
Machine Heart Release
Authors: Song Zhuoran, Wang Ru, Ru Dongyu, Peng Zhenghao, Jiang Li
Shanghai Jiao Tong University
In this article, the authors utilize the Dropout method to generate a large amount of sparsity during the neural network training process for acceleration. This paper has been accepted by the Design Automation and Test in Europe Conference 2019.
Paper: Approximate Random Dropout for DNN training acceleration in GPGPU

Paper link: https://arxiv.org/abs/1805.08939
1. Introduction
Currently, there are numerous methods for compressing deep neural networks, which utilize the sparsity of neural networks to make the synaptic weights in the network zero through techniques like pruning and regularization.
For example, in pruning [1], those zero weights are stored in on-chip memory after encoding. Since the positions of zeros are quite random, a special decoder must be added to the neural network accelerator to skip calculations involving zero operands. Therefore, pruning methods are limited to platforms such as ASIC/FPGA; moreover, due to the complexity of the encoder-decoder design, few accelerators adopt them.
Some structured sparsity [2] methods achieve acceleration by removing filters and channels in CNNs, making them easier to implement than the aforementioned methods. However, to date, few methods can utilize the sparsity of neural networks to accelerate the training process of deep neural networks. Even in distributed training scenarios, while techniques like gradient compression can reduce communication bandwidth, the training process on a single GPU card still struggles to achieve effective acceleration. The main reason is that the training process of neural networks involves updating weights, which does not exhibit large-scale sparsity.
This paper utilizes the Dropout method to generate a large amount of sparsity during the neural network training process for acceleration.
The Dropout technique is used in network training to prevent overfitting. It randomly temporarily removes a portion of neurons (30%-70%) and their associated connections during each training iteration. Theoretically, we should skip (omit) the computations related to the temporarily removed neurons and synapses in Dropout, thereby accelerating the training process.
However, all training frameworks (such as Caffe, TensorFlow, PyTorch, etc.) have overlooked this point, retaining the redundant computations brought by Dropout and merely masking the results of the deleted neurons in the training results. The main reason is that the positions of redundant computations (deleted neurons and synapses) introduced by Dropout are completely random, making it difficult for the GPU’s Single Instruction Multiple Thread architecture to achieve such fine-grained control.
Therefore, this paper proposes a method to generate a regular structured Dropout pattern online during training, allowing the GPU to flexibly skip the redundant computations introduced by Dropout at its control granularity. Furthermore, we propose an online generation (search) algorithm for Dropout Patterns to compensate for the loss of randomness during Dropout.
We tested our method on MLP and LSTM training tasks, achieving a high acceleration ratio with only slight accuracy degradation. Specifically, with a Dropout Rate ranging from 0.3 to 0.7, the MLP training process was accelerated by 30% to 120%, and the LSTM training process was accelerated by 20% to 60%.
2. Dropout Principle
The most widely used Dropout techniques are mainly divided into two types: unit Dropout proposed by Hinton et al. [3] and weight Dropout proposed by Wan et al. [4].
Unit Dropout randomly removes neurons during each training iteration, thereby reducing the interdependence between units and preventing overfitting. Weight Dropout randomly removes weights from the weight matrix during each update.
For fully connected layers, assuming the input vector is I, the weight matrix is W, the output vector is Y, and the mask M follows a Bernoulli distribution, we can define the aforementioned two methods as:
-
Unit Dropout:

-
Weight Dropout:
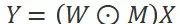
For the unit Dropout, during each training iteration, each neuron is ignored with a certain probability, implemented by element-wise multiplication with a Bernoulli-distributed 0-1 mask matrix (as shown in Figure 1(a)).
If we want to truly skip the redundant computations introduced by Dropout, we need additional if-else condition checks for fine-grained control over the GPU. However, due to the SIMT (Single Instruction Multiple Thread) characteristics of GPUs, some processing units in the GPU may remain idle, and the computational resources of the GPU cannot be fully utilized.
As shown in Figure 1(b), a single instruction simultaneously controls the data flow of 32 threads, which may include both threads evaluated as true and those evaluated as false. Once the GPU executes along the instruction flow evaluated as true, all threads will perform the multiply-accumulate operation. The results of those threads evaluated as false will be masked and not submitted; the GPU will re-execute the instruction flow evaluated as false, at which point all threads will skip calculations. The results of those threads evaluated as true are masked. The final results of both executions are merged via the mask and submitted to memory.
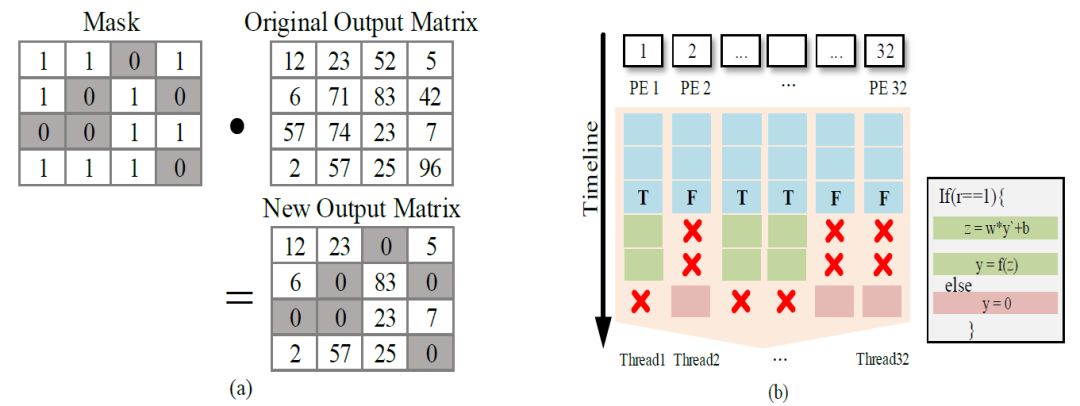
Figure 1(a) Implementation process of unit Dropout; (b) When directly avoiding the redundant calculations brought by unit Dropout, the GPU encounters divergence issues.
This phenomenon is referred to as Divergence in SIMT architectures, leading to additional performance loss. Due to the inefficiency in handling branches in SIMT architectures, mainstream deep learning frameworks do not handle the skipping of redundant computations.
3. Method
This paper defines the concept of Dropout Pattern. A Dropout Pattern is a manually designed regular and structured mask. If the GPU is informed in advance about which neurons or connections will be dropped during computation, we can inform the GPU of the predetermined Dropout Pattern, allowing it to skip reading and computing the relevant data that has been dropped. This way, we can skip redundant computations without causing divergence.
Next, we will introduce two types of Dropout Patterns in sections 3.1 and 3.2. The structured sparsity inevitably leads to a loss of randomness in Dropout, for which we introduce an algorithm to generate a probability distribution regarding Dropout Patterns in section 3.3 to ensure randomness. In section 3.4, we demonstrate that our proposed approximate random Dropout is statistically equivalent to traditional random Dropout.
3.1 Row-based Dropout Pattern (RBD)
RBD is a pattern that approximates traditional Dropout. It systematically drops certain neurons and regularly deletes rows from the weight matrix, thereby reducing the size of the matrix involved in computations.
We define two structural parameters, dp and offset, to systematically perform Dropout.
dp indicates that one row of weights is retained every dp rows (one neuron is retained every dp neurons, and the rest are dropped). Offset indicates that once dp is selected, the deletion of weights starts from the offset row, following the pattern of retaining one row every dp rows.
As shown in Figure 2, with dp=3 and offset=1, this matrix retains one row every three rows starting from the first row. The complete weight matrix is stored in DRAM, and the shared memory can bring in the rows that have not been deleted by specifying the retrieval pattern, after which the processing element (PE) performs computations on the retrieved data to achieve acceleration. From the GPU’s perspective, the row-based Dropout pattern is beneficial for data indexing and facilitates acceleration optimization. It is important to note that dp and offset will change during each training iteration, as detailed in section 3.3.
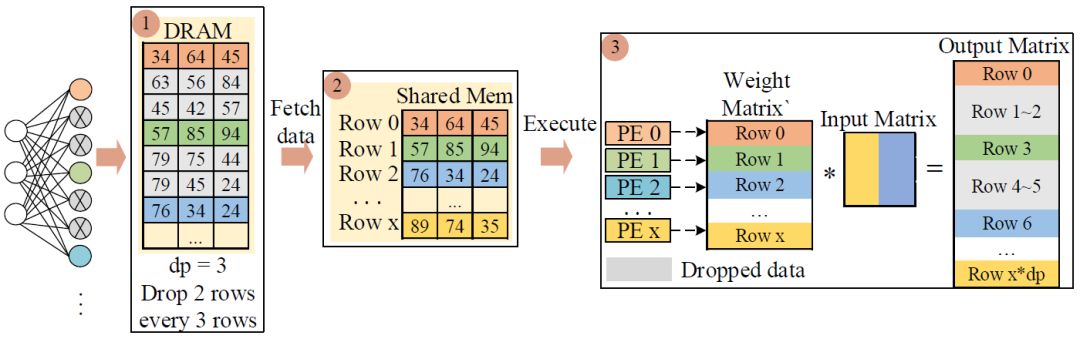
Figure 2 Row-based Dropout pattern
3.2 Tile-based Dropout Pattern (TBD)
TBD deletes the weight matrix in blocks, and the corresponding connections between neurons are ignored. Similar to RBD, we still define two structural parameters, dp and offset. As shown in Figure 3, with dp=4 and offset=1, this matrix retains one block every three blocks starting from the first block. The block-based Dropout pattern ensures the regularity of the data, aiding in GPU optimization and acceleration.
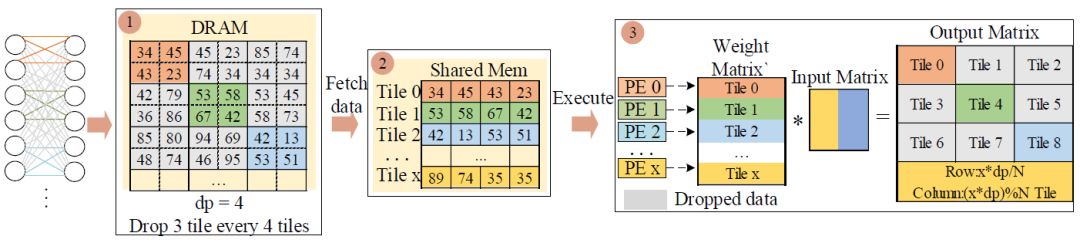
Figure 3 Block-based Dropout pattern
3.3 SGD-based Dropout Pattern Search Algorithm
First, we define Global Dropout Rate, which in this paper refers to the proportion of neurons dropped in a training iteration. This is somewhat different from the probability of each neuron being dropped in random Dropout, but we prove that in our method, the Global Dropout Rate is equivalent to the Dropout Rate of each neuron.
Next, we define a vector where the i-th element represents the proportion of neurons dropped in the Dropout Pattern with structural parameter dp=i, i.e.,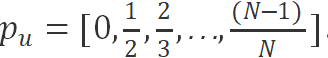 . Because in the Dropout Pattern, one neuron (or weight matrix row vector/block) is retained every dp neurons, the i-th element of vector p_u is (i-1) / i.
. Because in the Dropout Pattern, one neuron (or weight matrix row vector/block) is retained every dp neurons, the i-th element of vector p_u is (i-1) / i.
To compensate for the loss of randomness introduced by the Dropout Pattern, we aim to use different structural parameters (dp and offset) in each training iteration to generate more randomness and ensure that the probability of each neuron/synapse being dropped is approximately equal to the probability during traditional random Dropout.
To achieve this, we use SGD gradient descent for local search to obtain the probability density function regarding the structural parameters (dp). It is a vector where the i-th element indicates the probability of the Dropout Pattern with dp=i being selected.
Therefore, to make the Global Dropout Rate approach the Dropout Rate p of random Dropout, we set one of the loss functions of the SGD algorithm as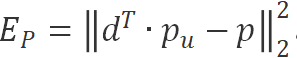 . Here, p is a parameter passed to the algorithm, indicating what we want the Global Dropout Rate to be.
. Here, p is a parameter passed to the algorithm, indicating what we want the Global Dropout Rate to be.
Furthermore, to diversify the combinations of structural parameters, another optimization goal of the SGD algorithm is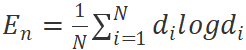 , which is the negative information entropy of the probability distribution.
, which is the negative information entropy of the probability distribution.
To achieve both optimization goals, we define the final loss function of SGD as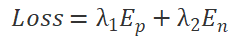 , where λ is the balancing factor.
, where λ is the balancing factor.
3.4 Statistical Equivalence
To prove that approximate random Dropout is statistically equivalent to traditional random Dropout, we provide the following proof.
The following expression gives the probability of any neuron being dropped when using the approximate random Dropout scheme (i.e., the traditional Dropout Rate). Given a Dropout Pattern, the probability of a neuron being selected is the product of the probability of that Dropout Pattern being selected and the probability of that neuron being dropped under that Dropout Pattern. According to the law of total probability, summing over all Dropout Patterns gives the probability of each neuron being dropped:
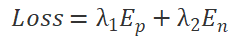
On the other hand, the proportion of neurons dropped from a global perspective (i.e., Global Dropout Rate) is the product of the probability of each Dropout Pattern (determined by the structural parameter dp) being selected and the proportion of neurons dropped under that Dropout Pattern. Since the search algorithm for Dropout Pattern distribution probability ensures that, we have Global Dropout Rate:
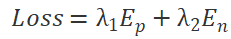
It can be seen that the Global Dropout Rate is equal to the Dropout Rate of individual neurons, and both are equal to the input parameter p of our Dropout Pattern probability distribution generation algorithm. Therefore, we say that our Dropout mechanism is statistically equivalent to the random Dropout mechanism throughout the training process.
4. Experiments
We applied this method to train a four-layer MLP network using the MNIST dataset to test the performance of this method. Table 1 shows the experimental results, indicating that as the size of the network increases, the acceleration ratio gradually improves. Compared to traditional methods, the maximum acceleration ratio can reach around 2.2X. All accuracy losses remain within 0.5%.
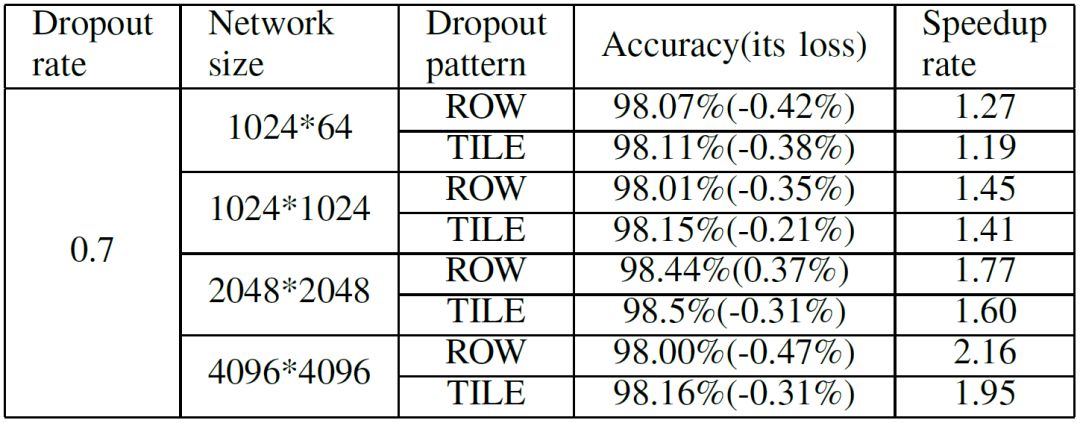
Table 1 Accuracy and Acceleration Ratios of Different Networks
We also applied this method to train LSTM using the Penn Treebank dataset for language modeling. Figure 4 shows the experimental results using a three-layer LSTM+MLP. With a dropout rate of 0.7, the test perplexity under RBD only increased by 0.04, and the training speed was accelerated by 1.6 times, significantly reducing the time consumed for training.
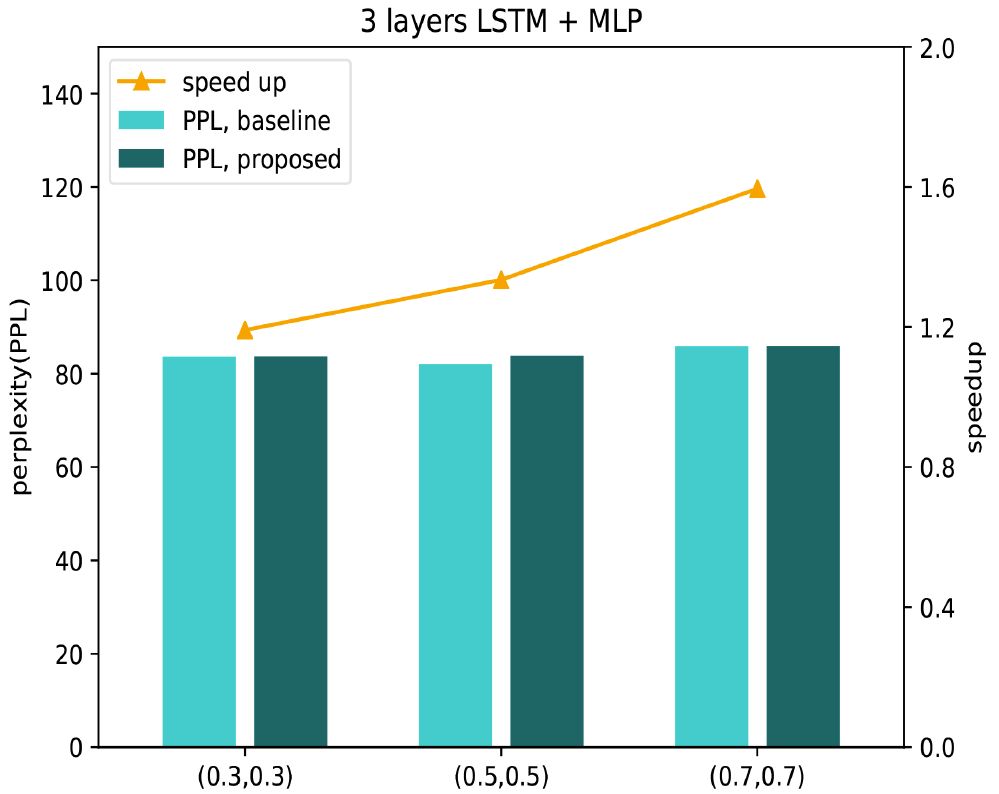
Figure 4 Accuracy and Acceleration Ratios of LSTM Network Based on PTB Dataset
5. Conclusion
We proposed approximate random Dropout as a replacement for traditional random Dropout. By reducing the actual parameters and input matrix sizes involved in DNN training, we decreased the computational load and data transfer on the GPU, thereby accelerating the DNN training process. At the same time, we introduced an SGD-based Dropout Pattern search algorithm, ensuring that the dropout rate for each neuron is approximately equal to the preset value, thus guaranteeing accuracy and convergence.

Reference
-
Han S, Mao H, Dally W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv preprint arXiv:1510.00149, 2015.
-
Wen W, Wu C, Wang Y, et al. Learning structured sparsity in deep neural networks[C]. Advances in Neural Information Processing Systems. 2016: 2074-2082.
-
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhut- dinov, “Dropout: a simple way to prevent neural networks from overfit- ting,” Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929– 1958, 2014.
-
L. Wan, M. D. Zeiler, S. Zhang, Y. Lecun, and R. Fergus, “Regulariza- tion of neural networks using dropconnect,” in International Conference on Machine Learning, pp. 1058–1066, 2013.
This article was released by Machine Heart, please contact this official account for authorization to reprint..
✄————————————————
Join Machine Heart (Full-time Reporter / Intern): [email protected]
Submissions or seeking coverage: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]