

Today, we are reading the 2019 paper by Google titled “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations”.
We know that the model’s performance improves with increased depth, but deeper models also make training more difficult. To address this issue, Google has proposed a lightweight BERT: ALBERT, which has fewer parameters than BERT-large and performs better.
1. Introduction
Generally, model depth is proportional to model performance, but deeper models can lead to hundreds of millions or even billions of parameters, which imposes certain requirements on computational memory. In distributed training, communication overhead is also proportional to the number of parameters, significantly impacting training speed.
The existing solutions either parallelize or manage memory, but they do not address communication overhead, which is to reduce the parameters of the model itself.
In this paper, the authors design a lightweight BERT and name it ALBERT (A Lite BERT), which has significantly fewer parameters than traditional BERT, effectively addressing the communication overhead of the model.
ALBERT introduces two techniques to reduce parameters: factorized embedding parameterization and cross-layer parameter sharing. The former decomposes the embedding parameter matrix into two smaller matrices, while the latter shares parameters across layers.
In addition to reducing parameters, to improve performance, the authors also introduce a self-supervised sentence prediction objective (sentence-order prediction, SOP) that focuses on the coherence between sentences, aiming to address the inefficacy of next sentence prediction (NSP) in BERT.
Ultimately, ALBERT has fewer parameters than BERT-large, performs better, and has achieved top rankings on multiple NLP tasks.
2. ALBERT
The backbone architecture of ALBERT is similar to BERT, both using the GELU-based nonlinear activation function of the Transformer. However, it reduces the number of parameters in two places.
As shown in the figure below, the model’s parameters are mainly concentrated in two blocks: the Token embedding projection block and the Attention feed-forward block, with the former accounting for 20% of the parameters and the latter accounting for 80%.

2.1 Factorized Embedding Parameterization
Let’s first look at the Token embedding projection module.
In BERT, the size of the Token Embedding parameter matrix is , where V represents the vocabulary length and H is the hidden layer size. That is:
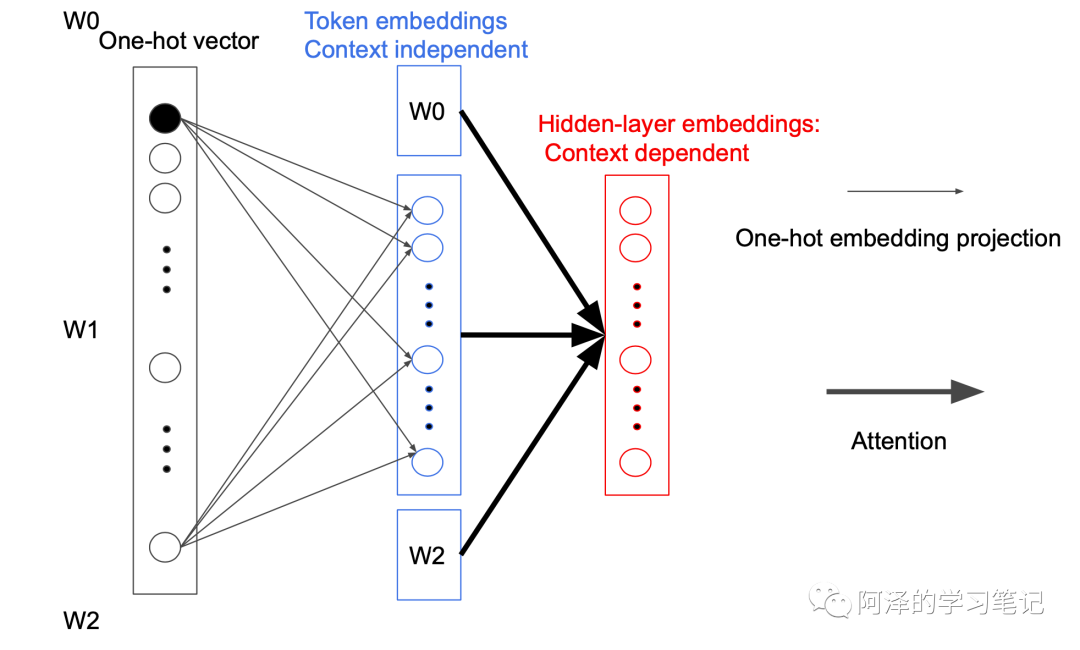
ALBERT reduces the number of parameters by adding a hidden layer of size E in the mapping, thus reducing the parameter size from to , where $E<<h$.
This is possible because during each backpropagation, only one Token-related parameter is updated, while others remain unchanged. Moreover, during the first projection, words do not interact with each other; only during the subsequent Attention process do they interact, which we call Sparsely updated. If words do not interact, there is no need to use a high-dimensional vector for representation, thus a smaller hidden layer is introduced. (This process is somewhat akin to matrix decomposition.)
This completes the first module for reducing parameters.
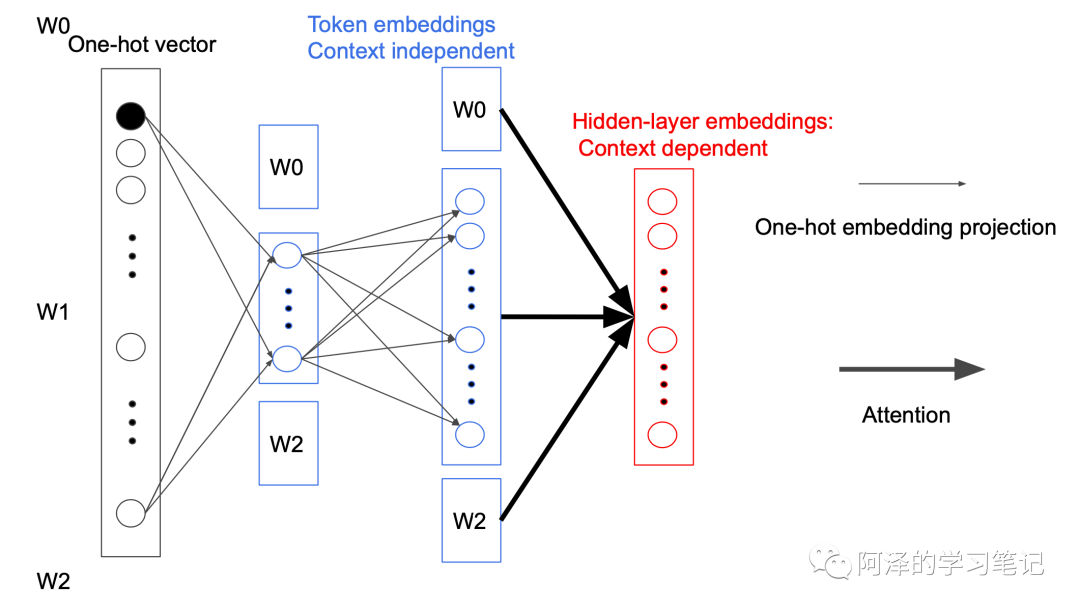
2.2 Cross-Layer Parameter Sharing
The parameter sharing in ALBERT mainly occurs within all sub-modules, thus reducing the parameter count of the Attention feed-forward module from to , where L is the number of layers and H is the hidden layer size.
ALBERT does this because, considering that each layer learns very similar content, it attempts to share parameters. The following figure illustrates what different layers of Attention learn:

This completes the second module for reducing parameters.
2.3 Sentence Order Prediction
BERT designed NSP to ensure the continuity of sentences, using two consecutive sentence pairs as positive examples and randomly selecting one sentence as a negative example. However, this raises an issue: sentences not only have continuity but also themes, and if randomly selected, the model may determine a negative example based on differing themes.
Thus, the authors improved this by proposing Sentence Order Prediction (SOP), which simply swaps the order of the sentences being predicted: sentence1 predicts sentence2 as a positive example, while sentence2 predicts sentence1 as a negative example, eliminating concerns about theme-based predictions.
3. Experiments
Let’s take a brief look at the experiments.
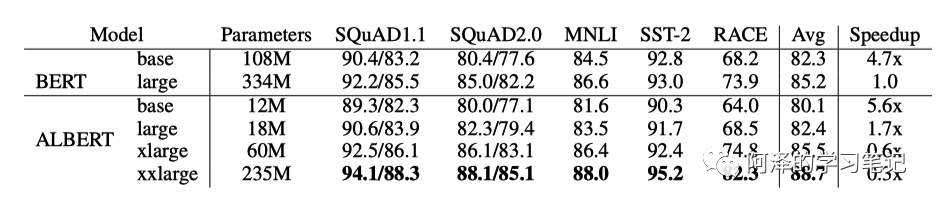
The following figure compares the parameters of BERT and ALBERT:

The next figure compares the parameters, accuracy, and speed of the models, showing that while the parameters have decreased, the speed has significantly dropped.
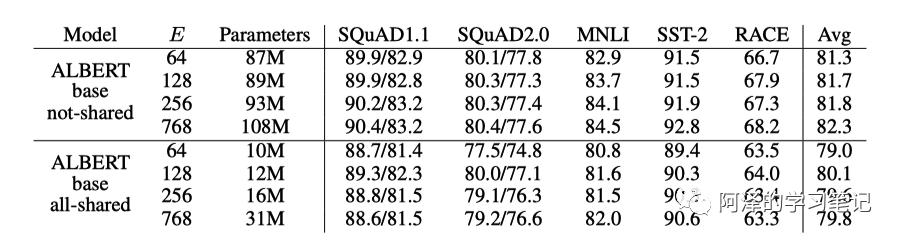
The following figure compares the accuracy and parameter size under shared parameters:
The following figure shows the improvement of SOP over NSP:

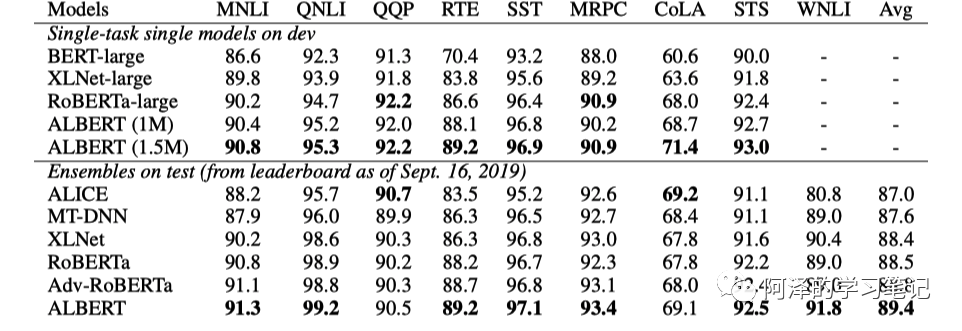
The next figure shows ALBERT’s ranking results:
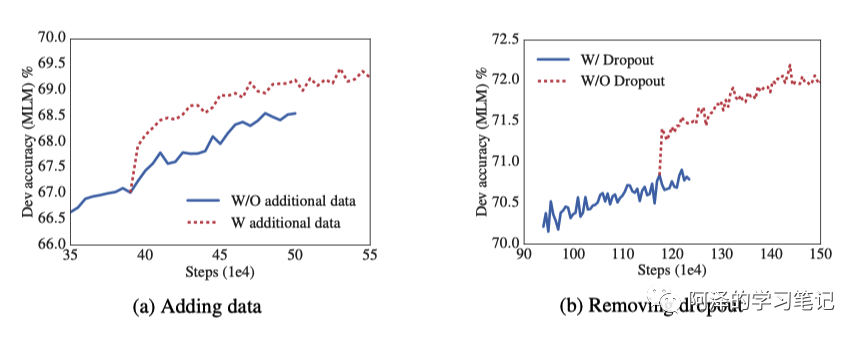
The following figure shows the accuracy before and after removing dropout. To explain: dropout is very effective in preventing overfitting, but for the Masked Language Model, learning is inherently difficult, so there is no need to worry about overfitting):

Additionally, adding dropout increases many temporary variables, while removing dropout improves memory utilization. Furthermore, ALBERT also added ten times the amount of data = = :
4. Conclusion
In summary: ALBERT designed two methods, factorized embedding parameterization and cross-layer parameter sharing, to reduce parameters in two parts of the model, and utilized sentence order prediction to improve BERT’s NSP. By designing a deeper network, removing dropout, and training on a tenfold dataset, ALBERT has achieved top rankings on multiple NLP tasks, but due to its larger structure, the computational cost is high, so its training speed has decreased.
ALBERT is more like an engineering optimization with some small tricks, making it seem unexpectedly simple. Although it reduces memory usage, the computational load has increased, and those who can’t afford it still can’t afford it.
5. Reference
-
“ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations” -
“ALBERT: A Lite BERT for Language Understanding”.ppt——Lan Zhenzhong
Important! The WeChat group for PyTorch natural language processing has been established,
to facilitate everyone in sharing PyTorch experience.
You can scan the QR code below to join the group for discussions.
Note: Please modify your remarks when adding, to include [School/Company + Name + Direction]
For example — HIT + Zhang San + Dialogue System.
Please avoid adding if you are a micro-business. Thank you!

Recommended Reading:
【Detailed Explanation】From Transformer to BERT Model
Sail Translation | Understanding Transformer from Scratch
Better than a thousand words! A step-by-step guide to building a Transformer with Python