
This article will explain the essence of pre-training principles, and applications in three aspects, helping you understand model pre-training Pre-training.

Pre-training
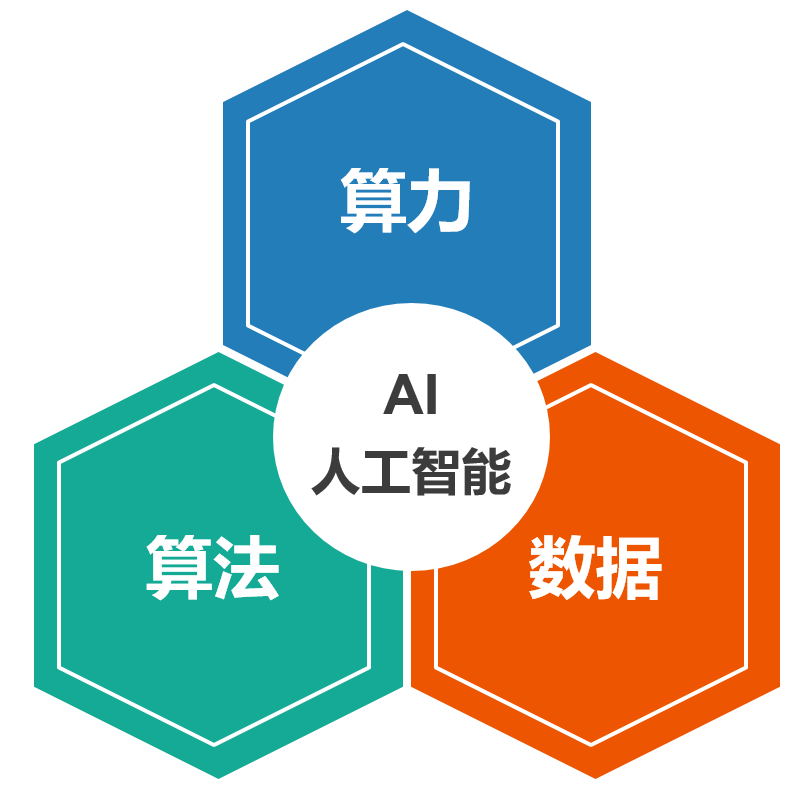
1.Essence of Pre-training
-
Training Set: Used to train the model, i.e., to adjust the model parameters to minimize prediction errors.
-
Validation Set: Used to adjust hyperparameters (such as learning rate, network structure, etc.) during training, as well as model selection (e.g., choosing which iteration of the model to use as the final model).
-
Test Set: Used to evaluate model performance after training is complete, providing an unbiased estimate of the model’s generalization ability.
-
Training Set: Students learn knowledge in class.
-
Validation Set: Exercises after class help students consolidate and correct the knowledge learned.
-
Test Set: The final exam tests the effectiveness of the students’ learning.

-
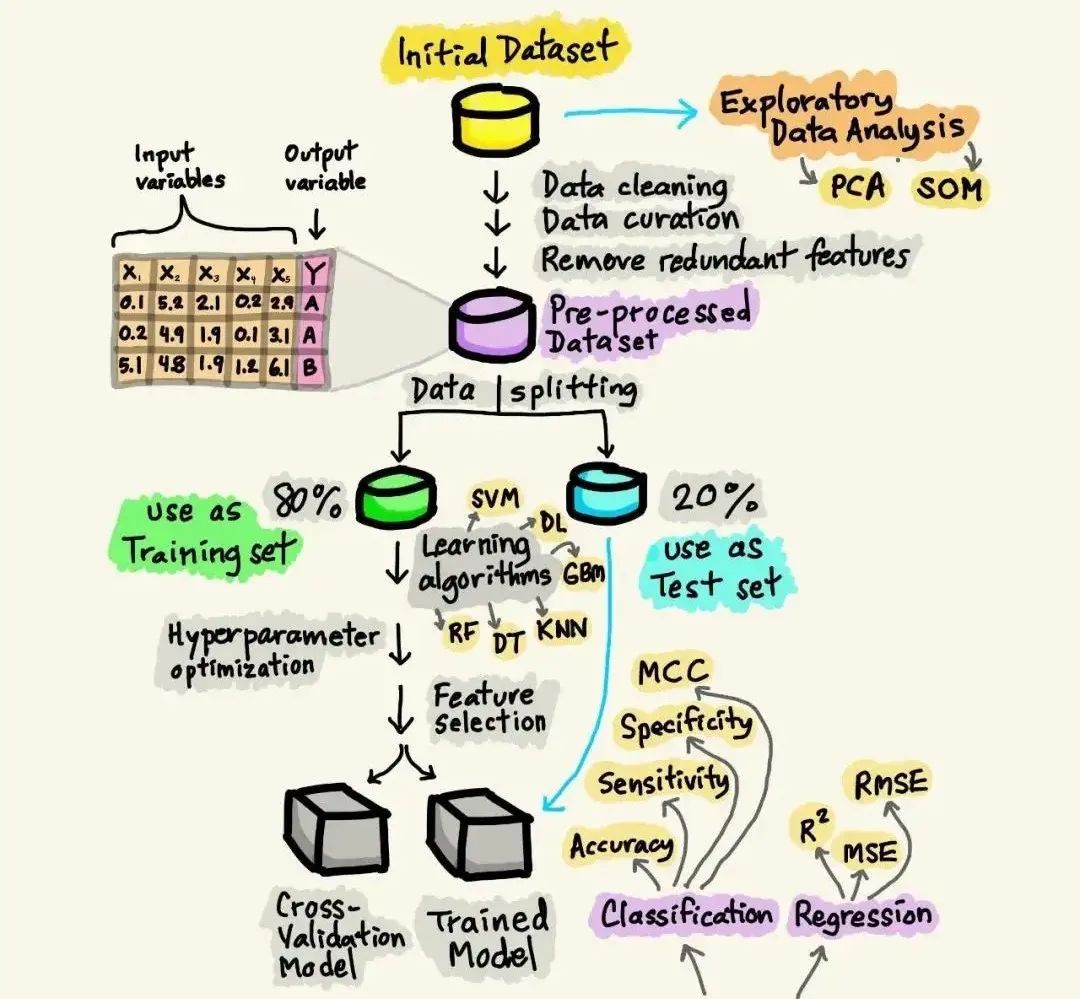
Parameter Initialization: The parameters of the neural network (including weights and biases) are randomly initialized before training begins.
-
Forward Propagation: During training, input data is propagated through the neural network to compute the model’s output. This process involves linearly combining the input data with the weights and biases of each layer, then applying an activation function to introduce non-linearity.
-
Calculate Loss: After obtaining the model’s output, the loss (or error) between the output and the true labels is calculated. The choice of loss function depends on the specific task; for example, mean squared error is commonly used for regression tasks, while cross-entropy loss is often used for classification tasks.
-
Backpropagation: Next, the backpropagation algorithm is used to compute the gradient of the loss function with respect to the model parameters. This process involves calculating the partial derivatives of the loss with respect to the parameters layer by layer, starting from the output layer and propagating this gradient information back to the input layer.
-
Parameter Update: After obtaining the gradients, optimization algorithms (such as stochastic gradient descent (SGD), Adam, RMSprop, etc.) are used to update the model parameters. The optimization algorithm adjusts the model parameters based on the computed gradients to minimize the loss function.
-
Iterative Training: The above steps (from forward propagation to parameter update) are repeated until the model’s performance on the validation set reaches a satisfactory level or the preset number of training epochs is reached.
-
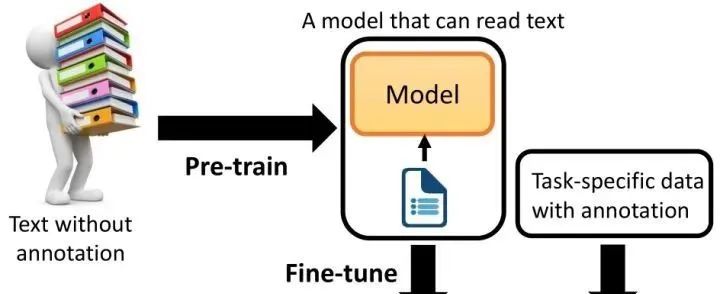
Data Scarcity: In real-world applications, collecting and labeling large amounts of data is often a time-consuming and expensive task. Especially in certain specialized fields, such as medical image recognition or specific text classification, acquiring labeled data is particularly challenging. Pre-training techniques enable models to learn general features from large amounts of unlabeled data, thus reducing reliance on labeled data.This allows for training well-performing models even on limited datasets.
-
Prior Knowledge Issue: In deep learning, models usually start learning from randomly initialized parameters. However, for many tasks, having some basic prior knowledge or common sense can be more helpful. Pre-trained models have learned many useful prior knowledge, such as grammatical rules of language, underlying visual features, etc., through training on large-scale datasets.This prior knowledge provides strong support for the model’s learning in new tasks.
-
Transfer Learning Issue: Transfer learning refers to the process of transferring knowledge learned from one task to another related task. Pre-trained models have learned general features from large amounts of data, which are shared across many tasks. Thus, by fine-tuning pre-trained models, they can be quickly adapted to new tasks, achieving knowledge transfer. This transfer learning approach not only improves the model’s performance on new tasks but also significantly shortens training time.
2. Principles of Pre-training
Pre-training Techniques: Pre-training is the initial stage of learning for language models. During pre-training, the model is exposed to a large amount of unlabeled text data, such as books, articles, and websites. The goal is to capture the underlying patterns, structures, and semantic knowledge present in the text corpus.
-
Unsupervised Learning:Pre-training is typically an unsupervised learning process, where the model learns from unlabeled text data without explicit guidance or labels.
-
Masked Language Modeling:Models are trained to predict missing or masked words in sentences, learning contextual relationships and capturing language patterns.
-
Transformer Architecture:Pre-training typically uses a transformer-based architecture, which excels at capturing long-range dependencies and contextual information.
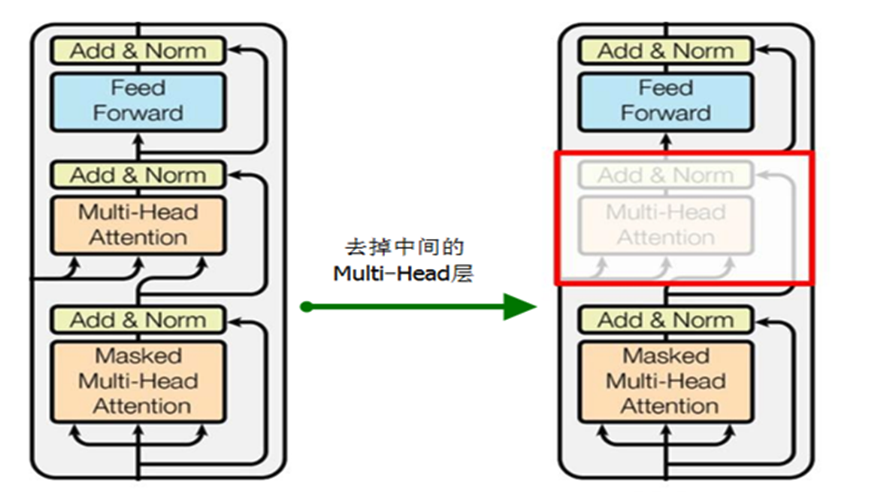
Principles of Pre-training:Based on the transformer as a feature extractor, a suitable model structure is selected, and through a self-supervised learning task, the transformer is forced to learn language knowledge from a vast amount of unlabeled free text.
As shown in the figure, the left side is the decoder of the transformer model, and the right side is the pre-training architecture of the large language model.
3. Applications of Pre-training