
Jishi Guide
In this article, the author presents a relatively complex self-attention replacement example project developed based on Diffusers, aimed at enhancing the consistency of SD video generation. Throughout this process, the author discusses the usage of AttentionProcessor-related interface functions and learns how to implement a code-maintainable multi-behavior attention processing class based on a global management class. >> Join the Jishi CV technology exchange group, stay at the forefront of computer vision
When using the pre-trained Stable Diffusion (SD) to generate images, if the input K, V of its U-Net’s self-attention layer at a certain denoising moment is replaced with that of another reference image, the output image will be more similar to the reference image. Many SD editing research works that do not require training utilize this property. Especially for video editing tasks, if the attention input is replaced with that of the previous frame when generating a certain frame, the output video will be more coherent. In this article, we will quickly learn the principles of SD self-attention replacement technology and implement a video editing pipeline based on this technology in Diffusers.
Attention Calculation
Let’s first review the attention mechanism proposed in the Transformer paper. All attention mechanisms are based on a computation called Scaled Dot-Product Attention:
Where, . The attention calculation can be understood as first calculating the similarity of vectors of length to vectors of length, and then using this similarity as weights to calculate the weighted sum of vectors of length.
Attention calculations are parameter-free. To include parameters, the Transformer designed the attention layer as shown below, where are parameters.
Generally, when using an attention layer, it is set to . This type of attention is called cross-attention. Cross-attention can be understood as data wanting to extract information from data, based on the similarity of each vector in to each vector in.
A special case of cross-attention is self-attention, where . This indicates that the vectors within the data exchange information pairwise.
Self-Attention Replacement in SD
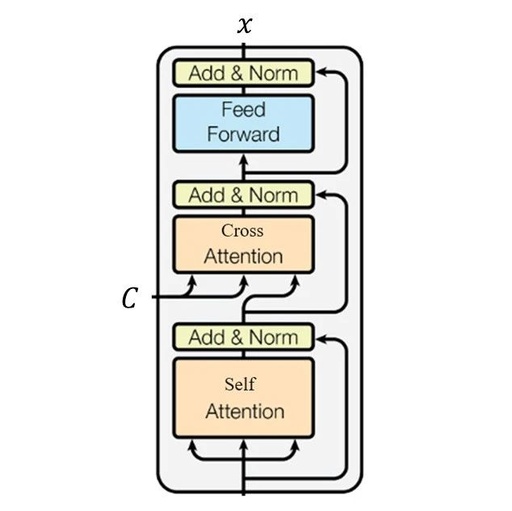
The U-Net in SD utilizes both self-attention and cross-attention. Self-attention is used for aggregating internal information of image features. Cross-attention is used to align the generated image with text, where Q comes from image features and K, V come from text encoding.
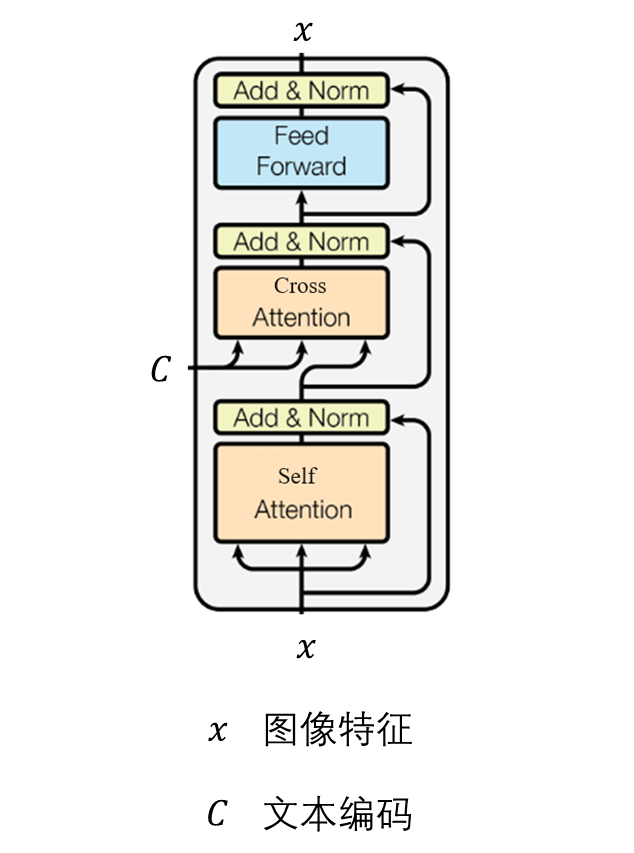
Since self-attention can actually be viewed as a special case of cross-attention, we can replace the K, V of self-attention with features from another reference image. This way, the generated image from the diffusion model will be similar to both the intended image and the reference image. Of course, the features used for replacement must have the same “format” as the original features, otherwise meaningful results cannot be generated.
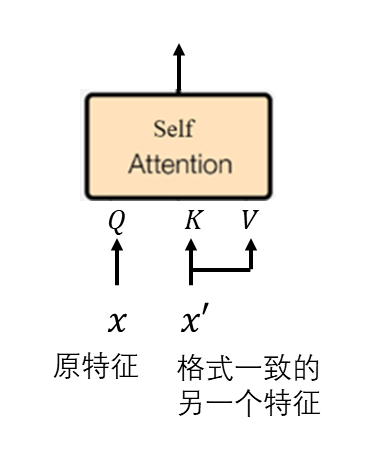
What does “format consistent” mean? We know that the diffusion model has many steps during sampling, and each self-attention layer in U-Net has its own “format” for inputs at each step. In other words, if you want to replace the K, V of a certain self-attention layer at a certain moment, you must first generate a reference image and replace it with the input of that self-attention layer at that moment during the generation of the reference image, rather than using inputs from other moments or other self-attention layers.
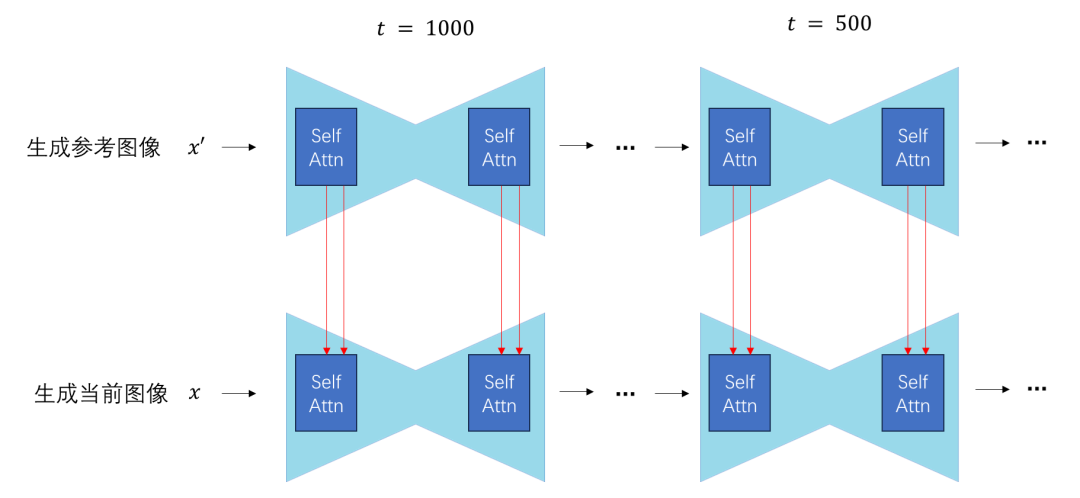
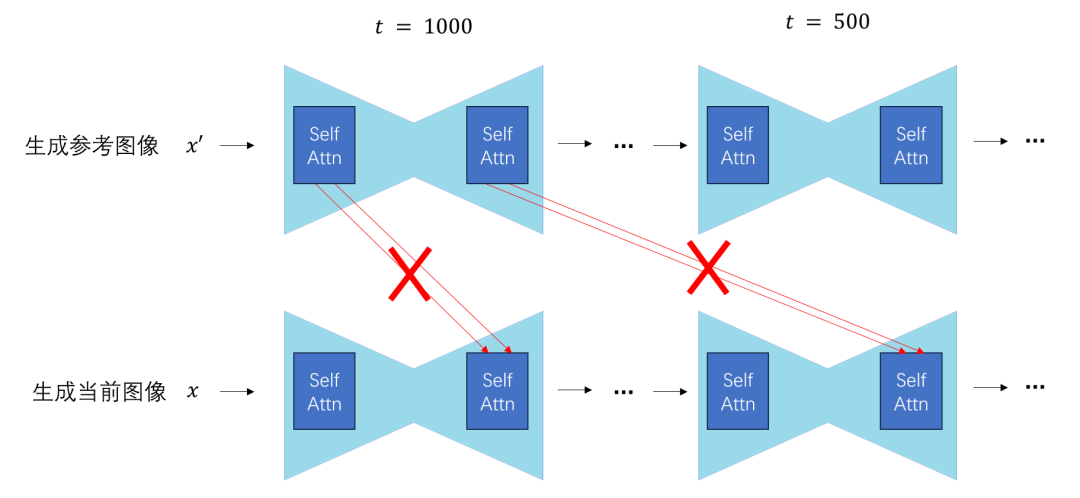
Generally, this editing technique is only applied to self-attention layers rather than cross-attention layers, because in SD, cross-attention is used to relate images to text, and information from another image cannot be input. Of course, aside from SD, any diffusion model that utilizes self-attention modules can adopt this editing method, though most works are developed based on SD.
Applications of Self-Attention Replacement
The most common application of self-attention replacement is to enhance the continuity of SD video editing. In this task, the first frame is typically edited normally, and then the K, V of the self-attention for subsequent frames are replaced with those of the first frame. This technique is generally referred to in the literature as cross-frame attention. The work that proposed this method earlier is Text2Video-Zero.
Self-attention replacement can also be used to improve the fidelity of single-image editing. An example is the drag-and-drop single-image DragonDiffusion. This application can be extended to image interpolation, such as DiffMorpher, which interpolates the self-attention inputs of two reference images in proportion during image interpolation, replacing the K, V of the corresponding interpolated image’s self-attention.
Implementing Self-Attention Replacement in Diffusers
The U-Net in Diffusers specifically provides an AttentionProcessor class for modifying attention calculations. With the relevant interfaces, we can easily modify the method of calculating attention. In this example project, we will implement an SD video editing pipeline that references the first frame and the previous frame’s attention inputs using Diffusers. Compared to generating edited images frame by frame, the results of this pipeline will be smoother. Project URL: https://github.com/SingleZombie/DiffusersExample/tree/main/ReplaceAttn
AttentionProcessor
In Diffusers, each attention module in U-Net has an instance of the AttentionProcessor class. The __call__ method of the AttentionProcessor class describes the process of attention calculation. If we want to modify the calculation of certain attention modules, we need to define our own attention processing class, whose __call__ method’s parameters must be compatible with those of AttentionProcessor. Afterwards, we can call the relevant interfaces to replace the original processing class with our own. Below, we will first look at the implementation details of the AttentionProcessor class, and then implement our own attention processing class.
The AttentionProcessor class is located in diffusers/models/attention_processor.py. It has only one __call__ method, whose main content is as follows:
class AttnProcessor:
def __call__(
self,
attn: Attention,
hidden_states: torch.FloatTensor,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
temb: Optional[torch.FloatTensor] = None,
scale: float = 1.0,
) -> torch.Tensor:
residual = hidden_states
query = attn.to_q(hidden_states, *args)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
key = attn.to_k(encoder_hidden_states, *args)
value = attn.to_v(encoder_hidden_states, *args)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states, *args)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
In the method parameters, hidden_states is Q, and encoder_hidden_states is K, V. If K, V are not passed in (i.e., None), then K, V will be assigned as Q. The implementation details of this method are exactly the same as those in the attention layer of the Transformer, so we won’t elaborate further here. Generally, when replacing the inputs of attention, we do not modify the implementation of this method; we will only call this method when necessary.
There is another class in attention_processor.py with similar functionality, AttnProcessor2_0, which differs from AttentionProcessor in that it calls the operator F.scaled_dot_product_attention enabled in PyTorch 2.0 instead of manually implementing attention calculation. This operator is more efficient; if you are certain that your PyTorch version is at least 2.0, you can use AttnProcessor2_0 instead of AttentionProcessor.
After reviewing the AttentionProcessor class, let’s see how to replace the original attention processing class with our own in U-Net. The attn_processors attribute of the U-Net class will return a dictionary, where the keys are the locations of each processing class, such as down_blocks.0.attentions.0.transformer_blocks.0.attn1.processor, and the values are instances of each processing class. To replace the processing class, we need to construct a dictionary attn_processor_dict in the same format, and then call unet.set_attn_processor(attn_processor_dict) to replace the original attn_processors. If we have implemented our processing class MyAttnProcessor, we can write the following code to achieve the replacement:
attn_processor_dict = {}
for k in unet.attn_processors.keys():
if we_want_to_modify(k):
attn_processor_dict[k] = MyAttnProcessor()
else:
attn_processor_dict[k] = AttnProcessor()
unet.set_attn_processor(attn_processor_dict)
Implementing Cross-Frame Attention Processing Class
Having familiarized ourselves with the AttentionProcessor class, let’s now write our own cross-frame attention processing class. When processing the first frame, the behavior of this class remains unchanged. For each subsequent frame, the K, V inputs of this class will be replaced with the concatenated results of the first frame and the previous frame’s inputs along the sequence length dimension, i.e.,
Are you wondering: why can the sequence length of K, V be modified? Don’t forget that in attention calculation, the shapes of Q, K, V are: . Attention calculation only requires that the sequence lengths of K and V are the same, and does not require that the sequence lengths of Q and K are the same.
Now, the attention calculation is no longer a stateless computation; its result depends on the inputs of the first frame and the previous frame. Therefore, we need to maintain these two variables in the attention processing class. We can write the constructor of the class as follows:
class CrossFrameAttnProcessor(AttnProcessor):
def __init__(self):
super().__init__()
self.first_maps = {}
self.prev_maps = {}
In the run method, we determine whether the attention is self-attention or cross-attention based on whether encoder_hidden_states is empty. We only modify self-attention. When the attention is self-attention, assuming we know the current moment t, we can obtain the inputs of the first frame and the previous frame at that moment and concatenate them to get cross_map. With this cross_map as the K, V of the current attention, we achieve cross-frame attention.
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, **kwargs):
if encoder_hidden_states is None:
# Is self attention
cross_map = torch.cat(
(self.first_maps[t], self.prev_maps[t]), dim=1)
res = super().__call__(attn, hidden_states, cross_map, **kwargs)
else:
# Is cross attention
res = super().__call__(attn, hidden_states, encoder_hidden_states, **kwargs)
return res
Since Diffusers frequently modifies function interfaces, when calling the ordinary attention calculation interface, it is best to write it exactly as
super().__call__(..., **kwargs)to ensure that this code remains compatible with future versions of Diffusers.
The above code only describes the behavior for subsequent frames. As mentioned earlier, our attention calculation has two different behaviors: for the first frame, we do not modify the attention calculation process, only caching its input; for each subsequent frame, we replace the attention inputs while maintaining the input of the current “previous frame”. Since the attention behaves differently in different situations, we should use a variable to record the current state, allowing __call__ to decide the current behavior based on this variable. The related pseudocode is as follows:
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, **kwargs):
if encoder_hidden_states is None:
# Is self attention
if self.state == FIRST_FRAME:
res = super().__call__(attn, hidden_states, cross_map, **kwargs)
# update maps
else:
cross_map = torch.cat(
(self.first_maps[t], self.prev_maps[t]), dim=1)
res = super().__call__(attn, hidden_states, cross_map, **kwargs)
# update maps
else:
# Is cross attention
res = super().__call__(attn, hidden_states, encoder_hidden_states, **kwargs)
return res
In the pseudocode, self.state represents the current state of the attention, indicating whether the attention calculation is processing the first frame or subsequent frames. In the video editing pipeline, we should follow the pseudocode below to first edit the first frame, then modify the attention state and edit the subsequent frames.
edit(frames[0])
set_attn_state(SUBSEQUENT_FRAMES)
for i in range(1, len(frames)):
edit(frames[i])
Now, there is a question: how do we modify the state of each attention module’s processor? Obviously, the most straightforward way is to find a way to access each attention module’s processor and directly modify the object’s property.
modules = unet.get_attn_moduels
for module in modules:
if we_want_to_modify(module):
module.processor.state = ...
However, traversing all modules each time can make the code more cluttered. Furthermore, this approach brings maintenance issues: every time we traverse the attention modules, we may need to determine whether that attention module should be modified. When using the previously discussed processing class replacement method unet.set_attn_processor, we also need to check once again. Repeating the same logic in two places is not conducive to code updates.
A more elegant implementation is to define a state management class, from which all attention processors can obtain the current state information. To modify the state of each processor, we only need to change the global state management class object once, without having to traverse all objects.
Following this implementation approach, we first write a state class.
class AttnState:
STORE = 0
LOAD = 1
def __init__(self):
self.reset()
@property
def state(self):
return self.__state
def reset(self):
self.__state = AttnState.STORE
def to_load(self):
self.__state = AttnState.LOAD
In the attention processing class, we save a reference to the state class object during initialization and obtain the current state based on the state class object during runtime.
class CrossFrameAttnProcessor(AttnProcessor):
def __init__(self, attn_state: AttnState):
super().__init__()
self.attn_state = attn_state
self.first_maps = {}
self.prev_maps = {}
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, **kwargs):
if encoder_hidden_states is None:
# Is self attention
if self.attn_state.state == AttnState.STORE:
res = super().__call__(attn, hidden_states, encoder_hidden_states, **kwargs)
else:
cross_map = torch.cat(
(self.first_maps[t], self.prev_maps[t]), dim=1)
res = super().__call__(attn, hidden_states, cross_map, **kwargs)
else:
# Is cross attention
res = super().__call__(attn, hidden_states, encoder_hidden_states, **kwargs)
return res
So far, assuming that the previous inputs have been maintained, our attention processing class can execute two different behaviors. Now, let’s implement the maintenance of previous inputs. When using the previous attention inputs, we actually need to know the current moment t. The current moment can also be considered another state, and it is best to maintain it in the state management class as well. However, to simplify our code, we can let each processing class maintain the current moment itself. The specific approach is: if we know the total number of denoising iterations, we can let the current moment increment from 0 until the maximum moment, then reset to 0. The complete code with time handling and previous input maintenance is as follows:
class AttnState:
STORE = 0
LOAD = 1
def __init__(self):
self.reset()
@property
def state(self):
return self.__state
@property
def timestep(self):
return self.__timestep
def set_timestep(self, t):
self.__timestep = t
def reset(self):
self.__state = AttnState.STORE
self.__timestep = 0
def to_load(self):
self.__state = AttnState.LOAD
class CrossFrameAttnProcessor(AttnProcessor):
def __init__(self, attn_state: AttnState):
super().__init__()
self.attn_state = attn_state
self.cur_timestep = 0
self.first_maps = {}
self.prev_maps = {}
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, **kwargs):
if encoder_hidden_states is None:
# Is self attention
tot_timestep = self.attn_state.timestep
if self.attn_state.state == AttnState.STORE:
self.first_maps[self.cur_timestep] = hidden_states.detach()
self.prev_maps[self.cur_timestep] = hidden_states.detach()
res = super().__call__(attn, hidden_states, encoder_hidden_states, **kwargs)
else:
tmp = hidden_states.detach()
cross_map = torch.cat(
(self.first_maps[self.cur_timestep], self.prev_maps[self.cur_timestep]), dim=1)
res = super().__call__(attn, hidden_states, cross_map, **kwargs)
self.prev_maps[self.cur_timestep] = tmp
self.cur_timestep += 1
if self.cur_timestep == tot_timestep:
self.cur_timestep = 0
else:
# Is cross attention
res = super().__call__(attn, hidden_states, encoder_hidden_states, **kwargs)
return res
In the code, tot_timestep represents the total number of moments, and cur_timestep represents the current moment. After each computation, cur_timestep increments until it reaches the total number of moments, after which it resets to 0. When processing the first frame, we store the current moment’s input in both the first frame cache first_maps and the previous frame cache prev_maps. For subsequent frames, we first perform attention calculation with the replaced input, then update the previous frame cache prev_maps.
Video Editing Pipeline
After preparing our custom cross-frame attention processing class, we will write a simple Diffusers video processing pipeline. This pipeline is based on ControlNet and the image-to-image pipeline, and its main code is as follows:
class VideoEditingPipeline(StableDiffusionControlNetImg2ImgPipeline):
def __init__(self,
...
):
super().__init__(...)
self.attn_state = AttnState()
attn_processor_dict = {}
for k in unet.attn_processors.keys():
if k.startswith("up"):
attn_processor_dict[k] = CrossFrameAttnProcessor(
self.attn_state)
else:
attn_processor_dict[k] = AttnProcessor()
self.unet.set_attn_processor(attn_processor_dict)
def __call__(self, *args, images=None, control_images=None, **kwargs):
self.attn_state.reset()
self.attn_state.set_timestep(
int(kwargs['num_inference_steps'] * kwargs['strength']))
outputs = [super().__call__(
*args, **kwargs, image=images[0], control_image=control_images[0]).images[0]]
self.attn_state.to_load()
for i in range(1, len(images)):
image = images[i]
control_image = control_images[i]
outputs.append(super().__call__(
*args, **kwargs, image=image, control_image=control_image).images[0])
return outputs
In the constructor, we create a global attention state object attn_state. A reference to this object will be passed to each cross-frame attention processing object. Generally, when modifying self-attention modules, only the upsampling parts of U-Net are modified, leaving the downsampling and intermediate parts untouched. Therefore, when filtering attention modules, our condition is k.startswith("up"). After filling in the new attention processor dictionary, we update all processing class objects using unet.set_attn_processor.
self.attn_state = AttnState()
attn_processor_dict = {}
for k in unet.attn_processors.keys():
if k.startswith("up"):
attn_processor_dict[k] = CrossFrameAttnProcessor(
self.attn_state)
else:
attn_processor_dict[k] = AttnProcessor()
self.unet.set_attn_processor(attn_processor_dict)
In the __call__ method, we need to implement our video editing pipeline based on the original image editing pipeline super().__call__(). In this process, our main task is to maintain the state in the attention management object. Initially, we reset the management class and set the maximum denoising moment number based on parameters. After resetting, the attention processor’s state defaults to STORE, meaning it will save the input of the first frame. After processing the first frame, we run attn_state.to_load() to change the state of the attention processors, allowing them to read the inputs of the first and previous frames before maintaining the input cache of the previous frame during each attention operation.
def __call__(self, *args, images=None, control_images=None, **kwargs):
self.attn_state.reset()
self.attn_state.set_timestep(
int(kwargs['num_inference_steps'] * kwargs['strength']))
outputs = [super().__call__(
*args, **kwargs, image=images[0], control_image=control_images[0]).images[0]]
self.attn_state.to_load()
for i in range(1, len(images)):
image = images[i]
control_image = control_images[i]
outputs.append(super().__call__(
*args, **kwargs, image=image, control_image=control_image).images[0])
return outputs
The example script for running this pipeline is located in the replace_attn.py file in the project root directory. The video used in the example can be downloaded from https://github.com/williamyang1991/Rerender_A_Video/blob/main/videos/pexels-koolshooters-7322716.mp4, and should be renamed to woman.mp4. The output results with and without using the new attention processor are as follows:
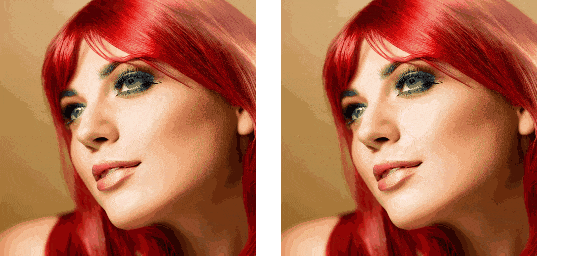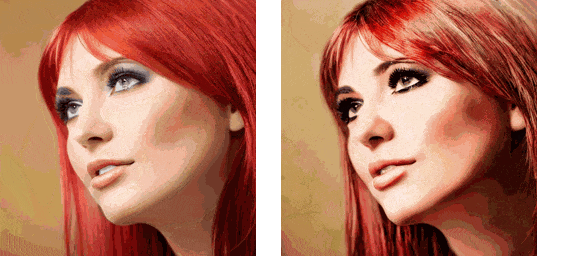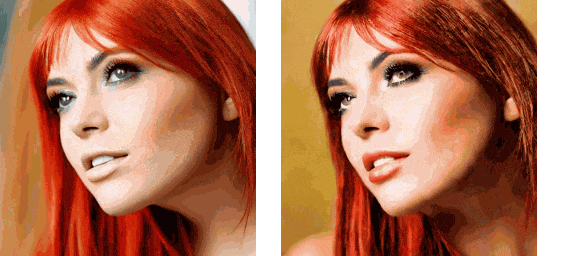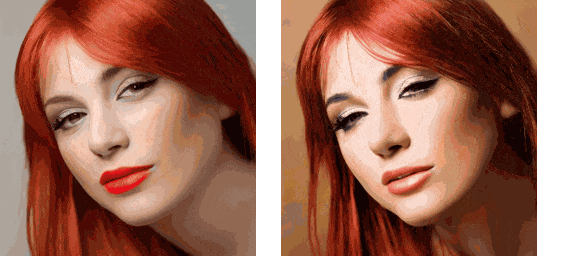
As can be seen, although attention replacement cannot solve the flickering problem in generated videos, the consistency between frames has improved significantly. By combining attention replacement technology with other techniques, we can create a decent SD video generation tool.
Conclusion
Self-attention replacement in diffusion models is a common technique to enhance image consistency. The implementation method of this technique is to replace the K, V inputs of self-attention in the diffusion model’s U-Net with those of another image. In this article, we learned about a relatively complex self-attention replacement example project developed based on Diffusers, aimed at enhancing the consistency of SD video generation. Throughout this process, we learned about the usage of the AttentionProcessor related interface functions and how to implement a code-maintainable multi-behavior attention processing class based on a global management class. If you can understand the examples in this article, you will encounter no difficulties when developing attention processing classes in Diffusers.
Project URL: https://github.com/SingleZombie/DiffusersExample/tree/main/ReplaceAttn
If you want to further learn about the development of video editing pipelines in Diffusers, you can refer to the pipeline I wrote for Diffusers: https://github.com/huggingface/diffusers/tree/main/examples/community#Rerender_A_Video

Reply in the public account with “Dataset” to get 100+ resources sorted by deep learning in various directions
Jishi Highlights

Click to read the original text and enter the CV community
Gain more technical highlights