

Author: GjZero
Tags: Bert, Chinese Classification, Sentence Vector
This article is about 1500 words, recommended reading time is 8 minutes.
This article starts from practice, guiding everyone through the tutorial on Chinese text classification using Bert and its use as a sentence vector.
Bert Introduction
The Bert model is a language representation model released by Google in October 2018. Bert has swept the optimal results of 11 tasks in the NLP field, making it one of the most significant breakthroughs in NLP today. The full name of the Bert model is Bidirectional Encoder Representations from Transformers, which is obtained by training a Masked Language Model and predicting the next sentence task. For more details on the specific training of Bert and more principles, interested readers can refer to the original paper on arXiv. This article starts from practice, guiding everyone through the tutorial on Chinese text classification using Bert and its use as a sentence vector.
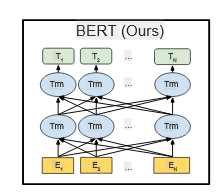
For the text classification task, N characters in a sentence correspond to E_1,…,E_N, which are N embeddings. Text classification is actually connecting the T_1 layer obtained from BERT to a fully connected layer for multi-class classification.
Preparation Work
1. Download Bert
Enter the following command in the terminal:
git clone
https://github.com/google-research/bert.git
2. Download the Bert Pre-trained Model
Google provides various pre-trained Bert models, available for different languages and model sizes. For the Chinese model, we use Bert-Base, Chinese. To download this model, you may need to use a VPN. If you need to download other models (English and other languages), you can find the download links in the Bert repository under Pre-trained models.
3. (Optional)
Install bert-as-service, which is a service that uses the Bert model to map sentences to fixed-length vectors.
Enter the following command in the terminal:
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of ‘bert-serving-server’
This service requires a minimum version of TensorFlow 1.10.
Prepare Data
Data Format
For the Chinese text classification problem, you need to organize the dataset into a usable format. Different formats correspond to different DataProcessor classes. You can save the data in the following format:
game APEX is a newly released battle royale game.
technology Google is about to release TensorFlow 2.0.
Each line represents a text, consisting of a label followed by a tab and the body text.
Split the text into three files: train.tsv (training set), dev.tsv (validation set), and test.tsv (test set); then place them in the same data_dir folder.
Write DataProcessor Class
In the “run_classifier.py” file in the Bert folder, add the processors content in the “def main(_):” function as follows:
python
processors = {
“cola”: ColaProcessor,
“mnli”: MnliProcessor,
“mrpc”: MrpcProcessor,
“xnli”: XnliProcessor,
“mytask”: MyTaskProcessor,
}
Implement the following “MyTaskProcessor” (DataProcessor) class and place this code alongside other processors in “run_classifier.py”.
In the “__init__(self)” method, self.labels contains all classification labels; in this example, we will classify the text into 3 categories: game, fashion, houseliving.
python
class MyTaskProcessor(DataProcessor):
“””Processor for the News data set (GLUE version).”””
def __init__(self):
self.labels = [‘game’, ‘fashion’, ‘houseliving’]
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, “train.tsv”)), “train”)
def get_dev_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, “dev.tsv”)), “dev”)
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, “test.tsv”)), “test”)
def get_labels(self):
return self.labels
def _create_examples(self, lines, set_type):
“””Creates examples for the training and dev sets.”””
examples = []
for (i, line) in enumerate(lines):
guid = “%s-%s” % (set_type, i)
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
If the data format is not a label followed by a tab and a piece of text, you need to modify the implementation of “_create_examples()”.
Write Run Script
Create a run script file named “run.sh” and edit its content as follows:
bash
export DATA_DIR=/media/ganjinzero/Code/bert/data/
export BERT_BASE_DIR=/media/ganjinzero/Code/bert/chinese_L-12_H-768_A-12
python run_classifier.py \
–task_name=mytask \
–do_train=true \
–do_eval=true \
–data_dir=$DATA_DIR/ \
–vocab_file=$BERT_BASE_DIR/vocab.txt \
–bert_config_file=$BERT_BASE_DIR/bert_config.json \
–init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
–max_seq_length=128 \
–train_batch_size=32 \
–learning_rate=2e-5 \
–num_train_epochs=3.0 \
–output_dir=/mytask_output
Where DATA_DIR is the folder where your training text data is located, and BERT_BASE_DIR is the address where your Bert pre-trained model is stored. The task_name must match the name in your DataProcessor class. The following parameters, do_train indicates whether to fine-tune, do_eval indicates whether to evaluate, and the not mentioned parameter do_predict indicates whether to make predictions. If fine-tuning is not required, or if the GPU configuration is too low, you can remove do_train. max_seq_length represents the maximum length of the sentence, and can be reduced if memory is insufficient.
Make Predictions
Run the script:
bash
./run.sh
You can get results similar to the following:
***** Eval results *****
eval_accuracy = 0.845588
eval_loss = 0.505248
global_step = 343
loss = 0.505248
If such output appears, it means the run was successful. In the output_dir folder specified in “run.sh”, you can see the model’s evaluation results and the model file after fine-tuning.
Using Bert as Sentence Vectors
If you want to use the encoding of the Bert model along with other models, it is meaningful to use the Bert model as sentence vectors (also known as sentence-level encoding). We can achieve this goal using bert-as-service.
After installing bert-as-service, you can use the Bert model to map sentences to fixed-length vectors. Start the service with the following command in the terminal:
bash
bert-serving-start -model_dir /media/ganjinzero/Code/bert/chinese_L-12_H-768_A-12 -num_worker=4
The parameter after model_dir is the folder where the Bert pre-trained model is located. The number of num_worker should be based on your CPU/GPU count.
Now you can call the following command in Python:
python
from bert_serving.client import BertClient
bc = BertClient()
bc.encode([‘一二三四五六七八’, ‘今天您吃了吗?’])
It is best to pass the parameters to “bc.encode()” in a list format rather than a single string, as this improves the efficiency of the program.
Reference Documents
[Github:bert]
(https://github.com/google-research/bert)
[arXiv:bert](https://arxiv.org/pdf/1810.04805.pdf)
[Github:bert-as-service](https://github.com/hanxiao/bert-as-service)
Author Introduction

GjZero, a second-year PhD student at Tsinghua University’s Statistics Center. His research focuses on natural language processing in medical informatics. His interests include games related to game theory such as poker and mahjong.
Github:
https://github.com/GanjinZero
Personal Homepage:
https://ganjinzero.github.io/
Editor: Wenjing
Proofreader: Lin Yilin

