Reprinted from: Machine Heart
Master these 17 methods to accelerate your PyTorch deep learning training in the most effortless way.
Recently, a post on Reddit has gone viral. The topic is about how to speed up PyTorch training. The original author is Lorenz Kuhn, a master’s student in computer science at ETH Zurich, who introduces the17 most effortless and effective methods to speed up training deep models using PyTorch.
The methods proposed in this article assume that you are training the model in a GPU environment. The specific content is as follows.17 Methods to Accelerate PyTorch Training1. Consider Changing the Learning Rate ScheduleThe choice of learning rate schedule has a significant impact on the convergence speed and generalization ability of the model. Leslie N. Smith et al. proposed cyclical learning rates and the 1Cycle learning rate schedule in the papers “Cyclical Learning Rates for Training Neural Networks” and “Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates”. Later, Jeremy Howard and Sylvain Gugger from fast.ai promoted it. The following figure illustrates the 1Cycle learning rate schedule:
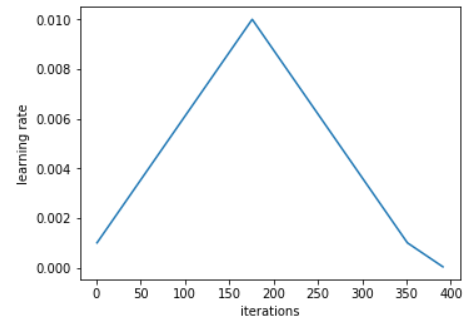
Sylvain wrote that 1Cycle includes two equal-length steps, one step is from a lower learning rate to a higher learning rate, and the other is back to the lowest level. The maximum value comes from the value selected by the learning rate finder, and the smaller value can be ten times lower. Then, the length of this cycle should be slightly less than the total number of epochs, and in the final stage of training, we should allow the learning rate to be several orders of magnitude lower than the minimum.Compared to traditional learning rate schedules, this schedule achieves tremendous acceleration in the best cases (Smith calls it super-convergence). For example, using the 1Cycle strategy to train ResNet-56 on the ImageNet dataset reduced the training iterations to 1/10 of the original, but the model performance can still match the level in the original paper. This schedule seems to perform well across common architectures and optimizers.PyTorch has implemented these two methods: “torch.optim.lr_scheduler.CyclicLR” and “torch.optim.lr_scheduler.OneCycleLR”.Reference documentation: https://pytorch.org/docs/stable/optim.html2. Use Multiple Workers and Pin Memory in DataLoaderWhen using torch.utils.data.DataLoader, set num_workers > 0 instead of the default value of 0, and set pin_memory=True instead of the default value of False.Senior CUDA deep learning algorithm software engineer Szymon Micacz from NVIDIA has achieved a 2x speedup in a single epoch using four workers and pinned memory. The rule of thumb for choosing the number of workers is to set it to four times the number of available GPUs; setting it higher or lower will reduce training speed. Note that increasing num_workers will increase CPU memory consumption.3. Maximize the Batch SizeMaximizing the batch size is a somewhat controversial viewpoint. Generally, if you maximize the batch size within the limits of GPU memory, your training speed will be faster. However, you also need to adjust other hyperparameters, such as the learning rate. A good rule of thumb is to double the learning rate when the batch size is doubled.OpenAI’s paper “An Empirical Model of Large-Batch Training” provides a good argument for how many steps different batch sizes need to converge. In the article “How to get 4x speedup and better generalization using the right batch size”, author Daniel Huynh conducted experiments with different batch sizes (also using the 1Cycle strategy discussed above). Ultimately, he increased the batch size from 64 to 512, achieving a 4x speedup.However, the downside of using large batches is that it may lead to poorer generalization compared to using smaller batches.4. Use Automatic Mixed Precision (AMP)PyTorch version 1.6 includes a native implementation of automatic mixed precision training. What is meant here is that certain operations run faster in half precision (FP16) compared to single precision (FP32) without losing accuracy. AMP automatically decides which precision should be used for which operation. This can speed up training and reduce memory usage.In the best-case scenario, the usage of AMP is as follows:
import torch# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter: optimizer.zero_grad() # Casts operations to mixed precision with torch.cuda.amp.autocast(): loss = model(data)
# Scales the loss, and calls backward() # to create scaled gradients scaler.scale(loss).backward()
# Unscales gradients and calls # or skips optimizer.step() scaler.step(optimizer)
# Updates the scale for next iteration scaler.update()5. Consider Using Another OptimizerAdamW is an Adam variant promoted by fast.ai that includes weight decay instead of L2 regularization, implemented in PyTorch as torch.optim.AdamW. AdamW seems to consistently outperform Adam in terms of error and training time.Both Adam and AdamW work well with the aforementioned 1Cycle strategy.Currently, some non-native optimizers have also attracted significant attention, most notably LARS and LAMB. NVIDIA’s APEX has implemented fused versions of some common optimizers, such as Adam. This implementation avoids multiple transfers with GPU memory, improving speed by 5% compared to the Adam implementation in PyTorch.6. CUDNN BenchmarkIf your model architecture remains unchanged and the input size remains constant, set torch.backends.cudnn.benchmark = True.7. Be Careful of Frequent Data Transfers Between CPU and GPUFrequent use of tensor.cpu() to transfer tensors from GPU to CPU (or using tensor.cuda() to transfer tensors from CPU to GPU) is very costly. item() and .numpy() are also similar; use .detach() instead.If you create a new tensor, you can allocate it to the GPU using the keyword argument device=torch.device(‘cuda:0’).If you need to transfer data, you can use .to(non_blocking=True) as long as there are no synchronization points after the transfer.8. Use Gradient/Activation CheckpointingCheckpointing works by trading computation for memory; it does not store all intermediate activations of the entire computation graph for the backward pass but recomputes these activations. We can apply it to any part of the model.Specifically, during the forward pass, the function runs in torch.no_grad() mode, not storing intermediate activations. Instead, the input tuples and function parameters are saved during the forward pass. During the backward pass, the inputs and function are retrieved and the forward pass is computed again on the function. Then the intermediate activations are tracked, and these activation values are used to compute gradients.Thus, while this may slightly increase the runtime for a given batch size, it significantly reduces memory usage. This, in turn, allows for further increases in the batch size used, thereby improving GPU utilization.Although checkpointing is implemented in torch.utils.checkpoint, it still requires some thought and effort to implement correctly. Priya Goyal wrote a great tutorial introducing key aspects of checkpointing.Priya Goyal’s tutorial link: https://github.com/prigoyal/pytorch_memonger/blob/master/tutorial/Checkpointing_for_PyTorch_models.ipynb9. Use Gradient AccumulationAnother way to increase the batch size is to accumulate gradients over multiple .backward() passes before calling optimizer.step().Thomas Wolf’s article from Hugging Face, “Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups”, discusses how to use gradient accumulation. Gradient accumulation can be implemented as follows:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set): predictions = model(inputs) # Forward pass loss = loss_function(predictions, labels) # Compute loss function loss = loss / accumulation_steps # Normalize our loss (if averaged) loss.backward() # Backward pass if (i+1) % accumulation_steps == 0: # Wait for several backward steps optimizer.step() # Now we can do an optimizer step model.zero_grad() # Reset gradients tensors if (i+1) % evaluation_steps == 0: # Evaluate the model when we... evaluate_model() # ...have no gradients accumulateThis method was primarily developed to circumvent GPU memory limitations.10. Use Distributed Data Parallel for Multi-GPU TrainingThere are many ways to accelerate distributed training, but a simple way is to use torch.nn.DistributedDataParallel instead of torch.nn.DataParallel. This way, each GPU will be driven by a dedicated CPU core, avoiding the GIL problem of DataParallel.Distributed training documentation link: https://pytorch.org/tutorials/beginner/dist_overview.html11. Set Gradients to None Instead of 0Set gradients using .zero_grad(set_to_none=True) instead of .zero_grad(). Doing so allows the memory allocator to handle gradients instead of setting them to 0. As the documentation states, setting gradients to None results in moderate acceleration, but do not expect miracles. Note that this also has downsides; see the documentation for details.Documentation link: https://pytorch.org/docs/stable/optim.html12. Use .as_tensor() Instead of .tensor()torch.tensor() will always copy data. If you are converting a numpy array, use torch.as_tensor() or torch.from_numpy() to avoid data copying.13. Enable Debugging Tools When NecessaryPyTorch provides many debugging tools, such as autograd.profiler, autograd.grad_check, and autograd.anomaly_detection. Be sure to enable the debugger only when you need to debug, and turn it off promptly when not needed, as the debugger will slow down your training speed.14. Use Gradient ClippingRegarding the issue of avoiding gradient explosion in RNNs, some experiments and theories have confirmed that gradient clipping (gradient = min(gradient, threshold)) can accelerate convergence. HuggingFace’s Transformer implementation is a very clear example of how to use gradient clipping. Other methods mentioned in this article, such as AMP, can also be used.In PyTorch, it can be implemented using torch.nn.utils.clip_grad_norm_.15. Turn Off Bias Before BatchNormTurn off the bias layer before starting the BatchNormalization layer. For a 2-D convolution layer, you can set the bias keyword to False: torch.nn.Conv2d(…, bias=False, …).16. Turn Off Gradient Calculation During ValidationTurn off gradient calculation during validation by setting: torch.no_grad().17. Use Input and Batch NormalizationMake sure to check whether the input is normalized? Is batch normalization being used?Original link: https://efficientdl.com/faster-deep-learning-in-pytorch-a-guide/
