
By / Goldie Gadde and Nikita Namjoshi, TensorFlow
TensorFlow 2.4 has been officially released! With increased support for distributed training and mixed precision, along with the introduction of a new NumPy frontend and tools for monitoring and diagnosing performance bottlenecks, this version highlights new features and enhancements in performance and scalability.
New Features of tf.distribute
Parameter Server Strategy
In version 2.4, experimental support for the tf.distribute module has been introduced, allowing asynchronous training of Keras models using ParameterServerStrategy and custom training loops. Similar to MultiWorkerMirroredStrategy, ParameterServerStrategy is a multi-worker data parallel strategy; however, its gradient updates are executed asynchronously.
-
ParameterServerStrategyhttps://tensorflow.google.cn/api_docs/python/tf/distribute/experimental/ParameterServerStrategy
The parameter server training cluster consists of worker nodes and parameter servers. The system creates variables on the parameter servers, and the worker nodes read and update these variables at each step. The reading and updating of variables occur independently on each worker node, without the need for any synchronization. Since worker nodes are independent of each other, this strategy has the advantage of worker fault tolerance and is beneficial when using preemptible servers.
To get started with this strategy, please refer to the Parameter Server Training Tutorial. This tutorial explains how to set up ParameterServerStrategy and how to use the ClusterCoordinator class to create resources, schedule functions, and handle task failures.
-
Parameter Server Training Tutorialhttps://tensorflow.google.cn/tutorials/distribute/parameter_server_training
-
ClusterCoordinatorhttps://tensorflow.google.cn/api_docs/python/tf/distribute/experimental/coordinator/ClusterCoordinator
Multi-Worker Mirrored Strategy
<span>MultiWorkerMirroredStrategy</span> has successfully transitioned out of the experimental phase and is now part of the stable API. Like the single worker replica <span>MirroredStrategy</span>, MultiWorkerMirroredStrategy achieves distributed training through synchronized data parallelism. However, with MultiWorkerMirroredStrategy, you can train across multiple machines, each equipped with multiple GPUs.
-
MultiWorkerMirroredStrategyhttps://tensorflow.google.cn/api_docs/python/tf/distribute/MultiWorkerMirroredStrategy
-
MirroredStrategyhttps://tensorflow.google.cn/api_docs/python/tf/distribute/MirroredStrategy
In synchronous training, each worker node computes forward and backward passes on different shards of input data and aggregates gradients at the end of each step. For this aggregation, known as All Reduce, MultiWorkerMirroredStrategy uses collective operations to keep variables synchronized. Collective operations are single operators in the TensorFlow graph that can automatically select All Reduce algorithms based on hardware, network topology, and tensor size during runtime. Collective operations also enable other collective operations, such as broadcasting and All Gather.
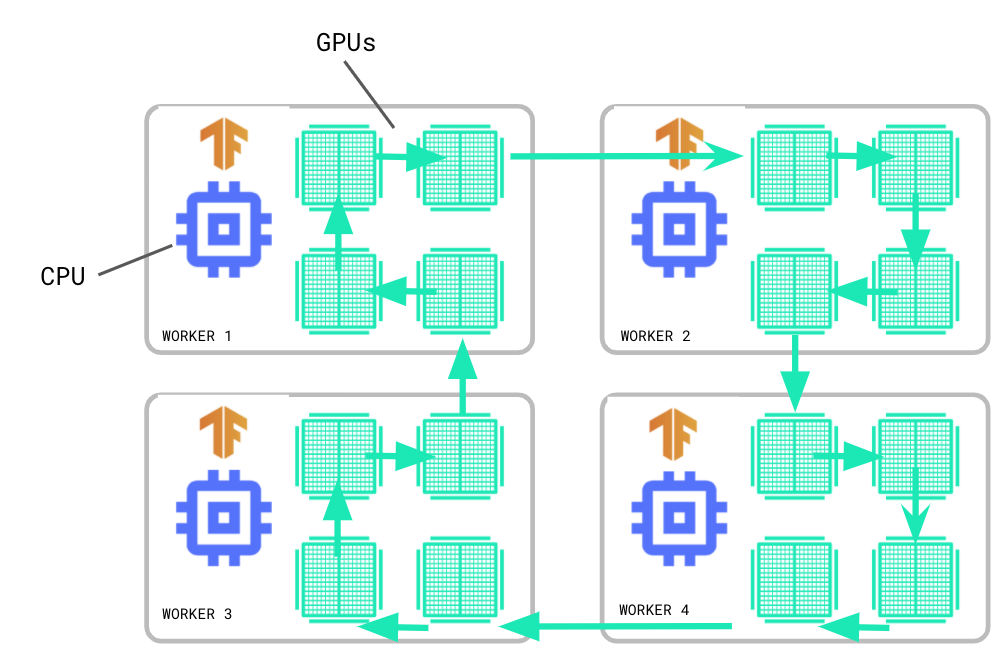
-
Collective Operationshttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/collective_ops.py
To get started with MultiWorkerMirroredStrategy, please refer to the Using Keras for Multi-Worker Training tutorial, which has been updated with details on dataset sharding, saving/loading models trained with distribution strategies, and using BackupAndRestore callbacks for fault recovery.
-
Using Keras for Multi-Worker Traininghttps://tensorflow.google.cn/tutorials/distribute/multi_worker_with_keras
-
BackupAndRestorehttps://tensorflow.google.cn/api_docs/python/tf/keras/callbacks/experimental/BackupAndRestore
If you are not familiar with distributed training and want to learn how to get started, or are interested in distributed training on Google Cloud Platform (GCP), please refer to this blog post for an introduction to key concepts and steps.
Related Updates in Keras
Mixed Precision
In TensorFlow 2.4, the Keras Mixed Precision API has successfully transitioned out of the experimental phase and is now a stable API. Most TensorFlow models use the float32 dtype; however, there are also lower precision types (such as float16) that use less memory. Mixed precision refers to using both 16-bit and 32-bit floating-point types within the same model to speed up training. This API can improve model performance by 3 times on GPUs and by 60% on TPUs.
-
Keras Mixed Precision APIhttps://tensorflow.google.cn/api_docs/python/tf/keras/mixed_precision
To use the mixed precision API, you must use Keras layers and optimization tools, but you do not need to use other Keras classes, such as models or losses. If you are interested in how to leverage this API for performance optimization, please refer to the Mixed Precision Tutorial.
-
Mixed Precision Tutorialhttps://tensorflow.google.cn/guide/mixed_precision
Optimization Tools
This version supports the refactoring of the tf.keras.optimizers.Optimizer class, allowing users of model.fit or custom training loops to write any training code applicable to optimization tools. Now, all built-in tf.keras.optimizer.Optimizer subclasses can support the use of gradient_transformers and gradient_aggregator parameters, allowing you to easily define custom gradient transformations.
-
tf.keras.optimizers.Optimizerhttps://tensorflow.google.cn/api_docs/python/tf/keras/optimizers/Optimizer
With this refactoring, you can now pass the loss tensor directly to Optimizer.minimize when writing custom training loops:
tape = tf.GradientTape()
with tape:
y_pred = model(x, training=True)
loss = loss_fn(y_pred, y_true)
# As shown below, when using the loss "tensor", you can pass it in "tf.GradientTape".
optimizer.minimize(loss, model.trainable_variables, tape=tape)These changes are intended to free both Model.fit and custom training loops from the constraints of optimization tool details, allowing you to write any training code applicable to optimization tools without modification.
Internal Improvements in Functional API Model Building
Finally, in Keras, TensorFlow 2.4 supports refactoring of the internal structure of the Keras Functional API, reducing memory consumption during functional model building and simplifying triggering logic. Such refactoring also ensures that TensorFlowOpLayers behavior is predictable and can be used with signatures of CompositeTensor types.
Introducing tf.experimental.numpy
TensorFlow 2.4 introduces experimental support for a subset of the NumPy API in the form of tf.experimental.numpy. With this module, you can run TensorFlow-accelerated NumPy code. Since this API is built on TensorFlow, it supports access to all TensorFlow APIs, enabling seamless interoperability with TensorFlow implementations and optimizations through compilation and automatic vectorization. For example, TensorFlow ND arrays can interact with NumPy functions, and similarly, TensorFlow NumPy functions can accept various types of input, including tf.Tensor and np.ndarray.
import tensorflow.experimental.numpy as tnp ```
# Use NumPy code in the input pipeline
dataset = tf.data.Dataset.from_tensor_slices(
tnp.random.randn(1000, 1024)).map(
lambda z: z.clip(-1,1)).batch(100)
# Compute gradients using NumPy code
def grad(x, wt):
with tf.GradientTape() as tape:
tape.watch(wt)
output = tnp.dot(x, wt)
output = tf.sigmoid(output)
return tape.gradient(tnp.sum(output), wt)-
tf.experimental.numpyhttps://tensorflow.google.cn/api_docs/python/tf/experimental/numpy
-
Experimental Support for NumPy APIhttps://github.com/tensorflow/community/blob/master/governance/api-reviews.md#experimental-apis
You can refer to the NumPy API on TensorFlow Guide for more information on using this API.
-
NumPy API on TensorFlow Guidehttps://tensorflow.google.cn/guide/tf_numpy
New Profiler Tool for Performance Analysis
Multi-Worker Support in TensorFlow Profiler
TensorFlow Profiler is a set of tools for evaluating the training performance and resource consumption of TensorFlow models. TensorFlow Profiler can help you understand the hardware resource consumption of operators in your model, diagnose bottlenecks, and ultimately speed up training.
-
TensorFlow Profilerhttps://tensorflow.google.cn/guide/profiler
Previous versions of TensorFlow Profiler supported monitoring multi-GPU, single-host training jobs. In the current 2.4 version, you can analyze the performance of MultiWorkerMirroredStrategy training jobs. For example, you can use the Sampling Model API to perform on-demand analysis and connect to the same server port used by MultiWorkerMirroredStrategy worker nodes:
# Start the performance profiler server before the model runs.
tf.profiler.experimental.server.start(6009)
# Insert your model code here……
# For example, if your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you
# want to perform performance profiling for 2 seconds. The profiling data will
# be saved to the Google Cloud Storage path "your_tb_logdir".
tf.profiler.experimental.client.trace(
'grpc://10.0.0.2:6009,grpc://10.0.0.3:6009,grpc://10.0.0.4:6009',
'gs://your_tb_logdir',
2000)-
Sampling Modelhttps://tensorflow.google.cn/guide/profiler#sampling_mode
Alternatively, you can use the Capture Profile tool by providing the addresses of the worker nodes to configure the TensorBoard profile plugin.
After the analysis is complete, you can use the new Pod Viewer tool to select a training step and review the breakdown of step times across all worker nodes.
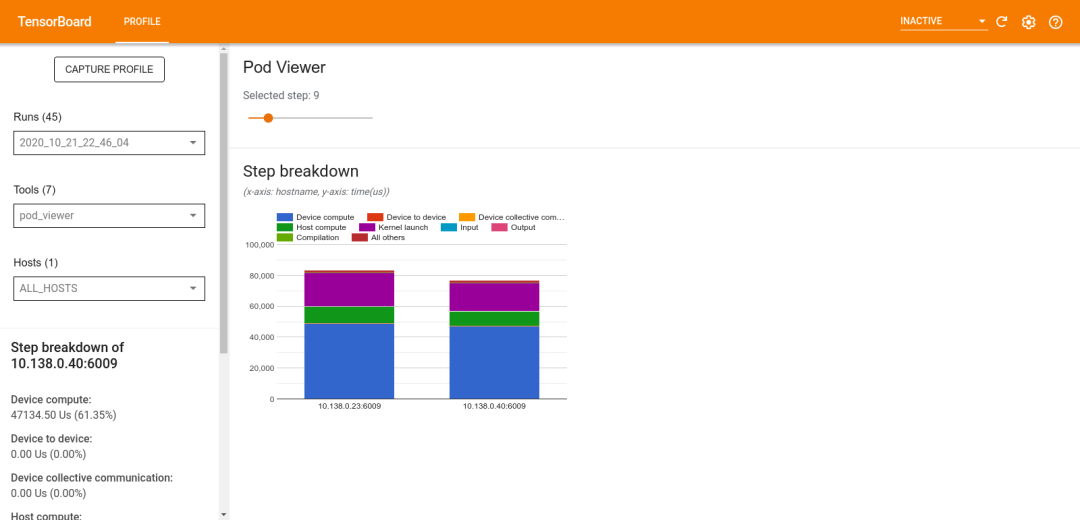
-
Pod Viewer Toolhttps://tensorflow.google.cn/guide/profiler#pod_viewer
For more information on how to use TensorFlow Profiler, please refer to the newly released GPU Performance Guide. This guide covers common scenarios you may encounter when profiling the performance of your model training jobs and provides debugging workflows to help you optimize performance, whether you are using a single GPU, multiple GPUs, or training across multiple machines.
-
GPU Performance Guidehttps://tensorflow.google.cn/guide/gpu_performance_analysis
TFLite Profiler
In version 2.4, you can also enable tracking of TFLite internals on Android. Now, you can use the Android TFLite Profiler to identify performance bottlenecks. The TFLite Performance Evaluation Guide explains how to use the Android Studio CPU profiler and system tracing app to add tracing events, enable TFLite tracing, and capture traces.
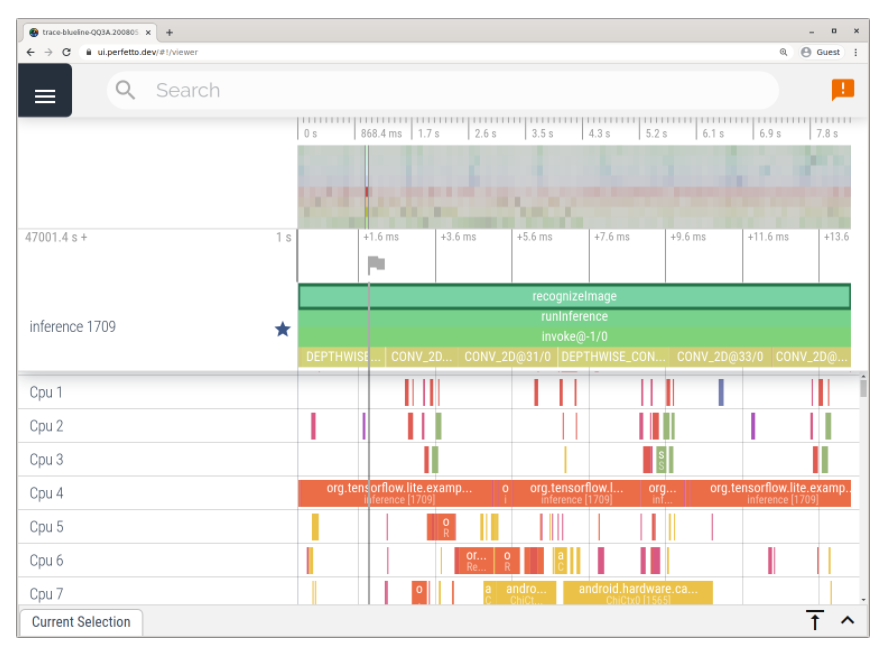
Example of tracing using the Android system tracing app
-
TFLite Performance Evaluation Guidehttps://tensorflow.google.cn/lite/performance/measurement#trace_tensorflow_lite_internals_in_android
New Features for GPU Support
TensorFlow 2.4 can run with CUDA 11 and cuDNN 8 to support the latest NVIDIA Ampere GPU architecture. For more information on CUDA 11 features, please refer to this NVIDIA Developer Blog.
-
NVIDIA Developer Bloghttps://developer.nvidia.com/blog/cuda-11-features-revealed/
Additionally, we will also enable support for TensorFloat-32 by default on GPUs equipped with Ampere. TensorFloat-32 (TF32) is a mathematical mode for NVIDIA Ampere GPUs that accelerates the execution of certain float32 operators (such as matrix multiplication and convolution) on Ampere GPUs, but with reduced precision. For more information, please refer to the tf.config.experimental.enable_tensor_float_32_execution documentation.
-
tf.config.experimental.enable_tensor_float_32_executionhttps://tensorflow.google.cn/api_docs/python/tf/config/experimental/enable_tensor_float_32_execution
Next Steps
Please refer to the Release Notes for more information. For updates, please read the TensorFlow Official Account(TensorFlow_official) or subscribe to the Bilibili Google China(space.bilibili.com/64169458). To share your builds, please submit your work to us through the Community Spotlight Program(goo.gle/TFCS). For feedback, please submit issues on GitHub. Thank you!
-
Release Noteshttps://github.com/tensorflow/tensorflow/releases
-
GitHubhttps://github.com/tensorflow/tensorflow/issues
For more information, click “Read Original” to visit Release Notes.
