Reprinted from Quantum Bit
Xiao Xiao from Aofeisi Quantum Bit Report | WeChat Official Account QbitAI
What are the differences between Longformer, a model capable of efficiently processing long texts, and BigBird, which is considered an “upgraded version” of the Transformer model?
What do the various other variants of the Transformer model (X-former) look like, and what new applications do they have?
Due to the rapid development of Transformer models, which change day by day, even if you come back to study after a while, there may already be many new models.
The Transformer model is a classic NLP model launched by Google in 2017 (BERT uses Transformer).
In machine translation tasks, the Transformer outperforms RNN and CNN, achieving good results with just an encoder/decoder, allowing for efficient parallelization.
The good news is that there is a “latest trend” article on Transformer models that focuses on improvements to the self-attention mechanism (Self-attention) in new Transformer models and compares these models.
Additionally, it covers the latest applications of these models across various fields such as NLP, computer vision, and reinforcement learning.
Standard Transformer Model
First, let’s take a look at what the standard Transformer model looks like.

The core part of the Transformer is the two black solid lines on the right, with the encoder (Encoder) on the left and the decoder (Decoder) on the right.
As can be seen, the encoder/decoder mainly consists of two modules: the feedforward neural network (the blue part in the image) and the attention mechanism (the magenta part in the image), with the decoder usually having an additional (cross) attention mechanism.
The most important part of the Transformer is the attention mechanism.
In simple terms, the application of the attention mechanism in image processing allows machines to “pay special attention to a certain part of the image like humans do”, just as we tend to “focus on” certain areas in a picture.

Among these, the self-attention mechanism is key to defining the features of the Transformer model, with one major challenge being its time complexity and space complexity.
Since the attention mechanism directly compares sequences (sequence) pairwise, it leads to a huge computational load (computational complexity becomes O(n²)).
Recently, a large number of papers have proposed new “variants” of the Transformer, all aimed at improving the efficiency of the model, but if one looks at them individually, it can be quite overwhelming.
To this end, Google AI researchers have specifically compiled a paper on the development of Transformer models, explaining their origins in detail.
Transformer Models After “Variants”
2 Classification Methods
By usage method, Transformer models can be classified into the following 3 categories:
Encoder-only: can be used for classification; Decoder-only: can be used for language modeling; Encoder-Decoder: can be used for machine translation.
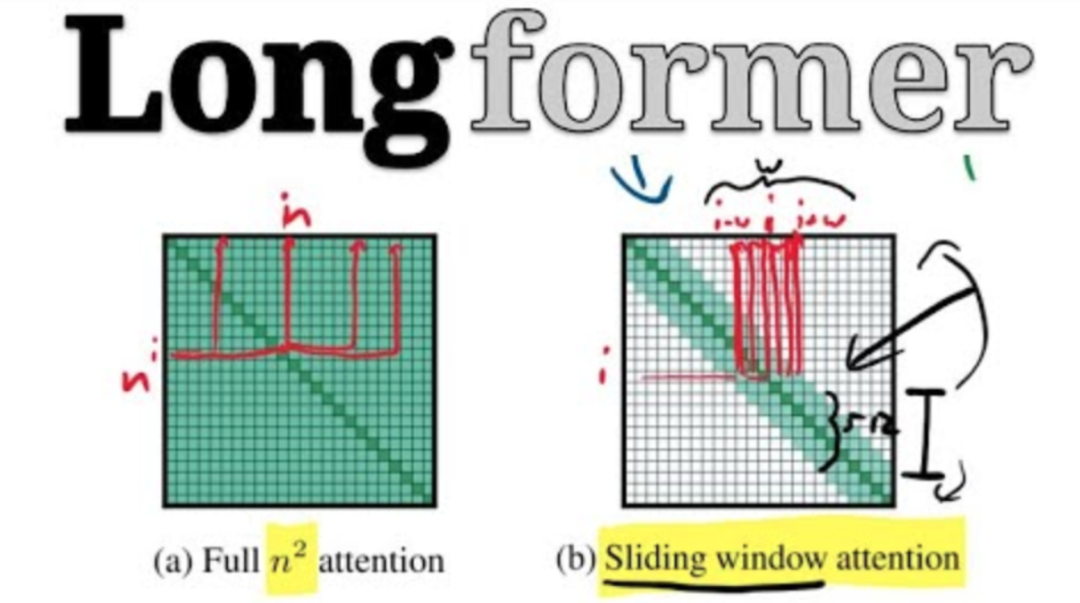
However, if classified by the principles of efficiency improvement, that is, by “efficient methods”, these “variants” of Transformer models can be divided into the following categories:
Fixed Patterns: Limit the visual field to fixed predefined patterns, such as local windows and fixed stride blocks, to simplify the attention matrix;
Learnable Patterns: Learn access patterns in a data-driven manner, with the key being to determine token relevance.
Memory: Utilize memory modules that can access multiple tokens at once, such as global memory.
Low Rank: Improve efficiency by utilizing low-rank approximations of the self-attention matrix.
Kernels: Improve efficiency through kernelization, where the kernel is an approximation of the attention matrix, which can be seen as a type of low-rank method.
Recurrence: Utilize recursion to connect the various blocks in matrix partitioning methods to ultimately improve efficiency.
As can be seen, recent research related to Transformers is clearly categorized in the image above.
After understanding the classification methods, the next step is to explore the various variants of the Transformer model.
17 Classic “X-former”
1. Memory Compressed Transformer (2018)
This was one of the early attempts to enable the Transformer to better handle long sequences, mainly modifying two parts: range attention and memory compressed attention.
The former aims to divide the input sequence into modules of similar lengths and run the self-attention mechanism within each part, ensuring that the attention cost for each part remains unchanged, allowing the number of activations to scale linearly with input length.
The latter uses dilated convolutions to reduce the size of the attention matrix and the computational load of attention, with the amount reduced depending on the dilation rate.
2. Image Transformer (2018)
This variant of the Transformer is inspired by convolutional neural networks, focusing on local attention ranges, i.e., limiting the receptive field to local areas, mainly with two schemes: one-dimensional local attention and two-dimensional local attention.

However, this model has a limitation: it sacrifices global receptive fields to reduce storage and computational costs.
3. Set Transformer (2019)
This model was born to solve a specific application scenario: the input is a set of features, and the output is a function of this set of features.

It utilizes sparse Gaussian processes to reduce the attention complexity from quadratic to linear based on input set size.
4. Sparse Transformer (2019)
The key idea of this model is to compute attention only on a small number of sparse data pairs, simplifying the dense attention matrix to a sparse version.
However, this model has hardware requirements, needing custom GPU kernels and cannot be used directly on other hardware such as TPUs.
5. Axial Transformer (2019)

This model mainly applies multiple attention mechanisms along a single axis of the input tensor, with each attention mixing information along a specific axis, keeping information along other axes independent.
Since the length of any single axis is usually much smaller than the total number of elements, this model can significantly save computation and memory.
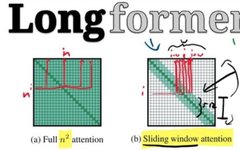
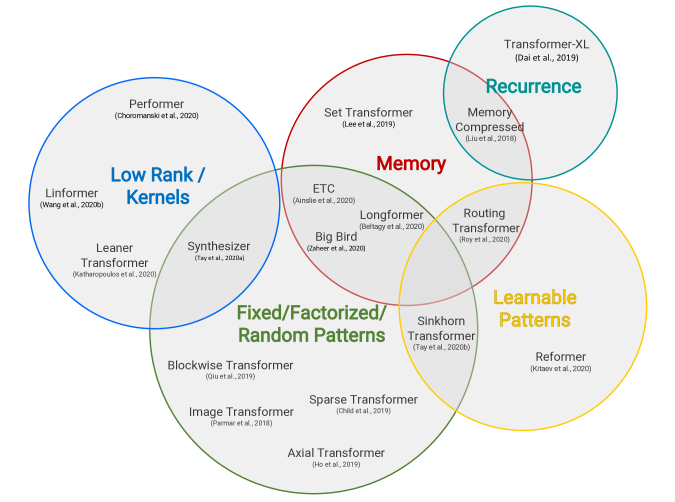
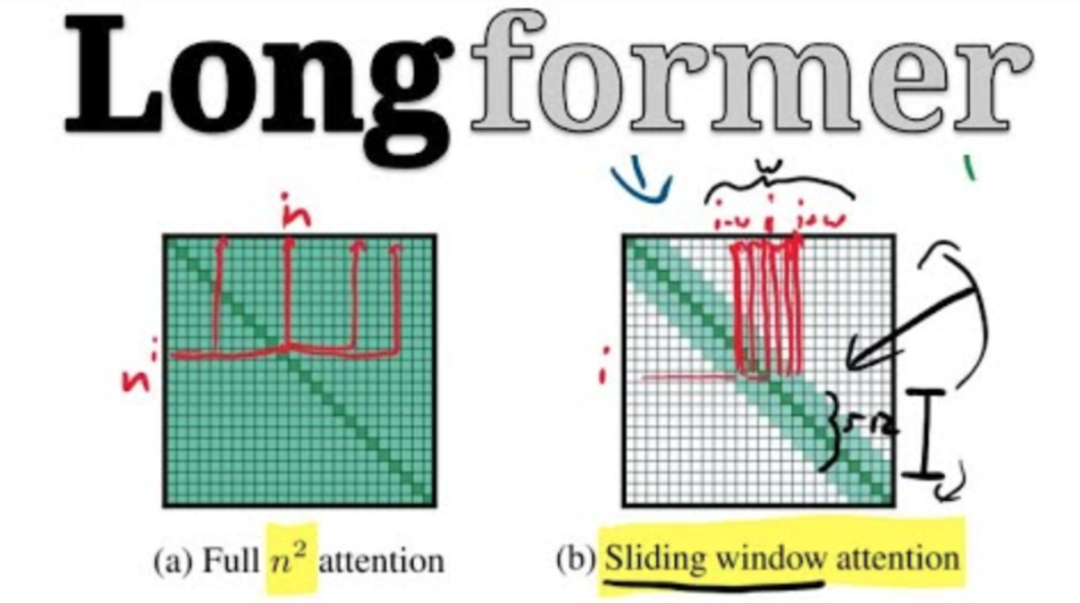
6. Longformer (2020)
A variant of Sparse Transformer, it achieves better long-range coverage by leaving gaps in the attention pattern and increasing the receptive field.
In classification tasks, Longformer uses a global token that can access all input sequences (e.g., CLS token).
7. Extended Transformer Construction (2020)
Also a variant of Sparse Transformer, it introduces a new global-local attention mechanism similar to Longformer in introducing global tokens.
However, due to the inability to compute causal masks, ETC cannot be used for autoregressive decoding.
8. BigBird (2020)
Like Longformer, it also uses global memory, but it has a unique “internal transformer construction (ITC)”, where the global memory is expanded to include tokens in the sequence rather than simple parameterized memory.
However, like ETC, BigBird also cannot be used for autoregressive decoding.
9. Routing Transformer (2020)
Proposed a clustering-based attention mechanism that learns attention sparsity in a data-driven manner. To ensure a similar number of tokens in clusters, the model initializes clustering and calculates the distance of each token from the cluster centroid.
10. Reformer (2020)
An attention model based on Locality-Sensitive Hashing (LSH), it introduces reversible transformer layers that help further reduce memory usage.
The key idea of the model is that nearby vectors should obtain similar hash values, while distant vectors should not, hence the term “locality-sensitive”.
11. Sinkhorn Transformer (2020)
This model belongs to the block model, reordering input keys and values in blocks and applying a block-based local attention mechanism to learn sparse patterns.
12. Linformer (2020)
This is an efficient transformer model based on low-rank self-attention mechanisms, mainly performing low-rank projections along the length dimension, mixing sequence information by dimension in a single transformation.
13. Linear Transformer (2020)
This model reduces the complexity of self-attention from quadratic to linear by using kernel-based self-attention mechanisms and the associativity of matrix products.
It has been shown to improve inference speed by up to three orders of magnitude while maintaining predictive performance.
14. Performer (2020)
This model utilizes orthogonal random features (ORF), employing an approximate method to avoid storing and computing the attention matrix.
15. Synthesizer models (2020)
This model studies the role of modulation in self-attention mechanisms, synthesizing a self-attention module that approximates the attention weights.
16. Transformer-XL (2020)
This model links adjacent parts using a recursive mechanism. The block-based recursion can be seen as an orthogonal approach to the other discussed techniques, as it does not explicitly use a sparse-dense self-attention matrix.
17. Compressive Transformers (2020)
This model is an extension of Transformer-XL, but unlike Transformer-XL, which discards past activations while moving across segments, its key idea is to maintain fine-grained memory of past segment activations.
Overall, the parameter counts of these classic models are as follows:
For more detailed interpretations (including specific model parameters, etc.) and predictions about the future trends of Transformers, you can check the full paper through the link below.
Author Introduction

The first author Yi Tay holds both a master’s and a PhD in computer science from the National University of Singapore.
Currently, Yi Tay is conducting research at Google AI, mainly focusing on natural language processing and machine learning.
Link
Paper Link:https://www.arxiv-vanity.com/papers/2009.06732
— End —
