

Source: DeepHub IMBA
This article is about 3000 words long and is recommended to read in 6 minutes.
With the latest advancements in NLP (Natural Language Processing), OpenAI's GPT-3 has become one of the most powerful language models on the market.
On January 25, 2022, OpenAI announced an embedding endpoint (Neelakantan et al., 2022). This neural network model converts text and code into vector representations, embedding them into high-dimensional space. These models can capture the semantic similarity of text and appear to achieve state-of-the-art performance in certain use cases.

Due to the popularity of ChatGPT, GPT-3 has re-entered public attention. This article will compare the performance of embeddings generated using text-embedding-ada-002 (one of the GPT-3 embeddings, chosen for its reasonable price and ease of use) with three traditional text embedding techniques: GloVe (Pennington, Socher & Manning, 2014), Word2Vec (Mikolov, 2013), and MPNet (Song, 2020). These embeddings will be used to train multiple machine learning models, using food review ratings from the Amazon food review dataset for classification. The performance of each embedding technique will be evaluated by comparing their accuracy metrics.
Data Preparation
The dataset used in this article is a subset of 1000 datasets from the Amazon food review dataset. This subset contains embeddings already generated using the “text-embedding-ada-002” model from GPT-3. The embeddings are generated from a combination of the title (summary) and text. As shown in Figure 1, each review also has ProductId, UserId, Score, and the number of tokens generated from the combined text.
# Libraries
from sentence_transformers import SentenceTransformer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import RobustScaler
from sklearn.pipeline import Pipeline
import gensim.downloader as api
from sklearn.svm import SVC
import pandas as pd
import numpy as np
import openai
import re
# import data
df1 = pd.read_csv('https://raw.githubusercontent.com/openai/openai-cookbook/main/examples/data/fine_food_reviews_with_embeddings_1k.csv', index_col=0)
# view first three rows
df1.head(3)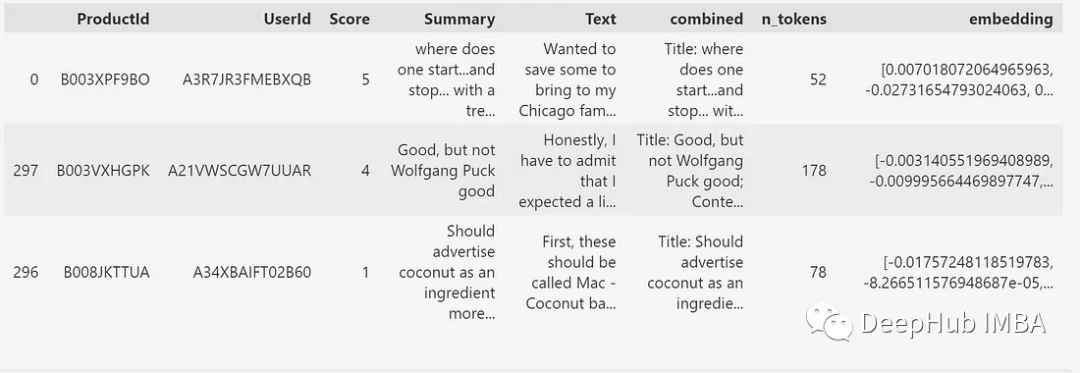
Line breaks and spaces may affect how we represent the embeddings as arrays. Therefore, we need a function to remove unnecessary characters and convert the embeddings into the appropriate array format. The name of the GPT-3 embedding variable will also be changed to ‘gpt_3’ to distinguish it from other embeddings generated later in this article.
# clean openai embeddings
def clean_emb(text):
# remove line break
text = re.sub(r'\n', '', text)
# remove square brackets
text = re.sub(r'\[|\]', "", text)
# remove leading and trailing white spaces
text = text.strip()
# convert string into array
text = np.fromstring(text, dtype=float, sep=',')
return text
# Rename column to gpt_3
df1.rename(columns={'embedding': 'gpt_3'}, inplace=True)
# Apply clean_emb function
df1['gpt_3'] = df1['gpt_3'].apply(lambda x: clean_emb(x))GPT-3 Embeddings
The dataset contains pre-generated embeddings based on GPT-3. However, to generate the latest embeddings, we also need an API key to access the model. This key can be obtained by registering for the OpenAI API. Then, we create a function to specify the model to use (in this case, text-embedding-ada-002).
api_key = 'api key'
# set api key as default api key for openai
openai.api_key = api_key
def get_embedding(text, model="text-embedding-ada-002"):
# replace new lines with spaces
text = text.replace("\n", " ")
# openai.Embedding.create to convert text into embedding array
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']Since this process involves retrieving the API’s return results, it is very straightforward.
GloVe Embeddings
GloVe (Global Vectors for Word Representation) is a text embedding technique that constructs vector representations of words based on their co-occurrence statistics in large text corpora. The idea behind GloVe is that words that appear in comparable contexts are semantically related and can be inferred to have connections by statistically analyzing their co-occurrence matrix.
Using the spaCy library, it is easy to generate GloVe-based embeddings. Here, we use the “en_core_web_lg” English pipeline. This pipeline performs a series of steps on the given text input, such as tokenization, tagging, and lemmatization, to convert it into an appropriate format. The pipeline contains 514,000 vectors, which is large enough for the current use case.
GloVe was released in 2014, and although it has been nearly 10 years since then, it can be said that GloVe was the most successful word embedding method before the advent of transformers, so we will still use it for the following comparisons.
import spacy
# load pipeline
nlp = spacy.load("en_core_web_lg")We also need to perform text cleaning here. As shown in Figure 2, some periods appear consecutively in the first text input. This pattern needs to be corrected.
df1.combined[0]
We create a function to replace consecutive periods with a single period and remove whitespace at the end of sentences.
def replace_multiple_fullstops(text):
# replace 2 or more consecutive fullstops with 1
text = re.sub(r'\.{2,}', '.', text)
# strip white spaces from ends of sentence
text= text.strip()
return text
# Apply function
df1['clean_text'] = df1['combined'].apply(lambda x: replace_multiple_fullstops(x))Then we can generate the embeddings after the cleaning process.
df1['glove'] = df1['clean_text'].apply(lambda text: nlp(text).vector)Word2Vec Embeddings
The Word2Vec technique is based on a neural network model trained on a large amount of text, predicting the target word from its surrounding context words. Word2Vec works by representing each word in the vocabulary as a continuous vector that captures the meaning and context of the word’s usage. These vectors are generated through an unsupervised learning process where the neural network model attempts to predict the surrounding words given a target word.
The Gensim library can be used to load models trained on Word2Vec techniques. The “word2vec-google-news-300” model in the Gensim library is trained on the Google News dataset, which contains about 100 billion words and can represent most words in the dataset.
import gensim.downloader as api
# Load word2vec-google-news-300 model
wv = api.load("word2vec-google-news-300")Since the Gensim library provides a model rather than a pipeline, it is necessary to use the spaCy library to tokenize, clean, and lemmatize the text input before generating vector representations with the Word2Vec model.
def wv_preprocess_and_vectorize(text):
# Process the input text using a natural language processing library
doc = nlp(text)
# Initialize a list to store the filtered tokens
filtered_tokens = []
# Loop through each token in the doc
for token in doc:
# If the token is a stop word or punctuation, skip it
if token.is_stop or token.is_punct:
continue
# Otherwise, add the lemma of the token to the filtered_tokens list
filtered_tokens.append(token.lemma_)
# If there are no filtered tokens, return np.nan
if not filtered_tokens:
return np.nan
else:
# Otherwise, return the mean vector representation of the filtered tokens
return wv.get_mean_vector(filtered_tokens)
# Apply function
df1['word2vec'] = df1['clean_text'].apply(lambda text: wv_preprocess_and_vectorize(text))MPNet Embeddings (BERT)
MPNet (Masked and Permuted Language Model Pre-training) is a transformer-based language model pre-training technique for NLP. MPNet provides a variant of the BERT model. During pre-training, BERT masks a portion of the input tokens and trains the model to predict the masked tokens based on the context of the unmasked tokens. This process is known as masked language modeling, which is effective for capturing the meanings and contexts of words in a text corpus.
In addition to masked language modeling, MPNet employs a permutation mechanism that randomly permutes the order of input tokens. This permutation helps the model learn the global context and relationships between words in the input sequence.
We use the Hugging Face Sentence Transformer model “all-mpnet-base-v2” to obtain MPNet-based embeddings. This model is built on the foundation of the MPNet base model and fine-tuned on a dataset of 1 billion sentence pairs.
model_sent = SentenceTransformer('all-mpnet-base-v2')
df1['mpnet'] = df1['clean_text'].apply(lambda text: model_sent.encode(text))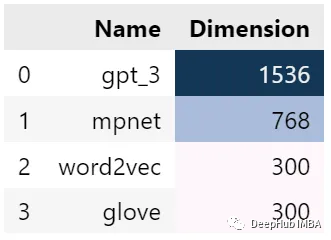
Dimension Comparison
Figure 3 below shows the different dimensions of each embedding. GPT-3 has a maximum dimension of 1536. Next are MPNet, Word2Vec, and GloVe, with dimensions of 768, 300, and 300 respectively.
# assign data of lists.
data = {'Name': ['gpt_3', 'mpnet', 'word2vec', 'glove'], 'Dimension': [len(df1.gpt_3[0]), len(df1.mpnet[0]), len(df1.word2vec[0]), len(df1.glove[0])]}
# Create DataFrame
df_emb_len = pd.DataFrame(data)
# Set background style
df_emb_len.style.background_gradient()Models Used for Evaluation
To evaluate the performance of text embeddings, we used four classifiers: Random Forest, Support Vector Machine, Logistic Regression, and Decision Tree to predict the Score variable. The dataset will be split into a 75:25 training and testing set to assess accuracy. Since the embeddings are two-dimensional, they will be converted into a single three-dimensional array using numpy functions before training.
# Define a list of embedding methods to evaluate
embedding_var= ['gpt_3', 'mpnet', 'word2vec', 'glove']
# Define a list of classifier models to use
classifiers = [('rf', RandomForestClassifier(random_state=76)), ('svm', SVC(random_state=76)), ('lr', LogisticRegression(random_state=76, max_iter=400)), ('dt', DecisionTreeClassifier(random_state=76))]
# Define a dictionary to store accuracy results for each classifier
accuracy_lists = { 'rf': [], 'svm': [], 'lr': [], 'dt': [] }
# Loop through each embedding method
for emb in embedding_var:
# Split the data into training and testing sets using the 'train_test_split' function
X_train, X_test, y_train, y_test = train_test_split( df1[emb].values, df1.Score, test_size=0.25, random_state=76 )
# Stack the training and testing sets into 3D arrays
X_train_stacked = np.stack(X_train)
X_test_stacked = np.stack(X_test)
# Loop through each classifier model
for classifier_name, classifier in classifiers:
# Create a pipeline that scales the data and fits the classifier
pipe = Pipeline([('scaler', RobustScaler()), (classifier_name, classifier)])
pipe.fit(X_train_stacked, y_train)
# Use the pipeline to make predictions on the test data
y_pred = pipe.predict(X_test_stacked)
# Evaluate the accuracy of the predictions
report = classification_report(y_test, y_pred ,output_dict=True)
acc = report['accuracy']
# Store the accuracy results for each classifier
accuracy_lists[classifier_name].append(acc)Results
Figure 4 shows some interesting results from the models. The GPT-3 embeddings achieved the highest accuracy across all models.
The MPNet embeddings performed second when using Logistic Regression and Support Vector Machine, but were surpassed by Word2Vec embeddings in the Random Forest algorithm and performed the worst in the Decision Tree algorithm. No definitive conclusions can yet be drawn about the impact of dimensionality on model performance, but it is evident from the results that GPT-3 embeddings consistently outperformed all other embeddings, demonstrating its advantage in text classification.
# Add a new key 'embeddings' to the dictionary 'accuracy_lists' and assign the list 'embedding_var' to it
accuracy_lists['embeddings'] = embedding_var
# Create a list of tuples using the values from the dictionaries
df_zip = list(zip(accuracy_lists['embeddings'], accuracy_lists['lr'], accuracy_lists['svm'], accuracy_lists['rf'], accuracy_lists['dt']))
# Create a DataFrame 'df_accuracy' from the list 'df_zip' and specify the column names
df_accuracy = pd.DataFrame(df_zip, columns = ['Embedding','Logistic_Regression','Support_Vector_Machine', 'Random_Forest','Decision_Tree'])
# Add a background gradient to the DataFrame for visual representation
df_accuracy.style.background_gradient()
So the saying goes, “Don’t ask, just GPT-3” 😏
If you want to test it yourself, the code from this article is here:
https://github.com/Derrick015/Python/blob/main/Natural_Language_Processing_(NLP)/GPT3_vs_other_embeddings_text_classification.ipynb
Editor: Yu Tengkai
Proofreader: Lin Yilin
