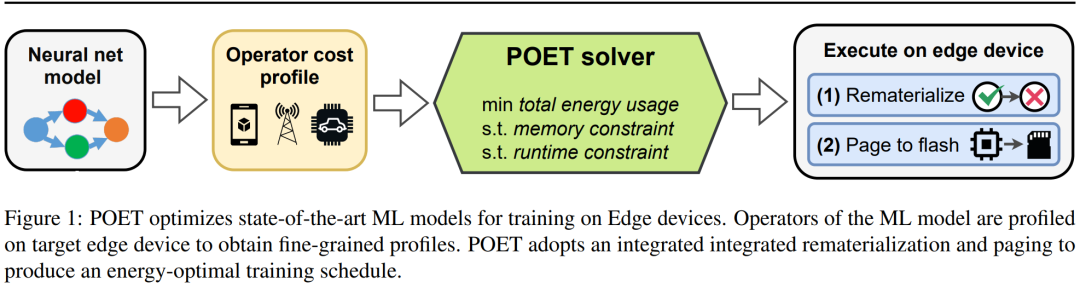
The researchers proposed POET (Private Optimal Energy Training), an algorithm for energy-optimal training of modern neural networks on memory-constrained edge devices, as illustrated in the following Figure 1. Given the high cost of caching all activation tensors for backpropagation, POET optimizes paging and reimplementation of activations, thus potentially reducing the highest memory consumption by two times. They reformulated the edge training problem as an Integer Linear Programming (ILP) problem, finding that it could be solved to optimality within 10 minutes using a solver.
Figure Caption: POET optimizes the training of SOTA machine learning models on edge devices.
For models deployed on real-world edge devices, training occurs when the edge device is idle and can compute cycles, for example, Google Gboard schedules model updates while the phone is charging. Therefore, POET also includes strict training constraints. Given memory limits and the number of training epochs, the solutions generated by POET can also meet specified training deadlines. Additionally, the researchers developed a comprehensive cost model using POET, demonstrating that it is mathematically sound (i.e., not approximated) and applicable to existing out-of-the-box architectures.
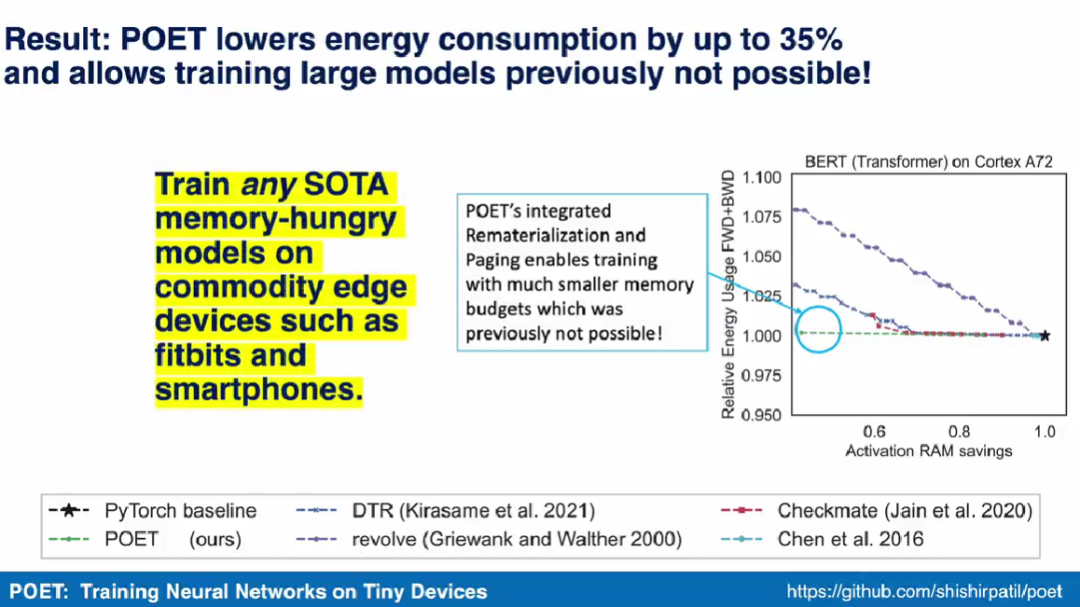
Lead author Shishir Patil stated in a demonstration video that the POET algorithm can train any SOTA model requiring significant memory on commercial edge devices such as smartphones.They also became the first research team to demonstrate the training of SOTA machine learning models like BERT and ResNet on smartphones and ARM Cortex-M devices.
Integrating Paging and Reimplementation
Reimplementation and paging are two techniques for reducing the memory consumption of large SOTA ML models. In reimplementation, once activation tensors are no longer needed, they are deleted, most commonly during forward propagation. This releases valuable memory for storing activations of subsequent layers. When the deleted tensors are needed again, this method will recompute them based on the lineage’s specifications. Paging, also known as offloading, is a complementary technique for reducing memory. In paging, activation tensors that are not immediately needed are moved from main memory to secondary storage, such as flash memory or SD cards. When the tensors are needed again, they are paged back in.
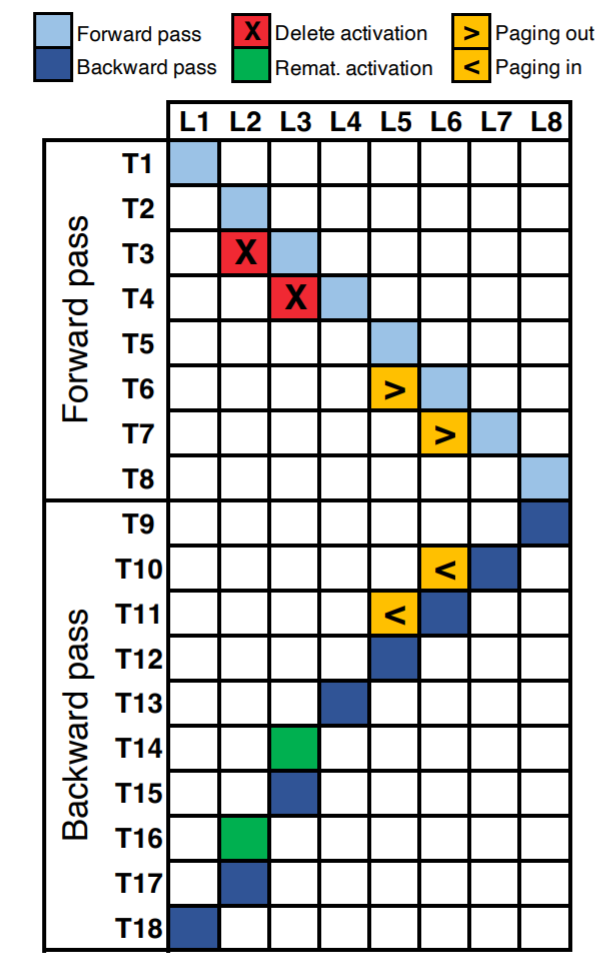
Figure 2 shows the execution timeline of an eight-layer neural network. Along the X-axis, each unit corresponds to each layer of the neural network (a total of 8 layers L8). The Y-axis represents the logical time steps within an epoch. The occupied units in the figure (filled with color) indicate the operations performed at the respective time steps (forward/backward propagation computations, reimplementation, or paging).
For example, we can see that the activation for L1 is computed at the first time step (T1). At T2 and T3, the activations for L2 and L3 are computed, respectively. Assuming layers L2 and L3 are memory-intensive but computationally inexpensive operations, such as nonlinear (tanH, ReLU, etc.), then reimplementation becomes the optimal choice. We can delete the activations ({T3, L2}, {T4, L3}) to free up memory, and when these activations are needed during backpropagation, we can recompute them ({T14, L3}, {T16, L2}).
Assuming layers L5 and L6 are computationally intensive operations, such as convolutions or dense matrix multiplications. For such operations, reimplementation will lead to increased runtime and energy, making it a suboptimal approach. For these layers, it is better to page the activation tensors to auxiliary storage ({T6, L5}, {T7, L6}) and page them back when needed ({T10, L6}, {T11, L5}).
A major advantage of paging is that it can enable pipelining based on memory bus occupancy to hide latency. This is because modern systems have DMA (Direct Memory Access) features that can move activation tensors from auxiliary storage to main memory while the compute engine runs in parallel. For example, at time step T7, L6 can be paged out while L7 is computed simultaneously. However, reimplementation is computationally intensive and cannot be parallelized, leading to increased runtime. For instance, we must allocate time step T14 for recomputing L3, thus delaying the execution of the remaining backward propagation.
The study proposes POET, a graph-level compiler for deep neural networks that rewrites the training DAG of large models to fit the memory constraints of edge devices while maintaining high energy efficiency.
POET is hardware-aware; it first tracks the execution of forward and backward propagation along with related memory allocation requests, runtimes, and the memory and energy consumption of each operation. This fine-grained analysis occurs only once for each workload on a given hardware, providing automation and cost-effectiveness, and thus offering the most accurate cost model for POET. POET then generates a Mixed Integer Linear Programming (MILP) problem that can be efficiently solved.
POET optimizer searches for effective reimplementation and paging schedules to minimize end-to-end energy consumption under memory constraints. The resulting schedules generate a new DAG for execution on edge devices.
Although the MILP is solved on commercial hardware, the scheduling table sent to edge devices is only a few hundred bytes, making it highly memory-efficient.
For operations that are low in computation cost but high in memory consumption, reimplementation is the most effective. However, paging is best suited for computation-intensive operations, where reimplementation would lead to significant energy overhead. POET jointly considers reimplementation and paging in an integrated search space.
The methods in this paper are scalable to complex, realistic architectures, as shown in the POET optimizer algorithm.
The study introduces a new objective function in the optimization problem to minimize the combined energy consumption of computation, page-in, and page-out, with the new objective function combining paging and reimplementation energy consumption as follows:
Where Φ_compute, Φ_pagein, and Φ_pageout represent the energy consumed by each node during computation, page-in, and page-out, respectively.
POET determines which nodes (k) are reimplemented based on the graph and which nodes are paged in at each time step (t) to produce the DAG schedule.
In the evaluation of POET, the researchers sought to answer three key questions. First, how much energy can POET reduce across different models and platforms? Second, how does POET benefit from the hybrid paging and reimplementation strategy? Finally, how does POET adapt to different runtime budgets?
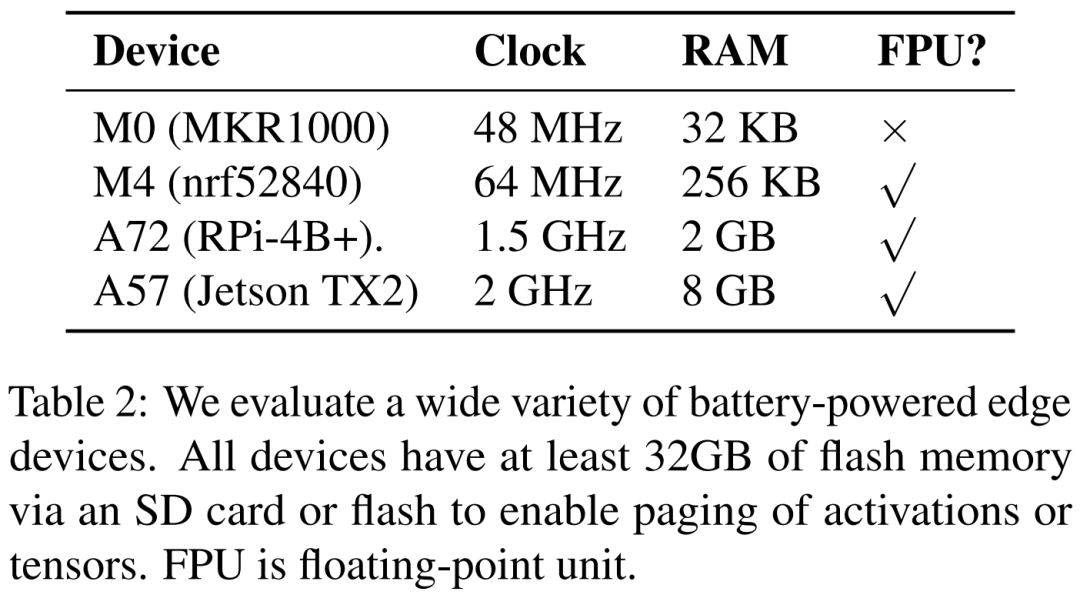
The researchers listed four different hardware devices in Table 2: ARM Cortex M0 MKR1000, ARM Cortex M4F nrf52840, A72 Raspberry Pi 4B+, and Nvidia Jetson TX2. POET is fully hardware-aware and relies on fine-grained analysis.
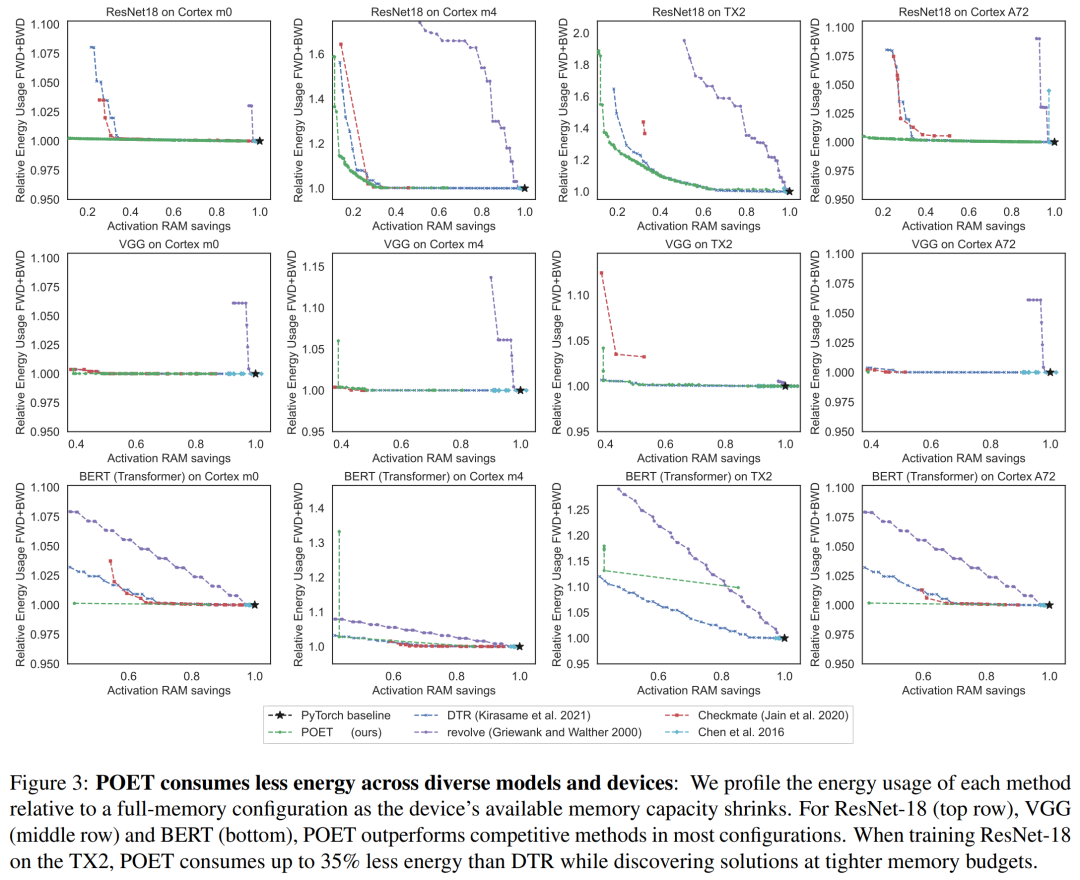
Figure 3 shows the energy consumption for a single training epoch, with each column corresponding to a different hardware platform. The researchers found that POET generates energy-optimal schedules (Y-axis) across all platforms while reducing peak memory consumption (X-axis) and meeting time budgets.
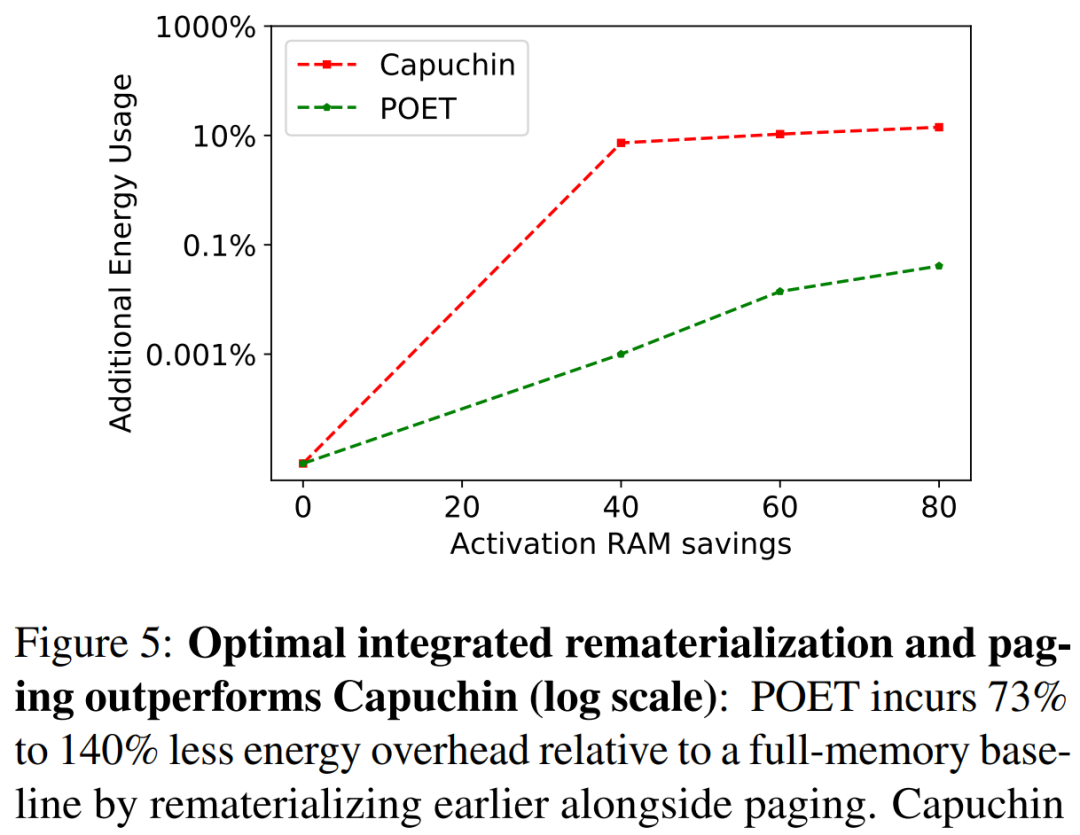
In Figure 5, the researchers benchmarked POET and Capuchin while training ResNet-18 on A72. As the RAM budget decreased, Capuchin consumed 73% to 141% more energy compared to the baseline with full memory. In contrast, the energy consumption generated by POET was less than 1%. This trend applies to all architectures and platforms tested.
In Table 3, the study benchmarked POET and POFO while training ResNet-18 on Nvidia’s Jetson TX2. The researchers found that POET discovered an integrated reimplementation and paging schedule that reduced peak memory consumption by 8.3% and increased throughput by 13%. This showcases the advantages of POET’s MILP solver, which optimizes across a larger search space. While POFO only supports linear models, POET can be extended to nonlinear models, as shown in Figure 3.
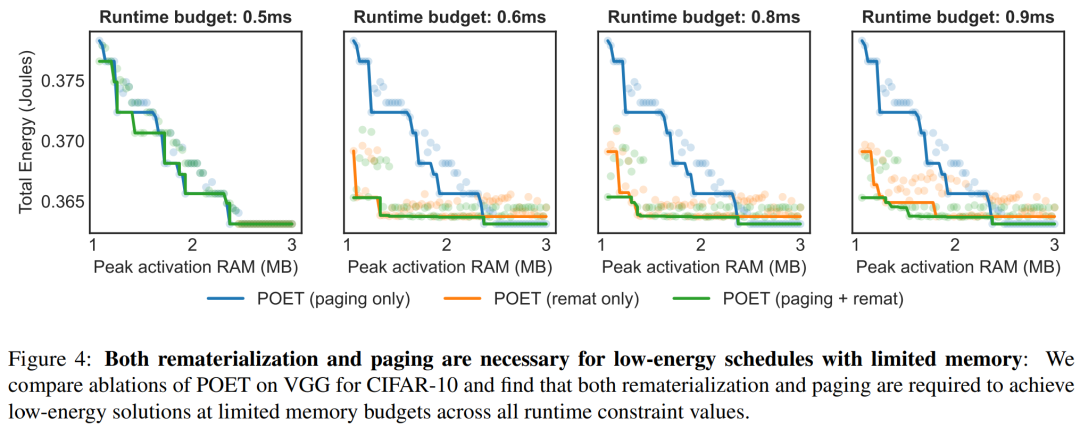
Figure 4 emphasizes the benefits of the integrated strategy adopted by POET under different time constraints. For each runtime, the total energy consumption is plotted in the figure below.
This article is for academic sharing only. If there is any infringement, please contact us for deletion.
Exclusive heavyweight course official website:cvlife.net

The largest national robot SLAM developer community

Technical exchange group

— Copyright Statement —
The original content copyright of this public account belongs to Computer Vision Life; non-original text, images, and audio-visual materials collected, sorted, and authorized for reproduction from public channels belong to the original authors. If there is any infringement, please contact us, and we will delete it promptly.