
Follow the public account “ML_NLP“

Motivation
Bert has been widely used in pre-trained language models, but current research mainly focuses on English. In cross-language scenarios, can Bert training bring improvements? The answer is almost certainly yes, it just depends on how to do it.
The paper [1] proposes two methods for training cross-lingual language models:
-
Unsupervised learning, relying solely on single-language data. -
Supervised learning, relying on bilingual parallel corpora.
Shared Sub-word Vocabulary
Whether using supervised or unsupervised methods, it is necessary to let multiple languages share a vocabulary. If words are mixed directly, the vocabulary will grow significantly as the number of languages increases. Fortunately, the vocabulary of the Bert model itself is sub-word based, and a suitable and reasonable vocabulary can be obtained through the Byte Pair Encoding (BPE) method.
BPE requires multiple iterations to obtain the final vocabulary result. Therefore, there are two drawbacks:
-
If the corpus is too large, BPE will take a long time to run. -
Rare languages often have less data, which may lead to insufficient sub-words for that language in the final BPE result.
Thus, a sampling method is used to generate a sub-dataset, and the BPE algorithm is run on this sub-dataset. The sampling probability formula is as follows, where p is the probability of each language in the total corpus, and q is the sampling probability. From the formula, it can be seen that q is the result of p after exponential normalization, and generally, alpha is set to 0.5.
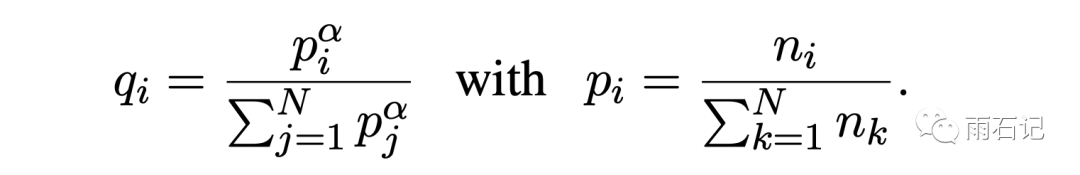
The lower the alpha, the more likely it is to appear for languages with lower frequencies.
Objectives of Training Language Models
The objectives used for training language models in the paper are threefold:
-
CLM, Casual Language Modeling. An autoregressive learning method, akin to GPT, using the Decoder part of the Transformer. -
MLM, Masked Language Modeling. A Bert-style learning method, masking 15% of the tokens as prediction targets. The difference is that in Bert, there is Next Sentence Prediction, so two sentences are combined. In the paper [1], however, a continuous single sentence is used, truncated to a length of 256. -
TLM, Translated Language Modeling. Similar to MLM, but the input consists of sentences from two languages concatenated together. Additionally, the position embedding must be reset, meaning that both the target language and the source language’s position embeddings should start from scratch.
Inputs and outputs for MLM and TLM are shown in the following figure:
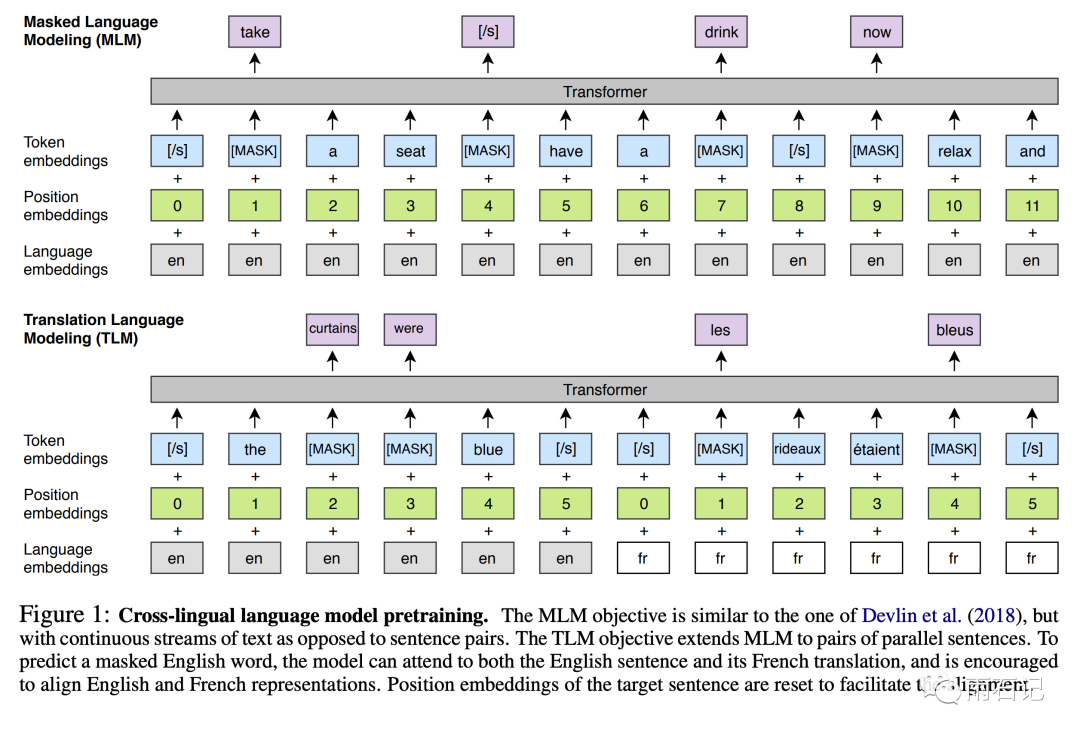
During training, a sampling method similar to that used for learning the vocabulary is still employed, but alpha is set to 0.7.
Model Pre-training
First, the model is pre-trained on a pre-processed Wiki dataset, with settings including:
-
MLM, on single-language training data -
MLM + TLM, in addition to single-language training data, also using parallel corpora to train TLM.
Experimental Results
XNLI Classification Experiment
Experiments were conducted on the XNLI dataset, which is a text classification dataset in fifteen languages. The pre-trained model was fine-tuned on the English corpus of XNLI and then evaluated on the 15 languages. To compare with previous papers, two baselines were also established:
-
TRANSLATE-TRAIN: Translating the English corpus in XNLI to a certain language in XNLI, then fine-tuning and testing on the translated corpus. -
TRANSLATE-TEST: Still conducting the model’s questions in English, then translating a certain language in XNLI to English for testing.
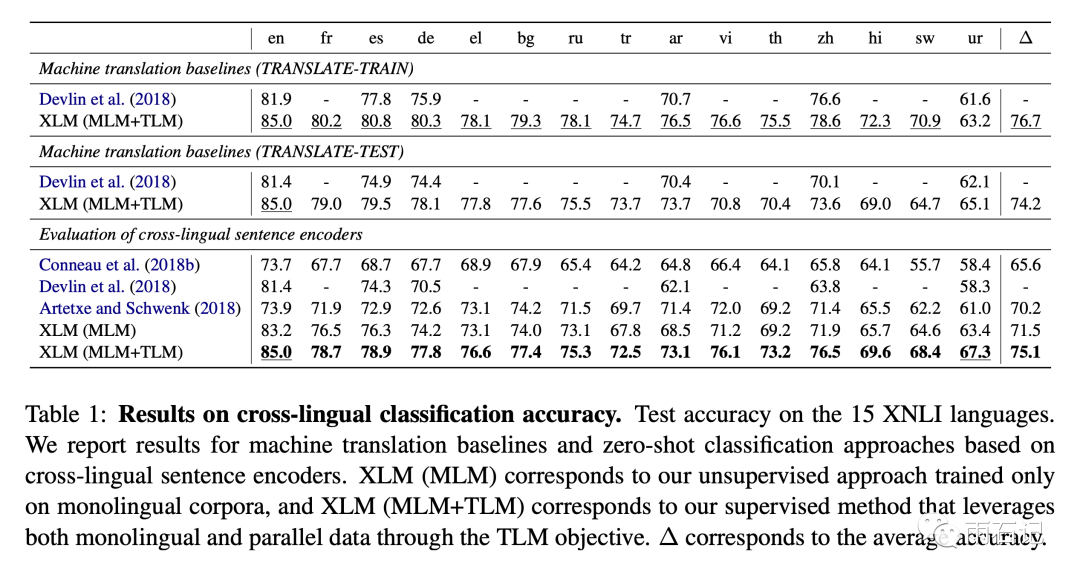
It can be seen that the MLM + TLM approach is much better than MLM. Additionally, fine-tuning on the translated language can achieve even better results.
Unsupervised Machine Translation
Using the pre-trained model to initialize the translation model can yield better results. EMB only uses the pre-trained embeddings to initialize the translation model’s embeddings. Moreover, both the Encoder and Decoder of the translation model can be initialized using XLM, resulting in nine different combination designs, where the Encoder and Decoder can each use one of three initialization methods: random initialization, CLM pre-training, or MLM pre-training.
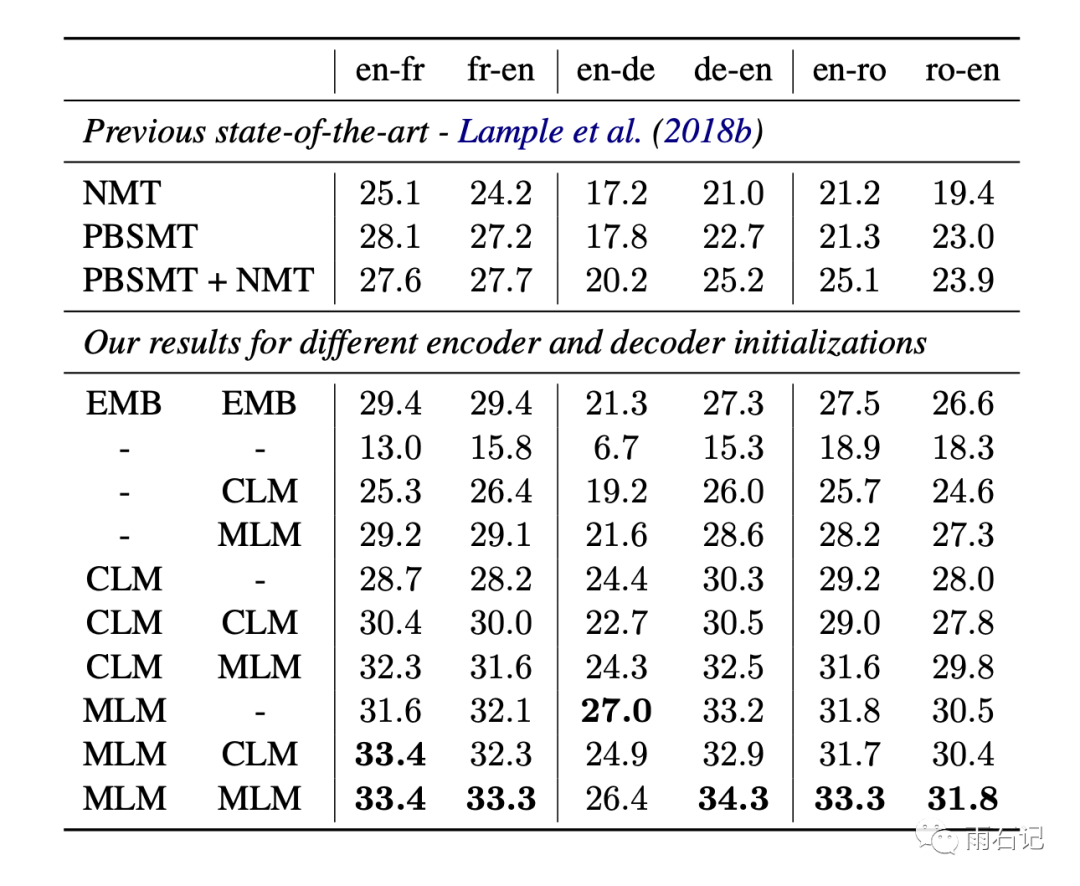
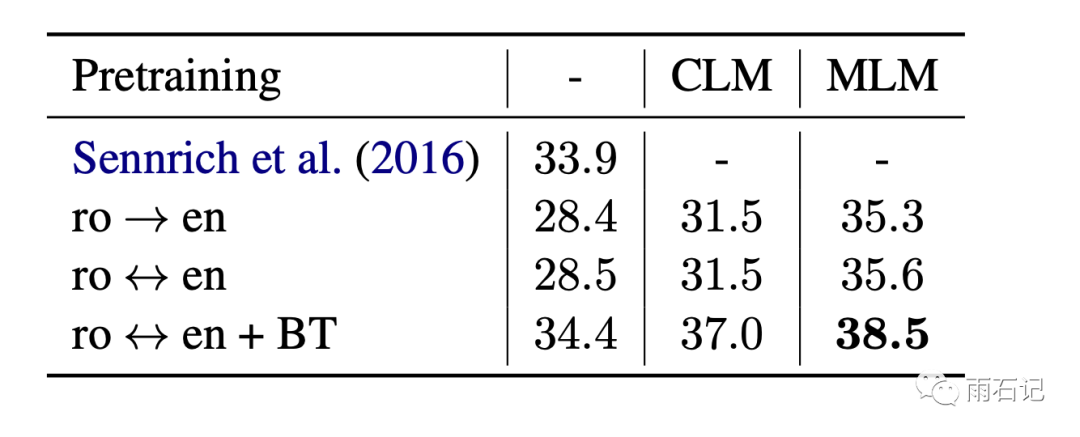
Supervised Machine Translation
Similar to the unsupervised experiments, both the Encoder and Decoder use the MLM pre-trained model for initialization.
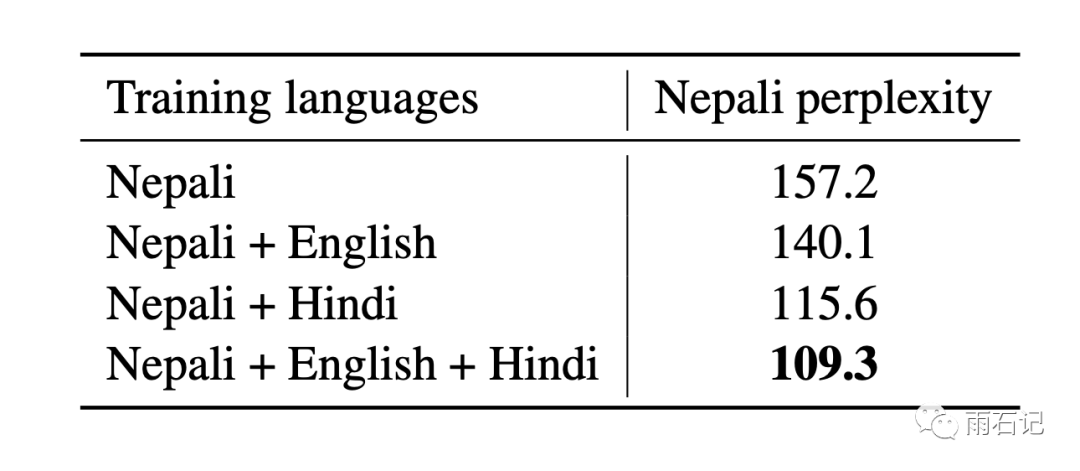
Low-Resource Language Models
XLM also aids in constructing language models for languages with limited data. As shown in the figure below, the language model trained on Nepali + English + Hindi data is significantly better than that trained solely on Nepali.
Conclusion and Reflections
From the experiments above, it can be seen that XLM can bring improvements in three aspects:
-
Better initialization methods for sentence encoders used in cross-language text classification problems. -
Better initialization methods for machine translation issues. -
Better methods for building language models for low-resource languages.
Additionally, from the experiments, it is evident that model initialization is a crucial aspect for machine translation problems.
References
-
[1]. Lample, Guillaume, and Alexis Conneau. “Cross-lingual language model pretraining.” arXiv preprint arXiv:1901.07291 (2019).
Repository Address Sharing:
Reply "code" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to obtain 195 papers from NAACL + 295 papers from ACL2019 that have open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavyweight! The Machine Learning Algorithms and Natural Language Processing exchange group has been officially established! There are a lot of resources in the group, welcome everyone to join and learn!
Bonus! Qiu Xipeng's deep learning and neural networks, the official Chinese tutorial of Pytorch, data analysis using Python, machine learning notes, Chinese version of pandas official documentation, effective java (Chinese version), and 20 other welfare resources.
How to obtain: After entering the group, click on the group announcement to get the download link. Please modify the note as [School/Company + Name + Direction] when adding.
For example — Harbin Institute of Technology + Zhang San + Dialogue System.
The account holder and WeChat merchants are advised to stay away. Thank you!
Recommended Reading:
Summary and Reflection on Common Normalization Methods: BN, LN, IN, GN
LSTM That Everyone Can Understand
Comprehensive Analysis of Python "Partial Functions" Usage