Machine Heart reports
Machine Heart Editorial Department
With a theoretical foundation, we can perform deep optimization.
Why is the performance of transformers so good? Where does the context learning (In-Context Learning) ability it brings to many large language models come from? In the field of artificial intelligence, transformers have become the dominant model in deep learning, but the theoretical foundation for their outstanding performance has been under-researched.
Recently, new research from Google AI, ETH Zurich, and Google DeepMind researchers attempts to unveil the mystery for us. In the new study, they reverse-engineered transformers and found some optimization methods. The paper titled “Uncovering mesa-optimization algorithms in Transformers”:
Paper link: https://arxiv.org/abs/2309.05858
The authors demonstrate that minimizing the general autoregressive loss leads to a gradient-based optimization algorithm that runs during the forward pass of the transformer. This phenomenon has recently been referred to as “mesa optimization”. Additionally, the researchers discovered that the resulting mesa optimization algorithms exhibit few-shot learning capabilities in context, independent of model size. Therefore, the new results supplement the principles of few-shot learning previously observed in large language models.
The researchers believe that the success of transformers is based on their architectural bias that implements mesa optimization algorithms in the forward pass: (i) defining internal learning objectives, and (ii) optimizing them.
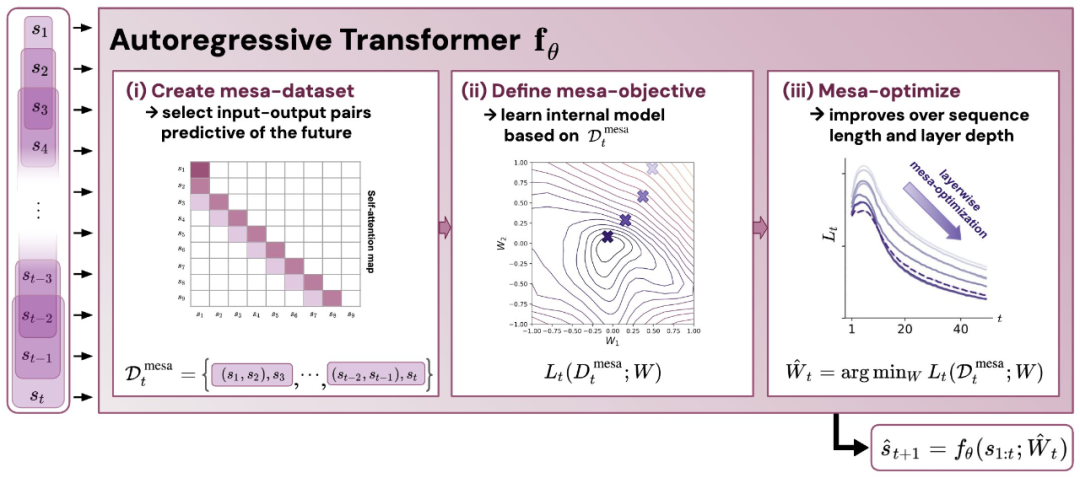
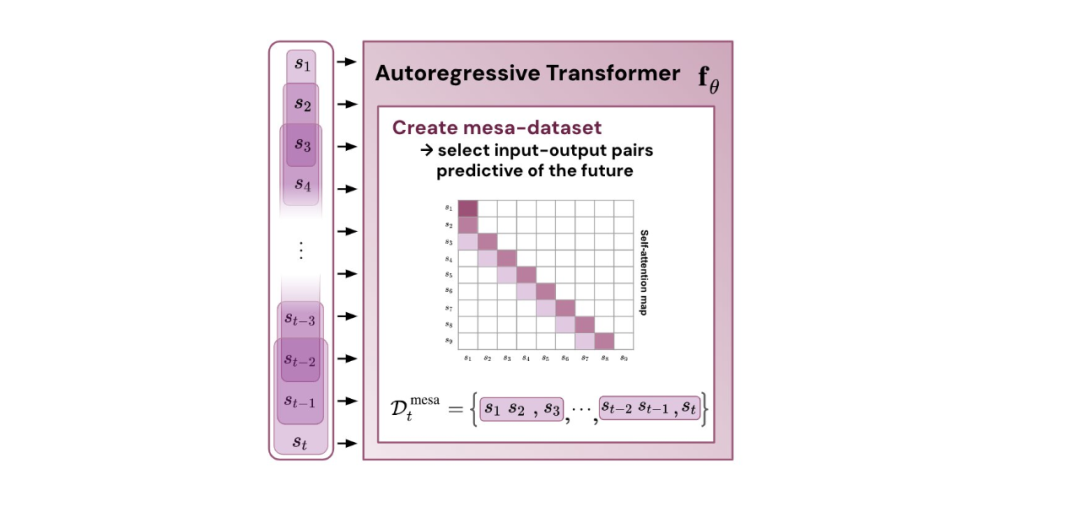
Figure 1: Explanation of the new hypothesis: Optimizing the weights θ of the autoregressive transformer fθ generates the mesa optimization algorithm implemented in the model’s forward propagation. As the input sequence s_1, . . ., s_t is processed at time step t, the transformer (i) creates an internal training set consisting of input-target pairs, (ii) defines the internal objective function using the result dataset to measure the performance of the internal model using weights W, (iii) optimizes this objective and uses the learned model to generate future predictions.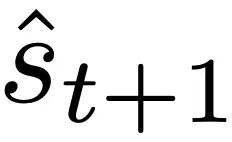 .
The contributions of this study include:
.
The contributions of this study include:
-
Summarizing the theory of von Oswald et al. and demonstrating theoretically how transformers optimize the internally constructed objectives to autoregressively predict the next element in the sequence using gradient-based methods.
-
Experimentally reverse-engineering transformers trained on simple sequence modeling tasks and finding strong evidence that their forward pass implements a two-step algorithm: (i) early self-attention layers build internal training datasets implicitly by grouping and copying tokens, thus defining internal objective functions, (ii) deeper layers optimize these objectives to generate predictions.
-
Similar to LLMs, experiments show that simple autoregressive training models can also become context learners, and that on-the-fly adjustments are crucial for improving LLM context learning, which can also enhance performance in specific environments.
-
Inspired by the discovery that attention layers attempt to implicitly optimize internal objective functions, the authors introduce mesa layers, a new type of attention layer that can effectively address least-squares optimization problems instead of merely taking a single gradient step for optimality. Experiments demonstrate that a single mesa layer outperforms deep linear and softmax self-attention transformers on simple sequential tasks while providing greater interpretability.

-
After preliminary language modeling experiments, promising results were found when replacing standard self-attention layers with mesa layers, proving that this layer possesses strong context learning capabilities.
Based on recent work indicating that transformers explicitly trained to solve few-shot tasks in context can achieve gradient descent (GD) algorithms. Here, the authors show that these results can be generalized to autoregressive sequence modeling—which is a typical method for training LLMs.
First, they analyze transformers trained on simple linear dynamics, where each sequence is generated by different W* to prevent cross-sequence memory. In this simple setting, the authors demonstrate that transformers create mesa datasets and then optimize mesa objectives using pre-processed GD.
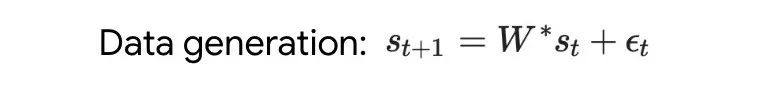
This study trains deep transformers on the token structure that aggregates adjacent sequence elements. Interestingly, this simple preprocessing results in an extremely sparse weight matrix (with less than 1% of weights being non-zero), leading to reverse-engineered algorithms.
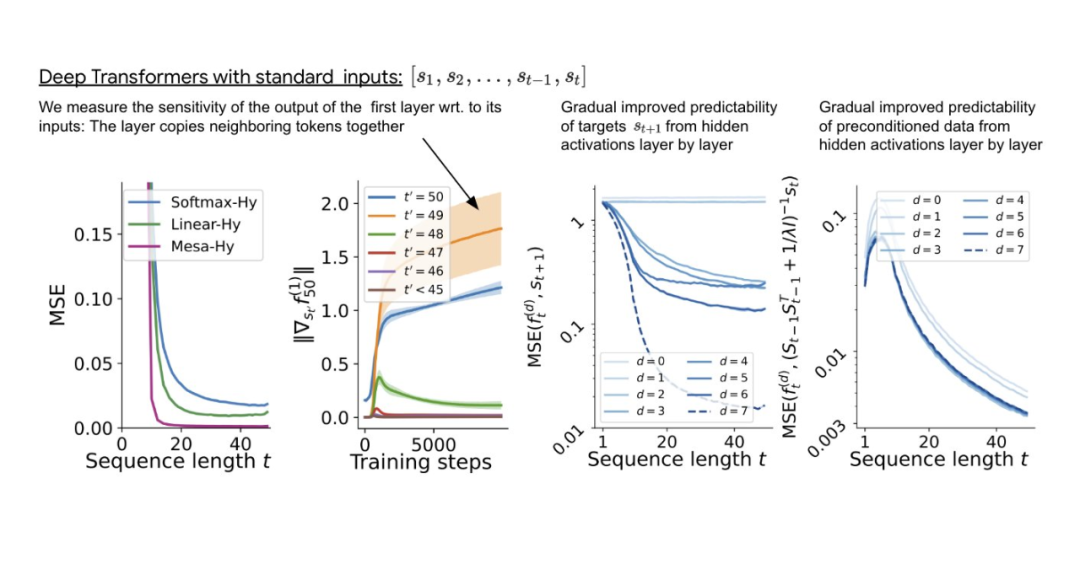
For single-layer linear self-attention, weights correspond to a GD step. For deep transformers, interpretability becomes challenging. This study relies on linear probes to examine whether hidden activations can predict autoregressive objectives or pre-processed inputs.
Interestingly, the predictability of both probing methods gradually increases with network depth. This finding suggests that hidden pre-processing GD exists in the model.
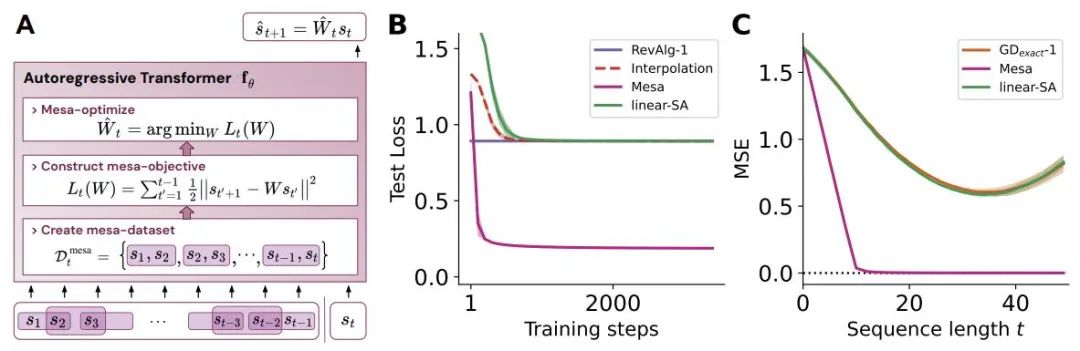
Figure 2: Reverse engineering the trained linear self-attention layer.
This study finds that when using all degrees of freedom in construction, it can perfectly fit the training layer, including not only the learned learning rate η but also a set of learned initial weights W_0. Importantly, as shown in Figure 2, the performance of the learned one-step algorithm still far exceeds that of a single mesa layer.
We can note that under simple weight settings, it is easy to discover through underlying optimization that this layer can optimally solve the tasks studied here. This result demonstrates that hard-coded inductive biases favor the advantages of mesa optimization.
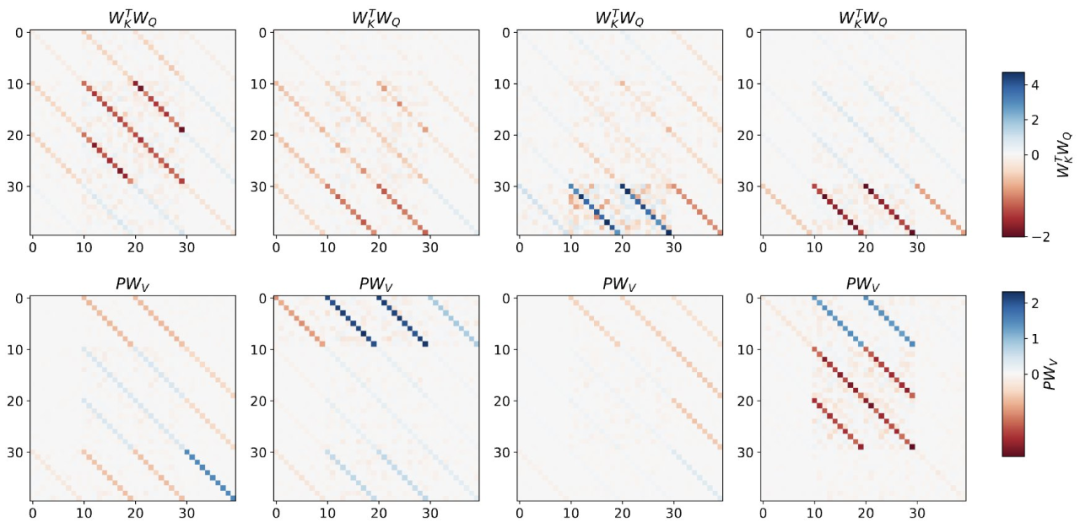
With theoretical insights into multi-layer cases, the authors first analyze deep linear and softmax-only attention transformers. They set the input format based on a 4-channel structure,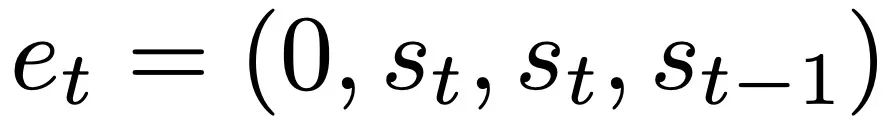 , corresponding to selecting W_0 = 0.
Similar to single-layer models, the authors observed clear structures in the weights of the trained model. As the first reverse engineering analysis, this study utilizes this structure to construct an algorithm (RevAlg-d, where d represents the number of layers) that contains 16 parameters per layer head (instead of 3200). The authors find that this compressed yet complex expression can describe the trained model. In particular, it allows for interpolation between the actual transformer and RevAlg-d weights with almost no loss.
While the RevAlg-d expression explains the trained multi-layer transformer with a few degrees of freedom, it is difficult to interpret it as a mesa optimization algorithm. Therefore, the authors adopt linear regression probing analysis (Alain & Bengio, 2017; Akyürek et al., 2023) to search for the characteristics of the hypothesized mesa optimization algorithms.
In the deep linear self-attention transformer shown in Figure 3, we can see that both probes can linearly decode, and decoding performance increases with the length of the sequence and the depth of the network. Therefore, the underlying optimization discovers a hybrid algorithm that descends layer by layer based on the original mesa-objective Lt (W), while improving the condition number of the mesa optimization problem. This leads to a rapid decrease in mesa-objective Lt (W). Additionally, performance can be seen to significantly improve with depth.
Thus, it can be argued that the rapid descent of the autoregressive mesa-objective Lt (W) is achieved through stepwise (cross-layer) mesa optimization on better pre-processed data.
, corresponding to selecting W_0 = 0.
Similar to single-layer models, the authors observed clear structures in the weights of the trained model. As the first reverse engineering analysis, this study utilizes this structure to construct an algorithm (RevAlg-d, where d represents the number of layers) that contains 16 parameters per layer head (instead of 3200). The authors find that this compressed yet complex expression can describe the trained model. In particular, it allows for interpolation between the actual transformer and RevAlg-d weights with almost no loss.
While the RevAlg-d expression explains the trained multi-layer transformer with a few degrees of freedom, it is difficult to interpret it as a mesa optimization algorithm. Therefore, the authors adopt linear regression probing analysis (Alain & Bengio, 2017; Akyürek et al., 2023) to search for the characteristics of the hypothesized mesa optimization algorithms.
In the deep linear self-attention transformer shown in Figure 3, we can see that both probes can linearly decode, and decoding performance increases with the length of the sequence and the depth of the network. Therefore, the underlying optimization discovers a hybrid algorithm that descends layer by layer based on the original mesa-objective Lt (W), while improving the condition number of the mesa optimization problem. This leads to a rapid decrease in mesa-objective Lt (W). Additionally, performance can be seen to significantly improve with depth.
Thus, it can be argued that the rapid descent of the autoregressive mesa-objective Lt (W) is achieved through stepwise (cross-layer) mesa optimization on better pre-processed data.
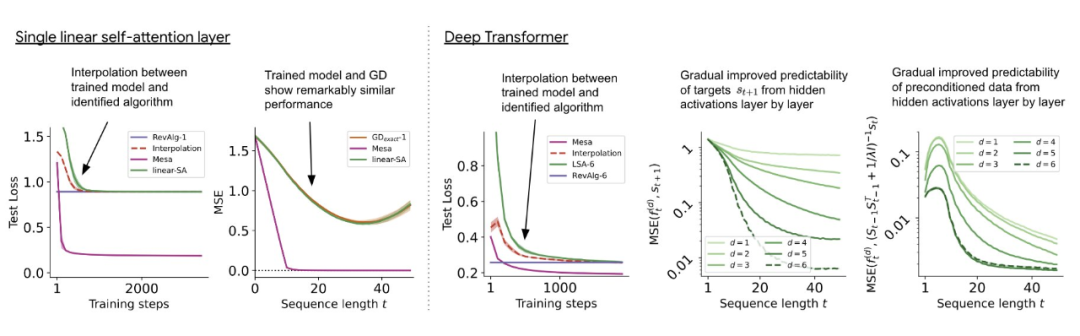
Figure 3: Reverse engineering the built token input of the multi-layer transformer training.
This indicates that if transformers are trained on constructed tokens, they will make predictions through mesa optimization. Interestingly, when directly given sequence elements, transformers construct tokens themselves by grouping elements, which the research team calls “creating mesa datasets.”
This study shows that when trained under standard autoregressive objectives for sequence prediction tasks, transformer models can develop gradient-based inference algorithms. Therefore, the latest results obtained in multi-task and meta-learning settings can also be translated into traditional self-supervised LLM training settings.
Moreover, the study also finds that the learned autoregressive inference algorithms can be repurposed for supervised context learning tasks without retraining, thereby explaining the results within a single unified framework.
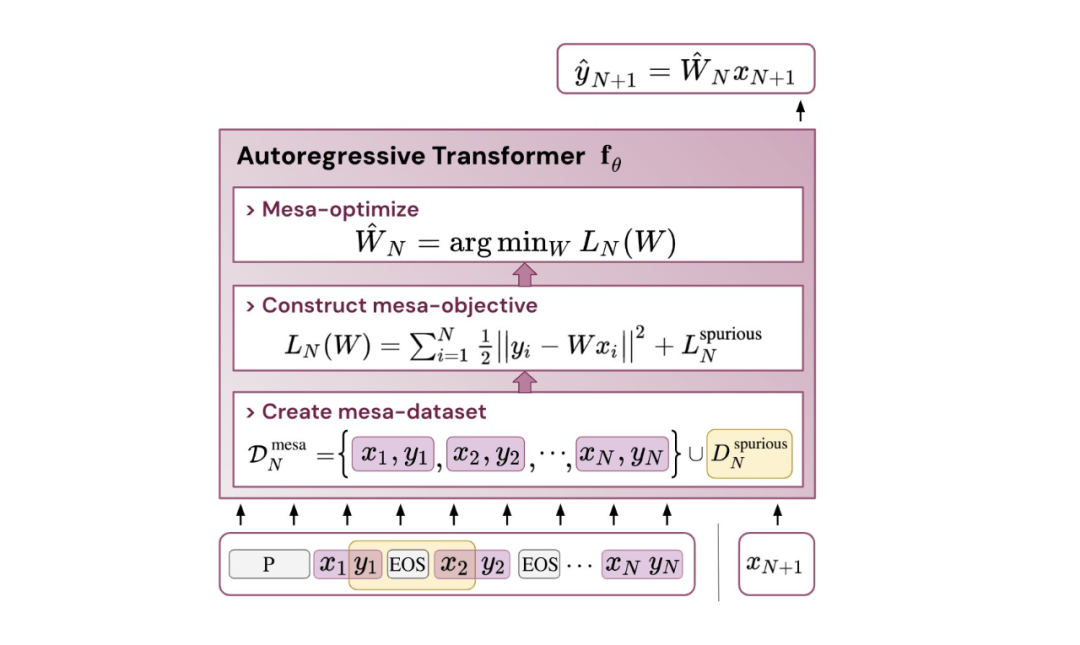
So, what does this have to do with context learning (in-context learning)? The study suggests that after training transformers on autoregressive sequence tasks, they achieve appropriate mesa optimization, allowing for few-shot context learning without any fine-tuning.
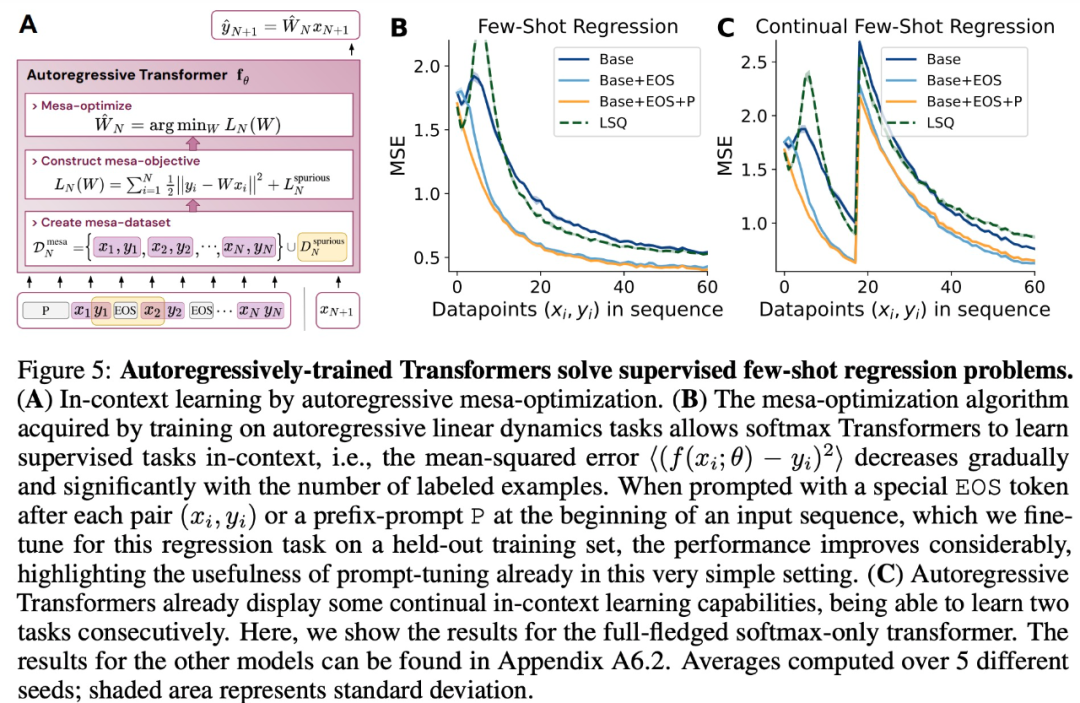
The study hypothesizes that LLMs also exhibit mesa optimization, thereby enhancing their context learning capabilities. Interestingly, the study also observes that effectively adjusting prompts for LLMs can lead to substantial improvements in context learning abilities.
Interested readers can read the original paper for more research content.
https://www.reddit.com/r/MachineLearning/comments/16jc2su/r_uncovering_mesaoptimization_algorithms_in/
https://twitter.com/oswaldjoh/status/1701873029100241241
© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]

