
Christopher Manning

In the past decade, remarkable achievements and breakthroughs in natural language processing have been made through the use of simple artificial neural networks, leveraging powerful computational resources represented by GPUs and TPUs, and training on massive datasets. The resulting pre-trained language models, such as BERT and GPT-3, provide a powerful universal base for language understanding and generation, which can be easily transferred to many semantic understanding, intelligent writing, and reasoning tasks. These models show a prototype of a more general form of artificial intelligence, which may lead to the development of powerful foundation models in areas beyond language and into sensory experiences.
Main Text
When scientists consider artificial intelligence, they often think of modeling or recreating the capabilities of individual human brains. However, modern human intelligence far exceeds that of individual brains. Human language is powerful and transformative for our species; it is not only the most distinguishing feature that sets humans apart from other animals but also provides a way for individuals to “network” their many brains. Individual humans may not be much more intelligent than our close relatives, chimpanzees or bonobos. These primates have been shown to possess many hallmark skills of human intelligence, such as using tools, planning, and acquiring power within groups. Additionally, their short-term memory is often better than ours.
To this day, the timing of when humans invented language remains uncertain, and perhaps it always will be. However, in the long evolutionary history of life on Earth, humans have developed language in an astonishingly short time. The common ancestors of primitive animals, monkeys, and apes can be traced back 65 million years; humans separated from chimpanzees around 6 million years ago, while human language is generally believed to have existed for only a few hundred thousand years. Although we may not be as strong as elephants or as fast as cheetahs, once humans developed language, the power of communication and interaction quickly led Homo sapiens to surpass other species. It was only in the last few hundred thousand years that humans developed writing (just over five thousand years ago) and gradually acquired the ability to construct complex sentences, allowing knowledge to flow across different times and spaces. In just a few thousand years, this mechanism of information sharing has brought us from the distant Bronze Age to the present age of smartphones. A high-fidelity code allows rational discussions among humans and facilitates the dissemination of information, making the cultural evolution of complex societies and the accumulation of modern technological knowledge possible. The power of language is fundamental to human societal intelligence, and in a future world where human capabilities are gradually enhanced by artificial intelligence tools, language will continue to play an important role.
For the reasons mentioned above, the field of natural language processing (NLP) has been one of the earliest hot research directions in artificial intelligence. In fact, the initial work on NLP issues such as machine translation, including the famous Georgetown-IBM demonstration in 1954, even predates the birth of the term “artificial intelligence” in 1956. I will then describe the dramatic developments in NLP that have emerged from the use of large artificial neural network models trained on vast amounts of data. I will trace the significant progress made in building effective NLP systems using these technologies and share some of my thoughts on the achievements of these models and the next steps in the field.
So far, the history of natural language processing can be roughly divided into four stages.
The first stage lasted from 1950 to 1969. NLP research began with the study of machine translation. People envisioned that translation could quickly build on the success of computers in breaking codes during World War II. During the Cold War, researchers from both the US and the Soviet Union attempted to develop systems capable of translating scientific achievements from other countries. However, at the beginning of this era, people knew almost nothing about the structure of human language, artificial intelligence, or machine learning. Looking back now, the computational power and data scale available at that time were pitifully small. Although the initial systems were promoted with great fanfare, they only provided word-level translation lookups and some simple, not very principled, rule-based mechanisms to handle inflections (morphology) and word order.
The second stage, from 1970 to 1992, saw the development of a series of NLP demonstration systems that exhibited complexity and depth in dealing with phenomena such as syntax and reference in human language. These systems included SHRDLU by Terry Winograd, LUNAR by Bill Woods, SAM by Roger Schank, LIFER by Gary Hendrix, and GUS by Danny Bobrow.
During this time, the rapid development of linguistics and knowledge-based artificial intelligence led to the emergence of a new generation of hand-built systems, which clearly separated declarative language knowledge from procedural processing and benefited from a series of more modern linguistic theories.
However, the direction of NLP work underwent a significant change during the third stage, roughly from 1993 to 2012. During this period, digital text data became abundant, and the focus shifted to developing algorithms capable of achieving some level of language understanding on large amounts of natural text and leveraging the existence of this text to help provide that capability. This led to a fundamental repositioning of the field around empirical machine learning models for NLP, transitioning from rules to statistics, a direction that still dominates the field today. At the beginning of this period, the mainstream approach was to master a considerable amount of online text—text datasets at that time were generally under several tens of millions of words—and extract some model from this data, primarily by calculating specific facts. For example, one might learn that the types of things captured by people are fairly balanced between human locations (such as cities, towns, or fortresses) and metaphorical concepts (such as imagination, attention, or essence). However, in terms of providing language understanding capabilities, counting vocabulary could only go so far, and early empirical attempts to learn language structures from text collections were quite unsuccessful. This led most people in the field to focus on building manually labeled language resources, such as labeling specific meanings of words in a particular context, instances of names of people or companies in texts, or the grammatical structures of sentences in treebanks, and then using supervised machine learning techniques to build models that would produce similar labels for new text fragments during runtime.
The period from 2013 to the present has continued the empirical orientation of the third stage but has undergone significant changes due to the introduction of deep learning or artificial neural network methods. In this approach, the semantics of vocabulary and sentences are represented by their positions in a real-valued vector space (hundreds or thousands of dimensions), while the similarity of meanings or syntax is represented by the proximity (distance) in this space. From 2013 to 2018, deep learning provided stronger baseline solutions for building high-performance models: it became easier to model long-distance contexts, and the models generalized better for vocabulary or phrases with similar meanings because they could leverage proximity in the vector space rather than relying on symbolic-level similarity (for example, two words being close in form but unrelated or even opposite in meaning). Nevertheless, the approach remained unchanged in building supervised machine learning models to perform specific analytical tasks.
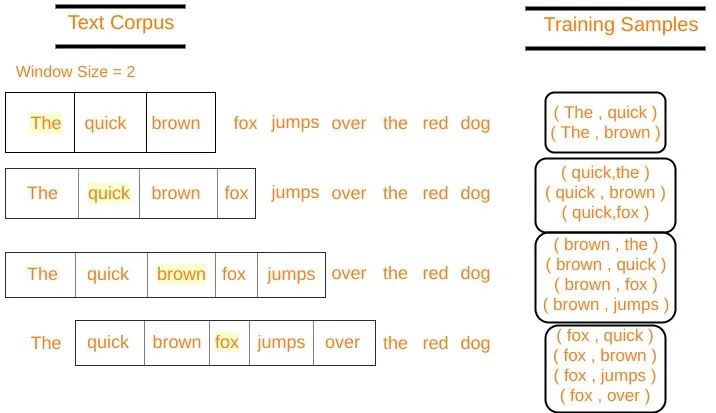
Example of word2vec model training principles
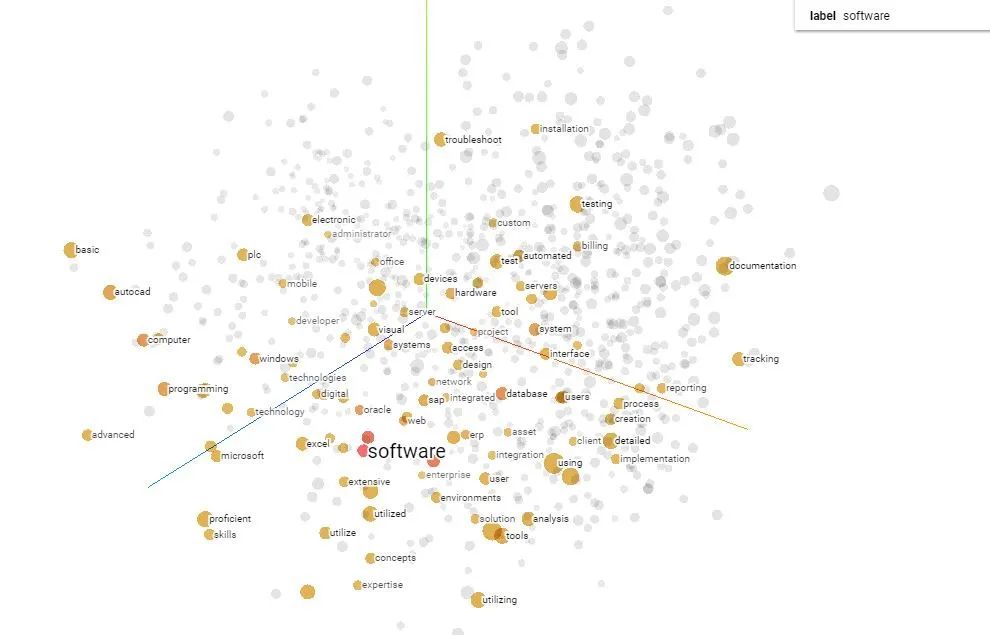
The vocabulary representations obtained after training with word2vec can perform mathematical operations such as addition, subtraction, and multiplication in semantic space.
However, everything changed after October 2018—when NLP experienced its first major success in large-scale self-supervised neural network learning. In this approach, models only need to receive a massive amount (starting from 20GB) of text to learn a great deal about language and much of the knowledge of the real world. This was made possible by the powerful self-supervised learning methods of transformer-based models: the models automatically create self-challenging prediction tasks from the text—similar to “fill in the blanks,” for example, identifying each next word in the text given the preceding vocabulary or filling in a masked word or phrase in the text. By repeating such prediction tasks dozens of times and learning from mistakes, the models improve their performance the next time they are given a similar text context, thereby accumulating general knowledge about language and the real world, which can then be applied to downstream semantic understanding tasks such as text classification, text retrieval, sentiment analysis, or reading comprehension.
In retrospect, the development of large-scale self-supervised learning approaches is likely to be seen as a fundamental change, marking the abrupt end of the third stage in 2017. The impact of self-supervised pre-training methods has been revolutionary: it is now possible to train models on vast amounts of unlabeled human language material to produce a large pre-trained model, which can achieve good results in various natural language understanding and generation tasks through fine-tuning or prompting. As a result, progress and interest in NLP have exploded. An optimistic view is that systems imbued with a certain degree of general intelligence and vast knowledge are gradually emerging.
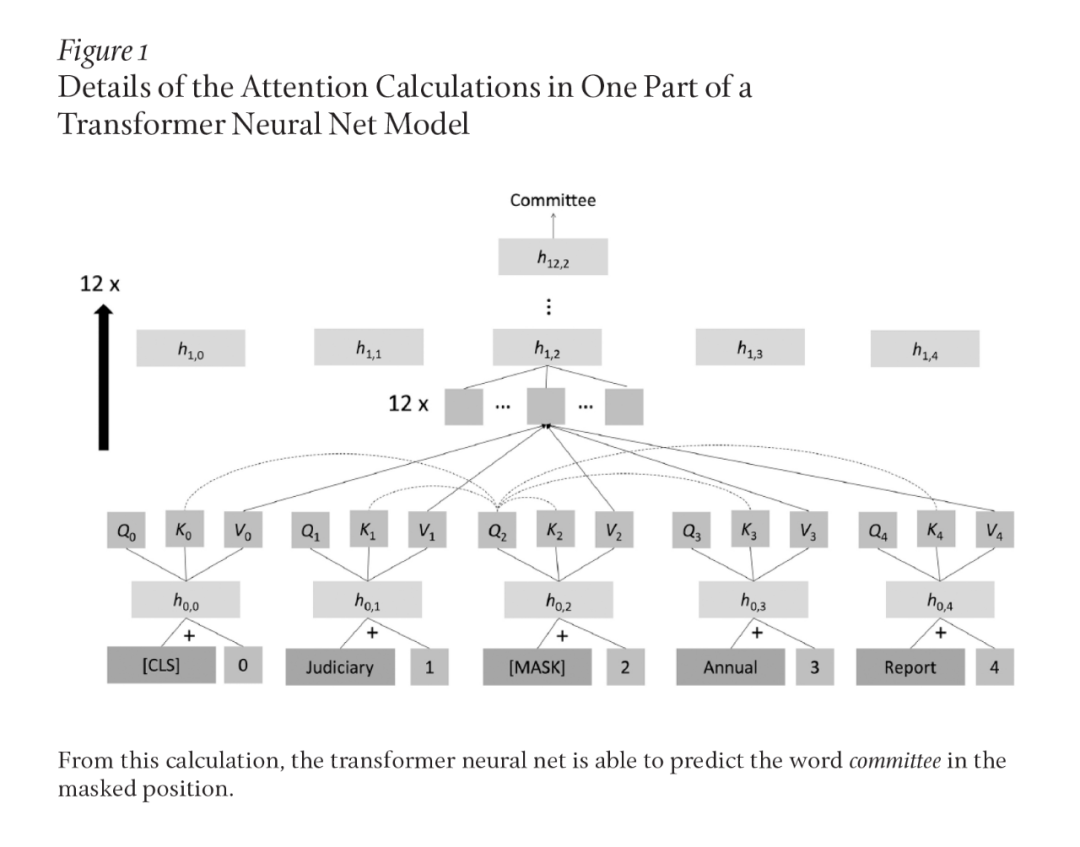
I cannot provide a comprehensive description of the currently dominant deep learning pre-trained models here, as there have been too many such models and their variants born between 2018 and 2022, but I can offer a clue. These models represent everything through real-valued vectors and are capable of learning better semantic representations by backpropagating errors (which boils down to performing differential calculations) from some prediction tasks back to the representations of words in the text after being exposed to a lot of text data. Since 2018, the mainstream models in NLP applications have been transformer-based neural networks. The transformer is a model that is much more complex than the simple sequential neural networks explored several decades ago. Its dominant idea is attention, through which the representation of one position is calculated as a weighted combination of the representations of other positions. A common self-supervised objective in transformer models is to mask occasional words in the text. The model calculates the words that have previously appeared. It achieves this by computing the query, key, and value vectors representing that position from each word’s position (including the masked position). It compares the query of one position with the values of each position to calculate the attention level for each position; based on this, it computes the weighted average of the values of all positions. This operation is repeated many times in each layer of the transformer neural network, and the resulting values are further processed through fully connected neural network layers using normalization layers and residual connections to produce a new vector for each word. This process is repeated multiple times, giving the transformer neural network additional depth. Finally, the representation above the masked position should capture the vocabulary present in the original text. For example, as shown in Figure 1, “committee”:
It is difficult to intuitively understand what can be achieved or learned through numerous simple computations in the transformer deep neural network. Initially, this may sound like some complex statistical association learner. However, considering a very powerful, flexible, and highly parameterized model like the transformer and the vast amounts of text data for learning and prediction, these models discover and represent much of the structure of human language. In fact, many studies have shown that these models learn and represent the syntactic structures of sentences and memorize many facts about the real world, as these contribute to the models’ success in predicting masked words. Moreover, while predicting a masked word may initially seem like a rather simple and low-level task—an unhumorous “crazy freedom”—and not a complex task like illustrating the grammatical structure of a sentence, this task has proven to be very powerful because it is universal: every form of language and world knowledge, from sentence structure, word connotations, and facts about the real world, helps people to better accomplish this task. Therefore, these models aggregate a vast amount of general knowledge about the language and the real world that they encounter. Such a large pre-trained language model (LPLM) can be applied to many specific NLP tasks, requiring only a small amount of training data for further “guidance.” From 2018 to 2020, the standard way of doing this was to fine-tune the model with a small amount of additional supervised learning for specific tasks of interest (such as sentiment analysis, reading comprehension, and entity extraction). However, recently, researchers unexpectedly found that the largest models among these, such as GPT-3 (Generative Pre-trained Transformer-3), can perform well on new tasks with just a prompt. By giving them a description in human language or a few examples of what they are expected to do, they can accomplish many tasks they have never been trained on.
Traditional natural language processing models are carefully “assembled” from several components that are usually developed independently, often constructed into a pipeline that first captures the sentence structure and low-level entities of the text, then understands some high-level semantic information, and inputs it into specific domain execution components. In recent years, companies have begun to replace these traditional NLP solutions with LPLMs, often fine-tuning them to perform specific tasks. What can we expect these systems to accomplish in the 2020s?
Early machine translation systems covered limited domains with limited language structures. Building large statistical models based on parallel translation corpora enabled machine translation with strong generalization capabilities, which was something most people first experienced when Google Translate was launched in 2006. A decade later, at the end of 2016, when Google switched to using neural machine translation, Google’s machine translation improved significantly. But the lifespan of that system was short: transformer-based neural network translation was launched in 2020. This new system not only optimized through different neural architectures but also used models that were fundamentally different from previous network structures. The new system did not establish bilingual matches from parallel texts to translate between two languages; instead, it benefited from a massive neural network trained simultaneously on all languages covered by Google Translate, using a simple marker (target_language, source_language) to represent the languages. Although this system still makes mistakes, research on machine translation continues, and today the quality of automatic translation is outstanding. When I input a few sentences from today’s cultural edition of the World Report:
Il avait été surnommé, au milieu des années 1930, le « Fou chantant », alors qu’il faisait ses débuts d’artiste soliste après avoir créé, en 1933, un duo à succès avec le pianiste Johnny Hess. Pour son dynamisme sur scène, silhouette agile, ses yeux écarquillés et rieurs, ses cheveux en bataille, surtout pour le rythme qu’il donnait aux mots dans ses interprétations et l’écriture de ses textes.(20世纪30年代中期,他在1933年与钢琴家约翰尼-赫斯成功创作了一首二重奏后,首次以独唱艺术家的身份亮相,被人称为 “唱歌的傻瓜”。他以充满活力的舞台形象、敏捷的身手、宽大的笑眼、狂野的头发而闻名,最重要的是他在演绎和撰写歌词时赋予文字以节奏。)
The quality of the translation produced by the machine is high:
He was nicknamed the Singing Madman in the mid-1930s when he was making his debut as a solo artist after creating a successful duet with pianist Johnny Hess in 1933. For his dynamism on stage, his agile figure, his wide, laughing eyes, his messy hair, especially for the rhythm he gave to the words in his interpretations and the writing of his texts.
In intelligent question answering, a system searches for relevant information in a series of texts and then provides answers to specific questions (as a snippet, rather than just returning pages believed to contain relevant information, as in earlier web searches). Intelligent question answering has many direct commercial applications, including pre-sales and post-sales customer support. Modern neural network question-answering systems have high accuracy in extracting answers from texts, and they perform quite well even in cases where there is no answer. For example, from this passage:
三星为Galaxy Note 20 Ultra保留了最好的功能,包括比Galaxy S20 Ultra更精致的设计–我不推荐这款手机。你会发现一个特殊的6.9英寸屏幕,锐利的5倍光学变焦相机和一个更迅速的手写笔,用于注释屏幕截图和做笔记。与Note 10 Plus相比,Note 20 Ultra还做了一些小而重要的改进,特别是在相机领域。这些功能是否证明了Note 20 Ultra的价格合理?128GB版本的起价为1300美元。这个零售价是一个很高的要求,特别是当你结合全球经济深度衰退和失业率上升的环境时。
People can get answers to questions like the following, with answers extracted from the above text:
三星Galaxy Note 20 Ultra的价格是多少?
128GB版本为1300美元
Galaxy Note 20 Ultra有20倍光学变焦吗?
没有
Galaxy Note 20 Ultra的光学变焦是多少?
5x
Galaxy Note 20 Ultra的屏幕有多大?
6.9英寸
For common traditional NLP tasks, such as identifying names of people or organizations in a text or performing sentiment classification (positive or negative) on product-related texts, the best systems are still based on LPLMs, generally fine-tuned by providing some training data. While these tasks could be performed well even before the recent large language models, these models contain vast amounts of broader knowledge about language and the real world, further enhancing the performance of these tasks.
Finally, LPLMs also possess the ability to generate fluent, coherent, and semantically consistent text. In addition to many creative uses, such systems have mundane applications, from writing “formulaic” news articles, such as weather forecasts and sports reports, to automatic summarization. For example, such systems can help radiologists output diagnostic summaries based on their findings. For the following research results, we can see that the system-generated summaries are very similar to those written by radiologists themselves:
发现:管线/管子:右髂骨鞘,中心静脉导管尖端在最初的X光片上,气管导管在锁骨头之间,肠管的侧口在ge交界处,尖端在视场外的横膈膜下;这些在随后的胶片上被移除。纵隔引流管和左胸造口管没有变化。肺部:肺容积较小。心后空隙疾病,在最近的片子中略有增加。胸膜:左胸腔少量积液。没有气胸。心脏和纵隔:手术后心脏纵隔轮廓变宽。主动脉弓钙化。骨骼:完整的胸骨正中切口线。
放射科医生生成的印象:左侧基底空隙病变和左侧小量胸腔积液。线条和管道位置如上。
系统自动生成的摘要:线条和管子的位置如上所述。心后空隙疾病,在最近的片子上略有增加。左侧小胸腔积液。
Recently, these NLP systems have performed very well on many tasks. In fact, given a relatively clear NLU task, they can often be “tuned” to perform as well as humans. However, we still have reason to doubt whether these systems truly understand what they are doing, or whether they are merely “carefully designed” rewriting systems rather than genuinely understanding semantics.
In both linguistics and philosophy of language, as well as in programming languages, the mainstream approach to describing meaning is referential semantics or referential theory: the meaning of a word, phrase, or sentence is a set of objects or situations in the world it describes (or its mathematical abstraction). This contrasts with the simple distributional semantics of modern empirical work in NLP, according to which the meaning of a word is merely a description of its context of occurrence. Meaning is not all or nothing; in many cases, we can only partially understand the meaning of linguistic forms. I believe that meaning arises from an understanding of the network of connections between linguistic forms and other things, whether they are objects in the world or other linguistic forms. If we have a dense network of connections, we have a good sense of the meaning of linguistic forms. For example, if I have been exposed to a shehnai from India, I would have a reasonable concept of the meaning of that word; furthermore, if I have also heard pieces played on the shehnai, then “shehnai” would have a richer connotation in my mind. Conversely, if I have never seen, touched, or heard a shehnai, but someone tells me it is like a traditional Indian oboe, then the word would have a somewhat “shallower” meaning for me: it connects with India, with reed woodwind instruments, and with playing music. If someone adds that its holes are somewhat like a flute but it has multiple reeds and an outwardly flared end, more like an oboe, then I would have more knowledge of the properties of the shehnai. In contrast, I might not have that information but only have some sentences containing “shehnai,” such as, “From a week ago, the shehnai players sat in bamboo carts at the door of the house, playing their pipes,” or, “Bikash Babu didn’t like the sound of the shehnai, but he was determined to meet all the traditional expectations that the groom’s family might have.” In some ways, my understanding of the connotation of the word “shehnai” is less than that of those who have merely picked up a shehnai, because I know certain cultural connections associated with the word that they do not, only knowing it is a playable instrument.
Using this definition, understanding meaning includes understanding the network of connections of linguistic forms, and there is no doubt that pre-trained language models like BERT learn meanings. In addition to the meanings of the words themselves, these models also learn a lot about real-world knowledge. If they are trained on texts from Wikipedia (as they usually are), they come to learn that Abraham Lincoln was born in Kentucky in 1809, and that the lead singer of “Destiny’s Child” is Beyoncé Knowles-Carter. Machines can benefit immensely from written texts that serve as repositories of human knowledge. However, the meanings of words and world knowledge learned by the models are often very incomplete and need to be supplemented with other sensory data and knowledge (such as images, sounds, and structured knowledge graphs).
The success of LPLMs in language understanding tasks, along with the exciting prospects of extending large-scale self-supervised learning to other types of data—such as vision, robotics, knowledge graphs, bioinformatics, and multimodal data—indicates that we are exploring a more universal direction. We propose the term foundation models, referring to general models trained in a self-supervised manner on large amounts of data, with millions of parameters that can be easily fine-tuned for many downstream tasks and make reasonable predictions. One direction is to connect language models with more structured knowledge bases, which are represented in the form of knowledge graph neural networks or provided as large amounts of text for “lookup” at runtime. An example in this area is the recent DALL-E model, which can generate vivid, finely detailed images by inputting a piece of text after undergoing self-supervised learning on vast amounts of image-text data.
We are still in the early days of the foundation models era, but let me outline a possible future. Most information processing and analysis tasks, even things like robot control, will be handled by a specialization of one of a relatively small number of foundation models. Training these models will be expensive and time-consuming, but adapting them to different tasks will be quite easy; in fact, one might only need to use natural language instructions to do so. The resulting convergence on a few models brings some risks: groups capable of building these models may hold excessive power and influence, many end-users may be affected by any biases present in these models, and due to the sheer size of the models and their training data, it will be difficult to assess whether a model can be safely used in specific situations. Nevertheless, the ability of these models to deploy the knowledge gained from vast amounts of training data to many different runtime tasks will make them powerful, showcasing the goal of artificial intelligence for the first time: a machine learning model completing many specific tasks based on simple on-site instructions. While we have only a vague understanding of the ultimate possibilities of these models, they may still be limited, lacking the careful logic or causal reasoning abilities of human levels. However, the broad effectiveness of foundation models means they will be deployed very widely, and they will provide the first glimpse of a more general form of artificial intelligence for people in the next decade.
Original Title: Human Language Understanding & Reasoning
Original Author: Christopher D. Manning
Original Address: https://www.amacad.org/sites/default/files/publication/downloads/Daedalus_Sp22_09_Manning.pdf
Endnotes
-
1. Frans de Waal, Are We Smart Enough to Know How Smart Animals Are? (New York: W. W. Norton, 2017). -
2. Mark Pagel, “Q&A: What Is Human Language, When Did It Evolve and Why Should We Care?” BMC Biology 15 (1) (2017): 64. -
3. W. John Hutchins, “The Georgetown-IBM Experiment Demonstrated in January 1954,” in Machine Translation: From Real Users to Research, ed. Robert E. Frederking and Kathryn B. Taylor (New York: Springer, 2004), 102–114. -
4. A survey of these systems and references to individual systems appears in Avron Barr, “Natural Language Understanding,” AI Magazine, Fall 1980. -
5. Larry R. Harris, “Experience with Robot in 12 Commercial, Natural Language Data Base Query Applications” in Proceedings of the 6th International Joint Conference on Artificial Intelligence, IJCAI-79 (Santa Clara, Calif.: International Joint Conferences on Artificial Intelligence Organization, 1979), 365–371. -
6. Glenn Carroll and Eugene Charniak, “Two Experiments on Learning Probabilistic Dependency Grammars from Corpora,” in Working Notes of the Workshop Statistically-Based NLP Techniques, ed. Carl Weir, Stephen Abney, Ralph Grishman, and Ralph Weischedel (Menlo Park, Calif.: AAAI Press, 1992). -
7. Ashish Vaswani, Noam Shazeer, Niki Parmar, et al., “Attention Is All You Need,” Advances in Neural Information Processing Systems 30 (2017). -
8. Christopher D. Manning, Kevin Clark, John Hewitt, et al., “Emergent Linguistic Structure in Artificial Neural Networks Trained by Self-Supervision,” Proceedings of the National Academy of Sciences 117 (48) (2020): 30046–30054. -
9. Tom Brown, Benjamin Mann, Nick Ryder, et al., “Language Models Are Few-Shot Learners,” Advances in Neural Information Processing Systems 33 (2020): 1877–1901. -
10. For example, Météo translated Canadian weather reports between French and English; see Monique Chevalier, Jules Dansereau, and Guy Poulin, TAUM-MÉTÉO: Description du système (Montreal: Traduction Automatique à l’Université de Montréal, 1978). -
11. Gideon Lewis-Kraus, “The Great A.I. Awakening,” The New York Times Magazine, December 18, 2016. -
12. Isaac Caswell and Bowen Liang, “Recent Advances in Google Translate,” Google AI Blog, June 8, 2020 -
13. Sylvain Siclier, “A Paris, le Hall de la chanson fête les inventions de Charles Trenet,” Le Monde, June 16, 2021. -
14. Daniel Khashabi, Sewon Min, Tushar Khot, et al., “UnifiedQA: Crossing Format Boundaries with a Single QA System,” in Findings of the Association for Computational Linguistics: EMNLP 2020 (Stroudsburg, Pa.: Association for Computational Linguistics, 2020), 1896–1907. -
15. Yuhao Zhang, Derek Merck, Emily Bao Tsai, et al., “Optimizing the Factual Correctness of a Summary: A Study of Summarizing Radiology Reports,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (Stroudsburg, Pa.: Association for Computational Linguistics, 2020), 5108–5120. -
16. For an introduction to this contrast, see Gemma Boleda and Aurélie Herbelot, “Formal Distributional Semantics: Introduction to the Special Issue,” Computational Linguistics 42 (4) (2016): 619–635. -
17. Emily M. Bender and Alexander Koller, “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (Stroudsburg, Pa.: Association for Computational Linguistics, 2020), 5185–5198. -
18. From Anuradha Roy, An Atlas of Impossible Longing (New York: Free Press, 2011). -
19. Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, et al., “On the Opportunities and Risks of Foundation Models,” arXiv (2021). -
20. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Stroudsburg, Pa.: Association for Computational Linguistics, 2019), 4171–4186. -
21. Robert Logan, Nelson F. Liu, Matthew E. Peters, et al., “Barack’s Wife Hillary: Using Knowledge Graphs for Fact-Aware Language Modeling,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Stroudsburg, Pa.: Association for Computational Linguistics, 2019), 5962–5971; and Kelvin Guu, Kenton Lee, Zora Tung, et al., “REALM: Retrieval-Augmented Language Model Pre-Training,” Proceedings of Machine Learning Research 119 (2020). -
22. Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, et al., “Zero-Shot Text-To-Image Generation,” arXiv (2021).
Today’s editor: Xiyu Xu
