Click the card below to follow the 「Intelligent Book Boy」 public account
Click to join👉「Intelligent Book Boy」 group chat





Cutting-edge AI visual perception full-stack knowledge👉「Classification, Detection, Segmentation, Key Points, Lane Line Detection, 3D Vision (Segmentation, Detection), Multi-modal, Object Tracking, NerF」
Welcome to scan the QR code above to join Intelligent Book Boy – Knowledge Planet, sharing papers, study notes, problem-solving solutions, deployment plans, and full-stack Q&A, looking forward to communication!

The author proposes the Waterfall Transformer architecture for human pose estimation (WTPose), which is a single-pass, end-to-end trainable framework aimed at multi-person pose estimation.
The author’s framework utilizes a Transformer-based Waterfall module to generate multi-scale feature maps from various backbone stages.
This module performs filtering operations in a cascading architecture to expand the receptive field and capture local and global context, thereby improving the network’s overall feature representation capability.
Experiments on the COCO dataset show that the WTPose architecture, using a modified Swin backbone and the Transformer-based Waterfall module, outperforms other Transformer architectures in multi-person pose estimation.
1. Introduction
Human pose estimation is a challenging computer vision task with wide practical applications. Deep learning methods based on Convolutional Neural Networks (CNNs) have improved state-of-the-art performance. Recently, Vision Transformers have shown excellent performance in computer vision tasks, including pose estimation.
In this paper, the author proposes a framework called WTPose, a “Waterfall Transformer” architecture that operates within a flexible framework to improve the performance of baseline models. Figure 1 shows an example of pose estimation using WTPose. A key feature of the author’s architecture is the integration of multi-scale Waterfall Transformer modules (WTM) to enhance the performance of Vision Transformer models (such as the Shifted Window (Swin) Transformer). The author processes feature maps extracted from multiple levels of the backbone network through WTM’s waterfall branches. This module executes filtering operations based on a dilated attention mechanism, increasing the field of view (FOV) and capturing local and global context, thereby significantly improving performance. The main contributions of this paper include:

The author proposes a novel Waterfall Transformer architecture for pose estimation, which is a single-pass, end-to-end trainable multi-scale method suitable for top-down multi-person 2D pose estimation. This method includes a multi-scale attention module and employs a dilated attention mechanism to capture a larger receptive field, thus acquiring global and local context.
The author’s experiments on the COCO dataset show that this method improves pose estimation performance compared to similar Transformer methods.
2. Related Work
2.1. CNNs for pose estimation
With the development of deep convolutional neural networks, human pose estimation has achieved outstanding results. The Convolutional Pose Machine (CPM) architecture includes multiple stages that progressively generate more refined joint detections. The OpenPose method introduces Part Affinity Fields to handle multiple poses in a single image. The Stacked Hourglass network uses repeated bottom-up and top-down processing, with supervision in between, to handle data at all scales and capture the best spatial relationships related to the body, achieving accurate human pose estimation. Building on this, multi-context attention methods designed Hourglass Residual Units (HRUs) to generate attention maps with larger receptive fields and different semantic levels. Additionally, post-processing with Conditional Random Fields (CRFs) generates locally and globally consistent human pose estimations.
The High-resolution Network (HRNet) architecture connects high-resolution sub-networks and low-resolution sub-networks in parallel, maintaining high-resolution representations throughout the process and generating more accurate and spatially precise pose estimations. Multi-stage pose networks operate similarly to HRNet but employ cross-stage feature aggregation strategies to pass information from earlier stages to later stages and are equipped with a coarse-to-fine supervision mechanism.
Methods like UniPose (+), OmniPose, and BAPose propose various variants of the Waterfall Atrous Spatial Pooling (WASP) module for single-person, multi-person top-down, and multi-person bottom-up pose estimation. The WASP module inspires the Waterfall Transformer module in WTPose, as it significantly enhances the network’s multi-scale representation capability and field of view (FOV), extracting features that contain more contextual information, thus achieving more accurate pose estimations without the need for subsequent processing.
Vision Transformers for Pose Estimation
In recent years, there has been a surge of interest in using Transformer architectures for human pose estimation. In early works, CNN Backbone networks were used as feature extractors, while Transformers were seen as superior decoders. The TransPose architecture combines the initial part of a CNN-based Backbone network for feature extraction from images and employs a standard Transformer architecture, utilizing attention layers to learn dependencies and predict key points of 2D human pose. However, TransPose has limitations in modeling direct relationships between key points.
TokenPose explicitly embeds each key point as a token and learns visual cues and constraint relationships through self-attention interactions. HRFormer, inspired by HRNet, adopts a multi-resolution parallel design. It uses convolutions in the stem and the first stage, followed by Transformer blocks. The Transformer blocks perform self-attention on non-overlapping partitioned feature maps and use 3×3 depth convolutions for cross-attention between partitioned maps. ViTPose employs a simple non-hierarchical Vision Transformer as a Backbone for feature extraction. This architecture then uses deconvolution layers or bilinear upsampling decoders for 2D pose estimation. PoseFormer proposes a pure Transformer architecture based on 2D pose sequences in video frames for 3D pose estimation.
3. Waterfall Transformer
The proposed Waterfall Transformer architecture, as shown in Figure 2, is a single-pass, end-to-end trainable network that combines a modified Swin Transformer Backbone and the author’s Transformer-based multi-scale waterfall module for multi-person pose estimation. The slicing layers in Swin are replaced by two convolutions (Stem) and the first residual block of ResNet-101, improving the feature representation of Swin.
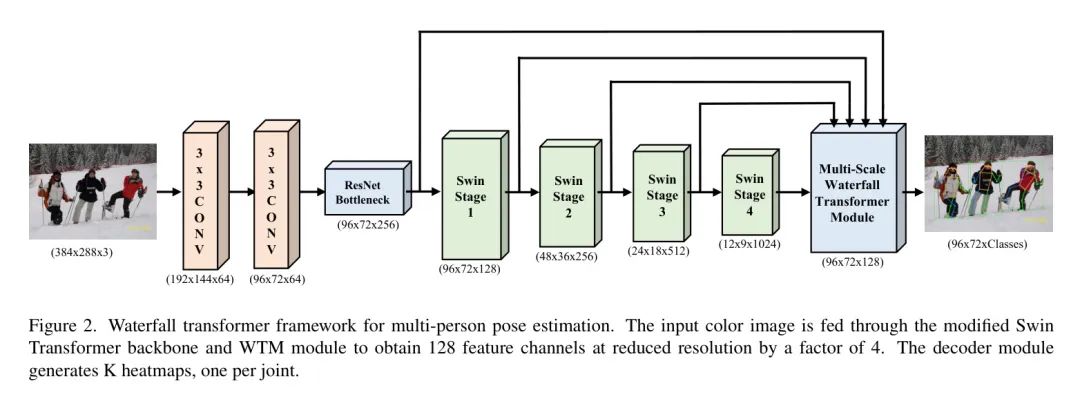
The processing pipeline of WTPose is shown in Figure 2. Input images are fed into the backbone network constructed by the author’s modified Swin Transformer. Multi-scale feature maps from multiple stages of Swin are processed through the author’s Waterfall Transformer module (WTM) and fed into a decoder to generate K heatmaps, one for each joint. The multi-scale WTM maintains high-resolution feature maps and can generate accurate predictions for visible and occluded joints.
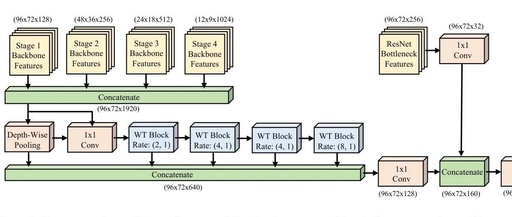
The architecture of the author’s Waterfall Transformer module is shown in Figure 3. WTM is inspired by the Disentangled Waterfall Atrous Spatial Pooling (D-WASP) module, which enhances multi-scale representation using dilated blocks and a waterfall architecture. However, unlike D-WASP, which expands the receptive field through dilated convolutions, the proposed method employs a dilated Transformer block with both dilated and non-dilated neighborhood attention to expand the receptive field. This dilated Transformer is built on the DiNAT architecture, including dilated and non-dilated neighborhood attention. The dilated neighborhood attention expands the local receptive field by increasing the dilation rate and performs sparse global attention; while the non-dilated neighborhood attention limits the self-attention of each pixel to its nearest neighbor range.
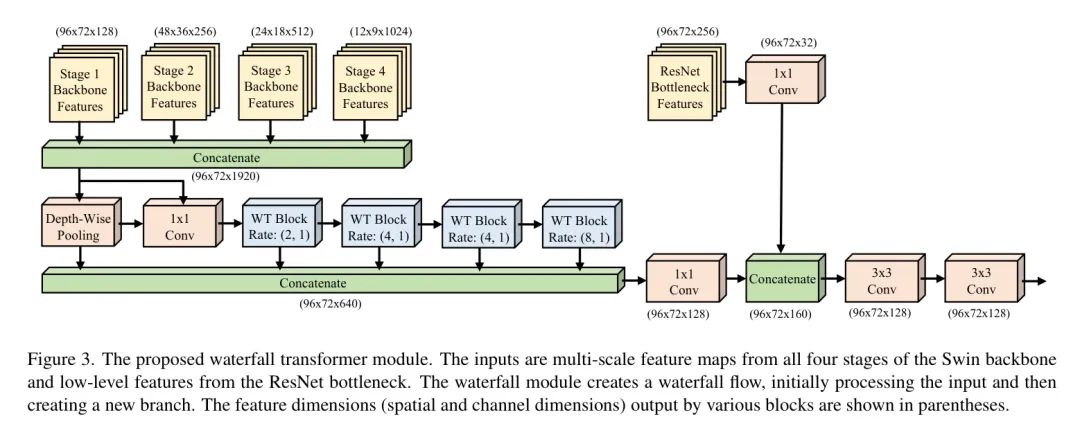
To address the loss of contextual and spatial information due to the hierarchical backbone structure, WTM processes multi-scale feature maps from the four stages of the Swin Backbone through waterfall branches. First, the WTM module uses bilinear interpolation to upsample low-resolution feature maps from the second, third, and fourth stages to match the high-resolution feature map from the first stage, and then combines all feature maps to generate the multi-scale feature representation required for enhanced joint estimation.
The output feature maps are sent to Waterfall Transformer Blocks (WTB), which extend the field of view through a cascade of progressively enhanced filtering stages. Each WTB contains two types of attention mechanisms: Dilated Multi-Head Neighborhood Self-Attention (D-MHSA), followed by a Multi-Layer Perceptron (MLP) to capture global context; and Non-dilated Multi-Head Neighborhood Self-Attention (N-MHSA), followed by an MLP to capture local context.
Here, and represent the output features of the MHSA module and MLP module in the block respectively; DMHSA and N-MSHA are multi-head self-attention mechanisms based on dilated and non-dilated windows.
The waterfall module is designed to create a waterfall stream processing procedure, initially processing the input and then generating new branches. Unlike cascading methods, WTM achieves a more comprehensive integration by combining all streams from all WTB branches and the depthwise separable pooling (DWP) layers in the multi-scale representation.
Here, the summation symbol represents the concat operation, which is low-level features obtained from the ResNet Bottleneck layer, representing convolution, while represents convolution with a kernel size of 3 and a stride of 1.
4. Experiments
The author conducted multi-person pose estimation experiments on the Common Objects in Context (COCO) dataset. The COCO dataset contains over 200,000 outdoor images and includes 250,000 instances of human targets. The author used the 2017 version of the COCO training set, which contains 57,000 images and 150,000 instances of human targets for training WTPose, and validated on the val 2017 validation set, which contains 5,000 images. The annotated poses include 17 key points.
The author employs Object Keypoint Similarity (OKS) to evaluate the author’s model. According to the evaluation framework set by COCO, the author reports OKS as the average precision (AP) of all instances IOU between 0.5 to 0.9, as well as at 0.5 and 0.75, including the average precision for medium and large instances. The author also reports the average recall (AR) between 0.5 to 0.95.
The author used the Swin Base (Swin-B) Transformer as the backbone network and initialized it with pre-trained weights from previous work. By default, the Swin-B architecture adopts a window size of 7. For the WTM module, the author experimented with various dilation rates and found that alternating between dilated windows, which provide a large receptive field, and non-dilated windows, which provide a small receptive field, can improve prediction performance. The dilation rates for the WTB blocks were set to (2,1), (4,1), (4,1), (8,1), while maintaining a window size of 7.
The author’s model was trained using the mmpose codebase on a system with 4 A100 GPUs, with a batch size set to 32. The author adopted the default training settings in mmpose to train WTPose and used the AdamW optimizer, with a learning rate set to 5e-4. The author’s model was trained for a total of 210 epochs, with a learning rate decay by a factor of 10 at the 170th and 200th epochs.
4.1. Experimental results on the COCO dataset
The author trained and tested on the COCO dataset and compared WTPose with the Swin framework, as detailed in Table 1. The author’s WTPose model has 1.3 million more parameters than Swin-B, with average precision and average recall improved by 1.2% and 0.9%, respectively. Compared to Swin-L, WTPose is approximately 54% smaller but still outperforms Swin-L in average precision and average recall by 0.8% and 0.6%, respectively. The Waterfall Transformer module improved the feature maps and increased the accuracy of keypoint detection.
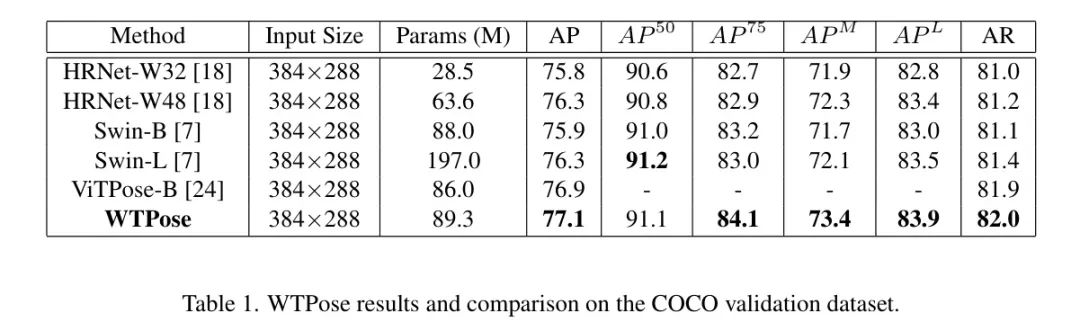
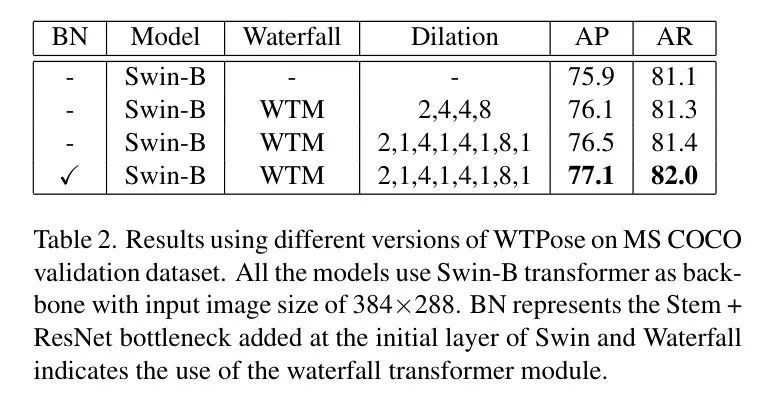
The author conducted ablation studies in WTPose to explore the effects of various components. Table 2 shows the results of various configurations using the Swin-B backbone and input images with a resolution of 384×288. The author set the window size to 7×7, allocated 8 heads in each attention layer, and selected dilation rates of 2, 4, 4, and 8 to increase the receptive area size of different WTB blocks. The receptive area sizes at dilation rates of 1, 2, 4, and 8 are 7×7, 13×13, 25×25, and 49×49, respectively. First, the author tested the case of dilation rates of 2, 4, 4, and 8 for each WTB separately, performing a dilated multi-head self-attention operation with the specified dilation rate in each WTB. Then, the author used a dilated and a non-dilated multi-head self-attention mechanism for each WTB, setting the dilation rates to (2, 1), (4, 1), (4, 1), and (8, 1). The author’s main observations are: (i) combining the Waterfall Transformer module with the modified Swin backbone can improve feature representation; (ii) adding a Stem and ResNet Bottleneck at the beginning of Swin-B can further enhance the backbone’s capability.
5. Conclusion
The author proposes a Waterfall Transformer framework for multi-person pose estimation. WTPose combines the author’s Waterfall Transformer module, which processes feature maps from various stages of the Swin backbone network, and increases the receptive field and captures local and global contexts through cascaded dilated and non-dilated attention blocks.
WTPose employs a modified Swin-B backbone network and the Waterfall Transformer module to achieve performance improvements over other Swin models.
References
[0]. Waterfall Transformer for Multi-person Pose Estimation.

Scan to join👉「Intelligent Book Boy」 group chat
(Note: Direction+ School/Company+ Nickname)