Wishing You a Prosperous Year of the Rat
HAPPY 2020’S NEW YEAR
Author:Tea Book Club of Lao Song
Zhihu Column:NLP and Deep Learning
Research Direction:Natural Language Processing
Source:AINLP
Introduction
BERT has achieved great success in the field of natural language understanding, but it performs poorly in natural language generation due to the language model used during its training.
The DAE language model of BERT only learns the ability to represent the context of words, which is the ability to understand language, but it does not learn how to organize language. This can be referred to in the introduction of AR and AE mentioned in the preface of XLNet. If we want to apply BERT to the generation field, then the design of the Decoder is a significant challenge.
Recently, two papers from Microsoft have made attempts in this area and have achieved good results, which are worth referencing. At the same time, considering the previous GPT and GPT 2.0 regarding the generation part, they will be discussed together.
From the Perspective of Neuroscience
In neuroscience, the language center controls human language activities, among which the most important are the Broca’s area and the Wernicke’s area. Interestingly, the functions of both have similarities with the current development of our language models:
-
Broca’s area is primarily responsible for our ability to organize language, which is natural language generation.
-
Wernicke’s area is responsible for our ability to understand language, which is natural language understanding.
From this perspective, for classification problems, we only need understanding ability (Wernicke’s area), but for dialogue problems, we need both (Broca’s area). In text dialogue, language is first transformed into some neural signals through the visual cortex and sent to the Wernicke’s area for understanding, then the understood information is transmitted via the arcuate fasciculus to the Broca’s area to organize language and generate dialogue.
From the progress of BERT and XLNet in reading comprehension problems, it can be seen that pre-trained language models are quite effective for understanding issues, and I believe there will be greater breakthroughs in this area.
As for generation problems, the idea of training language models with large-scale data is also quite reliable, which requires a well-designed language model.
From the process of text dialogue, the connection between understanding and generation still needs to be explored. Perhaps using BERT as an Encoder and a corresponding AR language model as a Decoder, followed by pre-training, can solve this problem.
However, a key question is: Do the neurons activated by classification problems and generation problems have the same parts? If there are common parts, it seems that multi-task learning is more suitable; if not, then separately implementing generative and classification pre-trained language models seems more appropriate. Since I am not very familiar with multi-task learning, I am unsure whether it can improve the performance of multiple tasks. If there are experts in this area, please explain.
Of course, I am not an expert, and I do not dare to instruct, I can only suggest some ideas. Without further ado, let’s see how the following articles are done.
GPT 1.0
GPT 1.0 actually did not involve the generation part, but considering that GPT 2.0 is an extension of it, I will touch on the details of GPT 1.0 here, with specific discussions reserved for GPT 2.0.
Overall, GPT 1.0 is quite similar to BERT, also serving as a two-stage model, but may differ significantly in details.
1. Language Model
For the given tokens  , the objective function of GPT 1.0’s language model is as follows:
, the objective function of GPT 1.0’s language model is as follows:

From the above equation, it can be seen that GPT 1.0 has the ability to generate sentences, but unfortunately, GPT 1.0 did not conduct experiments regarding generation.
2. Unidirectional Transformer
GPT 1.0 uses a unidirectional Transformer as a feature extractor, which is determined by the nature of the language model, as it generates words from front to back.
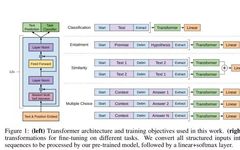
3. Fine-tuning
There is not much to say about the fine-tuning stage; it is just that, so I won’t discuss it in detail.
GPT 2.0
1. Language Model and Unidirectional Transformer
The language model of GPT 2.0 is very similar to that of GPT 1.0, with minimal changes, such as the transfer and addition of Layer Normalization, and this part is not the main innovation point of the article, so I will skip it.
2. The Bigger, The Better
Compared to 1.0, GPT 2.0 has made significant changes in terms of data, mainly including the following aspects:
-
Large-scale, high-quality, cross-domain data: WebText
-
Deeper Transformer model
GPT 2.0 validated the importance of data; even approaching it purely from a data perspective can yield significant improvements.
3. How to Adapt to Downstream Tasks
For downstream tasks, GPT 2.0 no longer uses fine-tuning, but instead directly employs the trained language model. So how can it perform classification, translation, and text summarization?
The answer is quite clever: while performing downstream tasks, GPT 2.0 adds some guiding characters to predict the target, and its output, like the language model, is a single word.
So how does GPT 2.0 perform generative tasks? It continuously predicts, predicting n times (set), and then concatenates these n tokens, taking several sentences from them as the generated text.
4. A Shift in Thinking
Compared to GPT 1.0, the most significant shift in thinking for GPT 2.0 is that it still follows a two-stage framework, but for downstream tasks, it no longer uses supervised fine-tuning but adopts an unsupervised approach directly.
The author believes that through large models and large-scale data, GPT 2.0 can learn a lot of general knowledge and can directly apply this general knowledge to downstream tasks to achieve good results. This essentially proves the correctness of the path of pre-trained language models, as they can indeed learn a lot of information about language and possess strong generalization capabilities.
However, is fine-tuning really unnecessary? I believe that the development of pre-trained language models in the coming period will still follow a two-stage or three-stage framework: pre-trained language model + [multi-task learning] + [pre-training on specific datasets] + downstream task fine-tuning.
It is undeniable that GPT 2.0 has also opened a new line of thinking: If one day the model is large enough and the data is abundant, do we still need fine-tuning?
MASS
I personally feel that the MASS paper has significant pioneering meaning in pre-trained language models + natural language generation. Of course, it cannot be compared to BERT, but it is not without recognition; after all, Google does know how to promote.
MASS adopts an Encoder-Decoder framework to learn text generation, with both the Encoder and Decoder parts using Transformers as feature extractors. Let’s take a closer look at how it does this.
1. Language Model Thinking

The idea of MASS is simple: for the input sequence x, mask the tokens from position u to v, denoted as  . Correspondingly, the token segment from position u to v is denoted as
. Correspondingly, the token segment from position u to v is denoted as  . k = v – u + 1 indicates the size of the masked window, representing how many tokens in a sentence are masked. For the language model of MASS, its input is the masked sequence
. k = v – u + 1 indicates the size of the masked window, representing how many tokens in a sentence are masked. For the language model of MASS, its input is the masked sequence  , and the output is the masked sequence
, and the output is the masked sequence  .
.
At the same time, MASS incorporates the Seq2Seq idea, allowing it to predict consecutive words simultaneously, which suggests that its generative performance should be better than BERT’s. The loss function of MASS is:

2. MASS and BERT
As mentioned earlier, an important parameter k in MASS determines how many tokens will be masked in the input sequence x. In contrast, BERT masks 15% of tokens (did MASS 3.2 make a mistake? It does not mask just one token). Additionally, BERT performs random masking, while MASS masks continuous tokens.
The original paper on MASS discusses BERT, suggesting that BERT masks only one token in a sentence, and thus it makes a comparison:

However, BERT actually masks 15% of tokens in a sentence. Am I misunderstanding something?
I have always been puzzled as to why BERT does not mask just one token like Word2Vec; wouldn’t that better capture contextual information? Could someone please clarify?
3. MASS vs GPT
When k = m, it is exactly the same as the situation with GPT.
4. Why MASS is Suitable for Generation
First, predicting masked tokens through the Seq2Seq framework allows the Encoder to learn information from the unmasked tokens, while the Decoder learns how to extract meaningful information from the Encoder.
Then, compared to predicting discrete tokens, the Decoder can establish better language generation capabilities by predicting continuous tokens.
Finally, by matching the input and output masks, the Decoder can extract meaningful information from the Encoder rather than relying on previous information (which is essentially a useful redundancy).
MASS Summary
In summary, MASS has the following points:
-
Introduced Seq2Seq to train the pre-trained model.
-
Masked continuous tokens instead of discrete masks, which helps the model’s language generation capability.
-
The Encoder masks the sequence, while the Decoder corresponds to the masked tokens.
UNILM
UNILM is impressive; it aims to train a pre-trained language model that can perform both natural language understanding and natural language generation. The basic unit of UNILM is still a multi-layer Transformer, but unlike others, these Transformer networks are pre-trained on multiple language models: unidirectional LM, bidirectional LM, and Seq2Seq LM. I will skip some details and focus mainly on how to pre-train the language model.
The greatness of UNILM lies in its simultaneous use of multiple pre-trained language models. As for how it does this, I think that’s secondary and not very important.
The general framework is as follows:
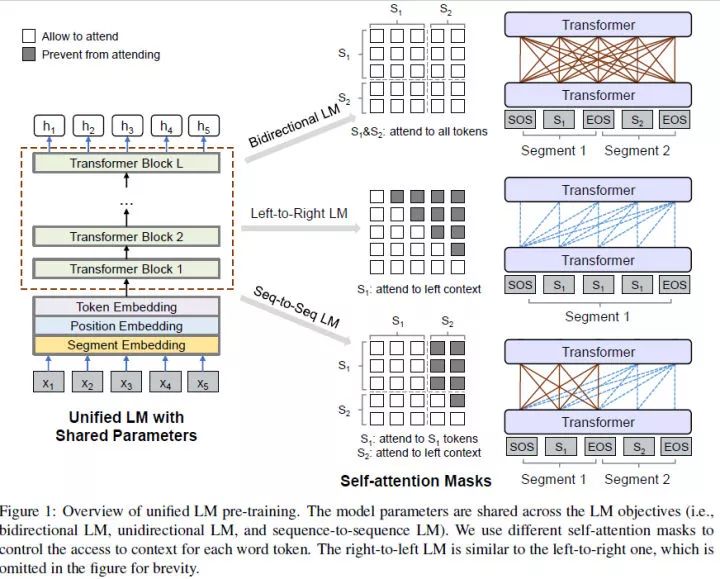
1. Input Representation
This part is quite similar to BERT, but I still need to elaborate. The input of UNILM is a sequence of words, which may be a text segment for unidirectional LMs or a pair of text segments for bidirectional LM and Seq2Seq LM. The format of the input sequence is as follows:
[SOS] + segment1 + [EOS]
[SOS] + segment1 + [EOS] + segment2 + [EOS]Similar to BERT, the model’s input includes:
token embedding + position embedding + segment embeddingAnother point is that UNILM processes all tokens into subwords, which may enhance the performance of the generation model, emmm, maybe? I don’t think that’s the focus.
2. Unidirectional LM
For a single paragraph input, UNILM utilizes both left-to-right LM and right-to-left LM (somewhat like ELMO). This is significantly different from BERT’s approach, and I believe this design is made considering generation aspects. I won’t delve into details; those interested can look it up.
3. Bidirectional LM
For paragraph pairs, it is essentially BERT’s language model, not much to say, just a brief mention.
4. Seq2Seq LM
For paragraph pairs, the first paragraph is encoded using the Bidirectional LM approach, while the second sentence is decoded using the Unidirectional LM approach, and both are trained simultaneously.
5. Next Sentence Prediction
Not much to say, similar to BERT, just a brief mention.
6. Parameters Initialized from BERT-large
Questions
1. Masking Strategy in MASS?
For MASS, it uses random masking of a segment of continuous tokens. Is there a better way to learn, such as masking 30% of the preceding tokens, 20% of the following tokens, and 50% randomly masking the middle tokens? This considers that for sentence generation, the beginning and end may require more thorough training and learning.
Or should we predict the next sentence based on the previous one, using the context of the dialogue to predict the next part?
2. Can BERT Directly Serve as the Encoder?
Using a pre-trained language model (like BERT) as the Encoder (freezing/unfreezing the Encoder parameters) might capture the information of the input sequence better, as the pre-trained language model has already achieved great success in natural language understanding. The Decoder only needs to learn how to extract information from the understood data to generate language, which could significantly reduce training time and complexity, potentially leading to better results.
3. MASS vs UNILM
Comparatively, UNILM undoubtedly excels in both innovation and model complexity and sophistication. However, for future development, I personally favor the Encoder-Decoder approach, as language generation is based on the foundation of language understanding. Therefore, why not directly use the pre-trained language models born from language understanding in the generation pre-training models? Is it necessary to train from scratch? Is it necessary to train generation + understanding together?
Conclusion
Ultimately, I want to express the core idea: Do understanding and generation coexist? If they coexist, in what manner? Could multi-task learning be a solution? Could GPT 2.0‘s approach of simply stacking data and models + unsupervised downstream tasks be the right answer? Is it possible to use multi-stage pre-training tasks, first for understanding, then using the pre-trained language model for understanding as the Encoder for generation pre-training, and finally fine-tuning for downstream tasks? Or should we follow UNILM’s approach of jointly training multiple pre-trained language models?
Currently, I feel that the path taken by pre-trained models is quite similar to cognitive neuroscience. Natural language understanding has already achieved breakthroughs, and I believe that natural language generation will become the main battlefield in the future.
The excitement belongs to others, but the bench is my own. I will quietly wait for the experts to produce results and see how they can be applied in practice; just observing will suffice.
I think it would be worthwhile to understand neuroscience; who knows, I might uncover some treasures, hee hee hee.
If you think this article is good, please give it a thumbs up before leaving; writing is quite exhausting.
References
[1] GPT1 – Improving Language Understanding by Generative Pre-Training
[2] GPT2 – Language Models are Unsupervised Multitask Learners
[3] MASS – Masked Sequence to Sequence Pre-training for Language Generation
[4] UNILM – Unified Language Model Pre-training for Natural Language Understanding and Generation
Recommended Reading:
How to Understand LSTM Followed by CRF?
Understanding Pytorch Distributed Training, This One is Enough!
EMNLP Best Paper Interpretation: A New Linguistic Theory from Information Bottleneck
