


Organized by: Zhiyuan Community Luo Li
NLP Hotspots in IJCAI 2020 Word Cloud
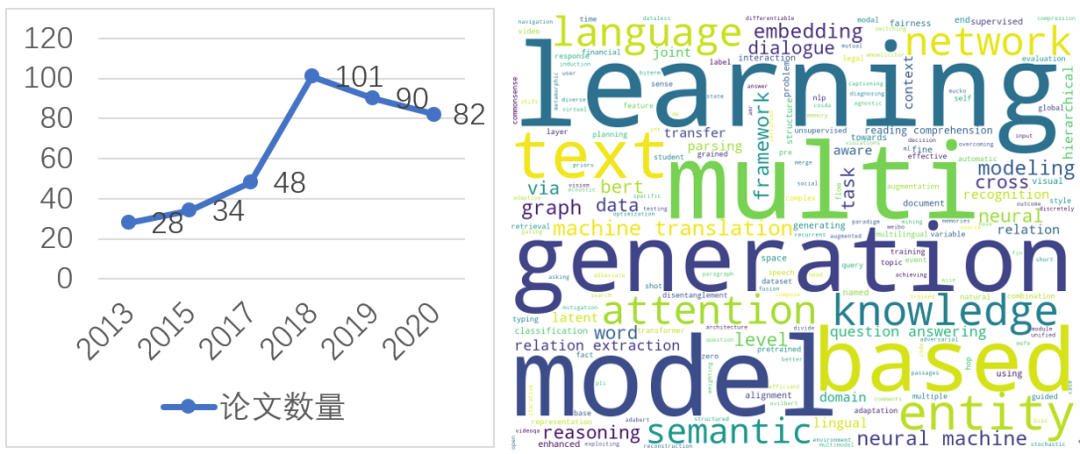 Figure 1: Number of NLP papers in IJCAI over the years and keyword “word cloud” analysis
Figure 1: Number of NLP papers in IJCAI over the years and keyword “word cloud” analysis Figure 2: Nine highlights in IJCAI NLP research
Figure 2: Nine highlights in IJCAI NLP research
Algorithmic Level Research Summary in NLP
1. Unsupervised Pre-training
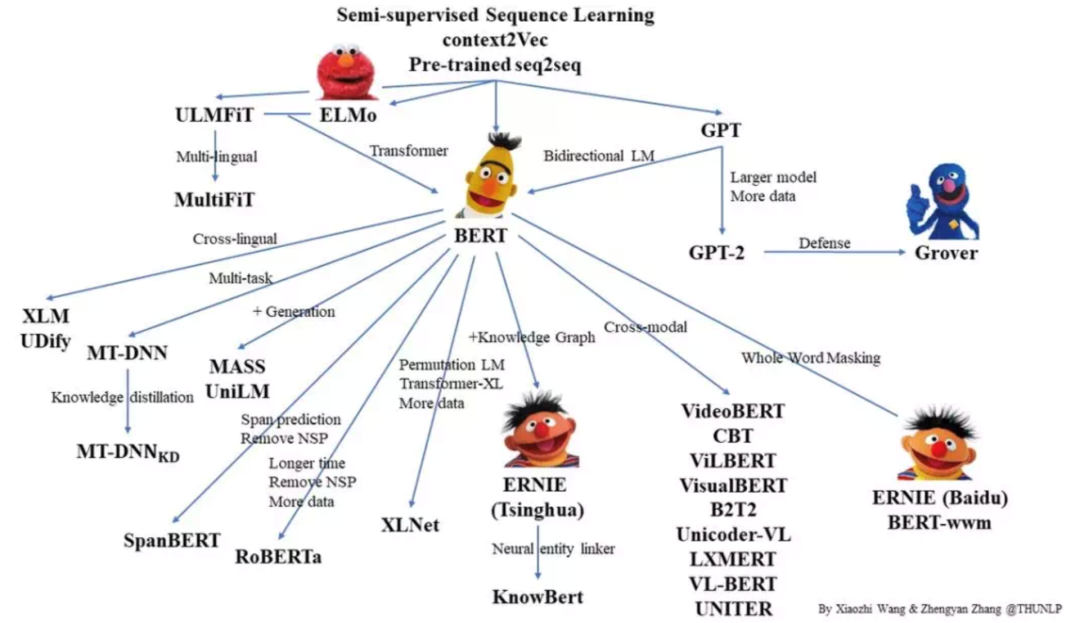 Figure 3: General Language Models Related to BERT
Figure 3: General Language Models Related to BERT
2. Cross-Language Learning
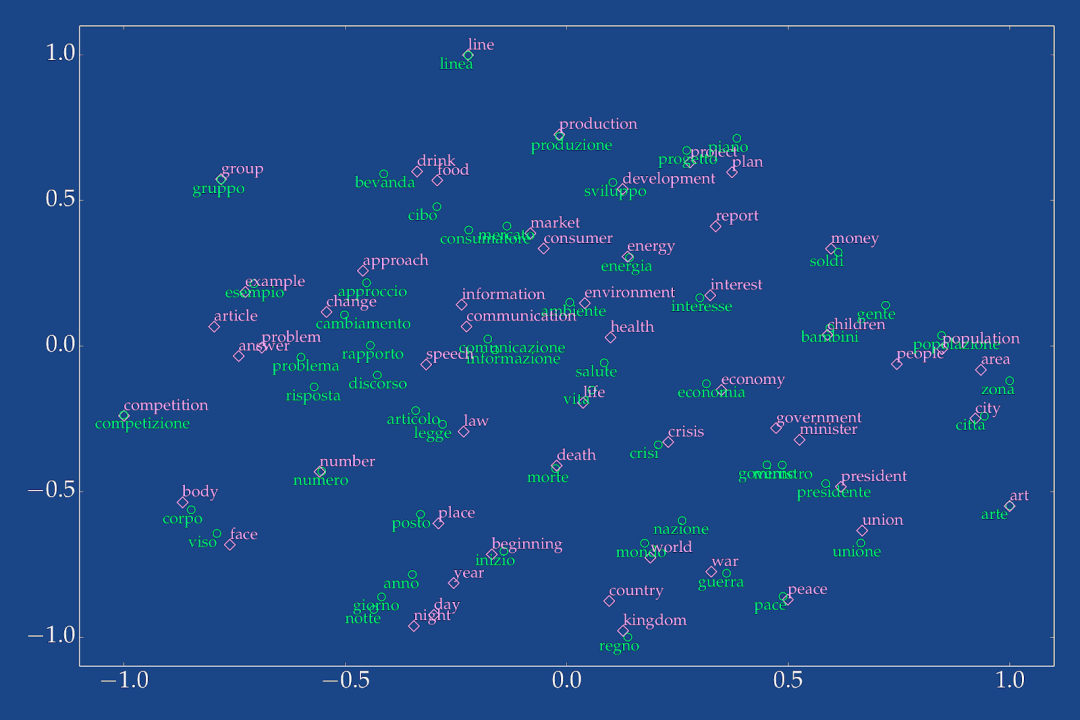 Figure 4: Example of Cross-Language Learning
Figure 4: Example of Cross-Language Learning
3. Meta-Learning and Few-Shot Learning
4. Transfer Learning
5. Errors
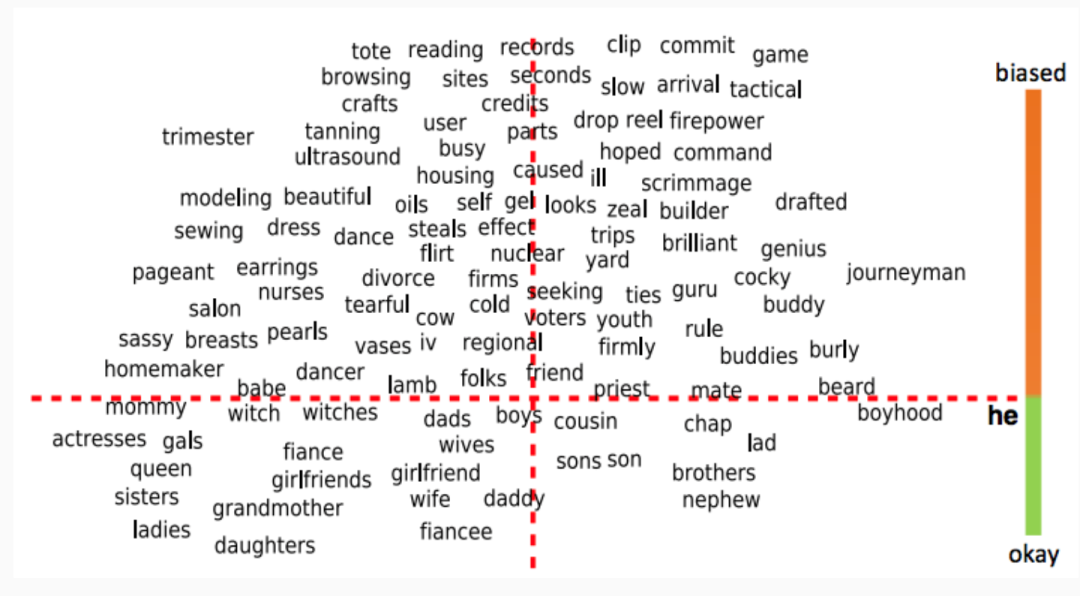 Figure 5: Example of Bias in NLP
Figure 5: Example of Bias in NLP
6. Knowledge Fusion
Task Level Research Summary in NLP
1. Question Answering
2. Natural Language Generation
3. Multi-Modality
References
[1] Agostina Calabrese, Michele Bevilacqua, Roberto Navigli. EViLBERT: Learning Task-Agnostic Multimodal Sense Embeddings. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp.481-487.
[2] Daoyuan Chen, Yaliang Li, Minghui Qiu, et al. AdaBERT: Task-Adaptive BERT Compression with Differentiable Neural Architecture Search. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 2463-2469.
[3] Xiaobin Tang, Jing Zhang, Bo Chen, et al. BERT-INT: A BERT-based Interaction Model For Knowledge Graph Alignment. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3174-3180.
[4] Yunqiu Shao, Jiaxin Mao, Yiqun Liu, et al. BERT-PLI: Modeling Paragraph-Level Interactions for Legal Case Retrieval. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3501-3507.
[5] Zhuang Liu, Degen Huang, Kaiyu Huang, et al. FinBERT: A Pre-trained Financial Language Representation Model for Financial Text Mining. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Special Track on AI in FinTech. 2021. pp. 4513-4519.
[6] Qianhui Wu, Zijia Lin, Börje F. Karlsson, et al. UniTrans : Unifying Model Transfer and Data Transfer for Cross-Lingual Named Entity Recognition with Unlabeled Data. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3926-3932.
[7] Juntao Li, Ruidan He, Hai Ye, et al. Unsupervised Domain Adaptation of a Pretrained Cross-Lingual Language Model. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3672-3678.
[8] Mingtong Liu, Erguang Yang, Deyi Xiong, et al. Exploring Bilingual Parallel Corpora for Syntactically Controllable Paraphrase Generation. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3955-3961.
[9] Edoardo Barba, Luigi Procopio, Niccolò Campolungo, et al. MuLaN: Multilingual Label propagatioN for Word Sense Disambiguation. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3837-3844.
[10] Yuncheng Hua, Yuan-Fang Li, Gholamreza Haffari, et al. Retrieve, Program, Repeat: Complex Knowledge Base Question Answering via Alternate Meta-learning. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3679-3686.
[11] Congzheng Song, Shanghang Zhang, Najmeh Sadoughi, et al. Generalized Zero-Shot Text Classification for ICD Coding. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 4018-4024.
[12] Xin Liu, Kai Liu, Xiang Li, et al. An Iterative Multi-Source Mutual Knowledge Transfer Framework for Machine Reading Comprehension. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3794-3800.
[13] Xiaoyuan Yi, Zhenghao Liu, Wenhao Li, et al. Text Style Transfer via Learning Style Instance Supported Latent Space. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3801-3807.
[14] Zechang Li, Yuxuan Lai, Yansong Feng, et al. Domain Adaptation for Semantic Parsing. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3723-3729.
[15] Pablo Badilla, Felipe Bravo-Marquez, Jorge Pérez. WEFE: The Word Embeddings Fairness Evaluation Framework. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 430-436.
[16] Pingchuan Ma, Shuai Wang, Jin Liu. Metamorphic Testing and Certified Mitigation of Fairness Violations in NLP Models. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 458-465.
[17] Dongling Xiao, Han Zhang, Yukun Li, et al. ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3997-4003.
[18] Xin Liu, Kai Liu, Xiang Li, et al. An Iterative Multi-Source Mutual Knowledge Transfer Framework for Machine Reading Comprehension. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3794-3800.
[19] Yongrui Chen, Huiying Li, Yuncheng Hua, et al. Formal Query Building with Query Structure Prediction for Complex Question Answering over Knowledge Base. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3751-3758.
[20] Jian Liu, Yubo Chen, Jun Zhao. Knowledge Enhanced Event Causality Identification with Mention Masking Generalizations. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3608-3614.
[21] Yang Zhao, Jiajun Zhang, Yu Zhou, et al. Knowledge Graphs Enhanced Neural Machine Translation. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 4039-4045.
[22] Sixing Wu, Ying Li, Dawei Zhang, et al. TopicKA: Generating Commonsense Knowledge-Aware Dialogue Responses Towards the Recommended Topic Fact. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3766-3772.
[23] Zihao Zhu, Jing Yu, Yujing Wang, et al. Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 1097-1103.
[24] Xiaobin Tang, Jing Zhang, Bo Chen, et al. BERT-INT:A BERT-based Interaction Model For Knowledge Graph Alignment. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3174-3180.
[25] Hongming Zhang, Daniel Khashabi, Yangqiu Song, et al. TransOMCS: From Linguistic Graphs to Commonsense Knowledge. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 4004-4010.
[26] Zihao Zhu, Jing Yu, Yujing Wang, et al. Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 1097-1103.
[27] Yuncheng Hua, Yuan-Fang Li, Gholamreza Haffari, et al. Retrieve, Program, Repeat: Complex Knowledge Base Question Answering via Alternate Meta-learning. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3679-3686.
[28] Yongrui Chen, Huiying Li, Yuncheng Hua, et al. Formal Query Building with Query Structure Prediction for Complex Question Answering over Knowledge Base. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3751-3758.
[29] Jian Liu, Leyang Cui, Hanmeng Liu, et al. LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3622-3628.
[30] Jiale Han, Bo Cheng, Xu Wang. Two-Phase Hypergraph Based Reasoning with Dynamic Relations for Multi-Hop KBQA. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3615-3621.
[31] Tianyang Zhao, Zhao Yan, Yunbo Cao, et al. Asking Effective and Diverse Questions: A Machine Reading Comprehension based Framework for Joint Entity-Relation Extraction. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3948-3954.
[32] Weijing Huang, Xianfeng Liao, Zhiqiang Xie, et al. Generating Reasonable Legal Text through the Combination of Language Modeling and Question Answering. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3687-3693.
[33] Hengyi Cai, Hongshen Chen, Yonghao Song, et al. Exemplar Guided Neural Dialogue Generation. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3601-3607.
[34] Mingtong Liu, Erguang Yang, Deyi Xiong, et al. Exploring Bilingual Parallel Corpora for Syntactically Controllable Paraphrase Generation. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3955-3961.
[35] Shifeng Li, Shi Feng, Daling Wang, et al. EmoElicitor: An Open Domain Response Generation Model with User Emotional Reaction Awareness. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3637-3643.
[36] Weijing Huang, Xianfeng Liao, Zhiqiang Xie, et al. Generating Reasonable Legal Text through the Combination of Language Modeling and Question Answering. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3687-3693.
[37] Shijie Yang, Liang Li, Shuhui Wang, et al. A Structured Latent Variable Recurrent Network With Stochastic Attention For Generating Weibo Comments. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3962-3968.
[38]Dongling Xiao, Han Zhang, Yukun Li, et al. ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3997-4003.
[39] Yang Bai, Ziran Li, Ning Ding, et al. Infobox-to-text Generation with Tree-like Planning based Attention Network. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3773-3779.
[40] Yimeng Chen, Yanyan Lan, Ruinbin Xiong, et al. Evaluating Natural Language Generation via Unbalanced Optimal Transport. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 3730-3736.
[41] Zihao Zhu, Jing Yu, Yujing Wang, et al. Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 1097-1103.
[42] Xi Zhu, Zhendong Mao, Chunxiao Liu, et al. Overcoming Language Priors with Self-supervised Learning for Visual Question Answering. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 1083-1089.
[43] Ganchao Tan, Daqing Liu, Meng Wang, et al. Learning to Discretely Compose Reasoning Module Networks for Video Captioning. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 745-752.
[44] Zerun Feng, Zhimin Zeng, Caili Guo, et al. Exploiting Visual Semantic Reasoning for Video-Text Retrieval. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 1005-1011.
[45] Yubo Zhang, Hao Tan, Mohit Bansal. Diagnosing the Environment Bias in Vision-and-Language Navigation. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track. 2021. pp. 890-897.

Copyright Notice
This article is authorized to be reproduced from the WeChat public account “Beijing Zhiyuan Artificial Intelligence Research Institute”.
|
Computer Science and Technology Academic Group |
Optical Engineering and Technology Academic Group |
|
Control Science and Technology Academic Group |
Information and Communication Academic Group |
|
Power Electronics Academic Group |
Artificial Intelligence Academic Group |
This public account is the official WeChat account of the Chinese Academy of Engineering journal “Frontiers of Information and Electronic Engineering (English)” (SCI-E, EI indexed journal). Its functions include: disseminating academic articles from the journal; providing convenient services for associated scholars (readers, authors, reviewers, editors, etc.); publishing information related to academic writing, review, editing, and publishing; introducing academic figures, thoughts, and achievements in the field of information and electronic engineering, showcasing cutting-edge scientific research progress in this field; and providing a friendly interaction platform for scholars at home and abroad in this field.
