
Introduction
In recent years, deep learning has made tremendous progress in the field of Natural Language Processing (NLP), and the Transformer model is undoubtedly one of the best. Since the Google research team proposed the Transformer model in their paper “Attention is All You Need” in 2017, it has become the cornerstone for many NLP tasks such as machine translation, text generation, and language understanding. This article will help you understand the working principles of the Transformer model through visual illustrations.
Overview of the Transformer Model
The core idea of the Transformer model is the Self-Attention Mechanism, which allows the model to process all words in the input sequence simultaneously, unlike traditional Recurrent Neural Networks (RNNs) that need to process sequentially. This capability of parallel processing greatly improves the training speed and performance of the model.

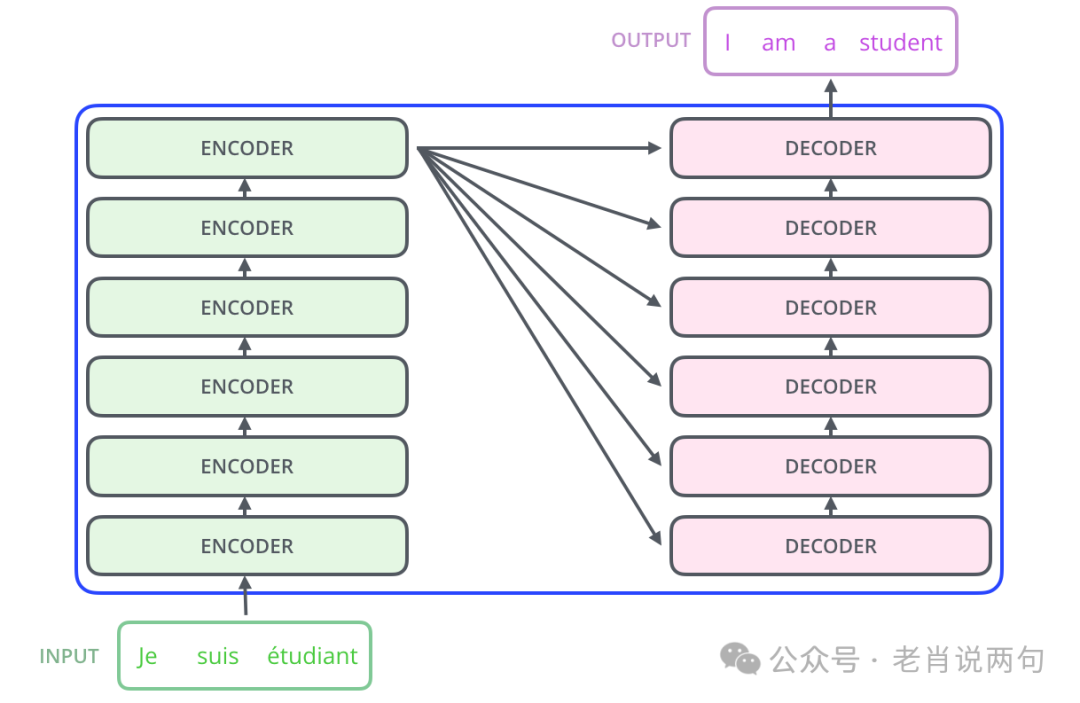
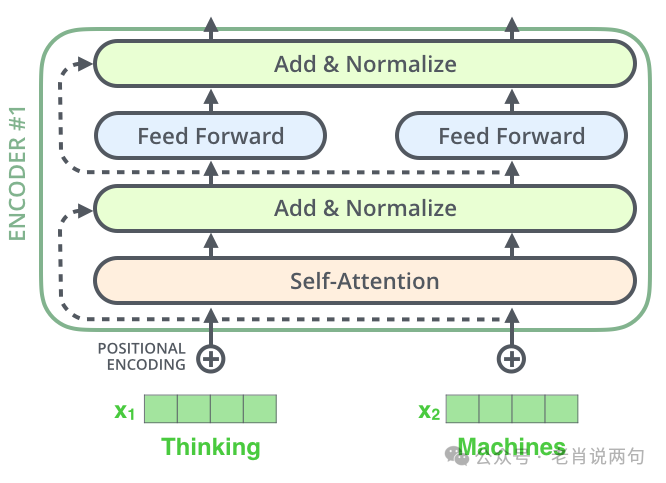
As shown in the figure above, the Transformer model consists of two main parts: Encoder and Decoder. The encoder is responsible for processing the input sequence, while the decoder is responsible for generating the output sequence.
Encoder
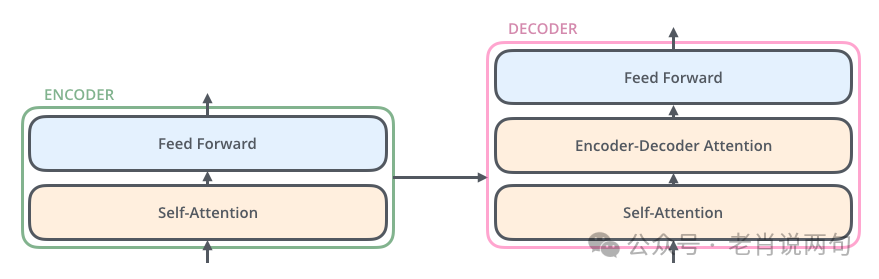
The encoder is composed of six identical layers, each of which contains two sub-layers: Self-Attention Layer and Feed-Forward Neural Network.
-
1. Self-Attention Layer: 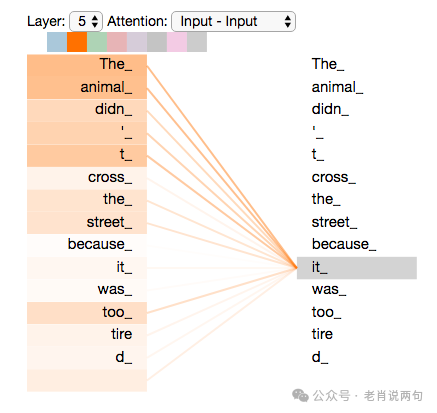
Self-Attention Mechanism
-
• Objective: Allow the model to focus on relevant information from other words in the input sequence when processing a specific word. -
• Working Principle: -
• For each word, generate three vectors: Query Vector, Key Vector, and Value Vector. -
• Calculate the dot product of the query vector with all key vectors to obtain the attention scores for each word. -
• Normalize the attention scores using softmax, then multiply and sum them with the value vectors to obtain the final output vector.
-
• Further process the output of the self-attention layer, with each position’s vector passing through the same fully connected network.
Decoder
The decoder is also composed of six identical layers, but each layer contains three sub-layers: Self-Attention Layer, Encoder-Decoder Attention Layer, and Feed-Forward Neural Network.
-
1. Self-Attention Layer:
-
• Similar to the self-attention layer in the encoder, but it is important to note that the self-attention layer in the decoder can only focus on the already generated parts of the current output sequence to maintain the order of the generation process.
-
• This layer allows the decoder to focus on the information output by the encoder, so that it can refer to the content of the input sequence when generating outputs. -
• Its working principle is similar to that of the self-attention layer, but the query vectors come from the decoder, while the key and value vectors come from the encoder.
-
• Similar to the feed-forward neural network in the encoder, further processing the output of the attention layer.
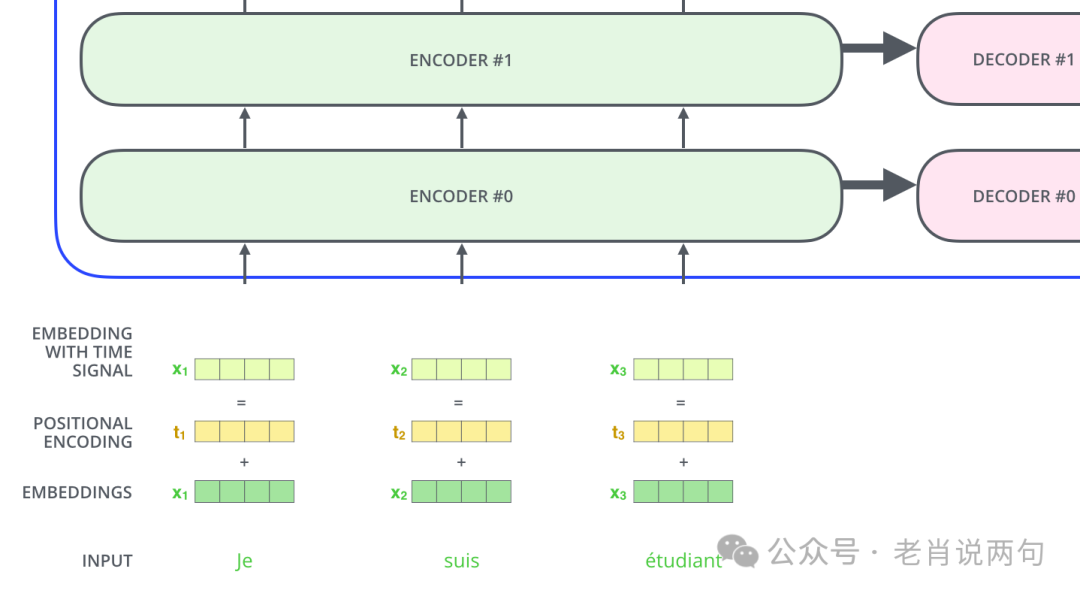
Positional Encoding
Since the Transformer model does not have built-in sequential information, positional encoding is needed to provide the model with information about the position of words in the sequence. Positional encoding is a vector of the same dimension as the word embedding vector, whose values follow a specific pattern, allowing the model to learn the relative positions of words.
Residual Connections and Layer Normalization
To alleviate the training difficulty of deep networks, the Transformer model incorporates residual connections and layer normalization in each sub-layer. Specifically, the output of each sub-layer is added to the input and then layer normalized.
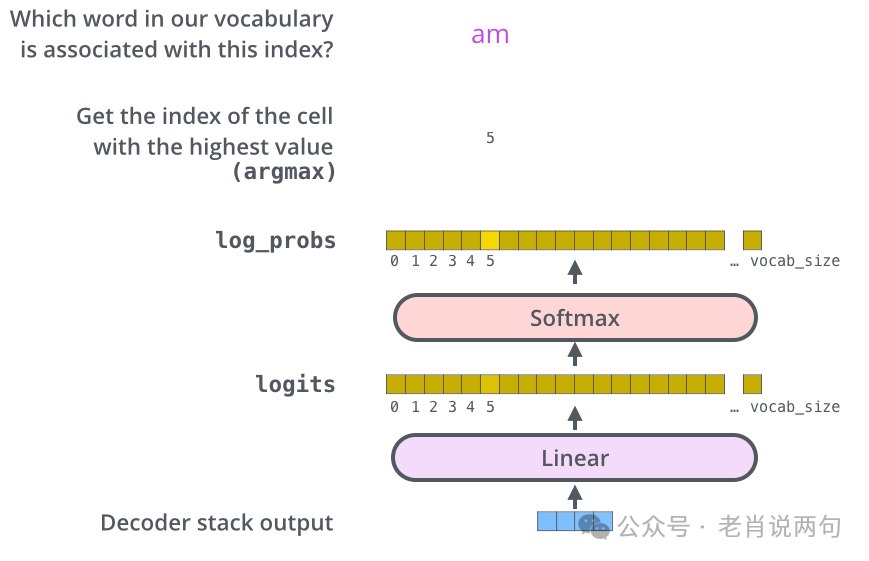
Output Layer
The output of the decoder stack is a vector, which is mapped to a larger vector called the logits vector through a fully connected layer. The softmax layer then converts the logits vector into a probability distribution, and the model selects the word with the highest probability as the output for the current time step.
Training Process
During the training process, the model compares its output with the actual labels, calculates the loss function, and uses the backpropagation algorithm to update the model parameters. A common loss function is the cross-entropy loss.
Conclusion
The Transformer model significantly enhances the performance of NLP tasks through the self-attention mechanism and parallel processing capabilities. Its simple yet powerful architectural design lays the foundation for many subsequent models (such as BERT, GPT, etc.). I hope that through the illustrations and explanations in this article, you can gain a clearer understanding of the Transformer model.
If you are interested in the Transformer model, here are some recommended resources:
-
• Read the original paper: “Attention is All You Need” -
• Watch Łukasz Kaiser’s explanatory video -
• Explore the Tensor2Tensor code repository
I hope these resources can help you delve deeper into the Transformer model and apply this powerful tool in your projects.
I hope this article helps you understand the Transformer model! If you have any questions or suggestions, feel free to leave a comment.