
Source: Shi Zhi AI wisemodel
This article contains 3335 words, and it is recommended to read in 7 minutes.
This article introduces the benchmark tests conducted by the research teams from the Hong Kong University of Science and Technology and Beijing DaMo Technology on the performance of different sizes of LLMs across various GPU platforms.
Large Language Models (LLMs) have made significant progress in both academia and industry, driving updates to open-source frameworks and technologies to accelerate the training and application of LLMs. However, performance differences are significant across different hardware and software configurations. The team led by Professor Xu Wen from the Hong Kong University of Science and Technology (Guangzhou) collaborated with the R&D team from Beijing DaMo Technology to benchmark the performance of different sizes of LLMs across various GPU platforms, including various optimization techniques, and conducted an in-depth analysis of the submodules of LLMs, including computational and communication operations. This work aims to help users and researchers better understand and select configurations for LLMs, as well as identify potential opportunities for further performance optimization.Original article link: https://arxiv.org/abs/2311.036871. Performance Evaluation IssuesThe deployment of LLMs involves three main stages: pre-training, fine-tuning, and serving. The pre-training stage is the most time-consuming, typically requiring thousands of GPUs and several months. The fine-tuning stage adjusts the model for specific tasks. Finally, the model is deployed as a web service to provide inference results.However, the performance of LLM frameworks and optimization techniques across different hardware remains to be explored. Important questions include: the requirements of specific hardware configurations, time costs, enabled optimization techniques, and whether existing systems are fully utilizing GPU resources. To this end, this study conducted benchmark tests on the runtime and memory performance of the LLM processes on different GPU servers, covering performance evaluations of various frameworks, hardware, and optimization techniques, along with detailed analyses of model modules and operations.
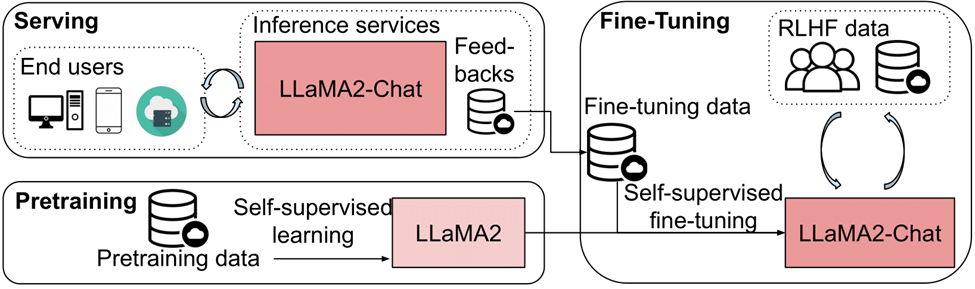
Complete process from fine-tuning to deploying the LLaMA2 model
2. Testing Methods
A comprehensive benchmarking method evaluated the performance of the Llama2 model on three 8-card GPU platforms (NVIDIA A800, RTX4090, and RTX3090). These platforms represent different levels of high-performance computing resources available in the market. The tests focused on the three stages of pre-training, fine-tuning, and serving, using various performance metrics such as end-to-end step time, module-level time, and operation time to analyze the time efficiency of LLMs in depth. The goal is to fully understand the performance of LLMs on different hardware and provide insights for their optimization.
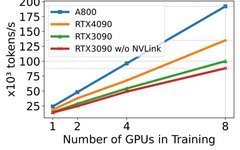
3. Pre-trainingThis section primarily analyzes the pre-training performance of models of different scales (7B, 13B, 70B), focusing on iteration time or throughput and memory consumption, along with micro-benchmarking at the module and operation levels.3.1 End-to-end Performance AnalysisThe training speed advantage of DeepSpeed is mainly attributed to its efficiency in data-parallel training. However, under the same batch size, DeepSpeed consumes more GPU memory compared to tensor-parallel-based Megatron-LM.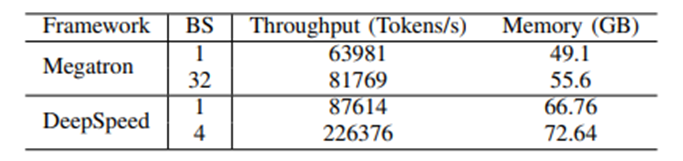 Comparison of Megatron-LM and DeepSpeed3.2 Scalability Efficiency Across Different GPU PlatformsBased on DeepSpeed and quantization techniques, the study researched the scalability efficiency of different hardware platforms. The results indicated that the A800 platform nearly achieved linear scalability; whereas the scalability efficiency of the RTX4090 and RTX3090 platforms was slightly lower, with the RTX4090 being 4.9% higher than the RTX3090. On the RTX3090, using NVLink can further enhance scalability efficiency by about 10%.
Comparison of Megatron-LM and DeepSpeed3.2 Scalability Efficiency Across Different GPU PlatformsBased on DeepSpeed and quantization techniques, the study researched the scalability efficiency of different hardware platforms. The results indicated that the A800 platform nearly achieved linear scalability; whereas the scalability efficiency of the RTX4090 and RTX3090 platforms was slightly lower, with the RTX4090 being 4.9% higher than the RTX3090. On the RTX3090, using NVLink can further enhance scalability efficiency by about 10%.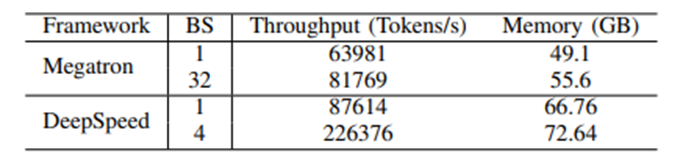 Scalability of data-parallel training on different GPUs3.3 Impact of Hardware and Optimization Techniques on Training PerformanceThe study also evaluated the impact of different memory and computational efficiency methods on training performance via DeepSpeed, with the results shown in the following table.
Scalability of data-parallel training on different GPUs3.3 Impact of Hardware and Optimization Techniques on Training PerformanceThe study also evaluated the impact of different memory and computational efficiency methods on training performance via DeepSpeed, with the results shown in the following table.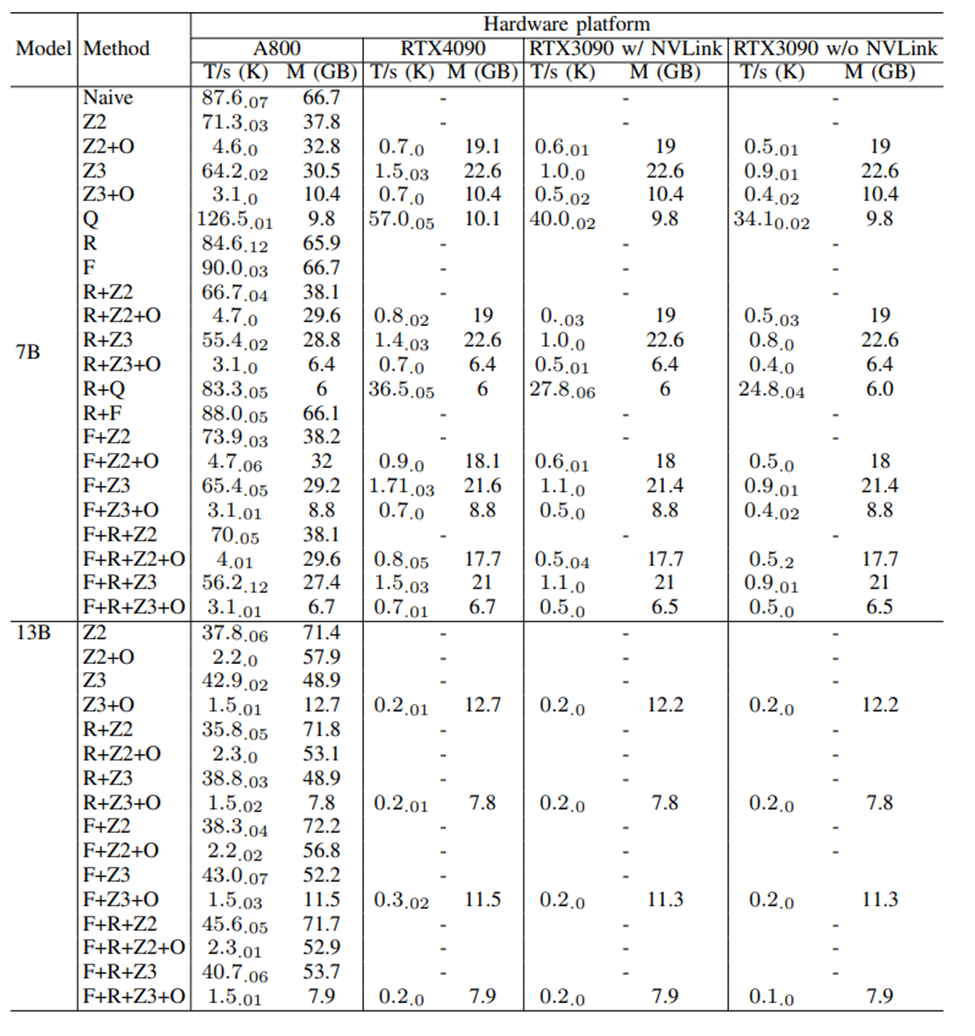 On four types of 8-GPU platforms, we compared the baseline setup (Naive), ZeRO-2 (Z2) and 3 (Z3), offloading (O), quantization (Q), activation value recomputation (R), and FlashAttention (F) on pre-training performance. The reported throughput is in units of 10^3 tokens/s (T/s), with the average and standard deviation of three independent runs shown at the lower right corner of each throughput value, along with peak GPU memory usage (M) in GB. In each run, throughput is averaged over 100 steps after 30 warm-up steps. “-” indicates out of memory (OOM).3.3.1 Impact of Hardware on Pre-trainingWhen considering hardware impact, the throughput of the A800 is generally 50 times that of the RTX4090 and RTX3090. However, when using quantization techniques, the performance of RTX GPUs can reach half that of the A800. In the comparison between RTX4090 and RTX3090, the performance of the RTX4090 is 50% higher than that of the RTX3090, while NVLink on the RTX3090 can enhance performance by approximately 10%.3.3.2 Analyzing SubmodulesTo gain a deeper understanding of pre-training performance, the study conducted a modular analysis of the pre-training process. An interesting finding is that about 37% of the time is spent on the optimizer. Further exploration of this phenomenon is planned, particularly regarding the impact of recomputation.The study also performed a time analysis on the forward and backward phases. In the Llama2 model, the decoder layer occupies most of the computation time. Notably, the multi-layer perceptron (MLP) and query, key, value (QKV) projections, which rely on General Matrix Multiplication (GEMM), are the most time-consuming parts. Additionally, the RMSNorm and RoPE modules also consume significant time due to numerous element-wise operations. In the backward phase, additional communication overhead occurs due to gradient synchronization across GPUs.
On four types of 8-GPU platforms, we compared the baseline setup (Naive), ZeRO-2 (Z2) and 3 (Z3), offloading (O), quantization (Q), activation value recomputation (R), and FlashAttention (F) on pre-training performance. The reported throughput is in units of 10^3 tokens/s (T/s), with the average and standard deviation of three independent runs shown at the lower right corner of each throughput value, along with peak GPU memory usage (M) in GB. In each run, throughput is averaged over 100 steps after 30 warm-up steps. “-” indicates out of memory (OOM).3.3.1 Impact of Hardware on Pre-trainingWhen considering hardware impact, the throughput of the A800 is generally 50 times that of the RTX4090 and RTX3090. However, when using quantization techniques, the performance of RTX GPUs can reach half that of the A800. In the comparison between RTX4090 and RTX3090, the performance of the RTX4090 is 50% higher than that of the RTX3090, while NVLink on the RTX3090 can enhance performance by approximately 10%.3.3.2 Analyzing SubmodulesTo gain a deeper understanding of pre-training performance, the study conducted a modular analysis of the pre-training process. An interesting finding is that about 37% of the time is spent on the optimizer. Further exploration of this phenomenon is planned, particularly regarding the impact of recomputation.The study also performed a time analysis on the forward and backward phases. In the Llama2 model, the decoder layer occupies most of the computation time. Notably, the multi-layer perceptron (MLP) and query, key, value (QKV) projections, which rely on General Matrix Multiplication (GEMM), are the most time-consuming parts. Additionally, the RMSNorm and RoPE modules also consume significant time due to numerous element-wise operations. In the backward phase, additional communication overhead occurs due to gradient synchronization across GPUs.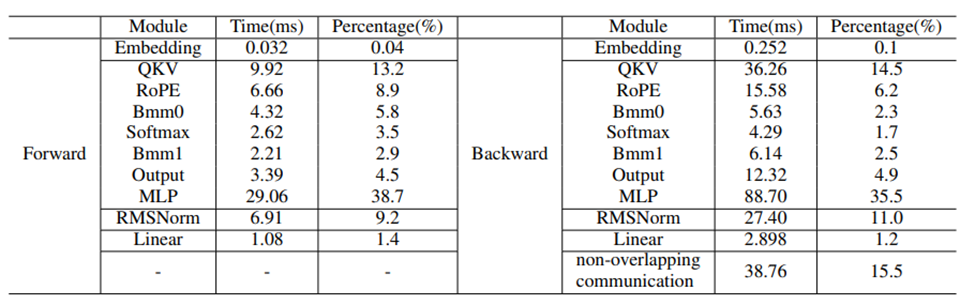 Time consumption and percentages of modules in the forward and backward phases for Llama2-7B. Time consumption of modules in the decoder layer is the cumulative time over 32 iterations.3.3.3 Impact of FlashAttentionThe table below shows that FlashAttention can improve the speed of the attention module by 34.9% and 24.7% respectively.
Time consumption and percentages of modules in the forward and backward phases for Llama2-7B. Time consumption of modules in the decoder layer is the cumulative time over 32 iterations.3.3.3 Impact of FlashAttentionThe table below shows that FlashAttention can improve the speed of the attention module by 34.9% and 24.7% respectively.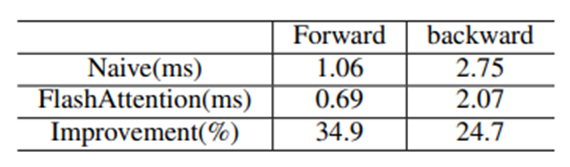 4. Fine-tuningIn terms of fine-tuning, this study focused on comparing the performance of LoRA and QLoRA under different model sizes and hardware settings. It was found that LoRA’s throughput is twice that of QLoRA, but QLoRA’s memory consumption is only half that of LoRA. When combined with FlashAttention and ZeRO-2, the throughput of LoRA fine-tuning increases by 20% and 10%. The throughput of fine-tuning the Llama2-13B model decreases by about 30% compared to the Llama2-7B model. Using all optimization techniques, even RTX4090 and RTX3090 can fine-tune the Llama2-70B model, with a total throughput of about 200 tokens per second.
4. Fine-tuningIn terms of fine-tuning, this study focused on comparing the performance of LoRA and QLoRA under different model sizes and hardware settings. It was found that LoRA’s throughput is twice that of QLoRA, but QLoRA’s memory consumption is only half that of LoRA. When combined with FlashAttention and ZeRO-2, the throughput of LoRA fine-tuning increases by 20% and 10%. The throughput of fine-tuning the Llama2-13B model decreases by about 30% compared to the Llama2-7B model. Using all optimization techniques, even RTX4090 and RTX3090 can fine-tune the Llama2-70B model, with a total throughput of about 200 tokens per second.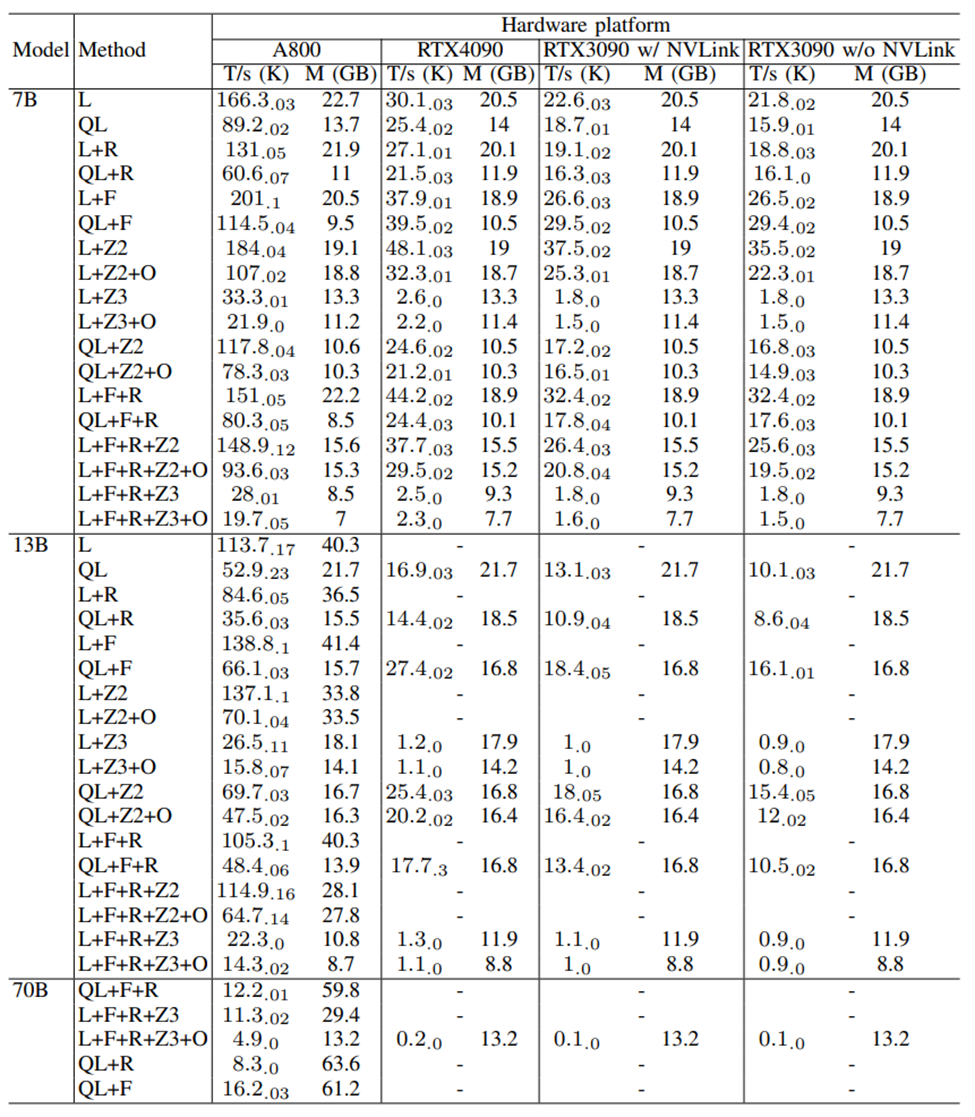 On four types of 8-GPU servers, including A800, RTX4090, RTX3090 w/ NVLink, and RTX3090 w/o NVLink, we compared the fine-tuning performance of LoRA (L), QLoRA (QL), and different optimization methods, including ZeRO stage 2 and 3 (Z2, Z3), FlashAttention (F), offloading (O), and activation recomputation (R). The batch size was fixed at 1. We reported the average throughput of 10^3 tokens/s (T/s) and its standard deviation in three independent runs, along with peak GPU memory usage (M) (in GB).5. Inference5.1 End-to-end Inference Performance Analysis5.1.1 Throughput AnalysisWhen comparing the throughput of different hardware platforms and inference frameworks, it was found that TGI performs well on 24GB GPUs, while LightLLM performs best on high-performance GPUs (such as A800/A100 series).
On four types of 8-GPU servers, including A800, RTX4090, RTX3090 w/ NVLink, and RTX3090 w/o NVLink, we compared the fine-tuning performance of LoRA (L), QLoRA (QL), and different optimization methods, including ZeRO stage 2 and 3 (Z2, Z3), FlashAttention (F), offloading (O), and activation recomputation (R). The batch size was fixed at 1. We reported the average throughput of 10^3 tokens/s (T/s) and its standard deviation in three independent runs, along with peak GPU memory usage (M) (in GB).5. Inference5.1 End-to-end Inference Performance Analysis5.1.1 Throughput AnalysisWhen comparing the throughput of different hardware platforms and inference frameworks, it was found that TGI performs well on 24GB GPUs, while LightLLM performs best on high-performance GPUs (such as A800/A100 series).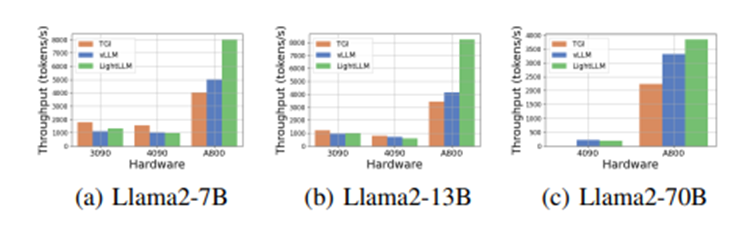 5.1.2 Latency ComparisonIn comparing the latency of different inference frameworks on the same GPU platform, it was found that TGI has the lowest latency on RTX3090 and A800, followed by LightLLM, while vLLM has the highest latency. Furthermore, inference time on consumer-grade GPUs increases with model parameters, especially on the RTX4090, where the inference time difference between Llama2-7B and Llama2-70B can reach 13 times. On the A800, the inference time difference for large models is smaller, indicating that the A800 can effectively handle large LLMs, and the 70B model has not reached its performance limit.
5.1.2 Latency ComparisonIn comparing the latency of different inference frameworks on the same GPU platform, it was found that TGI has the lowest latency on RTX3090 and A800, followed by LightLLM, while vLLM has the highest latency. Furthermore, inference time on consumer-grade GPUs increases with model parameters, especially on the RTX4090, where the inference time difference between Llama2-7B and Llama2-70B can reach 13 times. On the A800, the inference time difference for large models is smaller, indicating that the A800 can effectively handle large LLMs, and the 70B model has not reached its performance limit.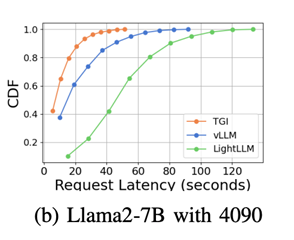 Llama2-7B on RTX3090 and A800
Llama2-7B on RTX3090 and A800 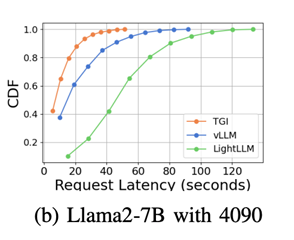
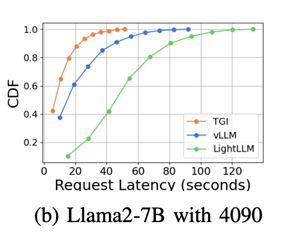 Comparison of 7B vs 70B on RTX40905.1.3 Inference SummaryIn terms of throughput and latency, the A800 platform outperforms the RTX3090 and RTX4090. The RTX3090 has a slight advantage over the RTX4090. The three inference frameworks perform similarly in terms of throughput, but the TGI framework performs better in terms of latency. On the A800, LightLLM achieves the highest throughput, with latency close to TGI.5.2 Micro-benchmarking5.2.1 Communication AnalysisThe study also tested the high-speed communication capabilities of NVLink. The tests showed that the RTX3090 equipped with NVLink outperformed the same model without NVLink in AllGather and ReduceScatter communication operations.
Comparison of 7B vs 70B on RTX40905.1.3 Inference SummaryIn terms of throughput and latency, the A800 platform outperforms the RTX3090 and RTX4090. The RTX3090 has a slight advantage over the RTX4090. The three inference frameworks perform similarly in terms of throughput, but the TGI framework performs better in terms of latency. On the A800, LightLLM achieves the highest throughput, with latency close to TGI.5.2 Micro-benchmarking5.2.1 Communication AnalysisThe study also tested the high-speed communication capabilities of NVLink. The tests showed that the RTX3090 equipped with NVLink outperformed the same model without NVLink in AllGather and ReduceScatter communication operations.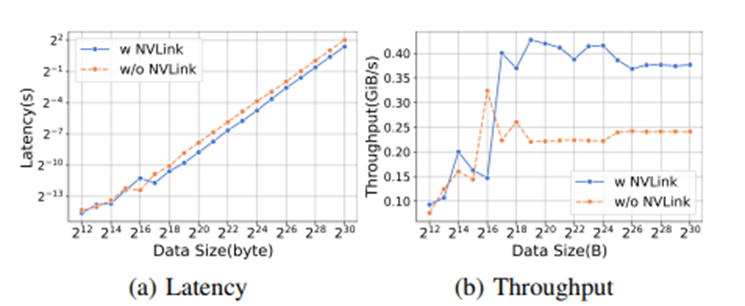 In data parallelism, the backward phase uses AllReduce to synchronize weights, while ZeRO-2 and ZeRO-3 use Reduce and ReduceScatter primitives respectively. The results indicate that NVLink significantly improves communication efficiency.
In data parallelism, the backward phase uses AllReduce to synchronize weights, while ZeRO-2 and ZeRO-3 use Reduce and ReduceScatter primitives respectively. The results indicate that NVLink significantly improves communication efficiency.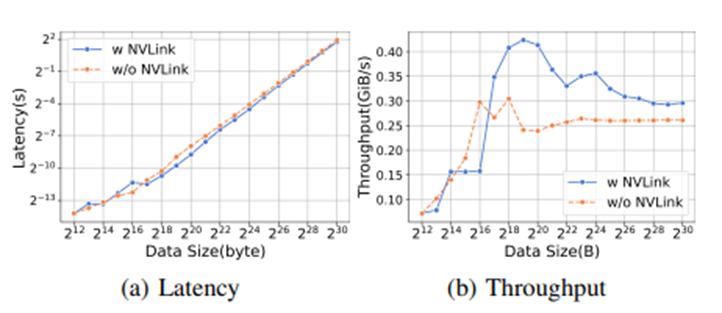 The experimental results show that the startup time of ReduceScatter kernels dominates when processing small data volumes, while performance for large data volumes relies on bandwidth. ZeRO-2 and ZeRO-3 use AllGather to update parameters, and their kernel performance is also similar.
The experimental results show that the startup time of ReduceScatter kernels dominates when processing small data volumes, while performance for large data volumes relies on bandwidth. ZeRO-2 and ZeRO-3 use AllGather to update parameters, and their kernel performance is also similar.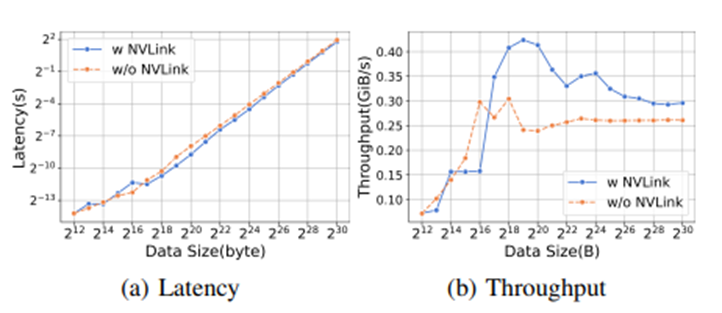 6. ConclusionThis study benchmarked the pre-training, fine-tuning, and deployment performance of LLMs on 8-card GPU hardware platforms including A800-80G, RTX4090, and RTX3090, analyzing the key modules and operations that impact total runtime. This provides important information for users in selecting hardware, software, and optimization technique configurations, aiding in the pre-training, fine-tuning, and deployment of LLMs, while also offering opportunities for system performance improvements. (For more detailed content, we welcome everyone to read the original article)
6. ConclusionThis study benchmarked the pre-training, fine-tuning, and deployment performance of LLMs on 8-card GPU hardware platforms including A800-80G, RTX4090, and RTX3090, analyzing the key modules and operations that impact total runtime. This provides important information for users in selecting hardware, software, and optimization technique configurations, aiding in the pre-training, fine-tuning, and deployment of LLMs, while also offering opportunities for system performance improvements. (For more detailed content, we welcome everyone to read the original article)
——END——
