
Click the “MLNLP” above and select the “Starred” public account
Heavyweight content delivered first
Author: Jay Alammar, Translated by Qbit AI
BERT, as a key player in the field of natural language processing, is something that NLPer can’t avoid.

However, for those with little experience and weak foundations, mastering BERT can be a bit challenging.
Now, tech blogger Jay Alammar has created a “Visual Guide to Using BERT for the First Time,” introducing how to get started with BERT in a very simple and clear way, with illustrations from the principles of BERT to the actual operation process, even with more illustrations than code. Qbit AI has compiled it for you~

This article mainly takes the classification of sentences using a variant of BERT as an example to introduce how to use BERT.
At the end, there is also a link to the Colab address.
Dataset: SST2
First, we need to use the SST2 dataset, which contains sentences from movie reviews.
If the reviewer expresses positive appreciation for the movie, it will have a label of “1”;
If the reviewer does not like the movie and gives a negative review, it will have a label of “0”.
The movie reviews in the dataset are written in English and look something like this:
|
Sentence |
Label |
|
a stirring, funny and finally transporting reimagining of beauty and the beast and 1930s horror films A stirring, funny, and ultimately transporting reimagining of Beauty and the Beast and 1930s horror films |
1 |
|
apparently reassembled from the cutting room floor of any given daytime soap Apparently reassembled from the cutting room floor of any given daytime soap |
0 |
|
they presume their audience won’t sit still for a sociology lesson They presume their audience won’t sit still for a sociology lesson |
0 |
|
this is a visually stunning rumination on love, memory, history and the war between art and commerce This is a visually stunning rumination on love, memory, history, and the war between art and commerce |
1 |
|
jonathan parker’s bartleby should have been the be all end all of the modern office anomie films Jonathan Parker’s Bartleby should have been the be-all-end-all of modern office anomie films |
1 |
Sentence Sentiment Classification Model
Now, with the SST2 movie review dataset, we need to create a model that automatically classifies English sentences.
If judged to be positive, label it as 1; if judged to be negative, label it as 0.
The rough logic is as follows:

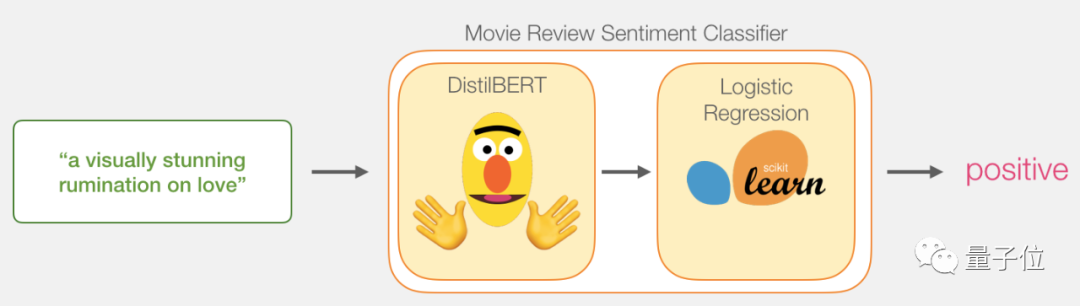
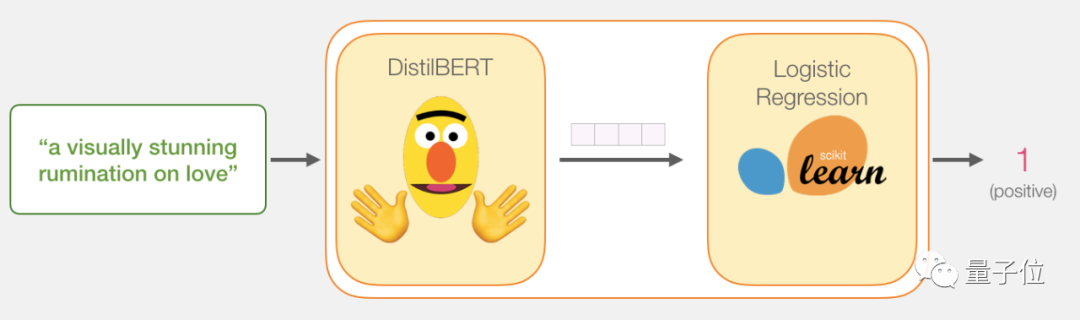
Input a sentence, pass it through the movie review sentence classifier, and output a positive or negative result.
This model is actually composed of two models.
DistilBERT is responsible for processing the sentence, extracting information, and then passing it to the next model. This is a lightweight and fast open-source version of BERT from 🤗 Hugging Face, with performance similar to the original version.
The next model is a basic logistic regression model, whose input is the output from DistilBERT, and it outputs positive or negative results.
The data we pass between the two models is a vector of size 768, which can be considered as a sentence embedding used for classification.
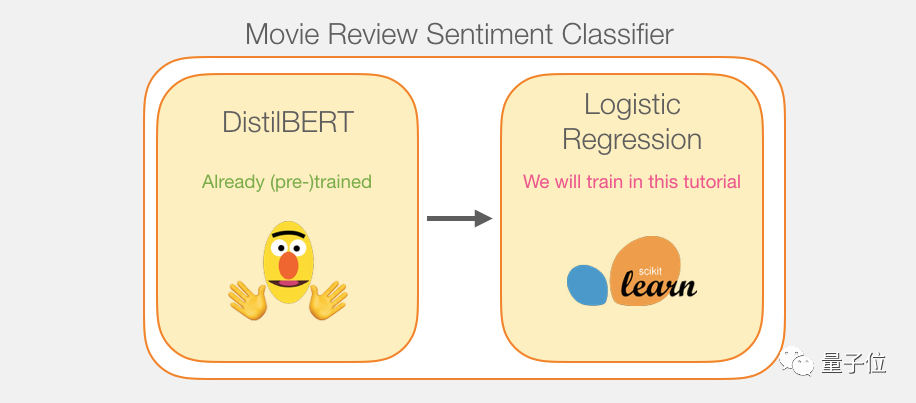
Model Training Process
Although we will use two models, we only need to train the logistic regression model; DistilBERT can be used directly in its pre-trained version.
However, this model has never been trained or fine-tuned for the sentence classification task. We obtain some sentence classification capabilities from the general-purpose BERT, especially for the BERT output at the first position (related to the [CLS] token). This is the second training objective of BERT, and the next step is sentence classification. This objective seems to train the model to encapsulate the meaning of the full sentence into the output at the first position.
This Transformer library provides us with the implementation of DistilBERT and the pre-trained version of the model.
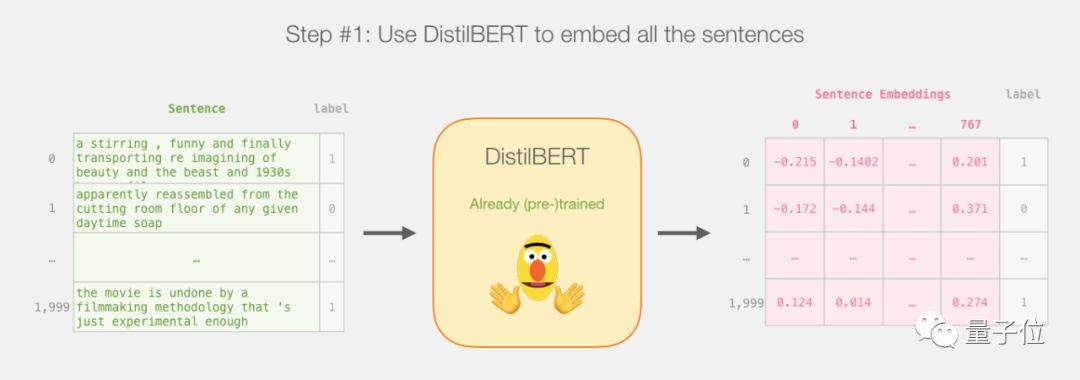
Tutorial Overview
This is the entire plan of this tutorial. We first use the trained DistilBERT to generate sentence embeddings for 2000 sentences.
After that, there is no need to touch DistilBERT anymore; everything here is Scikit Learn, where we perform regular training and testing on this dataset:
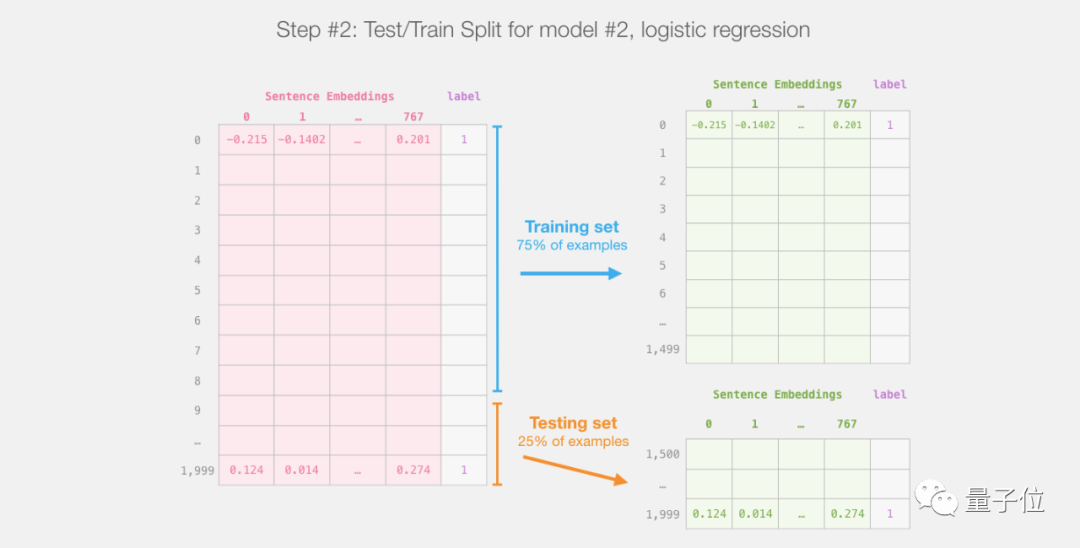
Train and test the first model, which is DistilBERT, create our training dataset, and evaluate the second model, which is the logistic regression model.
Then train the logistic regression model on the training set:

How Individual Predictions Are Made
Before we study the code explaining how to train the model, let’s first take a look at how a trained model makes predictions.
We will try to classify this sentence:
a visually stunning rumination on love
A visually stunning rumination on love
First step, use the BERT tokenizer to split the sentence into two tokens;
Second step, we add special tokens for sentence classification (the first position is [CLS], and the end of the sentence is [SEP]).

Third step, the tokenizer replaces each token with IDs from the embedding table, becoming components for training the model.

Note that the tokenizer completes all steps in this line of code:
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)Now our input sentence is in the appropriate state to be passed to DistilBERT.
This step visualizes as follows:
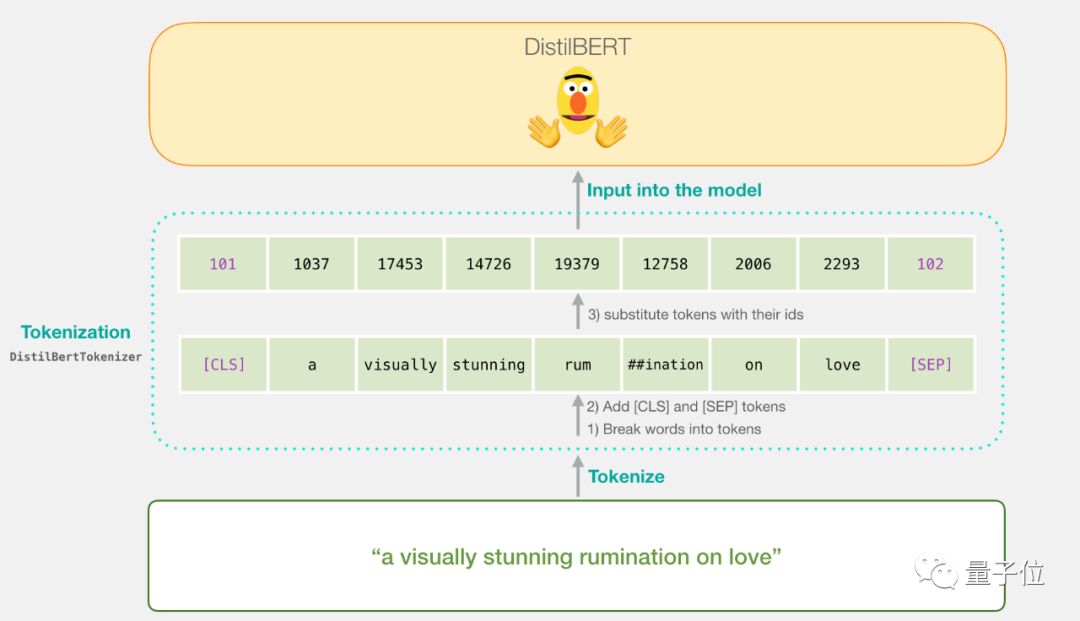
Passing Through DistilBERT
The input vector passes through DistilBERT, outputting a vector for each input token, each vector consists of 768 numbers.
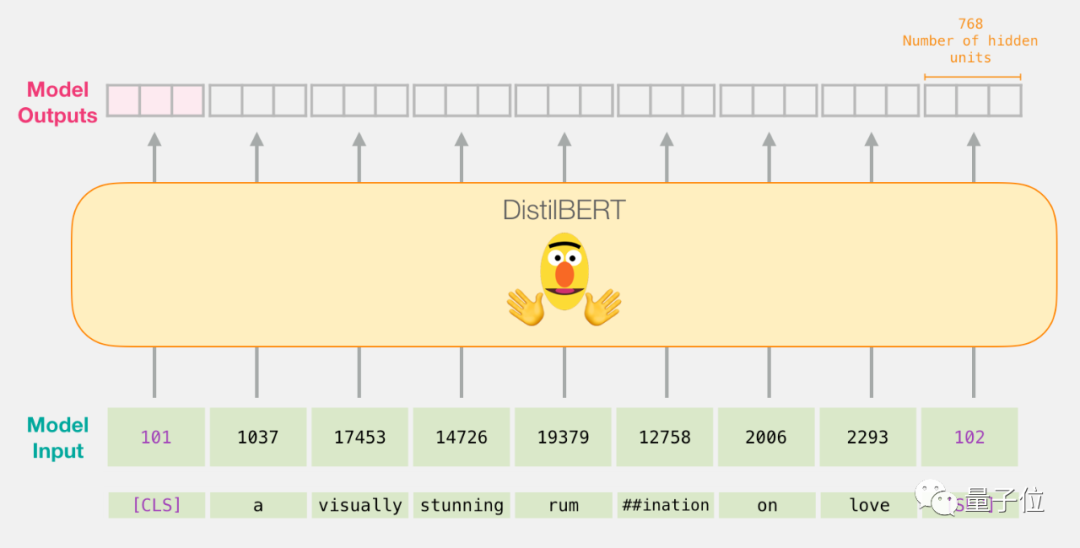
Since this is a sentence classification task, we ignore all other contents except for the first vector (related to the [CLS] token), and then use the first vector as the input for the logistic regression model.
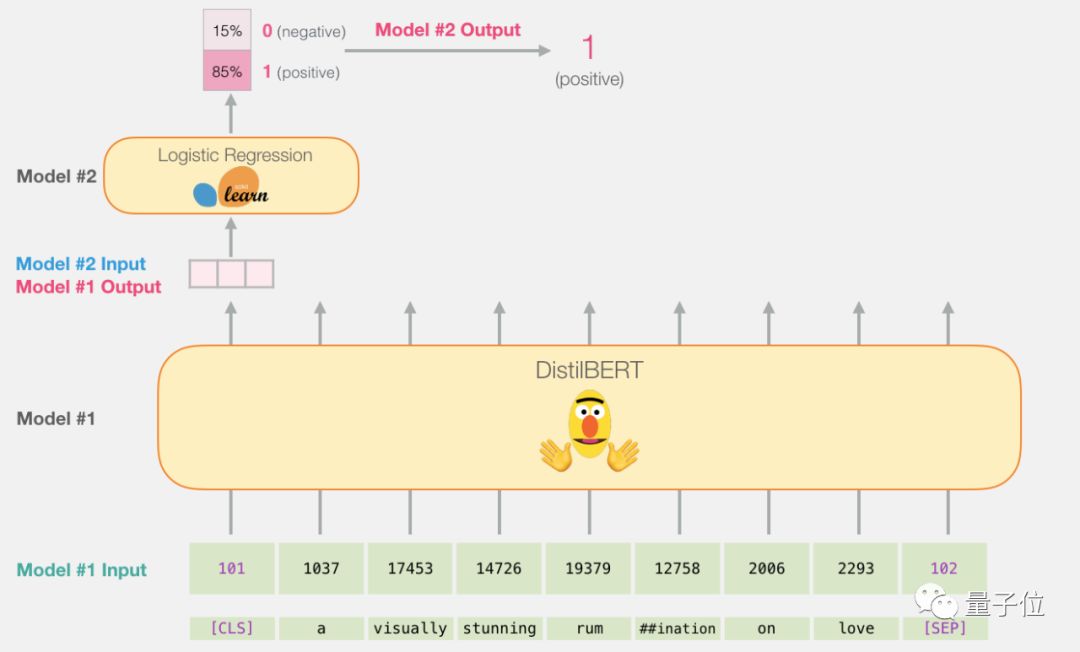
From here, the job of the logistic regression model is to classify this vector based on the experience it learned from the training process.
The process of prediction calculation is as follows:
Code
Now, let’s look at the code for the entire process. You can also find the GitHub code and the runnable version on Colab at the link provided later.
First, import the trading tools.
import numpy as np
import pandas as pd
import torch
import transformers as ppb # pytorch transformers
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_splitYou can find this dataset on GitHub, so we can directly import it into a pandas dataframe.
df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)You can directly use df.head() to view the first five rows of the dataframe to see what the dataset looks like.
df.head()Then it outputs:

Import Pre-trained DistilBERT Model and Tokenizer
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
## Want BERT instead of DistilBERT? Uncomment the following line:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
# Load pretrained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)Now we can tokenize this dataset.
Note that this step is different from the above example, which only processed one sentence, but we need to batch process all sentences.
Tokenization
tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))This step converts each sentence into a list of IDs.
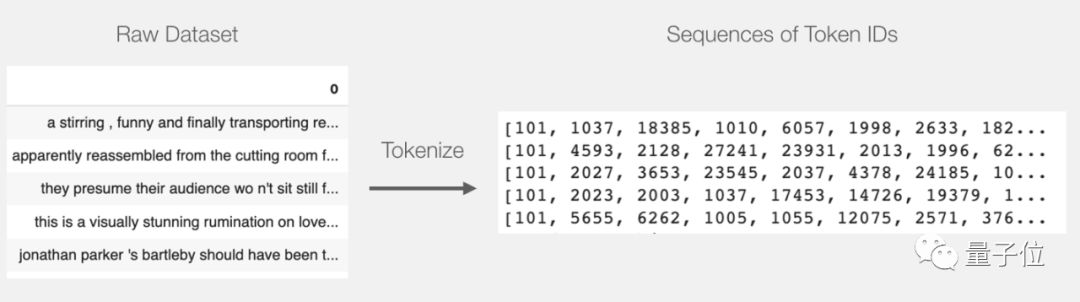
The dataset is now the current list (or pandas Series/DataFrame), and before DistilBERT processes it, we need to standardize all vectors and add token 0 to short sentences.
After padding with 0, we now have a complete matrix/tensor that can be fed to BERT:

Processing with DistilBERT
Now, create an input tensor for the padded token matrix and send it to DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)After running this step, last_hidden_states retains the output from DistilBERT.
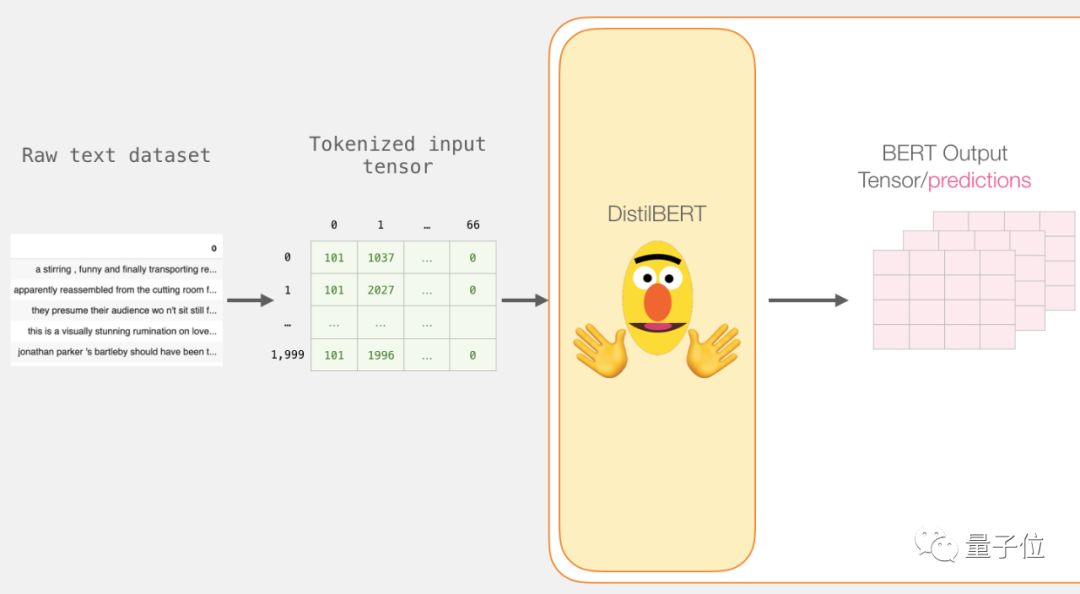
Open BERT’s Output Tensor
Unpack this 3D output tensor and first check its dimensions:
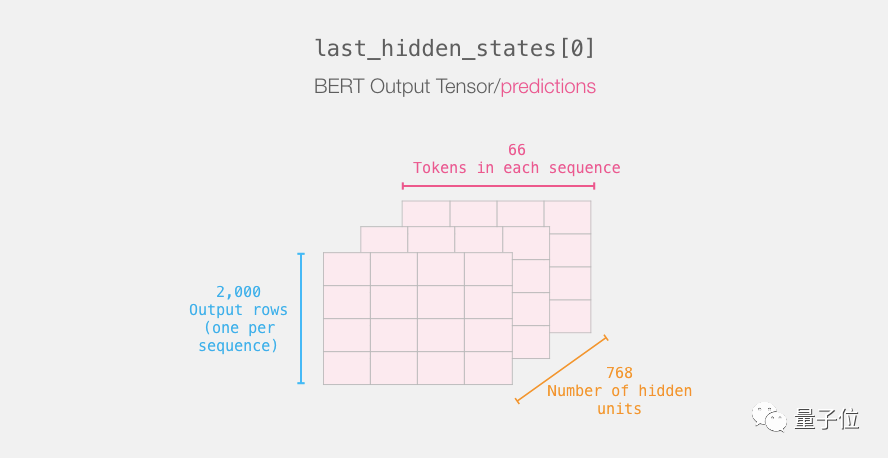
Review the Sentence Processing Steps
Each row is associated with a sentence in our dataset. To recap, the entire processing flow is as follows:
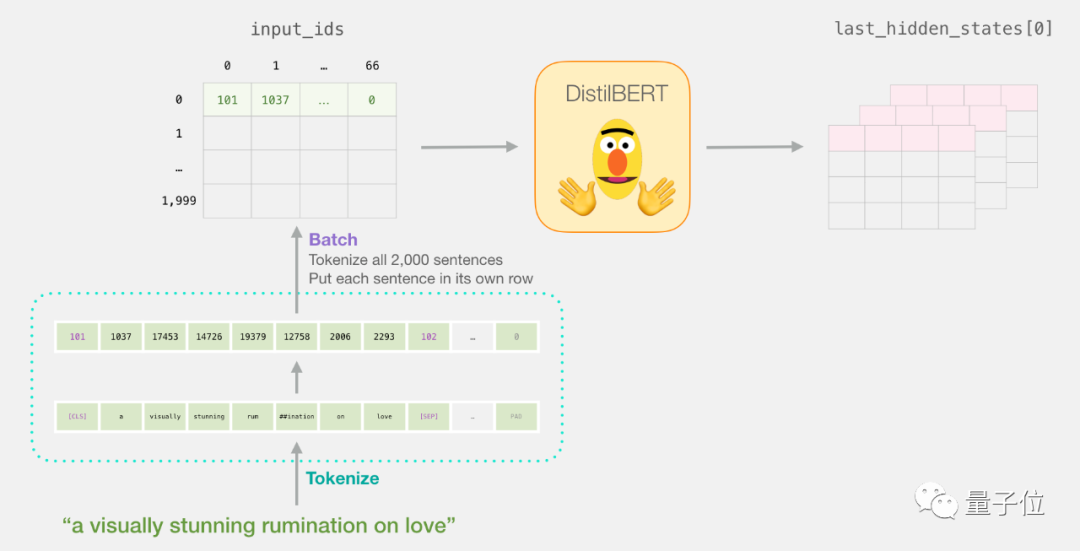
Extracting Important Parts
For sentence classification, we are only interested in the output of BERT’s [CLS] token, so we only need to extract the important part.
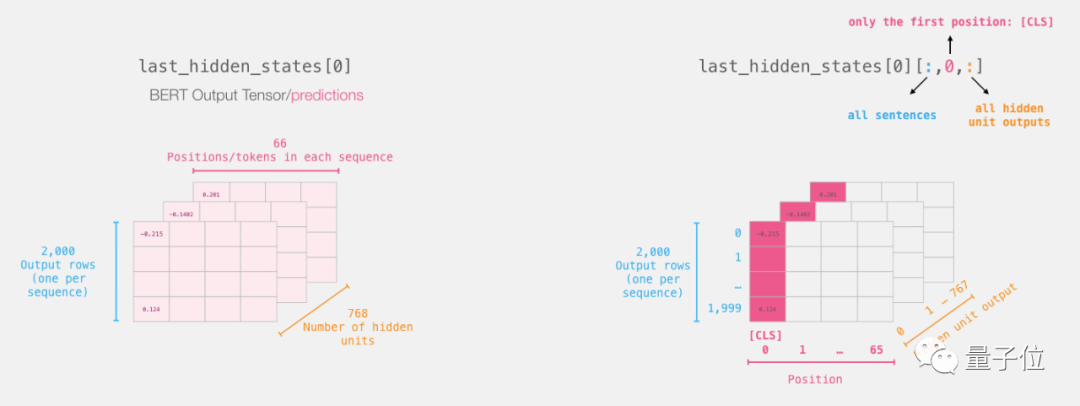
Here is how to extract the 2D tensor we need from the 3D tensor:
# Slice the output for the first position for all the sequences, take all hidden unit outputs
features = last_hidden_states[0][:,0,:].numpy()The current features are a 2D numpy array containing the sentence embeddings for all sentences in our dataset.
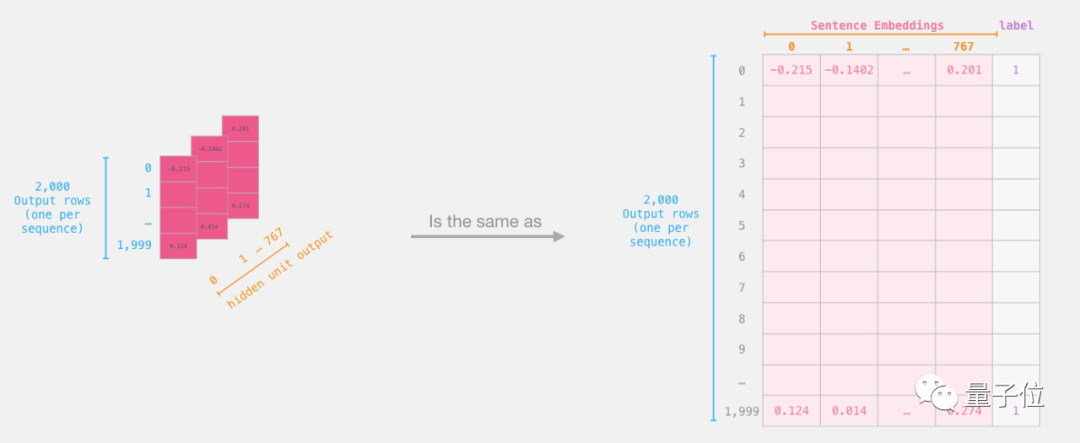
Logistic Regression Dataset
Now that we have the output from BERT, the logistic regression model has already been trained. The 798 columns in the figure are features, and the labels are from the initial dataset.
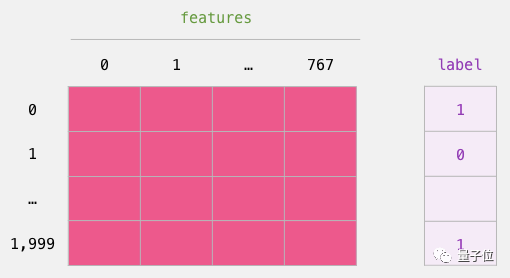
After completing traditional machine learning training and testing, we can train the logistic regression model again.
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)Split the data into training and testing sets:
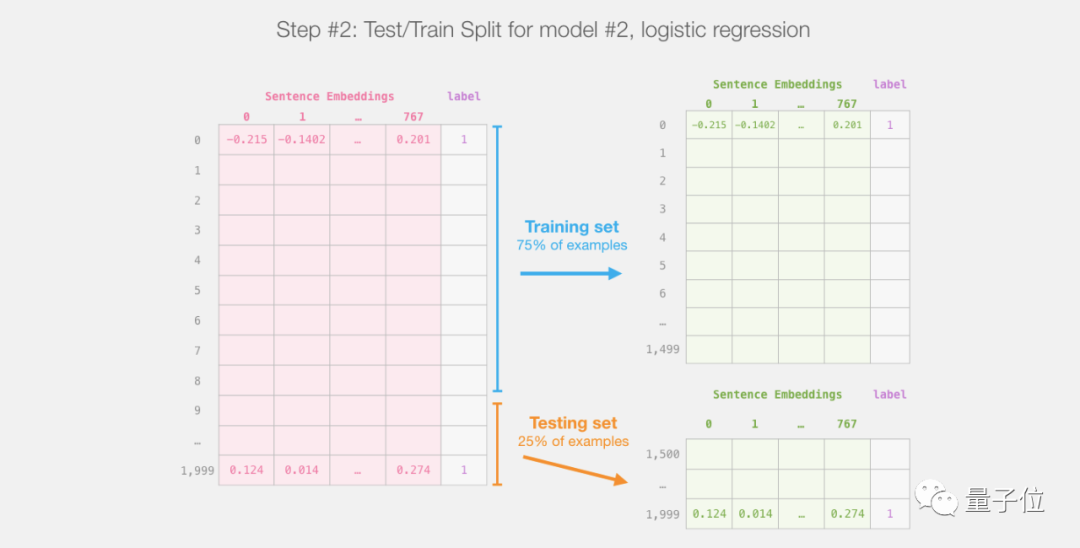
Next, train the logistic regression model on the training set:
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)Now that the model is trained, score it using the test set:
lr_clf.score(test_features, test_labels)The resulting model accuracy is 81%.
Score Benchmarks
As a reference, the current highest accuracy score for this dataset is 96.8.
In this task, DistilBERT can be trained to improve the score, a process called fine-tuning, which can update BERT’s weights to achieve better sentence classification.
Fine-tuned DistilBERT can achieve an accuracy of 90.7, and the complete BERT model can reach an accuracy of 94.9.
Links
A Visual Guide to Using BERT for the First Time: https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/
Code: https://github.com/jalammar/jalammar.github.io/blob/master/notebooks/bert/A_Visual_Notebook_to_Using_BERT_for_the_First_Time.ipynb
Colab: https://colab.research.google.com/github/jalammar/jalammar.github.io/blob/master/notebooks/bert/A_Visual_Notebook_to_Using_BERT_for_the_First_Time.ipynb
DistilBERT: https://medium.com/huggingface/distilbert-8cf3380435b5
Recommended Reading:
Discussing Position Representations in Transformer-based Models
Geometric Interpretation of Systems of Equations [MIT Linear Algebra First Class PDF Download]
PaddlePaddle Practical NLP Classic Model BiGRU + CRF Detailed Explanation
