
Click on the “MLNLP” above and select the “Star” public account
Heavyweight content delivered to you in real-time

Reprinted from the public account: AI Developer
Introduction to BERT
It is no exaggeration to say that Google’s AI Lab’s BERT has profoundly impacted the landscape of NLP.

Imagine a model trained on a vast amount of unannotated data, where you only need to make a slight fine-tuning to achieve SOTA results on 11 different NLP tasks. Indeed, BERT is such a model, and it has completely changed the way we design NLP models.
After BERT, many NLP architectures, training methods, and language models have emerged like mushrooms after rain, such as Google’s TransformerXL, OpenAI’s GPT-2, XLNet, ERNIE2.0, RoBERTa, and more.
Note: In this article, I will mention many aspects of Transformers. If you are not familiar with Transformers, you can first read this article – How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models.
What is BERT?
You must have heard of BERT and know how incredible it is to have changed the field of NLP, but what exactly is BERT?
Here is the BERT team’s description of the framework:
BERT stands for Bidirectional Encoder Representations from Transformers, which pre-trains deep bidirectional representations on unannotated text by conditioning on both left and right context. After training, you only need to fine-tune the BERT pre-trained model with an output layer specific to the task to achieve SOTA results.
This explanation may not be clear enough for newcomers, but it indeed summarizes the mechanism of BERT well. Next, we will analyze it step by step.
First, it is clear that BERT stands for Bidirectional Encoder Representations from Transformers, and every word in its name has significance, which we will introduce one by one in the following paragraphs. From the name BERT, we get the most important information: BERT is based on the Transformer architecture.
Secondly, BERT is pre-trained on a large amount of unannotated text, including the entire Wikipedia (2.5 billion words) and a book corpus (800 million words).
This pre-training step is crucial for BERT. It is precisely because of the support of such a vast corpus that the model can extract deeper and more accurate insights into how language works during training, and the knowledge extracted through this process serves as “universal oil” for all NLP tasks.
Then, BERT is a “deep bidirectional” model, which means that BERT pays attention to the context information of the current position during training.
Contextual information is vital for accurately understanding semantics. Look at the following example, where both sentences contain the same word “bank”:
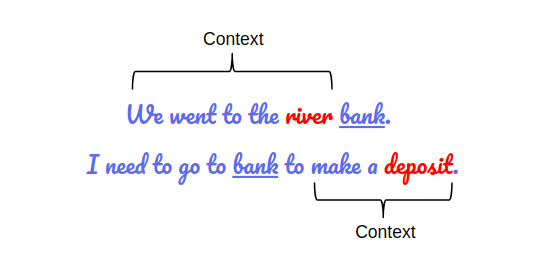
BERT captures contextual information
If we try to understand the meaning of “bank” relying solely on the information from either the preceding or following context, we will not be able to distinguish the different meanings of “bank” in these two sentences.
The solution is to consider both contextual information simultaneously before making predictions, and BERT does just that.
Finally, what is most appealing about BERT is that we can achieve SOTA results on various NLP tasks just by adding an output layer based on our needs at the end of the model.
From Word2Vec to BERT: Exploring Language Representations in NLP
One of the biggest challenges in natural language processing is the scarcity of training data. NLP is a diverse field with many tasks, and most domain-specific datasets contain only a few thousand or hundreds of thousands of manually labeled data.” — Google AI
Word2Vec and GloVe
The idea of pre-trained models learning language representations from a large amount of unannotated text comes from word embeddings, such asWord2Vec and GloVe.
Word embeddings have changed the way NLP tasks are performed. With embeddings, we can capture the contextual relationships between words.
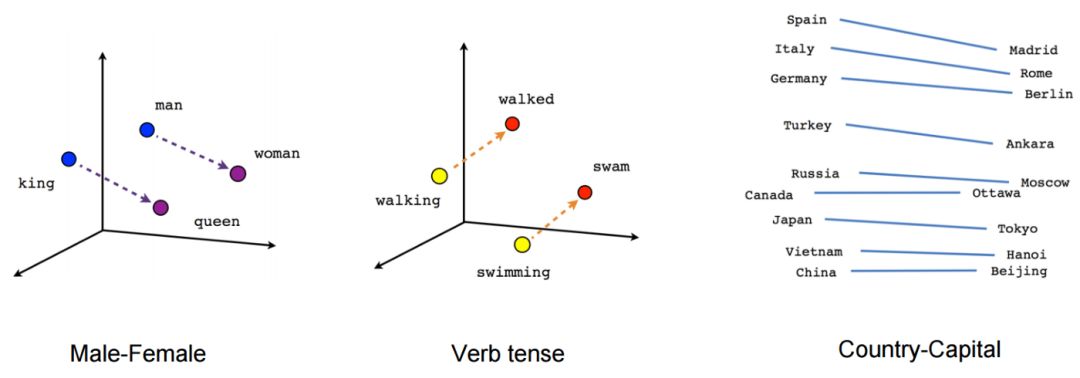
The embedding methods shown in the figure are widely used in training models for downstream NLP tasks to obtain better prediction results.
A major flaw in previous embedding methods is that they only used shallow language models, which means that the information they captured was limited.
Another flaw is that these embedding models did not consider the context of words. As mentioned earlier, the word “bank” may have different meanings in different contexts.
However, models like Word2Vec represent “bank” in different contexts with the same vector.
As a result, some important information is lost.
ELMo and ULMFiT
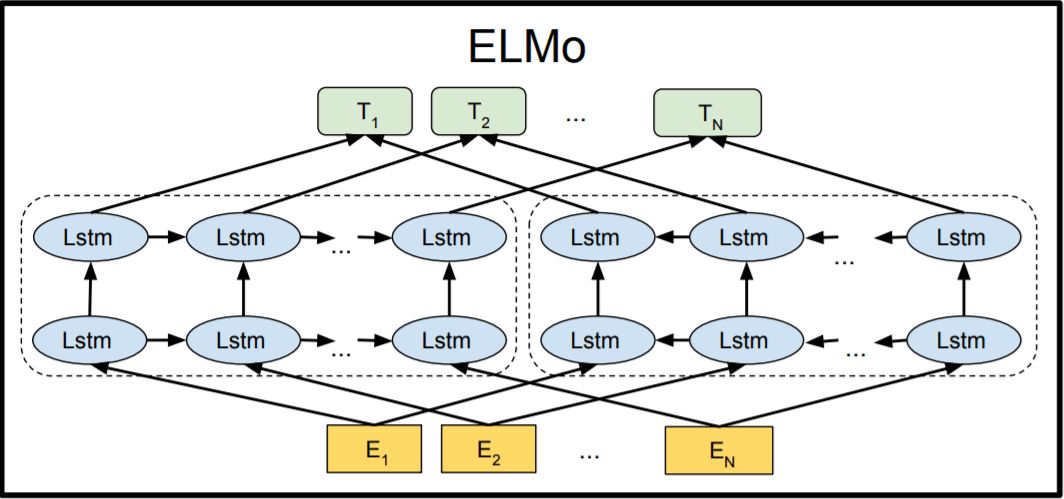
ELMo is a solution proposed for the problem of language polysemy—specifically for words that have different meanings in different contexts.
Starting from training shallow feedforward networks (Word2Vec), we gradually transitioned to using complex bidirectional LSTM structures to train word embeddings.
This means that the same word can have multiple ELMo embeddings depending on its context.
Since then, we have begun to notice that the advantages of pre-training will play a significant role in NLP tasks.

ULMFiT takes it a step further, where even with very little data (less than 100), fine-tuning a language model trained on document classification tasks can yield excellent results. This means ULMFiT solves the problem of transfer learning in NLP tasks.
This is the golden formula for NLP transfer learning we propose:
NLP Transfer Learning = Pre-training + Fine-tuning
After ULMFiT, many NLP tasks have been trained according to the above formula, achieving new benchmarks.
OpenAI’s GPT
OpenAI’s GPT further expands the pre-training and fine-tuning methods introduced in ULMFiT and ELMo.
The key to GPT is replacing the LSTM-based language modeling structure with a Transformer-based structure.
Not only for document classification tasks, but the GPT model can also be fine-tuned for other NLP tasks,
such as common sense reasoning, semantic similarity, and reading comprehension.
OpenAI’s GPT has achieved SOTA results in multiple tasks, validating the robustness and effectiveness of the Transformer architecture.
Thus, BERT emerged based on Transformers and brought significant changes to the field of NLP.
The Emergence of BERT
At this point, solving NLP tasks cannot do without these two steps:
1. Train a language model on a large corpus of unannotated text (unsupervised or semi-supervised)
2. Fine-tune the large language model for specific NLP tasks to fully leverage the vast knowledge of the pre-trained model (supervised)
Next, we will take a detailed look at how BERT trains its models and becomes the industry benchmark in the NLP field over time.
How Does BERT Work? A Detailed Explanation
Dive into BERT to understand why the language model built by BERT is so effective.
1. The Structure of BERT
The BERT architecture is built upon Transformers. We currently have two available variants:
-
BERT Base: 12 layers (transformer modules), 12 attention heads, 110 million parameters
-
BERT Large: 24 layers (transformer modules), 16 attention heads, 340 million parameters
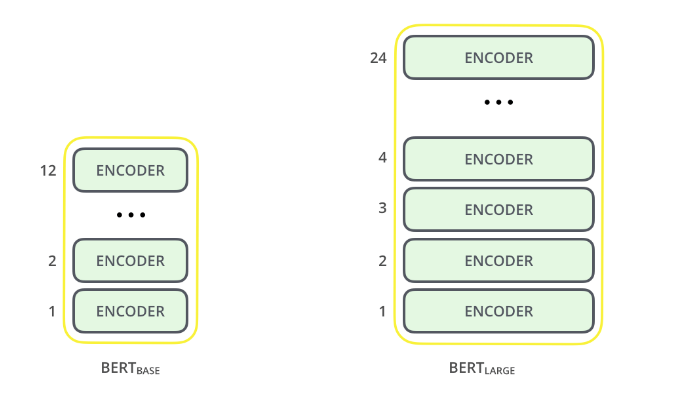
Image source
Compared to OpenAI’s GPT model, the size of the BERT Base model is similar, while all transformer layers of BERT Base only include the encoder part.
If you are not very clear about the transformer structure, I suggest you first read this article.
Now that we understand the overall architecture of BERT, we need to perform some text processing work before officially building the model.
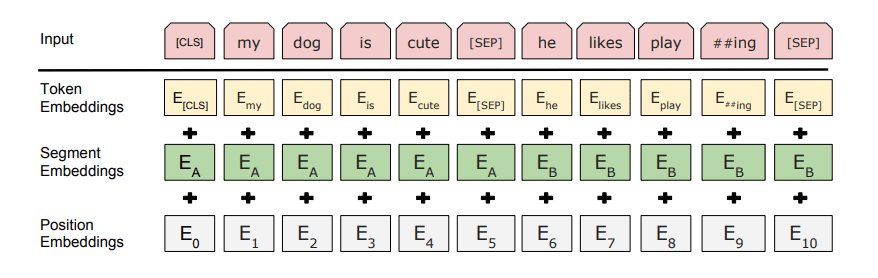
2. Text Preprocessing
The developers behind BERT added a set of specific rules to represent the input text for the model. Many of these are creative design choices that can enhance the model’s performance.
First, each input embedding is a combination of three embeddings:
1. Position embedding: BERT learns and uses position embeddings to express the position of words in a sentence. Adding this embedding helps overcome the limitation of Transformers, which, unlike RNNs, cannot capture “sequence” or “order” information.
2. Segment embedding: BERT can also take sentences as input for tasks (e.g., question-answering). Therefore, it learns unique embeddings for the first and second sentences to help the model distinguish between them. In the example above, all tags for EA belong to sentence A (and the same for EB).
3. Token embedding: These are embeddings learned for specific tokens from the WordPiece token vocabulary.
The input representation for a given token is constructed by summing the corresponding token, segment, and position embeddings.
This comprehensive embedding scheme includes a wealth of useful model information.
The combination of these preprocessing steps makes BERT so versatile.
3. Pre-training Tasks
BERT is pre-trained on two NLP tasks:
-
Masked Language Model
-
Next Sentence Prediction
Let’s understand these two tasks in more detail!
a. Masked Language Model (Bidirectional)
BERT is a deep bidirectional model, and the network consistently focuses on the context of the current word from the first layer to the last layer to capture information.
Word sequence prediction
Traditional language models either use right-to-left text information to predict the next word (e.g., GPT) or use left-to-right text information for training, which inevitably causes the model to lose some information, leading to errors.
ELMo attempted to solve this problem by training two LSTM language models (one using left-to-right text information and the other using right-to-left text information) and connecting them. While this made some progress, it was still far from enough.

Compared to GPT and ELMo, BERT made significant breakthroughs in utilizing contextual information, as shown in the above image.
The arrows in the image indicate the flow of information from one layer to the next, and the green box at the top represents the final representation of each input word.
From the above image, it is clear that: BERT is bidirectional, GPT is unidirectional (flow of information from left to right), and ELMo is shallowly bidirectional.
Regarding the masked language model—this is the secret of BERT’s bidirectional encoding.
For a sentence like “I love to read data science blogs on Analytics Vidhya,” how do we train a bidirectional language model?
We first replace “Analytics” with “[MASK],” where “[MASK]” indicates that the word at that position is masked.
Then we need to train a model to predict the masked word: “I love to read data science blogs on [MASK] Vidhya.”
This is the key to the masked language model. The authors of BERT also introduced some considerations for the masked language model:
-
To prevent the model from focusing too much on specific positions or masked tokens, researchers randomly mask 15% of the words.
-
The masked words are not always replaced with [MASK]; during the fine-tuning phase for specific tasks, the [MASK] token is not needed.
-
For this purpose, the general practice of researchers is: (15% of words need [MASK])
-
80% of the 15% masked words are replaced with [MASK]
-
10% of the remaining words are replaced with other random words
-
10% of the remaining words are left unchanged
In a previous article of mine, I detailed how to implement a masked language model in Python: Introduction to PyTorch-Transformers: An Incredible Library for State-of-the-Art NLP (with Python code)
b. Next Sentence Prediction
The masked language model (MLMs) learns the relationships between words.
Additionally, BERT is also trained on the next sentence prediction task to learn the relationships between sentences.
A typical example of such tasks is question-answering systems.
The task is simple: given sentences A and B, determine whether B is the next sentence after A or just a random sentence?
Since this is a binary classification problem, breaking down sentences in the corpus into sentence pairs can yield a large amount of training data. Similar to MLMs, the authors also provide considerations when performing the next sentence prediction task. This is illustrated through the following example:
For a dataset containing 100,000 sentences, we can obtain 50,000 sentence pairs as training data.
-
50% of the training data, the second sentence is the true next sentence
-
Another 50%, the second sentence is a random sentence from the corpus
-
The labels for the first 50% are ‘IsNext’, and for the remaining 50% are ‘NotNext’
By combining the masked language model (MLMs) and next sentence prediction (NSP) pre-training tasks during the modeling process, BERT becomes a task-agnostic model that can be easily fine-tuned for other downstream tasks.
Using BERT for Text Classification in Python
You must have various expectations for the possibilities of BERT. Indeed, we can leverage the advantages of the BERT pre-trained model in various ways in specific NLP applications.
One of the most effective methods is to fine-tune it based on your task and specific data, and then we can use the embeddings from BERT as embeddings for text documents.
Next, we will learn how to apply BERT’s embeddings to our tasks. As for how to fine-tune the entire BERT model, I will introduce it in another article.
To extract BERT’s embeddings, we will use a very practical open-source project called Bert-as-Service:
BERT-As-Service
Since BERT requires a large amount of code and many installation packages, it is unrealistic for ordinary users to run BERT directly. Therefore, the open-source project BERT-As-Service helps us conveniently use BERT. Through this project, we can call BERT to encode sentences with just two lines of code.
Installing BERT-As-Service
BERT-As-Service operates very simply. It creates a BERT server that we can access by writing Python code in a notebook. This way, we just need to send the sentences as a list, and the server will return the BERT embeddings for those sentences.
We can install the server and client via pip. They can be installed separately on a local computer or on different computers:
$ pip install bert-serving-server # server
$ pip install bert-serving-client # client
Additionally, since running BERT has high GPU requirements, I recommend installing the bert-serving-server on a cloud GPU platform or another computer with high computing power.
At the same time, the bert-serving-server requires Python and TensorFlow version: Python >= 3.5; TensorFlow >= 1.10.
Then, download the pre-trained model shown in the terminal (choose what you need) and unzip the downloaded zip file.
The following image shows the released BERT pre-trained models:

BERT Model
I chose to download and unzip BERT Uncased:
$ wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip && unzip uncased_L-12_H-768_A-12.zipOnce all files are unzipped, you can start the BERT service:
$ bert-serving-start -model_dir uncased_L-12_H-768_A-12/ -num_worker=2 -max_seq_len 50Now, you can call BERT-As-Service in Python through the bert-serving-client. Let’s look at the code!
Open a new Jupyter Notebook, and we want to obtain the BERT embedding for “I love data science and analytics vidhya.”
from bert_serving.client import BertClient
# Connect to the BERT server using the IP address; no need for IP if it's a local server
bc = BertClient(ip="Server IP Address")
# Get the embedding
embedding = bc.encode(["I love data science and analytics vidhya."])
# Confirm the shape of the returned embedding, which should be 1x768
print(embedding.shape)
The IP address is for the BERT server or cloud platform; if it’s a local server, there’s no need to fill in the IP.
Since this sentence is represented by 768 hidden units in the BERT architecture, the final returned embedding shape is (1,768).
Description of the Problem: Classifying Hate Speech on Twitter
Next, we will test the effectiveness of BERT using a real dataset. We will use the Twitter “Hate Speech” classification dataset, which labels tweets as either yes or no.
You can learn more or download the dataset from this link problem statement on the DataHack platform.
For simplicity, if a tweet contains racist or sexist sentiments, we consider that tweet to contain hate speech. Therefore, the task is to classify racist or sexist tweets from other tweets.
We will use BERT to embed each tweet in the dataset and then train a text classification model using these embeddings.
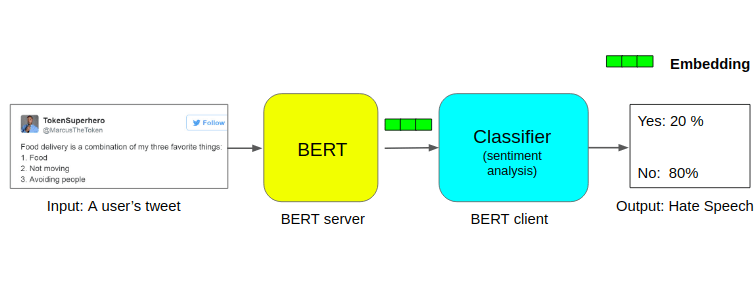
Task Process
Next, let’s look at the code:
import pandas as pd
import numpy as np
# Import training data
train = pd.read_csv('BERT_proj/train_E6oV3lV.csv', encoding='iso-8859-1')
train.shape
I’m sure you’re familiar with Twitter, where many tweets contain random symbols and numbers (also known as chat language!). Our dataset is the same way, so we need to preprocess the dataset before passing it to BERT:
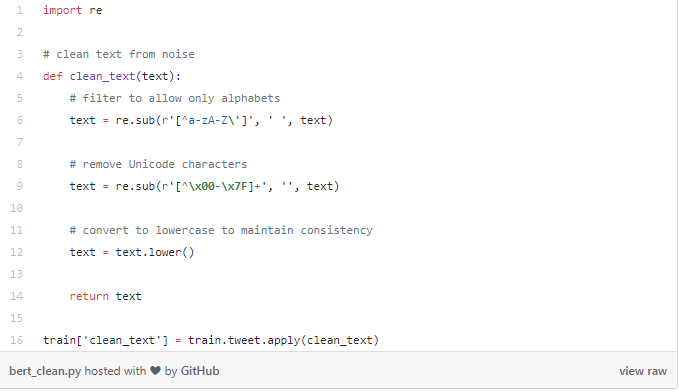
Now we need to split the cleaned dataset into training and validation sets:
from sklearn.model_selection import train_test_split
# Split into training and validation sets
X_tr, X_val, y_tr, y_val = train_test_split(train.clean_text, train.label, test_size=0.25, random_state=42)
print('X_tr shape:',X_tr.shape)
Next, we will perform BERT embeddings on all tweets in the test and validation sets:
from bert_serving.client import BertClient
# Connect to the BERT server using the IP
bc = BertClient(ip="YOUR_SERVER_IP")
# Obtain embeddings for training and test sets
X_tr_bert = bc.encode(X_tr.tolist())
X_val_bert = bc.encode(X_val.tolist())
Now it’s time to build the model! Let’s first train the classification model:
from sklearn.linear_model import LogisticRegression
# Logistic Regression model
model_bert = LogisticRegression()
# Train
model_bert = model_bert.fit(X_tr_bert, y_tr)
# Predict
pred_bert = model_bert.predict(X_val_bert)
Check the classification accuracy:
from sklearn.metrics import accuracy_score
print(accuracy_score(y_val, pred_bert))
As you can see, even with a very small dataset, we can easily achieve around 95% accuracy. It’s truly incredible!
You should practice BERT embeddings on other tasks yourself and share your results in the comments section below.
In the next article, I will use the fine-tuned BERT model on another dataset and compare its performance.
Beyond BERT: The Latest Technologies in NLP
BERT has sparked great interest in the field of NLP, especially with the widespread application of Transformers. This has led to more and more labs and organizations beginning to research tasks such as pre-training, transformers, and fine-tuning.
After BERT, several new projects have achieved better results in various NLP tasks. For example, RoBERTa, which is Facebook AI’s improvement on BERT and DistilBERT, the latter being a lighter and more convenient version of BERT.
You can learn more about improved models after BERT in this article regarding State-of-the-Art NLP.
via: https://www.analyticsvidhya.com , 2019/9/25.
Recommended Reading:
Learning Notes on Sentence Representation
Common Normalization Methods: BN, LN, IN, GN
PaddlePaddle Practical NLP Classic Model BiGRU + CRF Explained
