
Author: Chen Zhiyan
This article is about 3000 words, recommended reading time is 7 minutes.
This article introduces the use of the BERT model to automatically classify, filter, and summarize a large amount of COVID-19 information on Twitter.
Twitter has always been an important source of news, and during the COVID-19 pandemic, the public can express their anxiety on Twitter. However, manually classifying, filtering, and summarizing the vast amount of COVID-19 information on Twitter is almost impossible. This daunting and challenging task falls on BERT, which is the go-to machine learning tool in the field of Natural Language Processing (NLP). The BERT model is used to automatically classify, filter, and summarize the massive COVID-19 information on Twitter, improving the understanding of relevant COVID-19 content on Twitter and enabling analysis and summarization of this content, which is referred to as the COVID-Twitter-BERT model, abbreviated as CT-BERT.
The model is based on the BERT-LARGE (English, case insensitive, full-word masking) model. BERT-LARGE is mainly trained on large raw text datasets such as English Wikipedia (3.5B words) and free book corpora (0.8B words). Although these datasets contain a vast amount of data, they do not include relevant information from specialized subfields. In some specific professional areas, there have been cases of training specialized domain corpora using transformer models, such as BIOBERT and SCIBERT, all of which adopt the same unsupervised training techniques MLM / NSP / SOP and require huge hardware resources. A more common and general approach is to first train weights using general models, and after completing pre-training in specialized fields, replace the general pre-training results with the specialized pre-training results and input them into downstream tasks for training.
1. Training Process
The CT-BERT model is trained on a 160M corpus, which collects tweets about the coronavirus from January 12, 2020, to April 16, 2020, using the Twitter filtering API to listen for a set of English keywords related to COVID-19. Before training, the retweet labels in the original corpus are cleaned, a generic text replaces each tweet’s username, and similar operations are performed on all URLs and program pages. Additionally, all unicode emojis are replaced with text ASCII representations (for example, replacing smiley faces with “smile”). Finally, all retweets and duplicate data are removed from the dataset, resulting in a final corpus of 22.5 million tweets totaling 0.6B words. The content of the specialized pre-training dataset is one-seventh the size of the general model’s dataset. Each tweet is treated as an independent document, and the spaCy library is used to split it into independent sentences.
All sequences input into BERT are transformed into a token set consisting of a vocabulary of 30,000 words, with each tweet message limited to 280 characters, and a maximum sequence length of 96 tokens. The training batch size is increased to 1024, generating 285M training examples and 2.5M validation examples on the dataset. The continuous learning rate is set to 2e-5, and the model’s parameter settings during pre-training on the specialized dataset are consistent with the parameters recommended by Google on GitHub.
The loss and accuracy are calculated through pre-training programs, saving a checkpoint every 100,000 training steps and positioning it for various types of downstream classification tasks. Distributed training runs continuously for 120 hours on TPUv3-8 (128GB) using TensorFlow 2.2.
CT-BERT is a transformer-based model pre-trained on a large corpus of tweets related to COVID-19. The v2 model is trained based on 9,700 tweets (1.2B training examples).
CT-BERT is used to train specific professional domain datasets, and the training evaluation results indicate that the performance of this model will improve by 10-30% compared to the standard BERT-Large model, especially on the dataset of tweets related to COVID-19, where performance improvements are particularly significant.
2. Training Method
If you are familiar with fine-tuning transformer models, you can download the CT-BERT model from two channels: either through TFHub or from Huggingface.

Figure 1
Huggingface
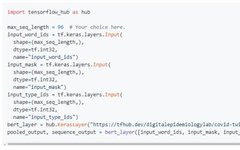
Load the pre-trained model from Huggingface:

Figure 2
You can use the built-in pipeline to predict internal identifiers:
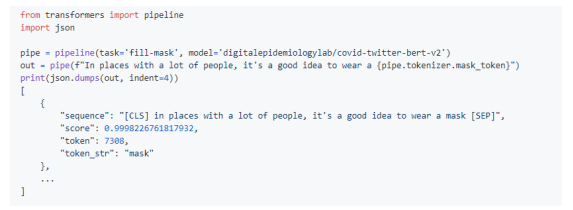
Figure 3
Load the pre-trained model from TF-Hub:
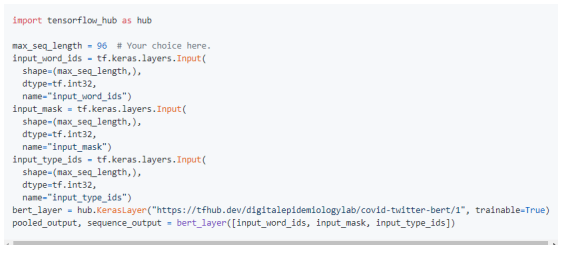
Figure 4
Use the following script to fine-tune CT-BERT
The script run_finetune.py can be used to train the classifier, which depends on the official BERT model implementation under TensorFlow 2.2/Keras framework.
Before running the code, the following settings need to be made:
-
Google Cloud bucket;
-
Google Cloud virtual machine running TensorFlow 2.2;
-
TPU running TensorFlow 2.2 in the same zone as the virtual machine.
If doing research work, you can apply for access to TPU and/or Google Cloud.
Installation
Recursively clone the repository:

Figure 5
The code is developed using tf-nightly and ensures backward compatibility to run on TensorFlow 2.2. It is recommended to use Anaconda to manage Python versions:

Figure 6
Install requirements.txt

Figure 7
3. Data Preparation
Divide the data into training dataset: train.tsv and validation dataset dev.tsv in the following format:

Figure 8
Place the prepared two dataset files in the following folder data/finetune/originals/<dataset_name>/(train|dev).tsv
Then run:
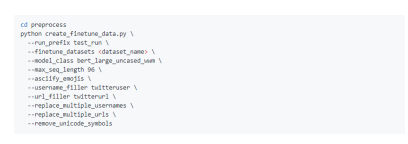
Figure 9
Afterwards, TF_Record files will be generated in the data/finetune/run_2020-05-19_14-14-53_517063_test_run/<dataset_name>/tfrecords. directory,
Load the data:

Figure 10
4. Pre-training
The pre-training code is based on existing pre-trained models (such as BERT-Large) for unsupervised pre-training on domain-targeted data (in this case, Twitter data). This code can, in principle, be used for pre-training on any specialized domain dataset.
Data Preparation Stage
The data preparation stage consists of two steps:
Data Cleaning Stage
In the first step, run the following script to clean user names/URLs and other information using asciifying emojis:
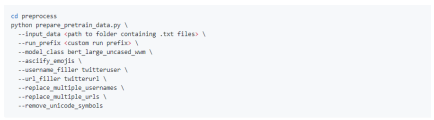
Figure 11
In the second step, generate TFrecord files for pre-training

Figure 12
This process will consume a lot of memory and may take a long time, so you can choose the already prepared TFrecord files max_num_cpus, and the preprocessed data is stored in data/pretrain/<run_name>/tfrecords/ directory.
Just synchronize the prepared data:

Figure 13
Pre-training
Before the pre-training model, make sure to extract the compressed file located at gs://cloud-tpu-checkpoints/bert/keras_bert/wwm_uncased_L-24_H-1024_A-16.tar.gz and copy the pre-trained model to gs://<bucket_name>/pretrained_models/bert/keras_bert/wwm_uncased_L-24_H-1024_A-16/ directory:
After loading the model and TFrecord files, access the TPU and bucket on the Google Cloud virtual machine (both must be in the same zone).
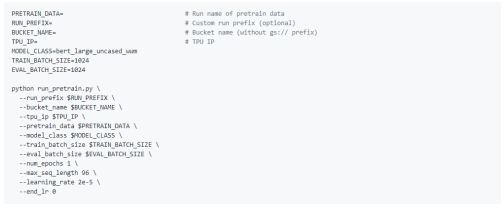
Figure 14
In the gs://<bucket_name>/pretrain/runs/<run_name> directory, running log files and model checkpoint files will be generated
5. Fine-tuning
Use the following command to fine-tune this dataset with CT-BERT:

Figure 15
Run the configuration file for training, saving the running log files to gs://<bucket_name>/covid-bert/finetune/runs/run_2020-04-29_21-20-52_656110_<run_prefix>/. In the TensorFlow log files, the run_logs.json file contains all relevant training information.
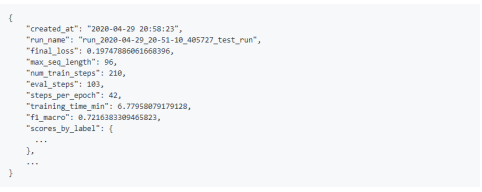
Figure 16
Run the sync_bucket_data.py script on your local machine to download the training log files:

Figure 17
The model training utilized TensorFlow Research Cloud (TFRC) and resources provided by Google Cloud for COVID-19 research.
6. Model Evaluation
Five independent training sets were selected to evaluate the actual performance of the model applied to downstream tasks. Three of the datasets are public datasets, and two come from unpublished internal projects, all datasets include Twitter data related to COVID-19.
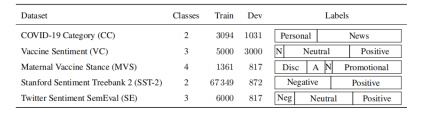
Figure 18: Overview of Evaluation Datasets: All five evaluation datasets are labeled multi-class datasets, visualized through the width of the ratio bar in the label column, where N and Neg represent negative sentiment; Disc and A represent frustrated and uncertain emotions, respectively.
7. Training Results
Figure 19 shows the results of CT-BERT after pre-training for 25k steps on the validation dataset and performing 1k steps of validation. All metrics are validated throughout the training process. Notably, there was a significant improvement in performance on the MLM loss task, achieving a final loss value of 1.48. The NSP task’s loss showed only slight improvement, as its initial performance was already quite good. Training was halted at 500,000 steps, equivalent to training on 512M samples, corresponding to about 1.8 epochs. All performance metrics for MLM tasks and NLM tasks improved steadily throughout the training process. However, using the losses/metrics from these tasks to evaluate the correct timing for stopping training is relatively difficult.
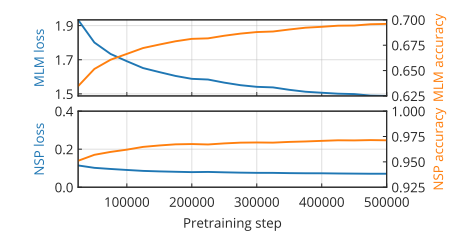
Figure 19: CT-BERT Domain-Specific Dataset Pre-training Evaluation Metrics. Shows the loss and accuracy for the masked language model (MLM) and next sentence prediction (NSP) tasks.
Experiments indicate that after completing 200,000 pre-training steps, downstream performance begins to improve rapidly. On the other hand, after completing 200,000 pre-training steps, the loss curve also gradually increases. For datasets related to COVID-19, significant improvements in downstream performance are observed after completing 200,000 pre-training steps. The SST-2, the only non-Twitter dataset, shows much slower performance improvement, starting to improve only after completing 200,000 pre-training steps.
Even when the same model runs on the same dataset, performance differences can be observed to some extent. This difference is dataset-related, but it does not significantly increase throughout the pre-training process, and is roughly similar to the differences observed when running BERT-LARGE. Training on the SE dataset is the most stable, while training on the SST-2 dataset is the least stable, with most differences within the margin of error.
8. Conclusion
Although using CT-BERT can significantly improve the performance of classification tasks, experiments have not yet been conducted on applying CT-BERT to other natural language processing tasks. Additionally, at the time of writing this article, access was only available to one COVID-19 related dataset. The next steps could include further improving model performance by modifying hyperparameters such as learning rate, training batch size, and optimizer. Future work may include evaluating training results on other datasets.
DataPi Research Department Introduction
The DataPi Research Department was established in early 2017, dividing into multiple groups based on interest, with each group following the overall knowledge sharing and practice project planning of the research department while having its own characteristics:
Algorithm Model Group: Actively participates in competitions such as Kaggle, original hands-on teaching series articles;
Research and Analysis Group: Investigates the application of big data through interviews, exploring the beauty of data products;
System Platform Group: Tracks cutting-edge technology in big data & artificial intelligence system platforms, conversing with experts;
Natural Language Processing Group: Focuses on practice, actively participates in competitions and plans various text analysis projects;
Manufacturing Big Data Group: Upholds the dream of becoming an industrial power, combining industry, academia, research, and government to explore data value;
Data Visualization Group: Merges information with art, exploring the beauty of data, learning to tell stories through visualization;
Web Crawling Group: Crawls web information, collaborating with other groups to develop creative projects.
Click on the end of the article “Read the Original” to sign up as a DataPi Research Department Volunteer, there is always a group suitable for you~
Reprint Notice
If you need to reprint, please prominently indicate the author and source at the beginning of the article (reprinted from: DataPi THUID: DatapiTHU), and place a prominent QR code for DataPi at the end of the article. For articles with original identification, please send [Article Name – Public Account Name and ID to be Authorized] to the contact email to apply for whitelist authorization and edit as required.
Unauthorized reprints and adaptations will be pursued legally.

Click “Read the Original” to join the organization~