
Follow the public account “ML_NLP“

Bert is a pre-trained model that has dominated the leaderboard of natural language processing tasks since its introduction; numerous improved pre-trained models based on it have also emerged. This article does not explain what Bert is, but attempts to compare and analyze various pre-trained models from the perspective of MASK application, allowing readers to re-examine these models from a previously unconsidered angle and clearly understand the innovations made on Bert by various pre-trained models.
We generally do not directly use Bert to solve downstream application tasks; instead, we fine-tune it on specific data before using it. This actually involves two stages: the first stage involves feeding large amounts of data to Bert for indiscriminate learning, which is akin to learning foundational knowledge (such as literacy, sentence formation, and cloze tests); the second stage is the fine-tuning phase, where a small amount of labeled domain data is used to fine-tune Bert, similar to learning from a reading comprehension exercise and then applying that knowledge (after fine-tuning) to more reading comprehension tasks.
The learning objectives during Bert’s pre-training phase are two:
-
Masked LM
-
Next Sentence Prediction
Masked LM refers to the masked language model, which differs from general language models, such as N-gram language models. The probability of the i-th character in an N-gram language model is related to the preceding i-1 characters; that is, to predict the i-th character, the model must first predict the first through the i-1 characters sequentially before predicting the i-th character. Such models are generally referred to as autoregressive models (Autoregressive LM); Masked LM randomly masks certain characters in a sentence and predicts the masked characters based on their context, thus we call this type of language model an autoencoder language model (Autoencoder LM).
Bert’s MASK mechanism works as follows: it randomly selects 15% of the tokens in a sentence, then replaces 80% of the tokens with the [MASK] symbol, replaces 10% with random other tokens, and keeps the remaining 10% unchanged.
Although it seems that Bert’s pre-training phase uses unlabeled data, appearing as unsupervised learning, we can see that through [MASK], the model has already utilized labels for classification task training, which is somewhat similar to the word vector model CBOW. However, it uses a more powerful Transformer as a semantic feature extractor, thus considering longer contextual information rather than merely utilizing a window length of tokens with a shallow fully connected neural network for training. Additionally, while CBOW learns static word vectors for each token after training, Bert learns a “learning capability,” meaning it can learn the word vectors of tokens based on their contextual information for downstream tasks. This type of word vector is dynamic, effectively addressing the issue of polysemy (i.e., the same token has different word vector embeddings in different contextual environments).
Explanation of MASK
The MASK serves two purposes: first, it handles non-fixed-length input sequences, such as those used in RNNs and Attention, where a MASK matrix is generally constructed containing only 0s and 1s; second, it prevents label leakage, as used in models like Bert, UNILM, and XLNET, where placeholders like [MASK] or a MASK matrix are employed.
In fact, when processing non-fixed-length input sequences in neural networks, we use Padding to adjust sentences to a fixed-length vector, filling shorter sentences with 0s. As shown in the example below:

The purpose of this is to facilitate batch training calculations for the model; however, it introduces a problem, as we generally perform a max pooling or average pooling operation after passing through RNN or CNN. Let’s take a look at the calculation results below.
Assuming the input dimension is (1,4,4), meaning a batch size of 1, and the sentence length after padding is 4, with a word vector dimension of 4, as shown below:
tensor = [[[-0.31374098, 1.37414397, 0.55369354, 1.48887183], [-1.66548506, 2.54986855, -0.11285839, 0.62201919], [-0.13604648, 0.91690237, 0.05759679, -1.06613941], [0, 0, 0, 0 ]]]The last one is the padding vector, and performing global max pooling and average pooling yields:
max_pooling = [[0. , 2.54986855, 0.55369354, 1.48887183]]mean_pooling = [[-0.52881813, 1.21022872, 0.12460799, 0.2611879 ]]If we do not perform padding (removing the last all-zero vector), the max pooling and average pooling results would be:
max_pooling = [[-0.13604648, 2.54986855,0.55369354, 1.48887183]]mean_pooling = [[-0.70509084, 1.6136383 , 0.16614398, 0.34825054]]We can see that padding affects the model’s learning results, so how do we eliminate this influence? The answer is to use the MASK matrix. For the above example, our MASK matrix is represented as follows:
M = [[1,1,1,0]]Its dimensions are generally batchsize * maxlen, where maxlen represents the maximum sentence length. In M, 1 indicates that the position is a normal token, while 0 indicates that the position is padding; thus, subsequent calculations need to ignore the information at that position. After adding the MASK matrix, the average pooling calculation formula is as follows:
mean_pooling = np.sum(tensor * M.T, axis=1)/np.sum(M,axis=1)Where .T indicates the transposition of the sentence, resulting in [[-0.70509084, 1.6136383 , 0.16614398, 0.34825054]], which is consistent with not performing padding.
max_pooling = np.max(tensor - (1-M.T) * 1e10 , axis=1)This means subtracting an infinitely large value from the padding positions in the sentence, making them infinitely small, so that during max calculations, we do not select this padding value, yielding the result [[-0.13604648, 2.54986855, 0.55369354, 1.48887183]], which is consistent with not performing padding.
In Attention, the MASK mechanism is similar to that of max pooling; after calculating the similarity matrix through q and k, we subtract an infinitely large value from the padding parts of the matrix, making them infinitely small, so that in softmax calculations, the weights of the padding parts are set to 0. Its calculation formula is as follows:
softmax(score) = softmax(score - (1-Mask.T) * 1e10)Here, the Mask matrix is no longer the previously input-related M matrix, but a transformed Mask matrix. To elaborate on this would take considerable length, and I will write a separate article on this in the future if the opportunity arises. In summary, the MASK here is also to eliminate the influence of padding.
As for how to use MASK to prevent label leakage, we will discuss it in conjunction with various Bert model variants below.
RoBERTa: Using Dynamic MASK Strategy
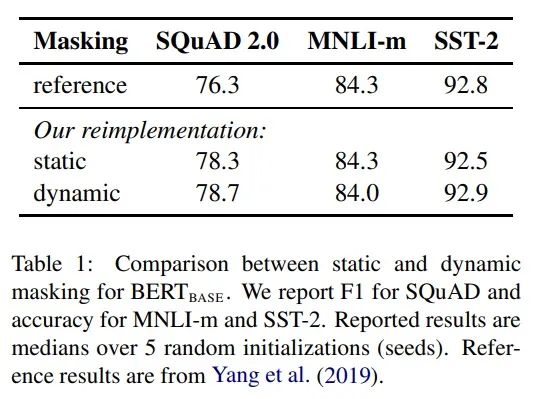
Before training the Bert model, during data preprocessing, it determines which characters to MASK, and in subsequent epochs, each training sample has the same MASK, which is a static MASK. RoBERTa employs a dynamic MASK strategy by copying training samples 10 times, randomly MASKing them 10 times, and then training for 40 epochs, meaning each training sample’s MASK strategy will be trained 4 times, which seems to increase the number of training samples. However, I believe this dynamic MASK is not necessarily effective, because increasing the data by “10 times” effectively increases the training time by 10 times, with an improvement of only 0.4 percentage points (as shown below), and it is still unclear whether this improvement is due to the dynamic MASK strategy.
Of course, RoBERTa not only uses dynamic MASK but also implements the following improvements (referred to as more refined tuning):
-
Removes the Next Sentence Prediction task, so the input is no longer in pairs, but uses a DOC-SENTENCES format, meaning each training sample comes from the same document, with a maximum length of 512. If the length is too short, it dynamically increases the batch size.
-
Increases the training batch size; the original Bert was 256, while RoBERTa uses batch sizes of 2000 and 8000 for training, resulting in better performance. Along with increasing the batch size, the learning rate is also increased.
-
Uses Byte-Pair Encoding (BPE) to construct the vocab; BPE combines character-level and word-level representations by statistically analyzing subword units in the training corpus. RoBERTa employs a vocabulary size of 50,000, which is 20,000 more than Bert, thus increasing many training parameters.
As we can see, RoBERTa does not make significant innovations compared to Bert; aside from dynamic MASK, other improvements have been previously proposed.
ERNIE (Baidu): MASKing Phrases and Entities
Bert randomly MASKs at the character level, while this model MASKs entire entities (such as names, places, organizations, and products) or phrases (obtained using lexical analysis tools). The comparison between them is shown in the figure below:
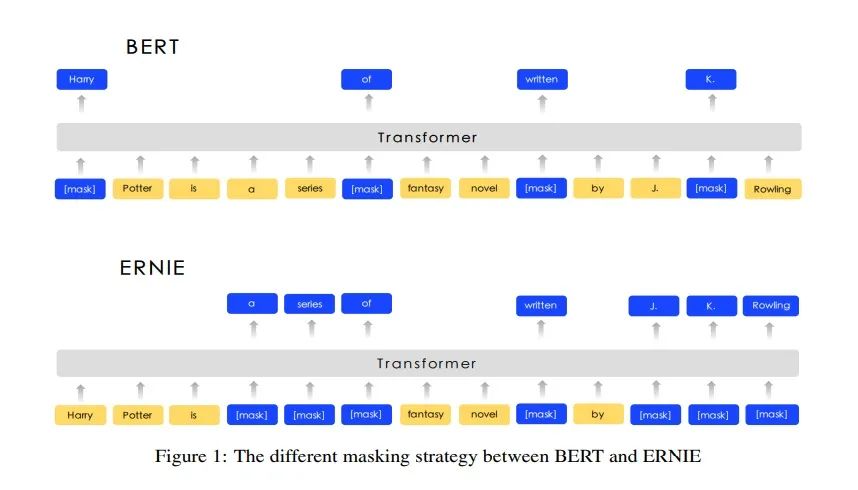
The article suggests that this MASK strategy enables the model to learn stronger semantic expression capabilities and is very suitable for Chinese tasks. Clearly, if you were to fill in the blanks in a sentence like:
A common __ problem is that input sequences have different lengths
You would easily know to fill in “seen” and “list” without needing to consider the context. However, if the sentence were framed like this:
A __ problem is that input __ sequences have different lengths
Then you would need to think about what to fill in based on more distant contextual information. This is similar to the model’s learning process; if the model can predict “seen” just from “common,” it would not create a significant loss gradient to optimize model parameters, leading to insufficient learning.
Chinese-BERT-wwm: Whole-Word Masking Strategy
Bert MASKs characters; if a character happens to be part of a word, the entire word is masked, resulting in the Chinese-BERT-wwm model, which is evidently designed for Chinese corpus. As shown in the figure below:

Additionally, this model is pre-trained based on Bert rather than starting from scratch; it is quite similar to Baidu’s ERNIE, but is said to perform slightly better in certain experiments.
UniLM: Simultaneously Training Multiple Language Models Using Three MASK Strategies
Self-encoding language models like Bert have the advantage of naturally integrating bidirectional language models, allowing them to learn the contextual semantics of words while seeing both preceding and following words. This is suitable for natural language understanding tasks; however, it is inherently unsuitable for natural language generation tasks due to the sequential nature of generating predictions. The issue arises because in the pre-training phase, a [MASK] token is introduced on the input side, while during downstream task fine-tuning, the input will not have [MASK] tokens, resulting in inconsistency between the two phases.
So how can we create a model that possesses both advanced natural language understanding capabilities and strong natural language generation abilities? Microsoft proposed the UniLM model, which I previously introduced in the article on vector-based deep semantic similarity text retrieval. The key to its capabilities lies in training three different language models using different MASK mechanisms within the self-attention of the Transformer during pre-training.
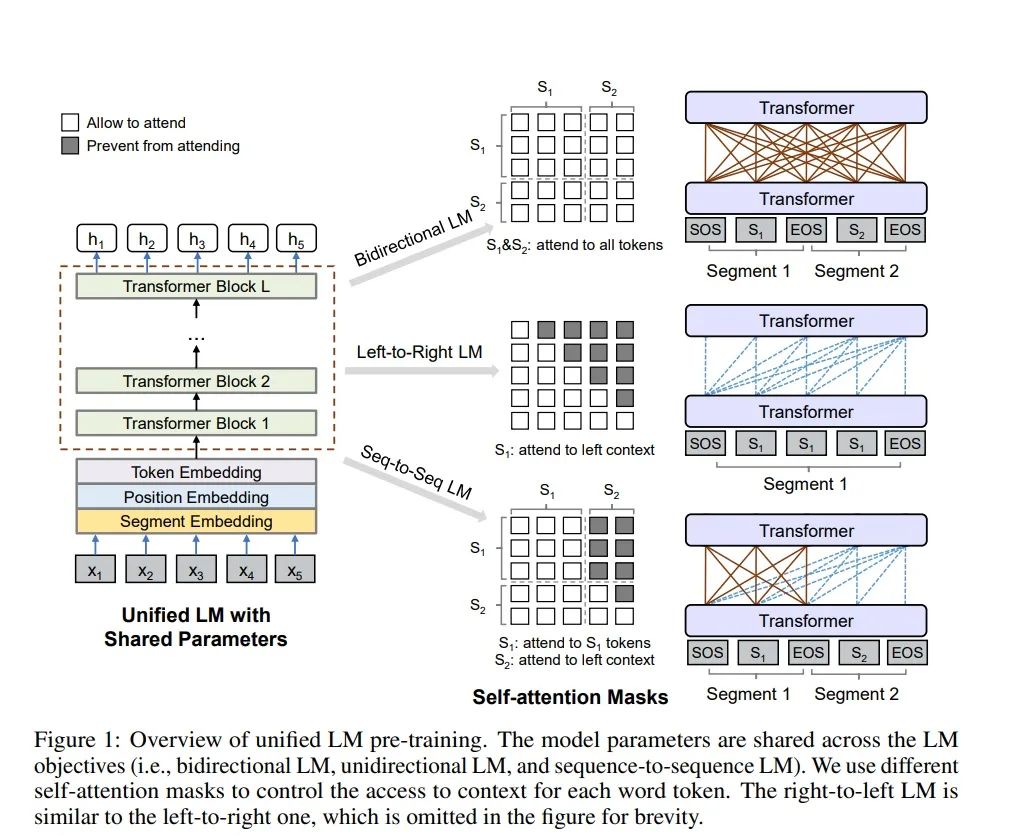
As shown in the figure below, UniLM uses shared Transformer layer parameters and simultaneously trains three tasks: unidirectional language model (unidirectional LM), bidirectional language model (bidirectional LM), and sequence-to-sequence model (sequence-to-sequence LM), using MASK to control which direction and how many contextual tokens the current token should attend to.
What are the MASK strategies? Let’s introduce them one by one.
-
For the bidirectional language model, the MASK matrix elements are all 0, indicating that all tokens can mutually perform attention operations to calculate semantic relationships.
-
For the unidirectional language model, taking left-to-right as an example, for the input “x1 x2 [MASK] x4,” if we want to predict [MASK], we only use the information to the left, x1 x2. To achieve this, we need to use a triangular matrix for the MASK, where all elements in the upper right corner are set to negative infinity to indicate inaccessibility, while other elements are set to 0 to indicate accessibility, as shown in the figure.
-
For the sequence-to-sequence model, the input consists of two concatenated sequences, designated as s1 and s2, where s1 contains t1 t2 and s2 contains t3 t4 t5; the input format is “[SOS] t1 t2 [EOS] t3 t4 t5 [EOS].” During training, t1 and t2 can access the information of the four tokens [SOS] t1 t2 [EOS], but cannot access information from s2; while t3 t4 t5 can access information from both s1 and s2. Therefore, its MASK matrix is illustrated in the third MASK matrix shown in the figure. If this is unclear, you can refer to the corresponding section in the article for clarification.
It is important to note that the MASK matrix in the self-attention of the UNILM model differs from the MASK in the attention discussed earlier; the UNILM MASK is designed to prevent label leakage, while the MASK applied in attention before softmax is to eliminate the influence of padding. However, they are essentially similar, as you can consider the tokens needing to be masked (to prevent label leakage) as extra tokens padded in. The subsequent operations will be the same. Thus, the only difference lies in how the MASK matrix is generated: one MASK matrix is generated based on the padded input, while the other is generated based on predefined strategies for different training tasks.
Other detailed issues include:
-
In training the bidirectional language model, the Next Sentence Prediction task is still retained, while the other language models do not retain it;
-
In the unidirectional language model, only one segment is used as input, while the other two language models, like Bert, use two segments concatenated as input, with [SOS] as the starting identifier for segments and [EOS] as the ending identifier;
-
Different segment embeddings are used to identify different language model tasks;
-
In each training batch, one-third of the time is spent training the bidirectional language model, one-third on the sequence-to-sequence model, and each sixth on training the left-to-right and right-to-left unidirectional language models;
-
Using the Bert-LARGE model for parameter initialization, the proportion of [MASK] placeholders is set the same as Bert, but in addition to masking single tokens, 20% of the time, bigrams or trigrams are masked (similar to ERNIE’s phrase MASK);
-
Other details will not be discussed further.
Overall, I believe the UniLM model introduces significant innovations based on Bert, unlike the other pre-trained models discussed above, which merely make slight adjustments.
XLNET: Innovative MASK for Self-encoding Models to Perform Autoregressive Pre-training
The authors of XLNET, like those of UNILM, also recognized the shortcomings of the self-encoding language model Bert. They sought to develop a model that possesses both natural language understanding capabilities and natural language generation abilities. However, unlike UNILM, XLNET does not train three language models; instead, it uses Attention Masks to create a so-called Two-Stream Self-Attention.
As mentioned earlier, Bert’s pre-training phase forcibly adds [MASK] identifiers on the input side, while no such identifiers are present during fine-tuning, leading to inconsistencies that affect downstream task performance. Moreover, while the application of [MASK] allows the model to learn contextual semantics, it assumes independence between the masked token and its context (cannot use the product rule to model joint probabilities?), overly simplifying the common high-order and long-range dependencies in natural language. In summary, while it is acceptable to forcibly add [MASK] during the pre-training phase, it is not ideal and does not align with the requirements of autoregressive language models! Therefore, XLNET proposes the following: during autoregressive modeling, the input side does not add [MASK] placeholders, creating uniformity between the pre-training and downstream fine-tuning phases. However, without [MASK], how can we train in an autoregressive manner while obtaining contextual information like Bert? XLNET introduces the Permutation Language Model as a training objective during pre-training. Assume our training sample s consists of words t1, t2, t3, t4; if we need to predict t3, according to autoregressive language model practices, we can only see the information of t1 and t2, but not t4. The Permutation Language Model fixes the position of t3 while randomly shuffling the other words t1, t2, and t4 (permutations). For instance, if the shuffled order becomes t2, t4, t3, t1, then while predicting t3, we can see t2 and t4 (which are both before t3). This provides the necessary contextual information for t3, effectively achieving a bidirectional language model. However, during actual pre-training, we cannot literally shuffle the input since the input will not be shuffled during downstream fine-tuning; thus, the XLNET model employs a dual-stream self-attention mechanism to realize this idea.
The figure below illustrates the architecture of the dual-stream self-attention mechanism, consisting of a content stream and a query stream (used to replace the [MASK] token in Bert). The MASK matrices of the two streams differ.
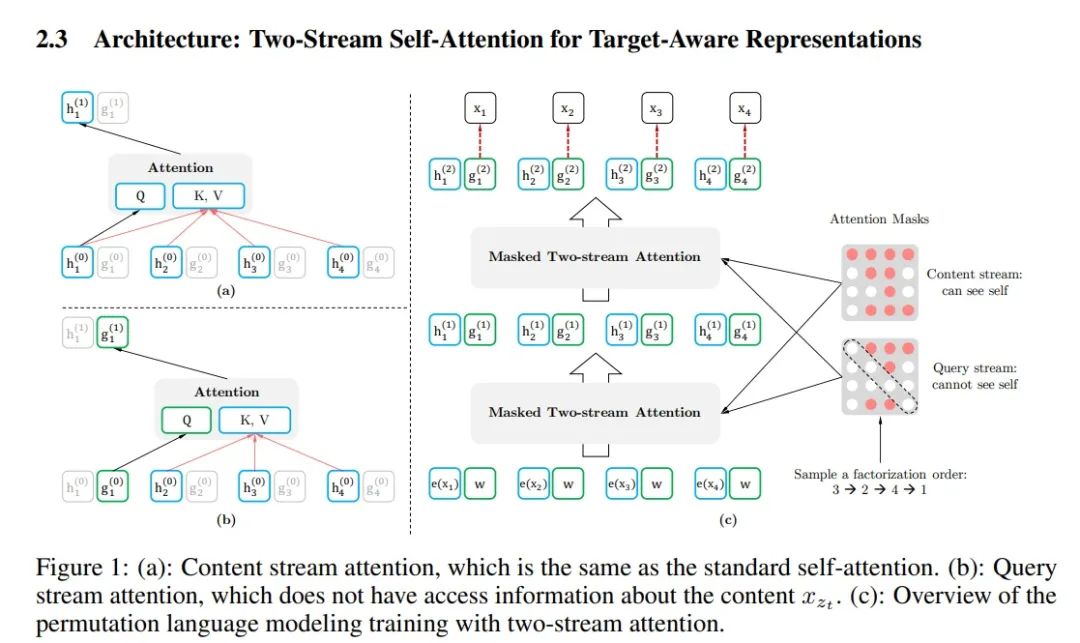
In the MASK matrix, the red points indicate visible tokens, while the white points indicate invisible tokens. The example in the figure shows the effect of “shuffling” the sequence t1, t2, t3, t4 into t3, t2, t4, t1. Why? The query stream matrix consists of four rows and four columns, with the first row indicating what token t1 can see, the second row what token t2 can see, and so forth. The red circle in the first row and second column indicates that t1 can see t2. We can see that the query stream MASK matrix indicates that t1 can see t2, t3, and t4, while t2 can see t3, and t3 cannot see anything. Thus, t3 is positioned first, where it can see nothing, while t2 is positioned second, allowing it to see its preceding token t3.
Other detailed issues include:
-
Using Transformer-XL instead of the Transformer in Bert, integrating relative positional encoding and segment recurrence mechanisms, which can handle longer documents;
-
Removing the Next Sentence Prediction task;
-
The dual-stream self-attention mechanism is only present during pre-training, and not during downstream fine-tuning.
SpanBERT: MASKing Longer Sequences
SpanBERT, like ERNIE, no longer MASKs individual tokens but MASKs contiguous sequences (masking contiguous random spans), which naturally includes phrases, entities, etc. A key difference is that SpanBERT introduces the span-boundary objective (SBO).
How does Span Masking work? First, it randomly selects a span length L based on a geometric distribution, then randomly chooses a starting position, and finally MASKs L tokens starting from that position. The average size of L is about 3.8 tokens; similarly, 15% of the tokens (spans) are MASKed, with 80% replaced by [MASK], 10% randomly replaced, and 10% remaining unchanged.
Lastly, let’s look at what SBO is. As shown in the figure, it adds the SBO loss to the total loss. During pre-training, to predict each token in the span, the loss formula for each token is as follows: if we are predicting the token “football,” we not only calculate its loss in the MLM language model (as in Bert), but also consider the information from the previous and next tokens in the span, as well as the positional information of “football” within the span.
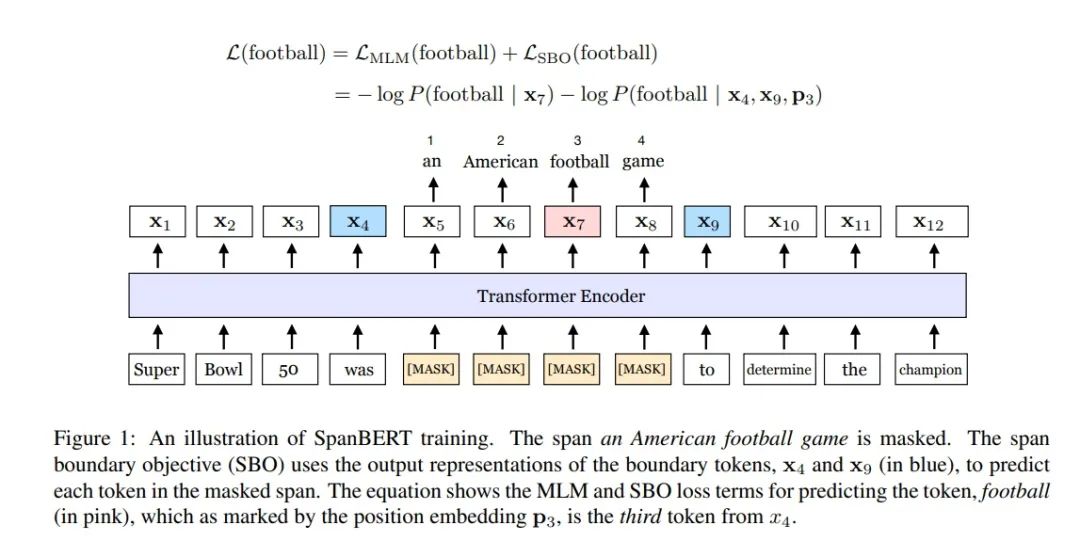
Moreover, like most other variants, this model also removes the Next Sentence Prediction task, no longer using two segments concatenated for input, but instead uses Single-Sequence training.
Through these various MASK modifications, we have explored different models based on Bert’s pre-training framework. This article has analyzed these models from the perspective of MASK application. If there are any misinterpretations in this analysis, please feel free to provide feedback.
Repository access shared:
Reply "code" in the background of the Machine Learning Algorithms and Natural Language Processing public account to obtain 195 NAACL and 295 ACL2019 papers with open-source code. The open-source address is: https://github.com/yizhen20133868/NLP-Conferences-Code
Big news! The Machine Learning Algorithms and Natural Language Processing communication group has officially been established! There are vast resources within the group, and everyone is welcome to join and learn!
Additional bonus resources! Deep learning and neural networks by Qiu Xipeng, official PyTorch Chinese tutorial, data analysis using Python, machine learning notes, official documentation of pandas in Chinese, effective java (Chinese version), and 20 other welfare resources.
How to obtain: After joining the group, click on the group announcement to get the download link. Please remember to modify the note to [School/Company + Name + Field] when adding.
For example, - Harbin Institute of Technology + Zhang San + Dialogue System.
Please avoid adding if you are a business person. Thank you!
Recommended reading:
Review of Open-Domain Knowledge Base Question Answering Research
Automatically Train Your Deep Neural Networks Using PyTorch Lightning
Collection of Common Code Snippets in PyTorch