Click the card below, select to add “star” or “top“
Important content delivered promptlySource | Heart of Autonomous DrivingEditor | Deep Blue AcademyHow to showcase a deep learning model that has been painstakingly trained? How to attract attention with a demo running only on the server? How can we make our achievements practical? This article takes you into the world of model deployment.
0 Introduction
Steps for model deployment:
- Train a deep learning model;
- Use different inference frameworks to convert the model;
- Run the converted model on the application platform.
The steps seem simple, but the knowledge involved is quite extensive. In practical applications, the models we use are usually not simple, as we need to ensure the model’s accuracy. However, practical application scenarios often require a good balance between model speed and accuracy. This requires optimizing the model at both the algorithm level (pruning, compression, etc.) and the underlying level (writing acceleration algorithms). However, we can now stand on the shoulders of giants to look at the world, so this article will introduce some commonly used open-source inference frameworks for everyone to reference and learn. After all, the tools developed by expert teams are generally more useful…
1 Which is Stronger for Model Deployment: ONNX, NCNN, OpenVINO, TensorRT, or Mediapipe?
1.1 ONNX
Introduction:
The Open Neural Network Exchange (ONNX) is an open format for representing deep neural network models, launched by Microsoft and Facebook in 2017, and quickly gained support from major vendors and frameworks. Through just a few years of development, it has become the practical standard for representing deep learning models, and with ONNX-ML, it can support traditional non-neural network machine learning models, aiming to unify the entire AI model exchange standard. ONNX defines a set of standard formats that are independent of the environment and platform, providing a foundation for the interoperability of AI models, allowing AI models to be used interchangeably in different frameworks and environments. Hardware and software vendors can optimize model performance based on the ONNX standard, benefiting all frameworks compatible with ONNX. In simple terms, ONNX is the intermediary for model conversion.
Usage Scenarios:
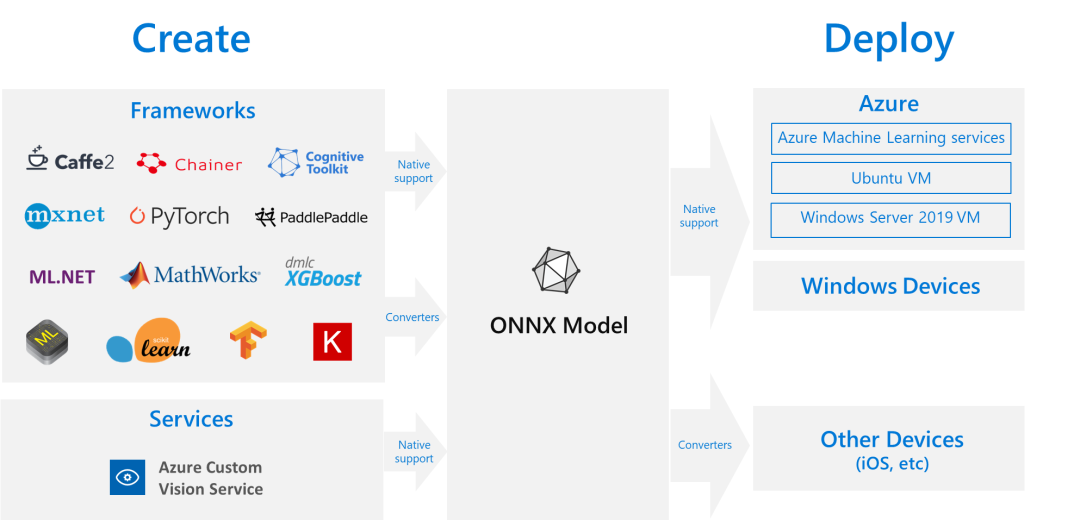
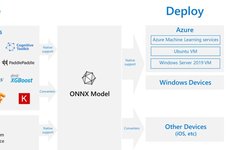
No matter what training framework you use to train the model (such as TensorFlow/PyTorch/OneFlow/Paddle), you can uniformly convert these framework models to ONNX for storage after training. The ONNX file not only stores the weights of the neural network model but also stores structural information about the model and input/output information for each layer in the network. Currently, ONNX mainly focuses on model prediction (inferring), and the converted ONNX model can be easily deployed in compatible ONNX runtime environments.
Usage Method:
[Code Example] Run shape inference on the ONNX model: https://github.com/onnx/onnx
import onnx
from onnx import helper, shape_inference
from onnx import TensorProto
# Preprocessing: Create a model with two nodes, Y is unknown
node1 = helper.make_node("Transpose", ["X"], ["Y"], perm=[1, 0, 2])
node2 = helper.make_node("Transpose", ["Y"], ["Z"], perm=[1, 0, 2])
graph = helper.make_graph(
[node1, node2],
"two-transposes",
[helper.make_tensor_value_info("X", TensorProto.FLOAT, (2, 3, 4))],
[helper.make_tensor_value_info("Z", TensorProto.FLOAT, (2, 3, 4))],
)
original_model = helper.make_model(graph, producer_name="onnx-examples")
# Check the model and print Y's information
onnx.checker.check_model(original_model)
print(f"Before shape inference, the shape info of Y is:\n{original_model.graph.value_info}")
# Perform inference on the model
inferred_model = shape_inference.infer_shapes(original_model)
# Check the model and print Y's information
onnx.checker.check_model(inferred_model)
print(f"After shape inference, the shape info of Y is:\n{inferred_model.graph.value_info}")
1.2 NCNN
Introduction:
ncnn is a high-performance neural network forward computation framework optimized for mobile devices, and it is the first open-source project established by Tencent Youtu Lab. From its design inception, ncnn has deeply considered deployment and usage on mobile devices, with no third-party dependencies, cross-platform capabilities, and faster CPU speed on mobile devices than all known open-source frameworks. Based on ncnn, developers can easily port deep learning algorithms to mobile devices for efficient execution and develop AI apps. ncnn is currently used in many Tencent applications, such as QQ, Qzone, WeChat, and TianTian Photo.
Usage Scenarios:
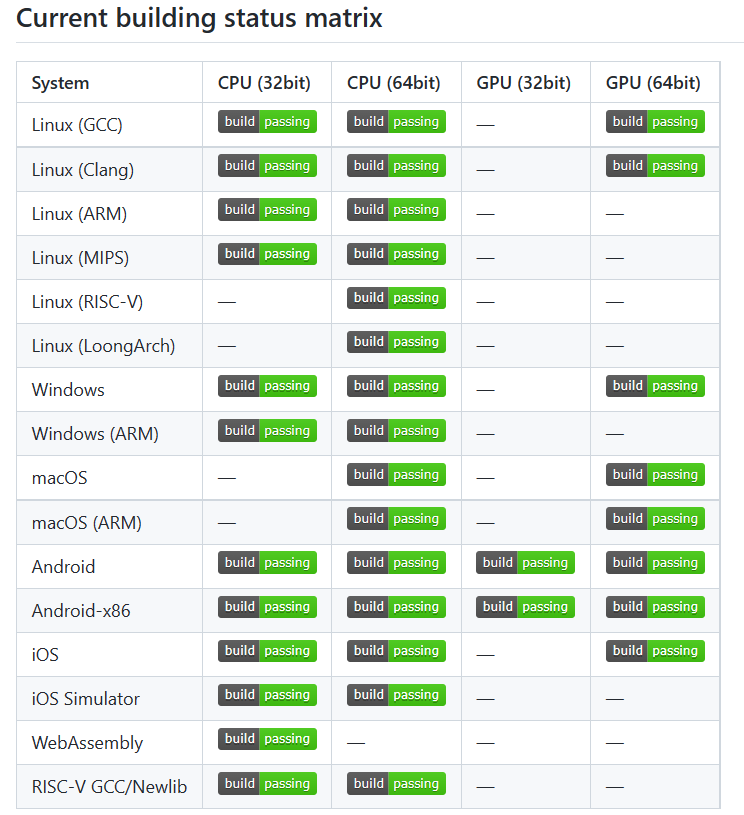
From NCNN’s development matrix, it can be seen that NCNN covers almost all commonly used system platforms, especially with better applicability on mobile platforms, and can use GPU to deploy models on Linux, Windows, Android, iOS, and macOS platforms.
Framework Features:
- Supports convolutional neural networks, multi-input, and multi-branch structures, can compute partial branches
- No dependencies on any third-party libraries, does not rely on BLAS/NNPACK and other computing frameworks
- Pure C++ implementation, cross-platform, supports Android/iOS, etc.
- ARM Neon assembly-level optimization, extremely fast computation speed
- Fine memory management and data structure design, very low memory usage
- Supports multi-core parallel computing acceleration, ARM big.LITTLE CPU scheduling optimization
- Supports new low-consumption Vulkan API GPU acceleration
- Expandable model design, supports 8bit quantization and half-precision floating-point storage, can import caffe/pytorch/mxnet/onnx/darknet/keras/tensorflow (mlir) models
- Supports direct memory zero-copy reference loading of network models
- Can register custom layer implementations and extensions
Usage Method:
[Code Example] Input data and infer output: https://github.com/Tencent/ncnn/wiki
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include "net.h"
int main()
{
// opencv reads input image
cv::Mat img = cv::imread("image.ppm", CV_LOAD_IMAGE_GRAYSCALE);
int w = img.cols;
int h = img.rows;
// Subtract mean and scale operation, the final input data value range is [-1,1]
ncnn::Mat in = ncnn::Mat::from_pixels_resize(img.data, ncnn::Mat::PIXEL_GRAY, w, h, 60, 60);
float mean[1] = { 128.f };
float norm[1] = { 1/128.f };
in.substract_mean_normalize(mean, norm);
// Build NCNN's net and load the converted model
ncnn::Net net;
net.load_param("model.param");
net.load_model("model.bin");
// Create network extractor, set network input, number of threads, light mode, etc.
ncnn::Extractor ex = net.create_extractor();
ex.set_light_mode(true);
ex.set_num_threads(4);
ex.input("data", in);
// Call extract interface to complete network inference and obtain output results
ncnn::Mat feat;
ex.extract("output", feat);
return 0;
}
1.3 OpenVINO
Introduction:
OpenVINO is a toolkit that can accelerate the development speed of high-performance computer vision and deep learning visual applications, supporting deep learning on various Intel platform hardware accelerators and allowing direct heterogeneous execution. The OpenVINO™ toolkit is a comprehensive toolkit for rapid application and solution development, addressing various tasks including simulating human vision, automatic speech recognition, natural language processing, recommendation systems, etc. This toolkit is based on the latest generation of artificial neural networks, including convolutional neural networks (CNNs), recurrent and attention-based networks, and can scale computer vision and non-vision workloads on Intel® hardware to maximize performance. It accelerates applications through high-performance AI and deep learning inference from edge to cloud.
Usage Scenarios:
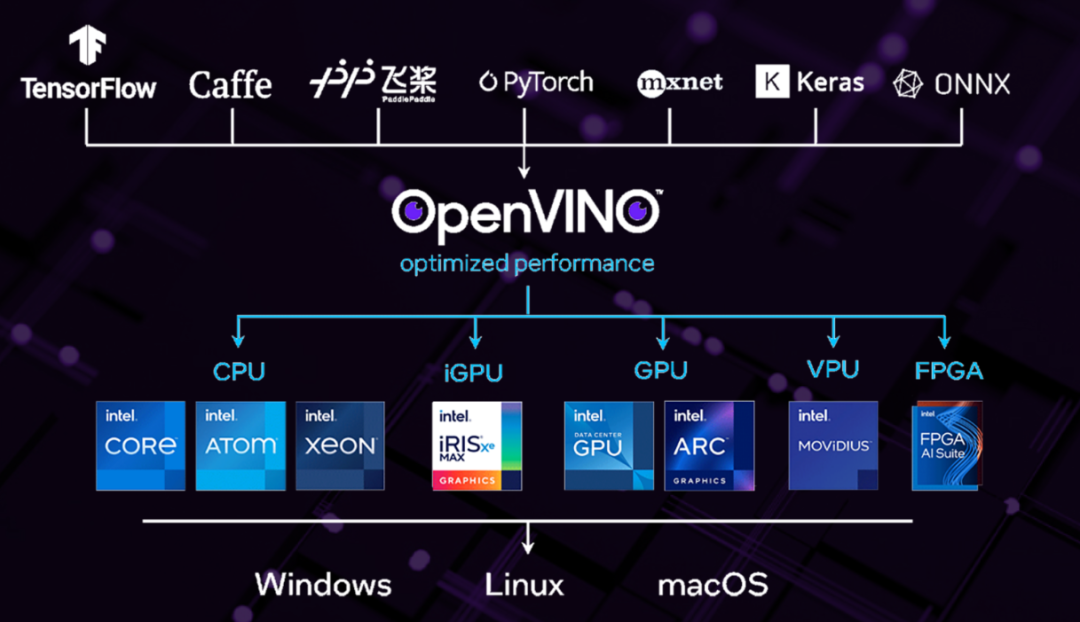
Framework Features:
Before model deployment, OpenVINO first optimizes the model, and the model optimizer optimizes the model’s topology, removing unnecessary layers and merging similar operations to speed up computation efficiency and reduce memory copies; FP16 and INT8 quantization can also reduce model size and improve performance while ensuring minimal accuracy loss. In terms of deployment, OpenVINO’s development is relatively simple, providing programming interfaces in C, C++, and Python3. Its greatest advantage is the ease of portability when deploying on different Intel hardware platforms. The inference engine provides a unified interface for different hardware, and developers do not need to worry about the underlying hardware implementation to accelerate model inference across different hardware platforms.
- Enables CNN-based deep learning inference at the edge
- Supports heterogeneous execution across Intel® CPUs, Intel® integrated graphics, Intel® Neural Compute Stick 2, and Intel® Vision Accelerator Design via Intel® Movidius™ VPU
- Accelerates time to market with easy-to-use computer vision function libraries and pre-optimized kernels
- Includes optimized calls for computer vision standards (including OpenCV* and OpenCL™)
Usage Method:
[Code Example] Implement typical OpenVINO™ running inference in applications: https://docs.openvino.ai/latest/openvino_docs_OV_UG_Integrate_OV_with_your_application.html
#include <openvino/openvino.hpp>
// 1. Create OpenVINO™ core to manage available devices and read model objects
ov::Core core;
// 2. Compile the model for a specific device
ov::CompiledModel compiled_model = core.compile_model("model.onnx", "AUTO");
// 3. Create inference request
ov::InferRequest infer_request = compiled_model.create_infer_request();
// 4. Set input
// Get the model's input port
auto input_port = compiled_model.input();
// Create tensor from external memory
ov::Tensor input_tensor(input_port.get_element_type(), input_port.get_shape(), memory_ptr);
// Set an input tensor for the model
infer_request.set_input_tensor(input_tensor);
// 5. Start inference
infer_request.start_async();
infer_request.wait();
// 6. Process inference results
// Get output tensor by tensor_name
auto output = infer_request.get_tensor("tensor_name");
const float *output_buffer = output.data<const float>();
// output_buffer[] - Access output tensor data
// 7. Free allocated objects (only applicable for C)
ov_shape_free(&input_shape);
ov_tensor_free(output_tensor);
ov_output_const_port_free(input_port);
ov_tensor_free(tensor);
ov_infer_request_free(infer_request);
ov_compiled_model_free(compiled_model);
ov_model_free(model);
ov_core_free(core);
// Create structure for the project
project/
├── CMakeLists.txt - CMake file to build
├── ... - Additional folders like includes/
└── src/ - source folder
└── main.cpp
build/ - build directory
...
// Create Cmake script
cmake_minimum_required(VERSION 3.10)
set(CMAKE_CXX_STANDARD 11)
find_package(OpenVINO REQUIRED)
add_executable(${TARGET_NAME} src/main.cpp)
target_link_libraries(${TARGET_NAME} PRIVATE openvino::runtime)
// Build the project
cd build/
cmake ../project
cmake --build .
1.4 TensorRT
Introduction:
NVIDIA TensorRT™ is an SDK for high-performance deep learning inference. This SDK includes a deep learning inference optimizer and runtime environment, providing low latency and high throughput for deep learning inference applications.During inference, applications based on TensorRT can execute up to 40 times faster than on CPU platforms. With TensorRT, you can optimize neural network models trained in all major frameworks, precisely calibrate low precision, and ultimately deploy models to large-scale data centers, embedded, or automotive product platforms.TensorRT is built on NVIDIA’s parallel programming model, CUDA, helping you leverage libraries, development tools, and techniques in CUDA-X for inference across all deep learning frameworks for AI, autonomous machines, high-performance computing, and graphics optimization.TensorRT provides INT8 and FP16 optimizations for production deployment of various deep learning inference applications, such as video streaming, speech recognition, recommendation, and natural language processing. Reducing inference precision significantly decreases application latency, which meets the requirements of many real-time services, autonomous, and embedded applications.
Usage Scenarios:
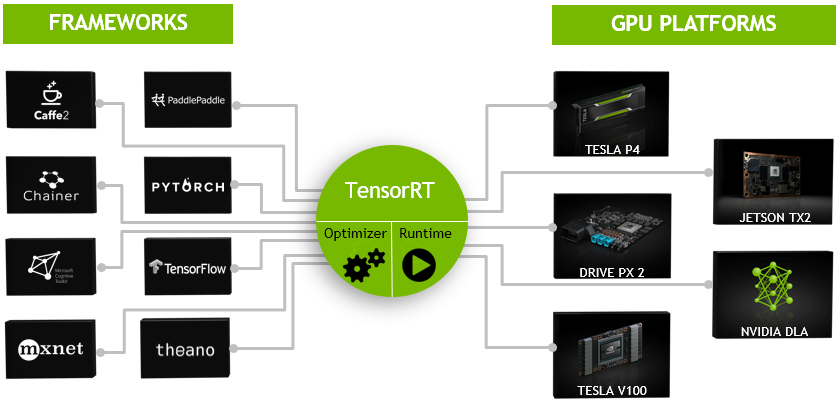
Framework Features:
1. Weight and activation precision calibrationMaximize throughput by quantizing the model to INT8 while maintaining high accuracy2. Layer and tensor fusionOptimize GPU memory and bandwidth usage by fusing nodes in the kernel3. Kernel auto-tuningSelect the best data layer and algorithm based on the target GPU platform4. Dynamic tensor memoryMinimize memory usage and efficiently reuse memory for tensors5. Multi-stream executionScalable design for parallel processing of multiple input streams
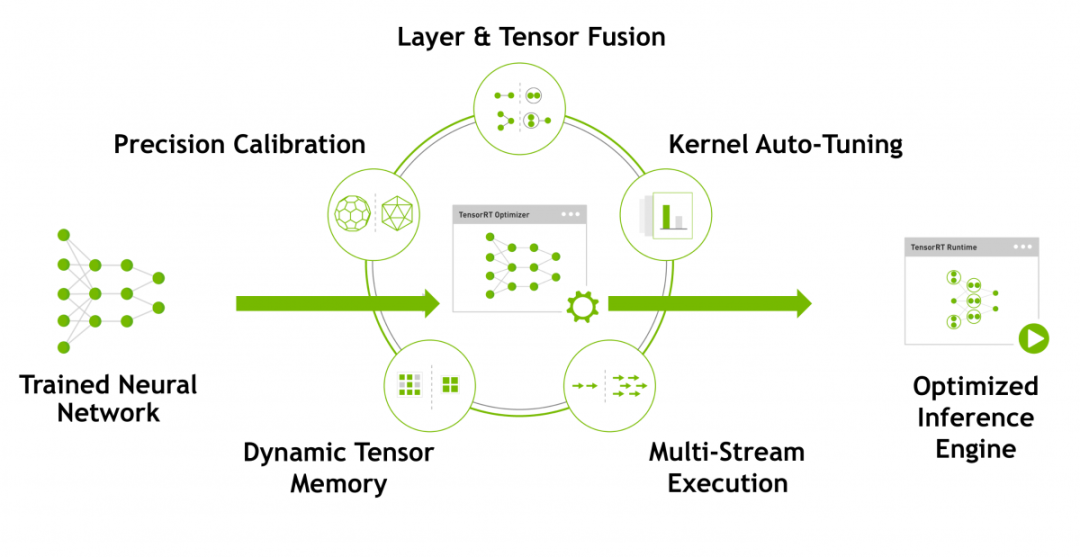
The image is taken from TensorRT’s official website, which lists some of the technologies used in TensorRT. It can be seen that model quantization, dynamic memory optimization, layer fusion, and other technologies have been integrated into TensorRT, which is also why it can greatly improve the speed of model inference. Overall, TensorRT transforms trained models into code that can run at high performance on specific platforms (GPUs) through a series of optimization techniques, which is the Inference Engine generated in the final image.
Usage Method:
1. Export the model2. Select batch size3. Select precision4. Convert the model:
- Use TF-TRT
- Automatically convert ONNX from file
- Manually build the network using TensorRT API (C++ or Python)
5. Deploy the model:
- Deploy in TensorFlow
- Use standalone TensorRT runtime API
- Use NVIDIA Triton Inference Server
For detailed model conversion and deployment methods, see: [Quick Start Guide :: NVIDIA Deep Learning TensorRT Documentation]: https://docs.nvidia.com/deeplearning/tensorrt/quick-start-guide/index.html
1.5 Mediapipe
Introduction:
MediaPipe is a multimedia machine learning model application framework developed and open-sourced by Google Research. A series of important products at Google, such as YouTube, Google Lens, ARCore, Google Home, and Nest, have deeply integrated MediaPipe. As a cross-platform framework, MediaPipe can be deployed not only on the server side but also on multiple mobile devices (Android and Apple iOS) and embedded platforms (Google Coral and Raspberry Pi) as a device-side machine learning inference framework.In addition to the above features, MediaPipe also supports inference engines for TensorFlow and TF Lite, and any TensorFlow and TF Lite models can be used on MediaPipe. Additionally, MediaPipe supports the device’s own GPU acceleration on mobile and embedded platforms.
Usage Scenarios:
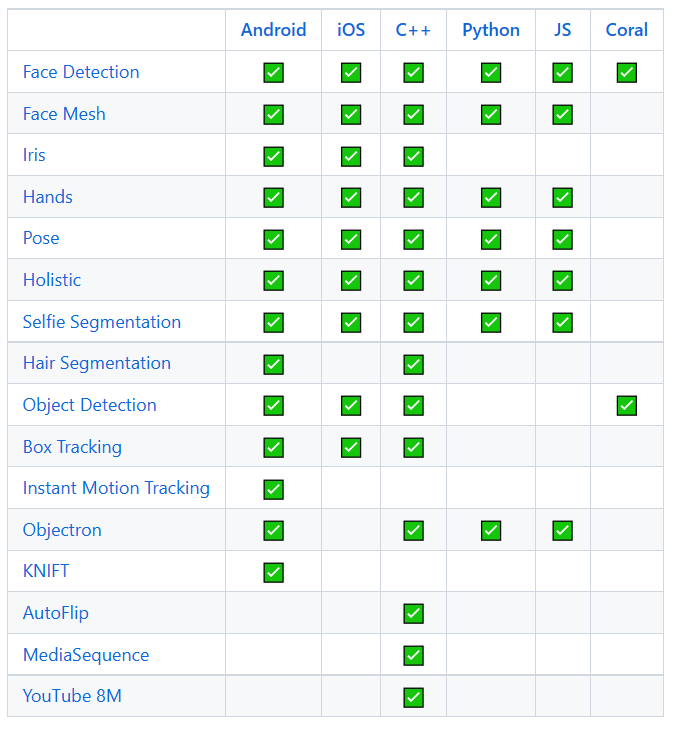
Framework Features:
- End-to-end acceleration: Built-in fast ML inference and processing, even on ordinary hardware
- Build once, deploy everywhere: A unified solution applicable to Android, iOS, desktop/cloud, web, and IoT
- Ready-to-use solutions: Cutting-edge ML solutions showcasing the full functionality of the framework
- Free and open-source: Frameworks and solutions under Apache 2.0, fully extensible and customizable
Usage Method:
[Code Example] For face detection: https://google.github.io/mediapipe/solutions/face_detection
import cv2
import mediapipe as mp
mp_face_detection = mp.solutions.face_detection
mp_drawing = mp.solutions.drawing_utils
# For static images:
IMAGE_FILES = []
with mp_face_detection.FaceDetection(
model_selection=1, min_detection_confidence=0.5) as face_detection:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
# Convert BGR image to RGB and process with MediaPipe face detection.
results = face_detection.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# Draw face detection on each face in the image.
if not results.detections:
continue
annotated_image = image.copy()
for detection in results.detections:
print('Nose tip:')
print(mp_face_detection.get_key_point(
detection, mp_face_detection.FaceKeyPoint.NOSE_TIP))
mp_drawing.draw_detection(annotated_image, detection)
cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image)
# For webcam input:
cap = cv2.VideoCapture(0)
with mp_face_detection.FaceDetection(
model_selection=0, min_detection_confidence=0.5) as face_detection:
while cap.isOpened():
success, image = cap.read();
if not success:
print("Ignoring empty camera frame.")
# If loading video, use "break" instead of "continue".
continue
# To improve performance, you can mark the image as non-writeable to pass by reference.
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = face_detection.process(image)
# Draw face detection annotations on the image.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.detections:
for detection in results.detections:
mp_drawing.draw_detection(image, detection)
# Flip the image horizontally for selfie view display.
cv2.imshow('MediaPipe Face Detection', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release();
2. Framework Comparison
Application Platforms:
Model inference deployment frameworksApplication Platforms
| NCNN | Mobile |
| OpenVINO | Can be used on CPU, GPU, and embedded platforms, especially preferred on CPU. DepthAI embedded spatial AI platform. |
| TensorRT | Inference framework that can only be used on NVIDIA GPUs. NVIDIA’s Jetson platform. |
| Mediapipe | Server-side, mobile, embedded platforms, TPU. |
Research and Development Units:
- NCNN, a mobile deployment tool developed by Tencent;
- OpenVINO, a deployment tool developed by Intel for its own devices;
- TensorRT, a deployment tool developed by NVIDIA for its GPUs;
- Mediapipe, a deployment tool developed by Google for its hardware devices and deep learning frameworks;
- Open Neural Network Exchange format jointly developed by Microsoft, Amazon, Facebook, IBM, and others;
How to Choose:
- ONNXRuntime is an inference framework that can run on multiple platforms (Windows, Linux, Mac, Android, iOS), accepting ONNX format model inputs, and supports inference on GPU and CPU. The only drawback is that ONNX nodes are relatively fine-grained, and inference speed can sometimes be lower than other inference frameworks like TensorRT.
- NCNN is targeted at mobile deployment. Its advantages are early open-source availability, a very stable community, and high open-source influence.
- OpenVINO is a friendly inference framework for Intel CPUs and GPUs, developed by Intel, and it also integrates with different training frameworks like TensorFlow, PyTorch, Caffe, etc. A potential drawback is that it only supports Intel hardware products.
- TensorRT has advantages that other frameworks do not have for NVIDIA GPUs; if running on NVIDIA GPUs, TensorRT is usually the fastest inference framework. Mainstream training frameworks like TensorFlow and PyTorch can be converted into models that can run on TensorRT. However, TensorRT’s limitation is that it can only run on NVIDIA GPUs and does not have open-source kernels.
- MediaPipe does not support other deep learning frameworks apart from TensorFlow. MediaPipe’s main use case is rapid prototyping of machine learning pipelines using inference models and other reusable components. MediaPipe also helps demonstrate and apply machine learning technologies across various hardware platforms, building world-class ML solutions and applications for mobile, desktop/cloud, web, and IoT devices.
3. Conclusion
This article mainly introduces five inference frameworks, aiming to give everyone a more intuitive understanding of the characteristics, application scenarios, and selection criteria of these frameworks, providing limited help for future learning. Please feel free to provide corrections for any shortcomings.
References
- https://learn.microsoft.com/en-us/windows/ai/
- https://github.com/Tencent/ncnn
- https://zhuanlan.zhihu.com/p/344442534
- https://github.com/google/mediapipe
- https://www.zhihu.com/question/346965029/answer/2395418101
ABOUT
About Us
Deep Blue Academy is an online education platform focused on artificial intelligence, with tens of thousands of partners learning on the platform, many of whom come from prestigious institutions at home and abroad, such as Tsinghua University and Peking University.