
MLNLP community is a well-known machine learning and natural language processing community at home and abroad, covering NLP master’s and doctoral students, university teachers, and corporate researchers.
The vision of the community is to promote communication and progress between the academic and industrial communities of natural language processing and machine learning, especially for the progress of beginners.
Reprinted from | New Intelligence
Editor | LRS
[Guide] In 2023, are there still people training models from scratch? Let’s track those pretrained models since BERT.
ChatGPT’s astonishing performance in few-shot and zero-shot scenarios has strengthened researchers’ belief that “pretraining” is the right path.
Pretrained Foundation Models (PFMs) are considered the foundation for various downstream tasks under different data modalities, based on large-scale data, training pretrained foundation models like BERT, GPT-3, MAE, DALLE-E, and ChatGPT to provide reasonable parameter initialization for downstream applications.
The pretraining idea behind PFMs plays an important role in the application of large models. Unlike previous methods that used convolutional and recurrent modules for feature extraction, the Generative Pretraining (GPT) method employs Transformers as feature extractors and conducts autoregressive training on large datasets.
With the tremendous success of PFMs in various fields, numerous methods, datasets, and evaluation metrics have been proposed in papers published in recent years. The industry needs a comprehensive review tracking the development process from BERT to ChatGPT.
Recently, researchers from several well-known institutions and companies, including Beihang University, Michigan State University, Lehigh University, Nanyang Technological University, and Duke University, jointly authored a review on pretrained foundation models, providing recent research progress in text, image, and graph fields, as well as current and future challenges and opportunities.

Paper link: https://arxiv.org/pdf/2302.09419.pdf
The researchers first reviewed the basic components of natural language processing, computer vision, and graph learning, as well as existing pretraining; then discussed other advanced PFMs in other data modalities and unified PFM considerations regarding data quality and quantity; and finally listed several key conclusions, including future research directions, challenges, and open questions.
From BERT to ChatGPT
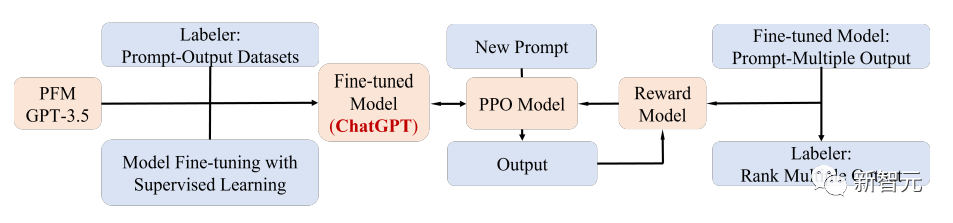
Pretrained Foundation Models (PFMs) are an important component in building artificial intelligence systems in the big data era, and they have been widely researched and applied in the three major AI fields of natural language processing (NLP), computer vision (CV), and graph learning (GL).
PFMs are general models that are effective in various fields or cross-domain tasks, showing great potential in learning feature representations for various learning tasks, such as text classification, text generation, image classification, object detection, and graph classification.
PFMs demonstrate excellent performance in training on large-scale corpora for multiple tasks and fine-tuning on similar small-scale tasks, enabling rapid data processing.
PFMs and Pretraining
PFMs are based on pretraining technology, aiming to train a general model using a large amount of data and tasks, which can be easily fine-tuned for different downstream applications.
The idea of pretraining originated from transfer learning in CV tasks. After recognizing the effectiveness of pretraining in the CV field, researchers began to use pretraining techniques to improve model performance in other fields. When applied to NLP, well-trained language models (LMs) can capture rich knowledge beneficial to downstream tasks, such as long-term dependencies and hierarchical relationships.
Additionally, a significant advantage of pretraining in NLP is that training data can come from any unlabeled text corpus, meaning there is an unlimited amount of training data available during pretraining.
Early pretraining was a static method, such as NNLM and Word2vec, which struggled to adapt to different semantic contexts; later, researchers proposed dynamic pretraining techniques such as BERT and XLNet.

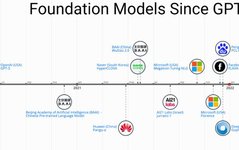
The history and evolution of PFMs in NLP, CV, and GL
PFMs based on pretraining techniques use large corpora to learn general semantic representations. With the introduction of these pioneering works, various PFMs have emerged and been applied to downstream tasks and applications.
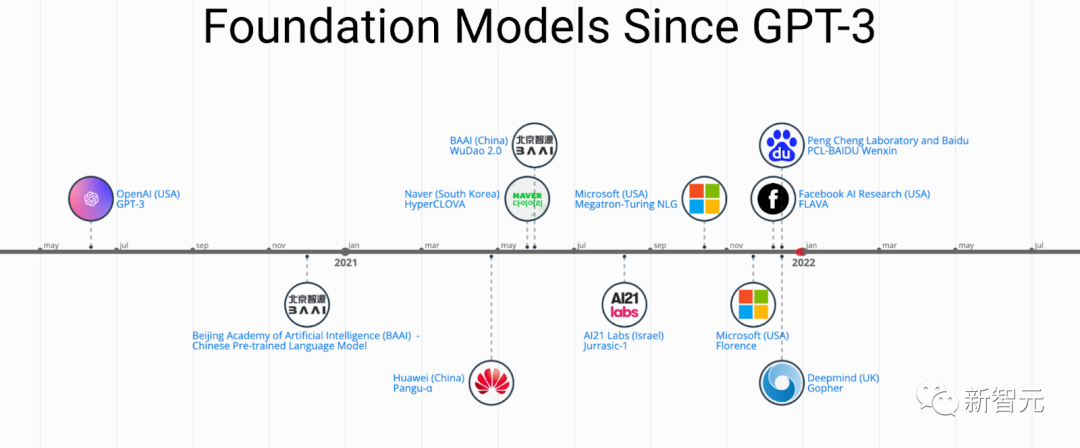
A notable application case of PFMs is the recently popular ChatGPT.
ChatGPT is fine-tuned from the Generative Pretrained Transformer, specifically GPT-3.5, trained on a mixed corpus of text and code; ChatGPT utilizes reinforcement learning from human feedback (RLHF) technology, which is currently one of the most promising methods for aligning large LMs with human intentions.
The superior performance of ChatGPT may lead to a critical point of paradigm shift in the training of every type of PFM, namely the application of instruction aligning technology, including reinforcement learning (RL), prompt tuning, and chain-of-thought, ultimately steering towards general artificial intelligence.
In this article, the researchers mainly review PFMs related to text, images, and graphs, which is also a relatively mature research classification method.
For text, language models can perform multiple tasks by predicting the next word or character; for example, PFMs can be used for machine translation, question answering systems, topic modeling, sentiment analysis, etc.
For images, similar to PFMs in text, a large-scale dataset is used to train a large model suitable for multiple CV tasks.
For graphs, similar pretraining ideas are also used to obtain PFMs, applicable to many downstream tasks.
In addition to PFMs targeting specific data domains, the article also reviews and elaborates on other advanced PFMs, such as those for speech, video, and cross-domain data, as well as multimodal PFMs.
Moreover, a trend towards a unified PFM capable of handling multimodal data is emerging; researchers first define the concept of unified PFMs and then review the state-of-the-art unified PFMs in recent studies, including OFA, UNIFIED-IO, FLAVA, BEiT-3, etc.
Based on the characteristics of existing PFMs in these three fields, the researchers conclude that PFMs have the following two major advantages:
1. They can significantly improve model performance on downstream tasks with minimal fine-tuning;
2. PFMs have been tested for quality.
Instead of building a model from scratch to solve similar problems, a better choice is to apply PFMs to task-related datasets.
The enormous potential of PFMs has spurred a lot of related work focusing on model efficiency, safety, and compression issues.
The characteristics of this review include:
-
The researchers have tracked the latest research findings, providing a solid summary of the development of PFMs in NLP, CV, and GL, discussing and providing insights regarding the design and pretraining methods of universal PFMs in these three major application areas. -
Summarizing the development of PFMs in other multimedia fields such as speech and video, and further discussing deeper topics about PFMs, including unified PFMs, model efficiency and compression, as well as safety and privacy. -
By reviewing PFMs for different tasks across various modalities, the discussion addresses the major challenges and opportunities for future research on ultra-large models in the big data era, guiding the development of a new generation of collaborative and interactive intelligence based on PFMs.

Scan the QR code to add the assistant WeChat
About Us
