This article aims to introduce the Transformer model. Originally developed for machine translation, this model has since been widely applied in various fields such as computer recognition and multimodal tasks. The Transformer model introduces self-attention mechanisms and positional encoding, and its architecture mainly consists of an input part, an output part, and encoders and decoders. Among them, the multi-head attention mechanism is a core component, which has significantly advanced artificial intelligence due to its advantages in parallel computation, capturing long-distance dependencies, and strong expressive capabilities.

1. Introduction to the Transformer Model
The Transformer model was proposed by Google in 2017 in their paper “Attention Is All You Need” as a deep learning model architecture based on attention mechanisms. This model was initially created to solve the sequence-to-sequence problem in machine translation tasks, and due to its excellent performance, it has been widely used in various natural language processing (NLP) tasks as well as in other fields such as computer vision (CV). The Transformer architecture introduces self-attention mechanisms, which are a key innovation that allows it to perform exceptionally well in processing sequential data.
It discards traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs) in favor of a self-attention mechanism to model the input sequence. This mechanism allows the model to simultaneously focus on other positions in the input sequence while processing information at each position, thus capturing dependencies in long sequences more effectively. Since the Transformer itself does not have the capability to perceive positional information in sequences, positional encoding is introduced. Positional encoding integrates positional information into the model by adding a fixed encoding vector to the input at each position, allowing the model to be aware of the order of elements in the input sequence.
2. Model Structure
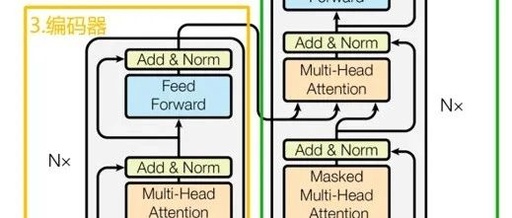
The Transformer model (see Figure 1) mainly consists of inputs, outputs, encoders, and decoders. Both the encoder and decoder parts contain multiple identical layers. The encoder’s responsibility is to encode the input sequence into a fixed-length hidden state representation, while the decoder uses this hidden state representation to generate the target sequence.
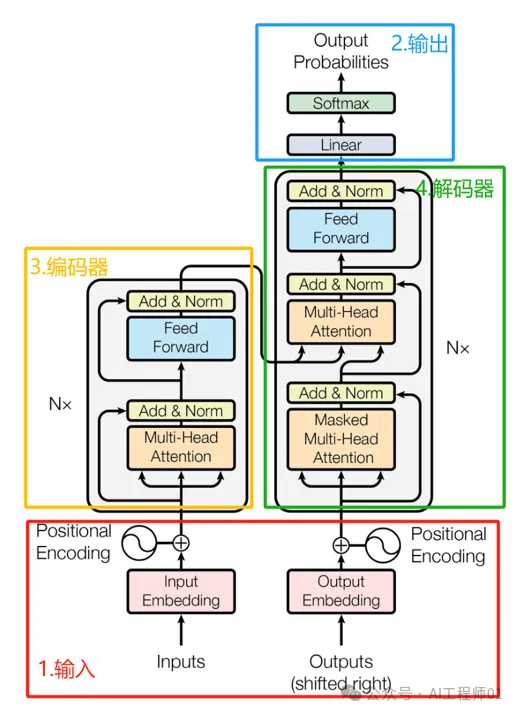
Figure 1: Transformer Model Architecture
First, the input statements undergo word vector processing to transform them into word vectors. Next, positional encoding provides the model with positional information of words in the sequence. Positional encoding is implemented through a set of sine and cosine functions, as shown in Figure 2, where the frequency and phase of these functions vary with position. The dimension of positional encoding matches the dimension of the embedding vector, allowing them to be directly added together to form an input vector containing positional information, which is then fed into the model.
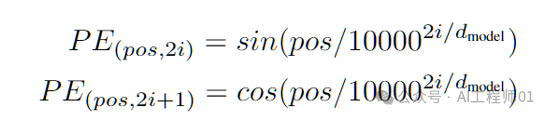
Figure 2: Calculation Formula for Positional Encoding
Where:
• pos represents the position of an element in the sequence.
• i is the index of the positional encoding vector’s dimension.
• d_model is the model’s dimension, which is the dimension of the embedding vector.
The encoder: Nx = 6, the encoder consists of 6 stacked encoder layers. Each encoder layer contains two sub-layers: the multi-head attention sub-layer and the feed-forward network sub-layer. The multi-head attention mechanism allows the model to compute attention in parallel across different representation subspaces, thus capturing complex relationships between different positions in the input sequence. Specifically, it projects the input queries (Query), keys (Key), and values (Value) into multiple low-dimensional spaces through linear transformations, then calculates attention weights in each subspace, and finally concatenates the results of these subspaces, followed by a linear transformation to obtain the final output. The feed-forward network is a fully connected neural network that performs nonlinear transformations on the output of the multi-head attention sub-layer while transforming and merging features. Typically, it consists of two linear layers and a ReLU activation function.
The code implementation of the encoder is as follows:
class EncoderLayer(nn.Module): def __init__(self): super(EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, enc_inputs, enc_self_attn_mask): # enc_inputs to same Q,K,V(未线性变换前) enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) enc_outputs = self.pos_ffn(enc_outputs) return enc_outputs, attn
class Encoder(nn.Module): def __init__(self): super(Encoder, self).__init__() # token Embedding self.src_emb = nn.Embedding(src_vocab_size, d_model) # Transformer中位置编码时固定的,不需要学习 self.pos_emb = PositionalEncoding(d_model) self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) def forward(self, enc_inputs): enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model] enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model] # Encoder输入序列的pad mask矩阵 enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len] # 在计算中不需要用到,它主要用来保存你接下来返回的attention的值(这个主要是为了你画热力图等,用来看各个词之间的关系 enc_self_attns = [] for layer in self.layers: # for循环访问nn.ModuleList对象 # 上一个block的输出enc_outputs作为当前block的输入 # enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len] # 传入的enc_outputs其实是input,传入mask矩阵是因为你要做self attention enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) enc_self_attns.append(enc_self_attn) # 这个只是为了可视化 return enc_outputs, enc_self_attnsThe decoder: The structure of the decoder is similar to that of the encoder, also consisting of 6 stacked identical layers. Unlike the encoder, the decoder adds a third sub-layer in each layer, which mainly performs multi-head self-attention processing on the encoder’s output. As with the encoder, we also apply residual connections and layer normalization after each sub-layer of the decoder. Additionally, we have specially designed the self-attention sub-layer of the decoder to avoid attending to the current and subsequent positions during prediction. With this masking process, combined with the offset mechanism of the output embeddings, we ensure that when predicting the symbol at any position i in the sequence, it can only rely on the outputs already generated before position i. This design guarantees the autoregressive nature of the decoding process.
The code implementation of the decoder is as follows:
import torch
import torch.nn as nn
class DecoderLayer(nn.Module): def __init__(self): super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() self.dec_enc_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask): # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len] dec_outputs, dec_self_attn = self.dec_self_attn( dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask ) # 这里的Q,K,V全是Decoder自己的输入 # dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len] dec_outputs, dec_enc_attn = self.dec_enc_attn( dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask ) # Attention层的Q(来自decoder) 和 K,V(来自encoder) dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model] return dec_outputs, dec_self_attn, dec_enc_attn # dec_self_attn, dec_enc_attn这两个是为了可视化
class Decoder(nn.Module): def __init__(self): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) # Decoder输入的embed词表 self.pos_emb = PositionalEncoding(d_model) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # Decoder的blocks def forward(self, dec_inputs, enc_inputs, enc_outputs): dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model] dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).to(device) # [batch_size, tgt_len, d_model] # Decoder输入序列的pad mask矩阵(这个例子中decoder是没有加pad的,实际应用中都是有pad填充的) dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).to(device) # [batch_size, tgt_len, tgt_len] # Masked Self_Attention:当前时刻是看不到未来的信息的 dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).to(device) # [batch_size, tgt_len, tgt_len] # Decoder中把两种mask矩阵相加(既屏蔽了pad的信息,也屏蔽了未来时刻的信息) dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).to(device) # [batch_size, tgt_len, tgt_len]; torch.gt比较两个矩阵的元素,大于则返回1,否则返回0 # 这个mask主要用于encoder-decoder attention层 # get_attn_pad_mask主要是enc_inputs的pad mask矩阵(因为enc是处理K,V的,求Attention时是用v1,v2,..vm去加权的,要把pad对应的v_i的相关系数设为0,这样注意力就不会关注pad向量) # dec_inputs只是提供expand的size的 dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len] dec_self_attns, dec_enc_attns = [], [] for layer in self.layers: # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len] # Decoder的Block是上一个Block的输出dec_outputs(变化)和Encoder网络的输出enc_outputs(固定) dec_outputs, dec_self_attn, dec_enc_attn = layer( dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask ) dec_self_attns.append(dec_self_attn) dec_enc_attns.append(dec_enc_attn) # dec_outputs: [batch_size, tgt_len, d_model] return dec_outputs, dec_self_attns, dec_enc_attnsThe last output of the decoder will go through a linear layer and a Softmax function. Through this processing, we can obtain the probability distribution of each word in the target sequence, thereby completing the sequence generation task.
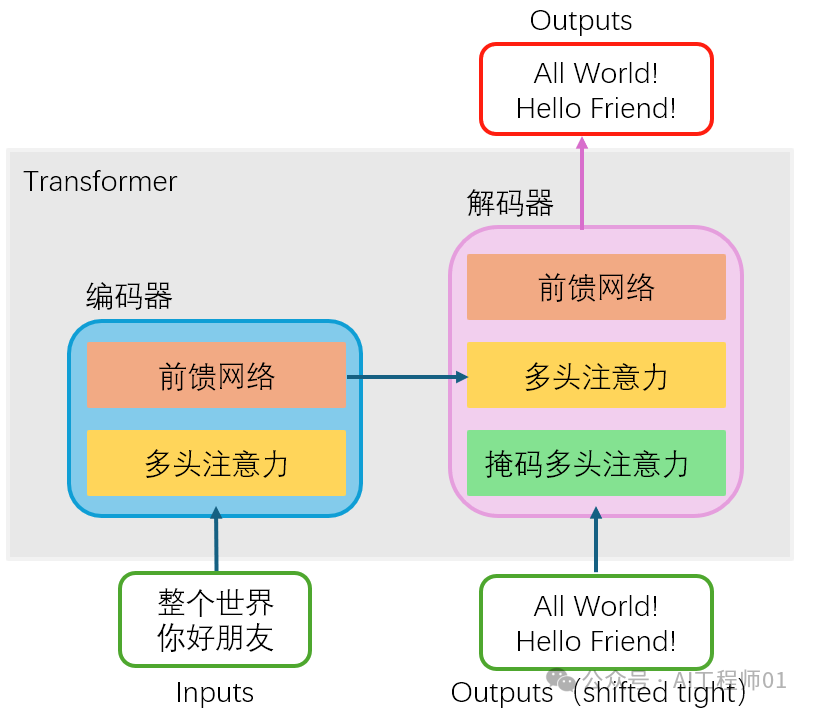
The above figure shows the basic flow of the training model.
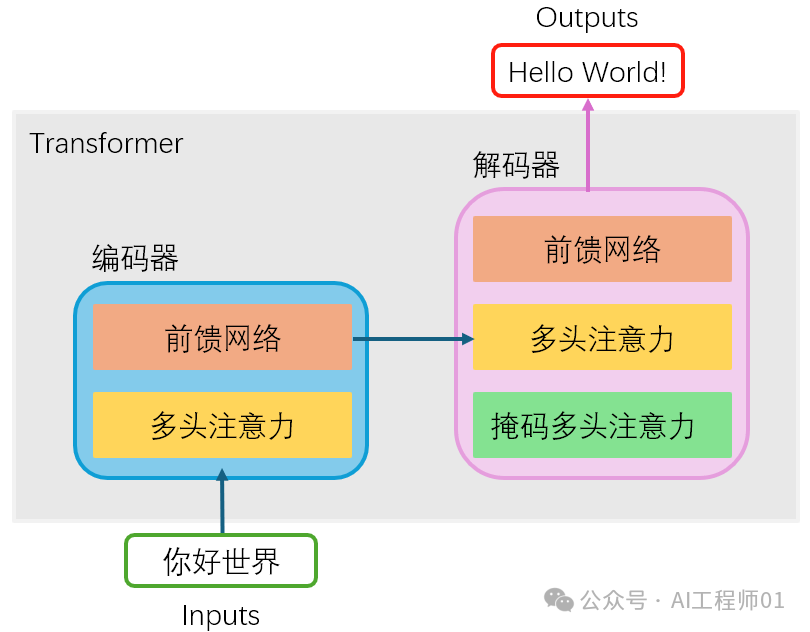
The above figure shows the basic flow of testing the model after training.
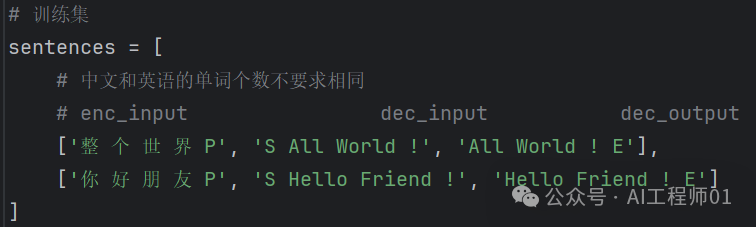
Example:
Training Set
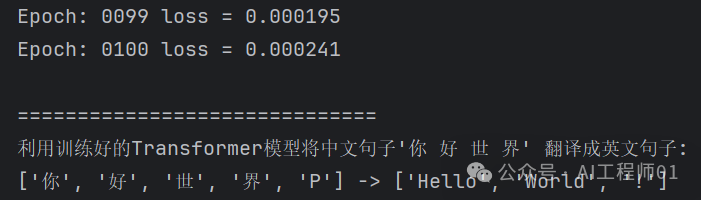
Testing Results
3. Multi-Head Attention Mechanism
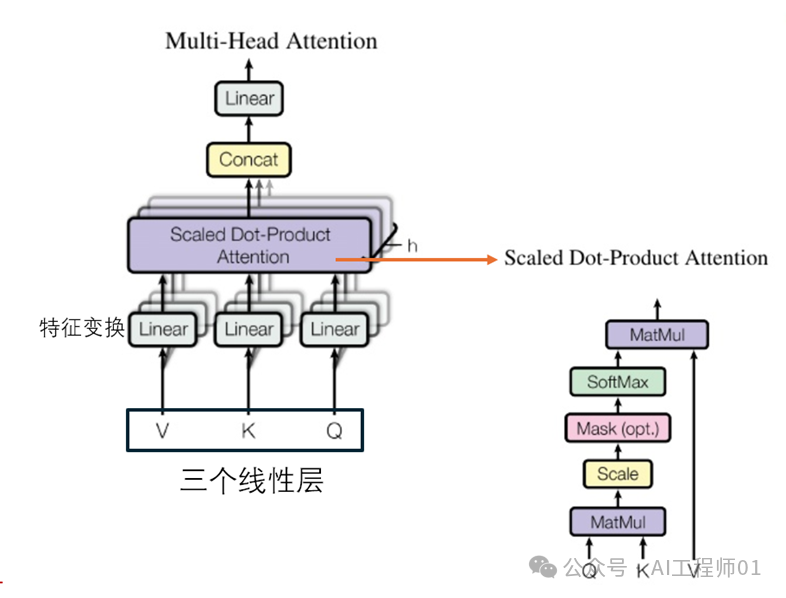
The multi-head attention mechanism is a core component of the entire framework. It is composed of multiple scaled dot-product attention mechanisms. This includes three linear layers (Linear) that perform feature transformations for the input Query (Q), Key (K), and Value (V). This is a pre-processing step for multi-head attention, which maps the input to different representation spaces through linear transformations, thereby more effectively capturing features and relationships.
Detailed Process:
1. Feature transformation: For the input word vector x, three weight matrices WQ, WK, and WV are used to perform feature transformations to obtain the Q, K, and V vectors needed to calculate the attention values.
2. Scaled Dot-Product Attention:
– Calculate attention scores: Perform dot product operations on the transformed Q and K, then divide by a scaling factor (usually the square root of the dimension of K) to obtain the unnormalized attention scores. This is done to prevent the dot product from becoming too large, which could cause the gradients of the subsequent SoftMax function to become too flat.
– Apply masking (optional): In certain cases, such as when processing sequence data, masking is used to prevent leakage of future information. Masks can set the attention scores of certain positions to negative infinity or a very small value, making the weights of these positions close to 0 after the SoftMax calculation.
– SoftMax normalization: Perform the SoftMax operation on the scaled and masked attention scores (if any) to obtain normalized attention weights. These weights represent the importance of each position.
– Weighted summation: Perform a weighted summation of the normalized attention weights with V to obtain the final attention output.
3. Concat and Linear: Concatenate the outputs of multiple scaled dot-product attention mechanisms, and then pass through a linear layer to obtain the final output of multi-head attention.
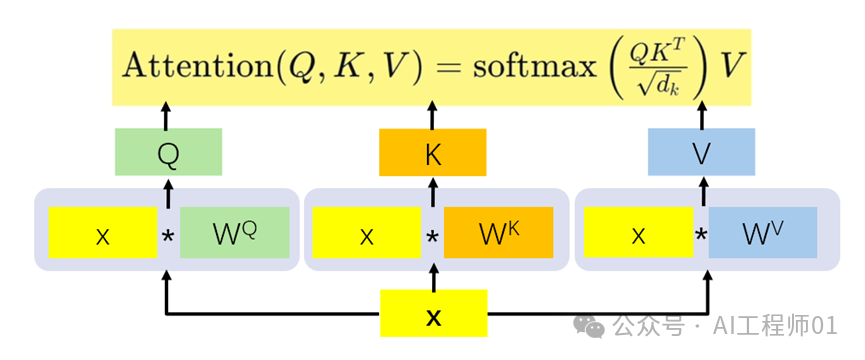
It is worth mentioning that the difference between the multi-head attention mechanism and the self-attention mechanism is that the self-attention mechanism uses only one set of WQ, WK, WV for linear transformations on the input matrix x. In contrast, the multi-head attention mechanism uses multiple sets of WQ, WK, WV, and each set calculates a matrix, which is finally concatenated.
The code implementation of multi-head attention is as follows:
class MultiHeadAttention(nn.Module): """ This Attention class can implement: - Encoder's Self - Attention - Decoder's Masked Self - Attention - Encoder - Decoder's Attention Input: seq_len x d_model Output: seq_len x d_model """ def __init__(self): super(MultiHeadAttention, self).__init__() # q,k must have the same dimension, otherwise dot product cannot be performed self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False) self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False) self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False) # This fully connected layer ensures that the output of multi-head attention is still seq_len x d_model self.fc = nn.Linear(n_heads * d_v, d_model, bias=False) def forward(self, input_Q, input_K, input_V, attn_mask): """ input_Q: [batch_size, len_q, d_model] input_K: [batch_size, len_k, d_model] input_V: [batch_size, len_v(=len_k), d_model] attn_mask: [batch_size, seq_len, seq_len] """ residual, batch_size = input_Q, input_Q.size(0) # The multi-head parameter matrices are combined for linear transformation and then split into multiple heads, which is an engineering implementation technique # B: batch_size, S:seq_len, D: dim # (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, Head, W) -trans-> (B, Head, S, W) # Linear transformation Split into multiple heads # Q: [batch_size, n_heads, len_q, d_k] Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k] # K and V must have the same length, but can have different dimensions K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # V: [batch_size, n_heads, len_v(=len_k), d_v] V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1, 2) # Since it is multi-head, the mask matrix must be expanded to 4 dimensions # attn_mask: [batch_size, seq_len, seq_len] -> [batch_size, n_heads, seq_len, seq_len] attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k] context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) # Below, concatenate the outputs of different heads # context: [batch_size, n_heads, len_q, d_v] -> [batch_size, len_q, n_heads * d_v] context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # This fully connected layer ensures that the output of multi-head attention is still seq_len x d_model output = self.fc(context) # [batch_size, len_q, d_model] return nn.LayerNorm(d_model).to(device)(output + residual), attn4. Summary and Recommendations
Due to its excellent parallel computing capabilities, outstanding long-distance dependency capturing ability, and strong model expressiveness, the Transformer model has been widely applied in various fields such as natural language processing (NLP), computer vision (CV), and multimodal tasks. The birth of the Transformer model has brought new ideas and methods to many fields, significantly advancing the development and application of artificial intelligence technologies. If you are very interested in Transformers, I strongly recommend this Transformer learning tutorial, which I dare say is the most comprehensive introductory manual for Transformers!
To obtain this manual, you can scan the code to add the assistant on WeChat:
I will give you a brief introduction:
Transformers is a natural language processing (NLP) toolkit developed by Hugging Face, which supports loading most existing pre-trained models. The corresponding tutorial is designed to help NLP beginners quickly become familiar with the usage of the Transformers library. This tutorial teaches people how to use the Transformers library to build and adjust models through specific examples, thereby completing various NLP tasks such as text classification, named entity recognition, and machine translation. Whether you are a student, researcher in the NLP field, or a developer looking to quickly get started with the Transformers library, or an enthusiast with a strong interest in NLP technology, this tutorial is undoubtedly your best choice.
Here are some contents from the book:



The article is too long to display everything, but the complete version has been packaged for you, and I hope it helps your learning.
Scan the code to add the assistant on WeChat to get it:
Remember to “like + view + share” to get it for free.