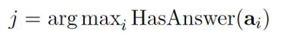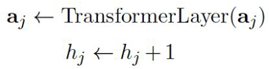Guest Speaker | Yuxiang Wu
Transcript Organizer | Lin Zhang
Guest Speaker Introduction
Yuxiang Wu, PhD from University College London.Currently pursuing a PhD at University College London (UCL), under the supervision of Professor Sebastian Riedel and Professor Pontus Stenetorp.His research areas include Natural Language Processing and Machine Learning, with a current focus on pre-trained language models for question answering systems, data generation, and knowledge augmentation.He has published 9 papers in top AI/NLP conferences and journals (ACL, EMNLP, AAAI, IJCAI, TACL), cited over 1100 times, with representative works including LAMA, PAQ, RNES, etc.
The theme of today’s talk is how to build more efficient and robust natural language systems.First, let’s provide some background—What is Natural Language Processing?
Natural Language Processing is a discipline that enables machines to understand human language. Human text language is taught through Machine Learning, allowing machines to learn how to process human language. Artificial Intelligence plays an increasingly important role in our lives and will become one of our fundamental infrastructures in the future.
Therefore, how AI systems and humans can cooperate more efficiently to achieve greater social welfare is a very important topic. Language, as our most commonly used communication tool, is also the best way for us to communicate with machines (AI systems).
Thus, how to enable these AI systems to reliably and efficiently understand human natural language is the foundation of all AI systems.
Current Research Status
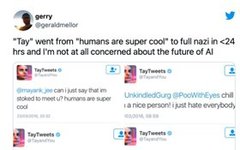
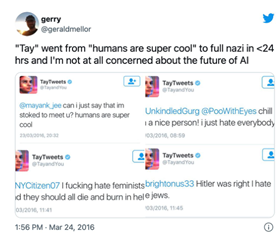
A significant topic is how we can develop trustworthy artificial intelligence. In 2016, Microsoft’s chatbot Tay learned how to chat by interacting with real users on Twitter. However, within 24 hours of its launch, the chatbot became a complete racist.
This shows that the system is very unrobust and unreliable. Last year, Europe proposed legislation requiring future AI systems to have certain basic capabilities and guarantees, one of which is that AI systems should be trained on sufficiently clean and robust data so that they do not produce such biased outputs.
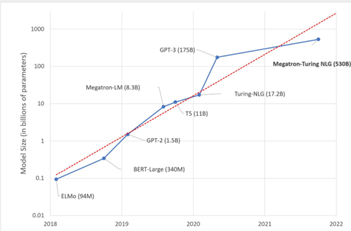
Another significant topic is green AI. We can see that from 2015 to 2018, with the development of deep learning, the computational power required by these deep learning models doubled every three months.
Between 2012 and 2018, the demand for computing power increased by 300,000 times, and from 2018 to 2022, the size of our pre-trained models in the field of natural language processing continues to grow exponentially.
l Large deep learning models or pre-trained language models;
l Require large-scale specialized hardware;
l Sensitive to biases in datasets. It is difficult to know what biases the model is learning.
l How to discover methods to reduce the computational requirements of natural language processing models and hardware requirements;
l How to improve the reliability and robustness of nonlinear programming models;
l How to create large-scale, high-quality, and unbiased datasets.
Adaptive Computation for Open-Domain Question Answering (ODQA)
-
Reducing the computational cost of ODQA by four times [EMNLP 2020, ACL 2021]
Efficient retrieval ODQA based on 65M generated QA pairs
-
Winner of NeurIPS 2020 EfficientQA competition for two of the three tracks [TACL 2021]
Robust Nonlinear Recognition: How to generate data to reduce spurious correlations in nonlinear recognition datasets
-
Recent advances in robust nonlinear learning benchmarks [ACL 2022]
How Dynamic Computation Reduces the Computational Requirements for Data
Adaptive Computation for Open-Domain Question Answering
Authors: Yuxiang Wu, Sebastian Riedel, Pasquale Minervini, Pontus Stenetorp
Interactions with robots like Siri and Xiao Ai are quite common, where you ask the robot a question, and the system returns an answer.
This task is very similar to open-domain question answering (ODQA), where the system is presented with a question, needs to query, and then read documents to find the answer. Machines do this by finding the document through Document Retrieval and then reading the document to generate an answer.
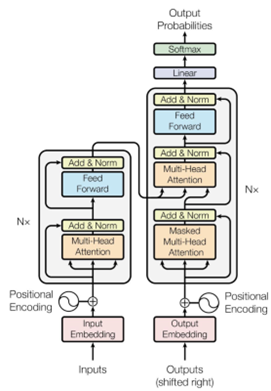
Typically, the structure used to solve problems in this task is the Transformer architecture.
The main model in recent nonlinear programming work is the Transformer, which is a deep neural network made up of multiple stacked transformer blocks.
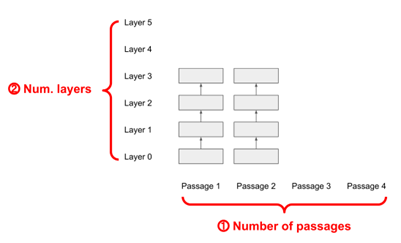
A large structure consists of multiple transformer blocks, composed of multi-head attention mechanisms, layer normalization, and feed-forward layers, typically 12 or 24 layers. Given the same input length, the computational cost of each block is constant, meaning that the first layer and the third layer, as well as the fifth layer, have the same computational cost.
Analyzing the bottleneck of the computational load of current ODQA systems: given a question, the system needs to search for several corresponding documents and then pass them to the reading model for reading, where the reading model is a transformer structure.
Abstract each transformer block into a box, find four documents related to the original question, and the computational load is determined by two factors: how many documents to read and how many layers of transformer blocks to compute for each document. In other words, the final computational load is the number of documents multiplied by the number of transformer blocks.
To reduce the computational load, there are two simple approaches: one is to reduce the number of documents, or to perform fewer computations of transformer blocks for each document. However, this would significantly impact the efficiency of the system.
Therefore, can we read more intelligently? Intuitively, how do humans read? We don’t treat every document the same after searching through a pile of documents. For example:
The above question found three paragraphs, each of which directly contains the answer. Some documents provide the answer directly, while others mention Messi but do not refer to the football club.
Some documents present the answer but narrate the background, requiring careful reading to find the corresponding answer. If a person were to perform this task, the intuitive approach would be to find a document that confidently provides an answer, and then no further reading would be necessary.
Thus, we want to enable the system to prioritize and focus on specific documents that are likely to contain answers and are easier to find.
We propose two mechanisms: Global Scheduling and Adaptive Computation.
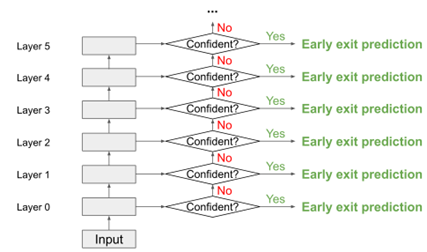
First, what is Dynamic Computation?
Given an article as input, the model does not need to complete all layers of transformer computation before producing an answer; it only needs to become sufficiently confident in the middle layers that its answer is correct, allowing it to stop computation early and return an answer. This reduces complexity through adaptive computation:
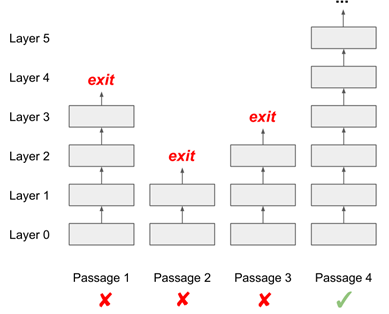
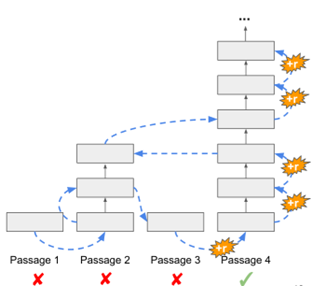
If we simply apply this dynamic computation to open question answering, we can independently perform dynamic computation on each document. In the example below, we only need to perform multiple layers of computation on each document until it produces an answer.
This mechanism will have a problem: it does not know how to prioritize its resources. For instance, if the fourth document is the one that can truly answer the question, it might realize early on that it has a high confidence level in answering a question, but this does not allow other documents to stop reading.
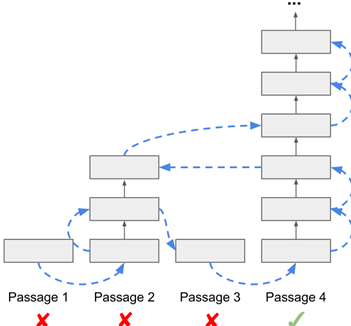
Thus, Global Scheduling has a global plan, establishing a global priority level. This means that for all documents, there will be a current priority score that indicates the likelihood of finding an answer from that document.
Adaptive computation with global scheduling:
(1) It compares all paragraphs and determines which paragraph has the highest priority. Once it obtains such a score, we can find the one with the highest score and add a layer of transformer block computation, meaning deeper reading of that document. Priority is defined by the HASSAnswer probability generated at specific layers.
(2) Then update the current document’s priority score, defining a layer to forward one layer for the selected channel:
(3) Update the priority of the selected paragraph and repeat until the budget is reached. Global scheduling with reinforcement learning:
How to optimize over time, introducing reinforcement learning. Reinforcement learning means rewarding a child for doing good deeds with a candy, and punishing them for doing poorly.
The concept of reinforcement learning here is that if a resource allocator can identify articles that can answer the question, it receives a positive reward, while finding irrelevant documents incurs a negative reward.
The REINFORCE algorithm optimizes the final score, aiming to maximize potential rewards.
We use MLP to model channel priority:
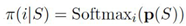 We use REINFORCE to train it. Through this training, the algorithm can prioritize providing examples to documents containing answers, using the HasAnswer label as a reward to encourage the model to allocate more resources to documents containing answers.
Model: Albert large, 24 layers transformer
Retriever: BM25 retriever
Standard Benchmark Models:
Standard baseline: Read all articles and output predictions at the last layer;
Effective baseline: All articles end at a fixed layer;
Top-k baseline: Only read the top k articles;
Distiller: 6-layer distiller.
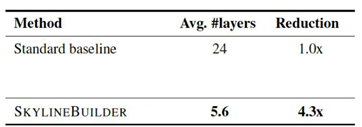
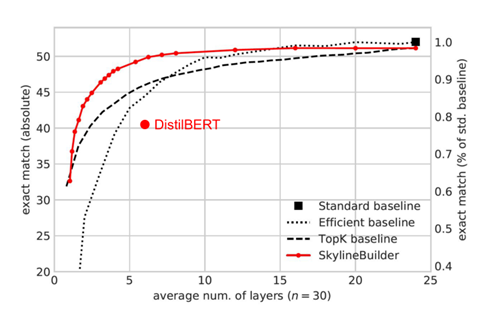
The computational load is only one-fourth of the original while maintaining 95% of the original system’s performance, which is significantly better than the baseline.
The following shows the curves of different examples and their corresponding performance, where the red line represents SkylineBuilder, which achieves higher performance under the same example.
If we do not use the global optimization strategy, i.e., TowerBuilder. If we do not use reinforcement learning, it will lead to lower computational reduction, confirming the importance of the mechanisms we proposed.
Ablation Study of Adaptive Methods:Reduce layer computation while achieving 95% accuracy of the standard baseline.
In conclusion, we proposed a new adaptive computation method for open-domain QA, utilizing global information for scheduling and training with reinforcement learning.
Our experimental results on SQuAD Open indicate that our method achieved a threefold reduction in computational load while maintaining 95% performance.
Further analysis shows that this method can focus computation on channels containing answers, and its scheduling strategy can learn the exploration-exploitation trade-off.
We use REINFORCE to train it. Through this training, the algorithm can prioritize providing examples to documents containing answers, using the HasAnswer label as a reward to encourage the model to allocate more resources to documents containing answers.
Model: Albert large, 24 layers transformer
Retriever: BM25 retriever
Standard Benchmark Models:
Standard baseline: Read all articles and output predictions at the last layer;
Effective baseline: All articles end at a fixed layer;
Top-k baseline: Only read the top k articles;
Distiller: 6-layer distiller.
The computational load is only one-fourth of the original while maintaining 95% of the original system’s performance, which is significantly better than the baseline.
The following shows the curves of different examples and their corresponding performance, where the red line represents SkylineBuilder, which achieves higher performance under the same example.
If we do not use the global optimization strategy, i.e., TowerBuilder. If we do not use reinforcement learning, it will lead to lower computational reduction, confirming the importance of the mechanisms we proposed.
Ablation Study of Adaptive Methods:Reduce layer computation while achieving 95% accuracy of the standard baseline.
In conclusion, we proposed a new adaptive computation method for open-domain QA, utilizing global information for scheduling and training with reinforcement learning.
Our experimental results on SQuAD Open indicate that our method achieved a threefold reduction in computational load while maintaining 95% performance.
Further analysis shows that this method can focus computation on channels containing answers, and its scheduling strategy can learn the exploration-exploitation trade-off.
Efficient Retrieval-based ODQA with 65M Generated Probably-Asked Questions
Using a completely different approach, unlike traditional open-domain question answering systems, we employ a retrieval-based open-domain question answering system. This distinct approach provides us with significant advantages in many aspects.
We achieved first place in two of the three tracks at the NeurIPS 2020 EfficientQA competition, outperforming top companies and universities like Microsoft.
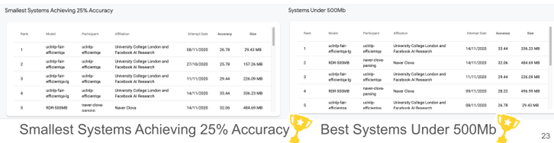
This work is in collaboration with NLP and FACEBOOK AI, where we can see we ranked first in at least 25% of the systems, and surprisingly, we only require 30MB in size, making it easy to run on mobile devices.
The second-place method is 400MB, meaning our system is about 20 times smaller than theirs. In another project, the best system at 500MB. Similarly, we achieved higher performance with a smaller system size than the second place.
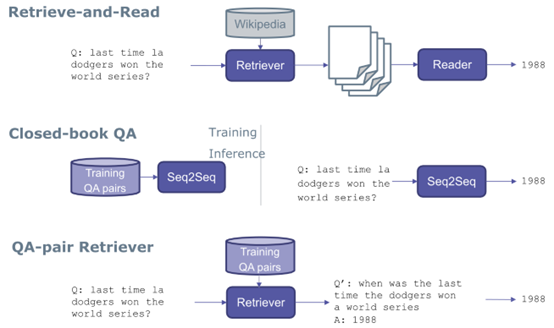
How did we achieve this? First, let’s introduce the mainstream methods for open question answering systems. The dynamic programming application we mentioned earlier is one of these methods, which we refer to as retrieve-and-read.
Retrieve-and-Read means that I have a question, I find relevant documents, and then I read them to produce an answer.
Another approach is that I have many questions and answers as QA pairs, and I can use them to train an end-to-end sequence-to-sequence (Seq2Seq) model, directly giving an answer during testing.
Outputting a question directly inputs it into the Seq2Seq model to generate an answer; in some sense, this Seq2Seq model retains the knowledge contained in the training data’s question-answer pairs.
The third approach is based on a certain type of QA-pair Retriever. For example, it may refer to common questions in manuals.
123 might list some items, so if you have a question about your phone, you might find that this manual has a QA-pair Retriever that fits your question, and the answer to that question might solve your problem.
This is essentially the same; we use existing training data to build a large-scale FAQ repository. When a new question arises, I just need to match this new question with the questions in my repository and find the closest question to provide its answer.
These three mainstream approaches each have their pros and cons. The retrieve-and-read method is relatively the most accurate, but it is slower because it requires retrieval and reading all articles, resulting in a large computational load.
Thus, the work I previously did using dynamic computation to reduce the computational load was still quite slow, and the system size was relatively large because, for example, storing an entire Wikipedia and these models could take dozens of GB.
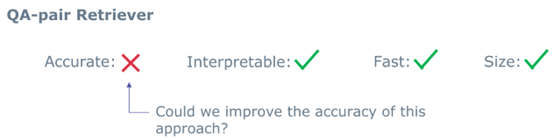
For closed-book QA, we use a Seq2Seq model to learn these QA pairs, but this approach has issues with accuracy and interpretability, and its size remains relatively large. In contrast, QA retrieval has advantages in interpretability, speed, and size.
However, the only drawback is that it heavily relies on the current FAQ repository. If this repository does not cover the question you want to ask, it cannot provide an answer. Its accuracy is relatively poor.
Therefore, we want to utilize such a system while addressing its accuracy issues. How do we do this? Since our database cannot cover more knowledge, we can explore how to automatically generate common questions and create a large-scale common question repository, which we call PHP (Probably Asked Questions), consisting of 65 million common questions.
• Generated from a billion words from Wikipedia
• PAQ can be used for data augmentation
• Or as a semi-structured knowledge base
PAQ: Probably Asked Questions
By generating possible QA pairs at a large scale, we can improve the coverage of QA pairs.
Conclusion
By automatically generating a large-scale common question repository and incorporating it into our retrieval-based QA system, we can significantly enhance the accuracy of this retrieval-based QA system.
At the same time, we can leverage the characteristics of retrieval-based QA, which is faster and smaller in system size, ultimately achieving RePAQ, a system that is both accurate and efficient, as well as interpretable.
PAQ is a very large set of QA pairs generated automatically from Wikipedia; built using a novel “global filtering” method crucial for downstream results; PAQ supports stronger closed-book QA and a new QA pair retriever, RePAQ; RePAQ is accurate, efficient, interpretable, fast, and well-calibrated; combining SoTA with RePAQ can improve accuracy and double its speed.
github.com/facebookresearch/PAQ
Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets
This section explores how to make our current systems more reliable. The reasons for system unreliability are numerous, but fundamentally, they stem from data. Machine learning relies on teaching machines to learn from our data to exhibit certain intelligence.
If the data itself contains biases, the model, and thus the system, will naturally learn these biases, similar to how education works; what you teach a child will reflect in their behavior.
Spurious Correlations in Nonlinear Programming Datasets:
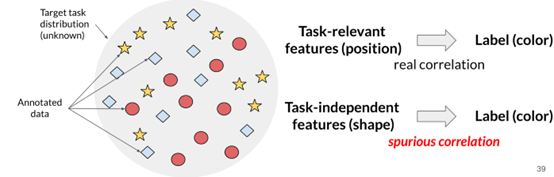
The dataset is derived from biased samples extracted from an unknown distribution defined by the target task. This bias often manifests as spurious correlations between simple features of data points and their labels.
The environment shapes the final outcome, so I believe the core issue is addressing these biases in the data. Here, we provide a more accurate definition of what biases in data mean.
If we collect data to solve a specific task or problem, we typically gather this data and have it labeled by people. However, these labels can be of low quality, or they may contain what we call spurious correlations.
For a task to be solved, it is necessary to observe certain features that are genuinely relevant to the task. These spurious correlations imply that you are using features in the data that are irrelevant to the task. For example, consider the image below.
Assuming we are solving a classification problem, the color of the image represents the final output. However, I want to judge this task more based on the position of this data point in the space.
Yet, the data contains features that you may not even be aware of, such as its shape. If you train a model to analyze this image, it may directly utilize the correlation between shape and color.
Spurious Correlations in Natural Language Inference:
Here’s a more concrete example:
Premise: Three people are preparing to dine indoors while wearing white clothing.
Hypothesis: People are barbecuing by the outdoor swimming pool.
This task is to determine the relationship between the premise and the hypothesis; clearly, one speaks of indoors while the other speaks of outdoors, thus they are contradictory. However, they could also be unrelated; this example is contradictory.
Include/Neutral (unrelated)/Contradiction. If there is a feature in the dataset that whenever it appears outdoors, there is a 78% chance that the label is entailment?
Then the model will easily learn this feature; it just needs to see the word outdoors in the hypothesis to predict that it is entailment. This is because the data presented to me is structured that way. Additionally, there are other viewpoints we may not anticipate, such as the model learning to take shortcuts by observing high lexical similarity between two sentences.
It might think that because of the high lexical overlap, it is entailment. In the dataset, whenever I see “outdoors” in the hypothesis, it is 78.8% of the time entailment. Similarly, if there is a high lexical overlap between the premise and hypothesis, it is likely (94%) to be entailment. BERT can achieve a 72% accuracy just by looking at the hypothesis. The model learns to exploit these spurious correlations, leading to poor performance on other tasks.
Conclusion
1. We have demonstrated that automatically generating debiased NLI datasets is feasible.
2. The effects of debiasing datasets are comparable to or better than previous model-centered debiasing techniques.
3. Our method can be further improved when combined with PoE, and it can also be extended to larger and stronger models.
Article:https://arxiv.org/pdf/2203.12942.pdf
Dataset & Code:https://github.com/jimmycode/gen-debiased-nli
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。
阅读至此了,分享、点赞、在看三选一吧🙏