
MLNLP ( Machine Learning Algorithms and Natural Language Processing ) is a well-known natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and industry researchers.The community’s vision is to promote communication between the academic and industrial circles of natural language processing and machine learning, especially for beginners.
This article is reproduced from | PaperWeekly
Author | serendipity
Affiliation | Tongji University
Research Direction | Pedestrian Search
As of 2022, Mixed Precision (Automatically Mixed Precision, AMP) training has become a standard tool for practitioners, requiring only a few lines of code to halve memory usage and double training speed.
AMP technology was proposed by the Baidu and NVIDIA teams in 2017 (Mixed Precision Training [1]), and this achievement was published at ICLR. Before PyTorch 1.6, everyone used NVIDIA’s apex [2] library to implement AMP training. After version 1.6, PyTorch comes with AMP by default.This article explains in depth how to use AMP in PyTorch, the principles of AMP, and the code implementation of AMP.
1
『How to Use AMP in PyTorch』
If you are a beginner and just want to try using AMP, you only need to modify your training code as follows.
output = net(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()as follows.
with torch.cuda.amp.autocast():
output = net(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()If the GPU supports Tensor Core (Volta, Turing, Ampere architectures), AMP will significantly reduce memory consumption and speed up training. For other types of GPUs, it can still reduce memory usage, but training speed may slow down.
2
『Principles of AMP』
2.1 What is FP16
Half-precision floating point (FP16) is a binary floating-point data type used by computers, stored in 2 bytes (16 bits), with a representation range. PyTorch defaults to using single-precision floating point (FP32) for network model calculations and weight storage. FP32 is stored in 4 bytes (32 bits) in memory, with a much larger representation range than FP16.
Additionally, floating-point numbers have a fascinating characteristic: when two numbers differ too much, their sum becomes ineffective, also known as rounding error [3].
Here is a code example:
>>> # FP32 addition has no issues.
>>> torch.tensor(2**-3) + torch.tensor(2**-14)
tensor(0.1251)
>>> # FP16 addition, smaller numbers will be ignored. Because in [2**-3, 2**-2], the fixed interval represented by FP16 is 2**-13.
>>> # This means the next number larger than 2**-3 is 2**-3 + 2**-13, so adding 2**-14 is the same as not adding.
>>> # half() converts FP32 to FP16.
>>> torch.tensor(2**-3).half() + torch.tensor(2**-14).half()
tensor(0.1250, dtype=torch.float16)
>>> # Replacing 2**-14 with 2**-13 works.
>>> torch.tensor(2**-3).half() + torch.tensor(2**-13).half()
tensor(0.1251, dtype=torch.float16)2.2 Why Use FP16
By replacing FP32 with FP16 during training, we gain the following two advantages:1. Reduced memory usage: FP16’s memory usage is only half that of FP32, allowing for larger batch sizes;2. Accelerated training: Using FP16 can nearly double the training speed.
2.3 Why Using Only FP16 Can Cause Problems
If we simply convert model weights and inputs from FP32 to FP16, while speed may double, the model’s accuracy will be severely impacted. The reasons are as follows:Overflow/Underflow: FP16’s representation range is small; numbers exceeding will overflow to inf, while numbers below will underflow to 0. Underflow is more common because, in the later stages of network training, model gradients are often very small, even smaller than FP16’s lower limit, causing gradient values to become 0, and model parameters cannot be updated. The following image shows the gradient statistics of the SSD network during training, with 67% of values underflowing to 0.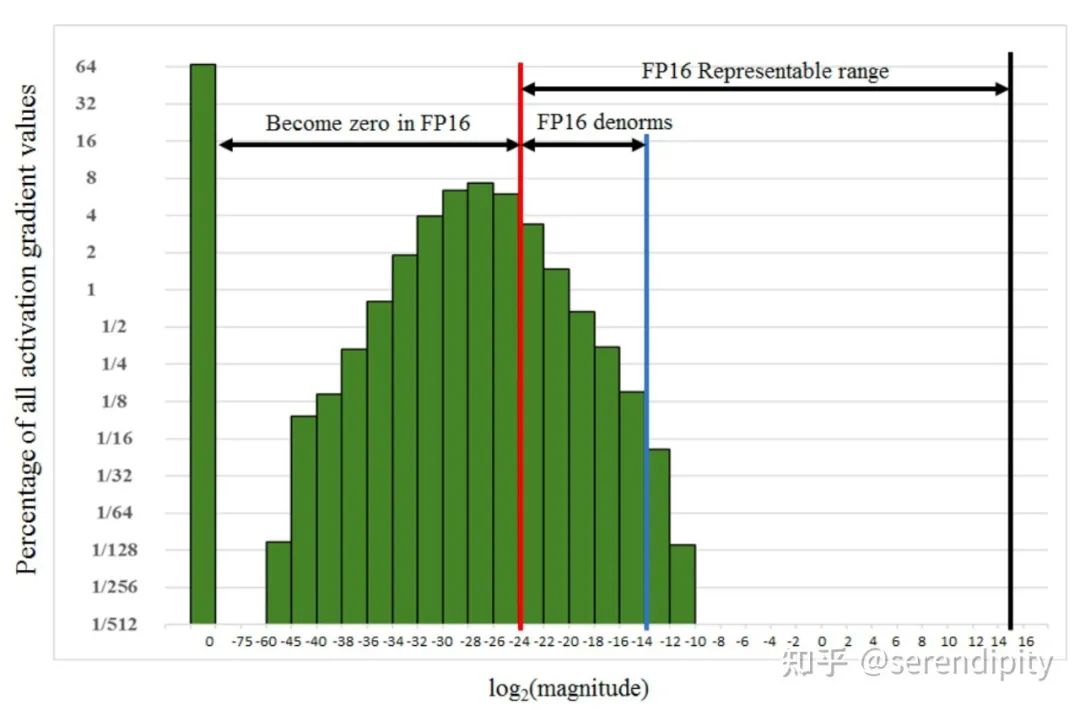 Rounding Error: Even if gradients do not overflow/underflow, if the gradient values and model parameter values differ too much, rounding error issues can occur. Assuming model parameter weight, learning rate, gradient gradient, weight weight gradient.
Rounding Error: Even if gradients do not overflow/underflow, if the gradient values and model parameter values differ too much, rounding error issues can occur. Assuming model parameter weight, learning rate, gradient gradient, weight weight gradient.
2.4 Solutions
Loss Scaling
To solve the underflow issue, the paper scales the computed loss value (scale), and due to the chain rule, scaling the loss will affect each gradient. The scaled gradients will then shift into FP16’s effective range. This way, we can store gradients in FP16 without overflowing. Furthermore, before updating, we need to first convert the scaled gradients back to FP32, then unscale the gradients.Note that it is essential to convert to FP32 first; otherwise, unscale will still underflow.The scaling factor (loss_scale) is generally automatically determined by the framework; as long as inf or nan does not occur, the larger the loss_scale, the better. Because as training progresses, the network gradients will become smaller, a larger loss_scale can make better use of FP16’s representation range.
FP32 Weight Backup
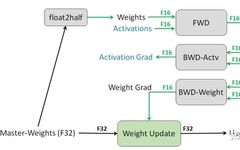
To implement FP16 training, we need to convert model weights and input data to FP16, resulting in FP16 gradients during backpropagation. If we directly update at this point, due to the value of gradient * learning rate being often small, the difference from model weights may be significant, potentially causing rounding error issues.Therefore, the solution is to store model weights, activation values, gradients in FP16 while maintaining a backup of FP32 model weights for updates. After obtaining FP16 gradients during backpropagation, convert them to FP32 and unscale, and finally update the FP32 model weights. Since the entire update process occurs in an FP32 environment, rounding errors will not occur.FP32 weight backup resolves the rounding error issue during backpropagation.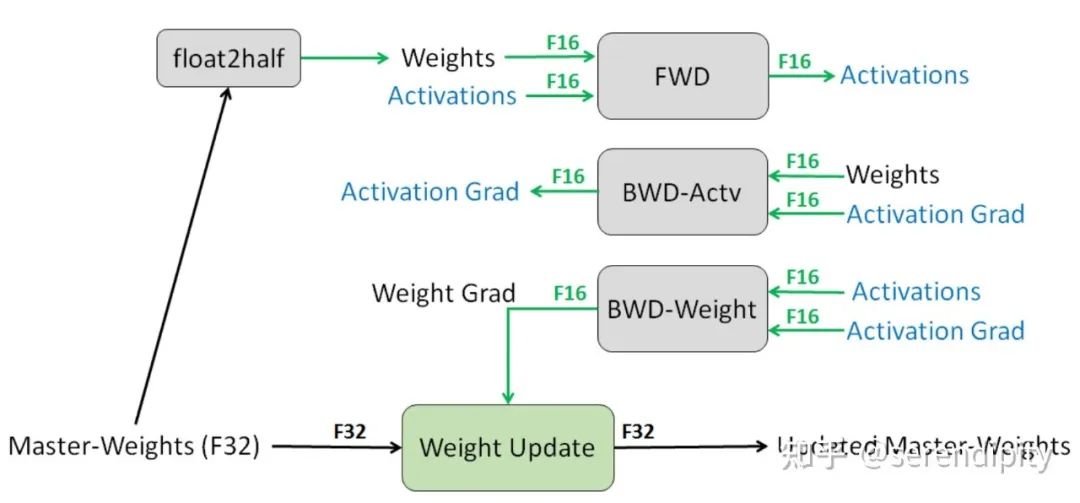
Blacklist
For modules that run unstably in FP16 environments, we will add them to the blacklist, forcing them to run at FP32 precision. For example, the BN layer, which requires batch mean calculation, should run in FP32; otherwise, rounding errors will occur. Some functions that require high algorithm precision, such as torch.acos(), should also run in FP32. The blacklist in the paper only includes the BN layer.To ensure that blacklisted modules run in an FP32 environment: taking the BN layer as an example, convert its weights to FP32 and its inputs from FP16 to FP32, ensuring that the entire module runs in FP32.The blacklist resolves arithmetic instability issues for certain functions in FP16 environments.
Tensor Core
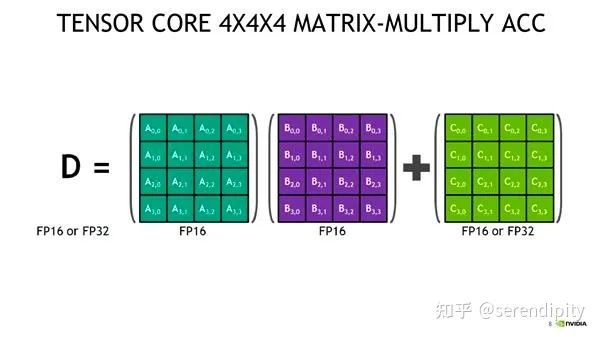 Tensor Core allows FP16 to perform matrix multiplication and then accumulate the results into the FP32 matrix. This way, we can enjoy the high-speed matrix multiplication of FP16 while utilizing FP32 to eliminate rounding errors.It is unclear how Tensor Core is applied in AMP. Some say Tensor Core helps us utilize FP16 gradients to update FP32 model weights. However, after reading the apex source code, I found that FP16 gradients are first converted to FP32 before updates, so weight updates are unrelated to Tensor Core. I will return to supplement this once I understand it better.
Tensor Core allows FP16 to perform matrix multiplication and then accumulate the results into the FP32 matrix. This way, we can enjoy the high-speed matrix multiplication of FP16 while utilizing FP32 to eliminate rounding errors.It is unclear how Tensor Core is applied in AMP. Some say Tensor Core helps us utilize FP16 gradients to update FP32 model weights. However, after reading the apex source code, I found that FP16 gradients are first converted to FP32 before updates, so weight updates are unrelated to Tensor Core. I will return to supplement this once I understand it better.
2.5 Some Thoughts
Actually, mixing FP16 and FP32 is an inevitable result for several reasons:1. In the later stages of network training, gradient values are very small, which may lead to FP16 underflow. If FP32 is not used, even if we temporarily avoid this issue through scaling operations, the unscale operation during weight updates will still cause gradient underflow;2. Continuing from point 1, even if gradients can be represented in FP16, gradient * learning rate may still underflow. Therefore, the weight update operation must still run in FP32;3. Continuing from point 2, even if gradient * learning rate does not underflow, its value is also very small relative to the weights themselves. weight + gradient * learning rate may encounter rounding error issues;4. Continuing from point 3, even if weight + gradient * learning rate does not encounter rounding errors, some operators are also unstable in FP16, such as BN,torch.acos, etc.
3
『Understanding NVIDIA Apex Library Code』
First, let’s introduce the various opt-level: o1, o2, o3, o4. Note that here it is the letter “o”, not the number “0”.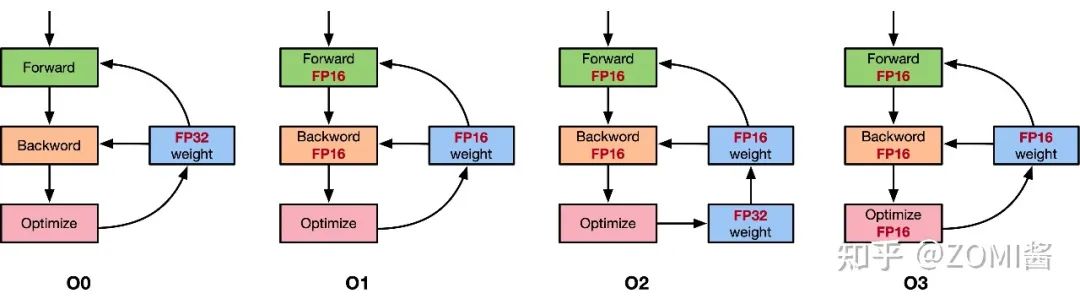 Image from: The Most Comprehensive – Principles of Mixed Precision Traininghttps://zhuanlan.zhihu.com/p/441591808o0 is pure FP32, used as a precision baseline.o3 is pure FP16, used as a speed baseline. Focus on o1 and o2. The AMP strategy we discussed earlier is actually o2: except for the BN layer’s weights and inputs using FP32, all other model weights and inputs will be converted to FP16. Additionally, an FP32 weight backup will be created to perform update operations. Unlike o2, o1 does not require FP32 weight backup since o1 models are always FP32. Some readers might wonder, since model parameters are FP32, how can FP16 be used during training? The answer is that o1 establishes a whitelist and blacklist for PyTorch functions; for functions on the whitelist, FP16 is enforced, meaning their parameters are first converted to FP16 before executing the function. The blacklist enforces FP32.For example, nn.Linear has two weight parameters weight and bias, and input is input, with forward propagation calling torch.nn.functional.linear(input, weight, bias).o1 mode will convert input, weight, bias to FP16 format input_fp16, weight_fp16, bias_fp16, and then call the function torch.nn.functional.linear(input_fp16, weight_fp16, bias_fp16). This way, model parameters can be FP32 while still using FP16 to accelerate training.o1 has another detail: although whitelisted PyTorch functions run in FP16, the resulting gradients are FP32, so there is no need to manually convert them to FP32 before unscale; they can be unscaled directly.My personal guess is that PyTorch keeps the data type of each Tensor consistent with the data type of its gradients; although FP16 gradients are generated, because the weights are FP32, the framework will convert the gradients to FP32 as well.If o1 is FP16 + FP32, the more aggressive o2 is almost FP16 (mostly FP16). Generally, o1 is more stable, so it is advisable to choose o1 first, and then try o2 to see if there is a drop in accuracy; if not, use o2.
Image from: The Most Comprehensive – Principles of Mixed Precision Traininghttps://zhuanlan.zhihu.com/p/441591808o0 is pure FP32, used as a precision baseline.o3 is pure FP16, used as a speed baseline. Focus on o1 and o2. The AMP strategy we discussed earlier is actually o2: except for the BN layer’s weights and inputs using FP32, all other model weights and inputs will be converted to FP16. Additionally, an FP32 weight backup will be created to perform update operations. Unlike o2, o1 does not require FP32 weight backup since o1 models are always FP32. Some readers might wonder, since model parameters are FP32, how can FP16 be used during training? The answer is that o1 establishes a whitelist and blacklist for PyTorch functions; for functions on the whitelist, FP16 is enforced, meaning their parameters are first converted to FP16 before executing the function. The blacklist enforces FP32.For example, nn.Linear has two weight parameters weight and bias, and input is input, with forward propagation calling torch.nn.functional.linear(input, weight, bias).o1 mode will convert input, weight, bias to FP16 format input_fp16, weight_fp16, bias_fp16, and then call the function torch.nn.functional.linear(input_fp16, weight_fp16, bias_fp16). This way, model parameters can be FP32 while still using FP16 to accelerate training.o1 has another detail: although whitelisted PyTorch functions run in FP16, the resulting gradients are FP32, so there is no need to manually convert them to FP32 before unscale; they can be unscaled directly.My personal guess is that PyTorch keeps the data type of each Tensor consistent with the data type of its gradients; although FP16 gradients are generated, because the weights are FP32, the framework will convert the gradients to FP32 as well.If o1 is FP16 + FP32, the more aggressive o2 is almost FP16 (mostly FP16). Generally, o1 is more stable, so it is advisable to choose o1 first, and then try o2 to see if there is a drop in accuracy; if not, use o2.
3.1 Implementation of Apex’s o1
1. Wrap PyTorch built-in functions based on the whitelist and blacklist [4]. Whitelisted functions are enforced to run in FP16, blacklisted functions are enforced to run in FP32. Other functions are automatically determined based on parameter types; if all parameters are FP16, they run in FP16; if any parameter is FP32, they run in FP32. 2. Initialize loss_scale to a large value [5]. 3. For each iteration (a). Forward propagation: model weights are FP32, and operators are automatically selected based on the whitelist and blacklist. (b). Multiply loss by loss_scale [6] (c). Backward propagation: since model weights are FP32, even if functions run in FP16, FP32 gradients will be obtained.(d). Unscale gradients [7], i.e., divide by loss_scale (e). If inf or nan is detected [8]i. loss_scale /= 2 [9]ii. Skip this update [10](f). optimizer.step(), perform this update (g). If there are no inf or nan for 2000 consecutive iterations, then loss_scale *= 2 [11]
3.2 Implementation of Apex’s o2
1. Convert model weights to FP16 except for the BN layer [12], and wrap the forward function [13], converting its parameters to FP16;2. Maintain an FP32 model weight backup for updates [14];3. Initialize loss_scale to a large value [15];4. For each iteration (a). Forward propagation: except for the BN layer, model parts are FP16. (b). Multiply loss by loss_scale [16] (c). Backward propagation, obtaining FP16 gradients (d). Convert FP16 gradients to FP32 and unscale [17](e). If inf or nan is detected [18]i. loss_scale /= 2 [19]ii. Skip this update [20](f). optimizer.step(), perform this update (g). If there are no inf or nan for 2000 consecutive iterations, then loss_scale *= 2 [21]Additionally, it is recommended to read MMCV’s implementation of AMP’s o2 [22], as the code is clearer than apex. However, since I want to discuss both o1 and o2, I did not choose to interpret MMCV’s code; interested readers can further study it.References[1] https://arxiv.org/abs/1710.03740[2] https://github.com/NVIDIA/apex[3] https://en.wikipedia.org/wiki/Round-off_error#Addition[4] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/amp.py#L68[5] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L40[6] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/handle.py#L113[7] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/_process_optimizer.py#L123[8] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L202[9] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L207[10] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/handle.py#L128[11] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L213[12] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/_initialize.py#L179[13] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/_initialize.py#L194[14] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/_process_optimizer.py#L44[15] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L40[16] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/handle.py#L113[17] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L94[18] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L202[19] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L207[20] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/handle.py#L128[21] https://github.com/NVIDIA/apex/blob/1403c21acf87b0f2245278309071aef17d80c13b/apex/amp/scaler.py#L213[22] https://github.com/open-mmlab/mmcv/blob/f5425ab7611ab2376ddb478b57cb2f46f6054e13/mmcv/runner/hooks/optimizer.py#L344[23] https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html[24] https://pytorch.org/docs/stable/amp.html#autocast-op-reference[25] Must-have Tool for PyTorch | Speed Wins: Mixed Precision Acceleration Based on Apex[26] https://zhuanlan.zhihu.com/p/103685761[27] https://zhuanlan.zhihu.com/p/441591808Technical Community Invitation

△Long press to add the assistant
Scan the QR code to add the assistant’s WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply for joining the Natural Language Processing/PyTorch technical community
About Us
MLNLP Community ( Machine Learning Algorithms and Natural Language Processing ) is a grassroots academic community built by scholars in natural language processing from both domestic and international backgrounds. It has now developed into a well-known natural language processing community, including well-known brands such as 10,000-person top conference communication group, AI Selection, AI Talent Exchange, and AI Academic Exchange , aimed at promoting progress among academic and industrial circles in machine learning and natural language processing.The community provides an open communication platform for related practitioners’ further education, employment, and research. We welcome everyone to follow and join us.
