[Smart Butterfly Guide] Natural Language Processing (NLP) is a subfield of AI that extracts structured data from unstructured text information used in everyday human communication, allowing computers to understand it. This article introduces NLP in a simple and easy-to-understand manner and implements several interesting examples using Python.
Natural Language Processing (NLP) is a subfield of artificial intelligence that focuses on enabling computers to understand and process human language. This article will introduce the basic mechanisms of how NLP works, hoping to inspire readers.
Note: The example language used in this article is English.

Since the dawn of computers, programmers have been attempting to write programs that can understand language. The reason is simple—human history with language spans thousands of years, and if computers can read and comprehend all data, it would be immensely beneficial.
Although computers cannot yet truly understand language like humans, they have made significant progress, and in certain areas, using NLP can bring about magical changes. By applying NLP technology to your own projects, you might save a lot of time.
The good news is that we can now easily access the latest achievements in the NLP field through open-source Python libraries (such as spaCy, textacy, and neuralcoref). With just a few lines of code, astonishing results can be achieved immediately.
Reading and understanding language is a very complex process—it doesn’t even judge whether such understanding is logical and consistent. For example, what does the following news headline mean?
“Environmental regulators grill business owner over illegal coal fires.” Environmental regulators are questioning the business owner about illegal coal burning. (grill: to question, to roast)
Are the regulators questioning the business owner regarding illegal coal burning, or are they cooking the business owner? As you can see, parsing language with computers complicates the issue.
In machine learning, solving complex tasks often means building a pipeline. The idea is to break the problem down into several very small parts and then use machine learning to tackle them one by one. Finally, by stitching these machine learning models together, we can accomplish complex tasks.
This is exactly the strategy we often use in NLP. We break down the process of understanding language text into several small pieces and then independently analyze their specific meanings.
Here is a passage about “London” from Wikipedia:
London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the southeast of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium. 伦敦是英格兰和英国的首府,也是英国人口最多的城市。它位于大不列颠岛东南部的泰晤士河畔,2000年来一直是这一地区的主要定居点之一。伦敦最初由罗马人建立,取名为伦蒂尼恩。
This passage contains several useful facts, and if the computer can read and understand that “London is a city,” “London is in England,” and “London was founded by the Romans,” then we would have succeeded. However, to achieve this goal, we must first teach the computer the most basic concepts of written language before seeking further development.
Step 1: Sentence Segmentation
The first step in the NLP pipeline is to segment the text into individual sentences, as follows:
-
London is the capital and most populous city of England and the United Kingdom.
-
It is located on the River Thames in the southeast of the island of Great Britain and has been a major settlement in this area for two millennia.
-
London was originally founded by the Romans and named Londinium.
We can assume that each sentence here represents an independent thought or idea, and it is indeed much easier to write a program to understand individual sentences than to understand the entire paragraph.
As for building a sentence segmentation model, it is not difficult; we can determine each sentence based on punctuation. Of course, modern NLP typically uses more complex techniques, which can still roughly distinguish complete sentences even if the document content is messy.
Step 2: Word Tokenization
Now that we have split the sentences, we can process them one by one. Let’s start with the first sentence:
London is the capital and most populous city of England and the United Kingdom.
The goal of this step is to split the sentence into individual words or punctuation marks. After splitting, the entire sentence becomes:
“London”, “is”, “the”, “capital”, “and”, “most”, “populous”, “city”, “of”, “England”, “and”, “the”, “United”, “Kingdom”, “.”
In English, there are natural delimiters—spaces—so generating tokens is very convenient. As long as there is a space between two tokens, we can split them directly. Since punctuation also has meaning, we treat them as separate tokens.
Step 3: Predicting Word Part-of-Speech
Next, we focus on the part of speech of each token: noun, verb, adjective… Knowing the role of each word in the sentence helps us understand what the sentence is saying.
To achieve this, we can pre-train a part-of-speech classification model and then input each word to predict its part of speech:

This model was initially trained on millions of English sentences, where each word’s part of speech was already labeled in the dataset, allowing it to learn this “definition” process. However, note that this model is entirely based on statistical data—it cannot truly understand the meaning of words like humans but can only guess based on “similar sentences” it has seen.
After processing the complete sentence, we get the following result:

With this information, we can start collecting some very basic meanings, such as the nouns in the sentence include “London” and “capital,” so this sentence is likely talking about London.
Step 4: Text Lemmatization
In English, words have different forms, for example:
-
I had a pony.
-
I had two ponies.
Both sentences involve the noun “pony,” but one is in singular form and the other in plural form. When the computer processes text, if not specified, it will treat “pony” and “ponies” as completely different objects. Therefore, understanding the basic form of each word is very helpful; only in this way can the computer know that both sentences are talking about the same concept.
In NLP, we refer to this process of reducing any form of a word to its base form as lemmatization, which identifies the most basic form of each word in the sentence.
Similarly, this also applies to English verbs. We can use lemmatization to find the root of words; after that, “I had two ponies” becomes “I [have] two [pony].”
Lemmatization is achieved by looking up vocabulary generation tables, and it may also have some custom rules to handle words that people have never seen before.
Here is an example after lemmatization; the only change we made is turning “is” into “be”:

Step 5: Identifying Stop Words
The next step is to measure the importance of each word in the sentence. English has many filler words, such as the frequently occurring “and,” “the,” and “a.” When performing statistical analysis on text, these words introduce a lot of noise due to their high frequency. Some NLP pipelines will label them as stop words—meaning that we might want to filter these words out before doing any statistical analysis.
Here is an example with stop words highlighted in gray:

Stop word detection also has a pre-prepared list, but it differs from lemmatization; we do not have a standard stop word list suitable for every problem; it needs to be analyzed case by case. For example, if we are building a search engine about rock bands, the word “The” must not be ignored, as it appears in many band names; there was a famous band in the 1980s called “The The.”
Step 6 (a): Dependency Parsing
The next step is to figure out how all the words in the sentence are related to each other, which is dependency parsing.
Our goal is to build a dependency tree, where the root of the tree is the dominant main verb, referred to as the head word, and the dependent words are the modifiers:
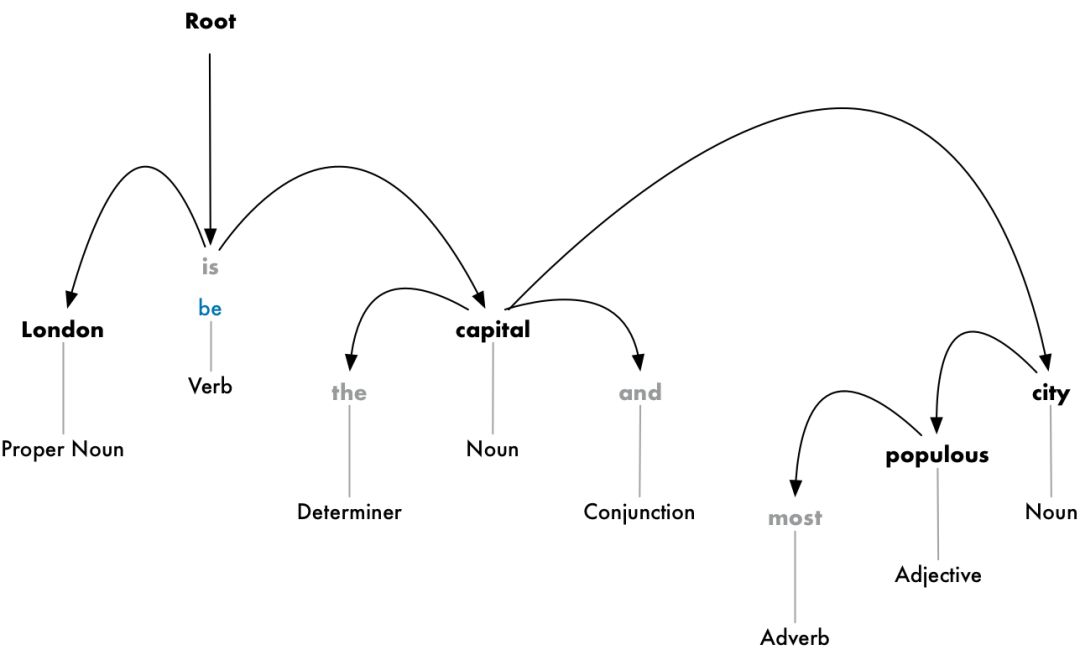
But we can go further. In addition to identifying the head word of each token, we can also predict the type of dependency relationship between the two words:
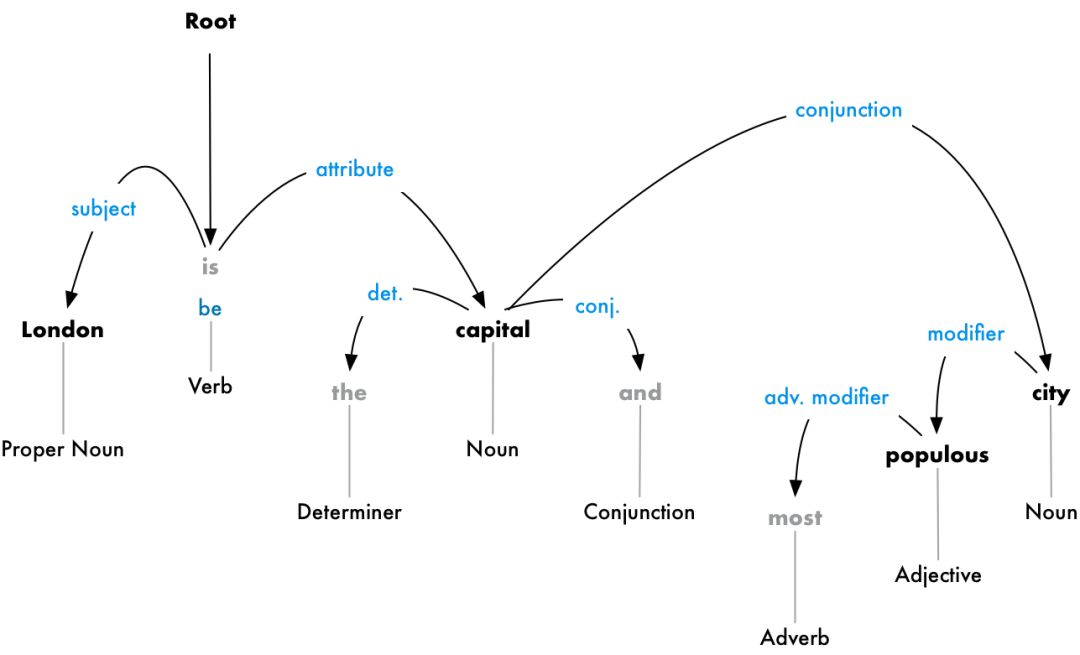
This dependency tree tells us that the subject of the sentence is “London,” and it has a “be” relationship with “capital.” Based on this, we get useful information—London is a capital. On this basis, if we continue to look further, we can find that London is the capital of the United Kingdom.
Just like we used a machine learning model to predict part of speech, dependency parsing can also be achieved with a model. The difference is that parsing word dependencies is particularly complex and requires a detailed explanation of the entire text. If you are interested, Matthew Honnibal’s tutorial “Parsing English with 500 Lines of Python Code” is a good resource.
Although the author stated in 2015 that this method had become standard, it seems a bit outdated now, and many researchers no longer use it. In 2016, Google released a new dependency parser called Parsey McParseface, which is based on deep learning and significantly outperforms existing benchmarks, thus gaining widespread popularity upon release. A year later, they released an updated version, ParseySaurus, which further improved performance. In short, dependency parsing is still an active research area and is constantly changing and evolving.
Moreover, many English sentences have ambiguous meanings, which are often difficult to parse. In these cases, the model will guess the most likely option based on various parsing versions of the sentence, but it is not perfect, and sometimes the model makes awkward mistakes. However, over time, our NLP models will gradually become more reasonable.
Step 6 (b): Finding Noun Phrases
So far, we have treated each word in the sentence as a separate entity, but sometimes, combining words that represent a single idea or thing can be more meaningful. Using the dependency tree, we can automatically consolidate information and group words that discuss the same thing together.
Instead of the following format:

We can group noun phrases to generate:

Whether to take this step depends on our ultimate goal. However, if we do not need to understand additional details of the sentence, such as which words are adjectives, but rather focus more on extracting complete ideas, then this is often a convenient way to simplify sentences.
Step 7: Named Entity Recognition (NER)
After completing the above steps, we can move beyond basic grammar and begin to extract meaning.
In the example sentence, we have the following nouns:

These nouns include some real-world entities, such as “London,” “England,” and “United Kingdom,” which represent geographical locations on the map. With this information, we can use NLP to automatically extract a list of real-world locations mentioned in the document.
The goal of Named Entity Recognition (NER) is to detect these words that represent real-world entities and label them. The following image shows the changes in the example sentence after inputting the tokens into the NER model:

Although it may not be visually obvious, NER is by no means a simple dictionary lookup and labeling; it involves a statistical model of a word’s position in context, which can predict what type of noun each word represents. For example, a good NER model can differentiate whether “Brooklyn” refers to the person Brooklyn Decker or the place Brooklyn.
Here are some objects that a typical NER system can label:
-
People’s names
-
Company names
-
Geographical locations (geopolitical)
-
Product names
-
Dates and times
-
Amounts
-
Event names
NER has many applications as it can easily extract structured data from text, making it one of the simplest ways to obtain valuable information from an NLP pipeline.
Step 8: Coreference Resolution
So far, we have many useful representations related to the sentence. We know the part of speech of each word, the dependency relationships between words, and which words represent named entities.
However, we still have a tricky problem, which is that English contains a large number of pronouns, such as “he,” “she,” and “it,” which frequently appear in sentences and are used as abbreviations to avoid repeating a specific name. Humans can understand the meaning of these pronouns based on context, but NLP models cannot, as they have only been detecting one sentence at a time up to this point.
Let’s look at the third sentence of the example:
“It was founded by the Romans, who named it Londinium.”
According to the NLP pipeline, our model only knows that “it” was made by the Romans but does not yet know what “it” is. However, this question should not be difficult for anyone able to read this passage; we know that the “it” here refers to “London” from the first sentence.
Here are the results of running coreference resolution for the word “London” in our document:

By combining coreference resolution with dependency trees and named entity information, we can extract a wealth of information from this document! In fact, this is also a major challenge in the NLP field today, and its difficulty is far greater than parsing single sentences. Although some breakthroughs have been made in recent years based on deep learning advancements, they are not perfect.
The above is some basic knowledge about NLP. If you are interested in this content, we will discuss more about NLP in the future, such as text classification, intelligent assistant parsing questions, and other specific applications.
The following image is an overview of the complete NLP pipeline:

Coreference resolution is an optional step.
First, assume you have installed Python 3, then use the following code to install spaCy:
# Install spaCy pip3 install -U spacy# Download the large English model for spaCypython3 -m spacy download en_core_web_lg# Install textacy which will also be usefulpip3 install -U textacy
Then write the following code to run the NLP pipeline:
import spacy# Load the large English NLP modelnlp = spacy.load(‘en_core_web_lg’)# The text we want to examinetext = ”’London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the southeast of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.”’# Parse the text with spaCy. This runs the entire pipeline.doc = nlp(text)# ‘doc’ now contains a parsed version of text. We can use it to do anything we want!# For example, this will print out all the named entities that were detected:for entity in doc.ents: print(f’{entity.text} ({entity.label_})’)
After running, you will get a list of named entities detected from the document along with their entity types:
London (GPE) England (GPE) the United Kingdom (GPE) the River Thames (FAC) Great Britain (GPE) London (GPE) two millennia (DATE) Romans (NORP) Londinium (PERSON)
It is worth noting that an error appeared on “Londinium,” which was identified as a person’s name rather than a place. This may be because there was nothing similar in the training dataset, and it made the best guess. Named Entity Detection often requires some model fine-tuning.
Here, let’s consider detecting entities and reversing them to build a data scrubber. Manually editing names in thousands of documents could take years, but for NLP, it’s a piece of cake. Below is a simple data scrubber that can remove all detected names:
import spacy# Load the large English NLP modelnlp = spacy.load(‘en_core_web_lg’)# Replace a token with ‘REDACTED’ if it is a namedef replace_name_with_placeholder(token): if token.ent_iob != 0 and token.ent_type_ == ‘PERSON’: return ‘[REDACTED] ‘ else: return token.string# Loop through all the entities in a document and check if they are namesdef scrub(text): doc = nlp(text) for ent in doc.ents: ent.merge() tokens = map(replace_name_with_placeholder, doc) return ”.join(tokens)s = ”’In 1950, Alan Turing published his famous article ‘Computing Machinery and Intelligence’. In 1957, Noam Chomsky’s Syntactic Structures revolutionized Linguistics with ‘universal grammar’, a rule based system of syntactic structures.”’print(scrub(s))
The output is as follows:
In 1950, [REDACTED] published his famous article ‘Computing Machinery and Intelligence’. In 1957, [REDACTED] Syntactic Structures revolutionized Linguistics with ‘universal grammar’, a rule based system of syntactic structures.
There is a Python library called textacy that implements several common data extraction algorithms based on spaCy. One of the algorithms it implements is called Semi-structured Statement Extraction. We can use it to search the parse tree for simple statements where the subject is “London” and the verb is some form of “be.” This helps us find facts about London. As follows:
import spacyimport textacy.extract# Load the large English NLP modelnlp = spacy.load(‘en_core_web_lg’)# The text we want to examinetext = ”’London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the southeast of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.”’# Parse the document with spaCydoc = nlp(text)# Extract semi-structured statementsstatements = textacy.extract.semistructured_statements(doc, ‘London’)# Print the resultsprint(‘Here are the things I know about London:’)for statement in statements: subject, verb, fact = statement print(f’ – {fact}‘)
The output is as follows:
Here are the things I know about London: – the capital and most populous city of England and the United Kingdom.- a major settlement for two millennia.
This may seem simple, but if you run the same code on the entire Wikipedia article about London (instead of just three sentences), you will get impressive results, as follows:
Here are the things I know about London: – the capital and most populous city of England and the United Kingdom – a major settlement for two millennia – the world‘s most populous city from around 1831 to 1925 – beyond all comparison the largest town in England – still very compact – the world’s largest city from about 1831 to 1925 – the seat of the Government of the United Kingdom – vulnerable to flooding – ‘one of the World’s Greenest Cities’ with more than 40 percent green space or open water – the most populous city and metropolitan area of the European Union and the second most populous in Europe – the 19th largest city and the 18th largest metropolitan region in the world – Christian, and has a large number of churches, particularly in the City of London – also home to sizeable Muslim, Hindu, Sikh, and Jewish communities – also home to 42 Hindu temples – the world‘s most expensive office market for the last three years according to world property journal (2015) report – one of the pre-eminent financial centres of the world as the most important location for international finance – the world top city destination as ranked by TripAdvisor users – a major international air transport hub with the busiest city airspace in the world – the centre of the National Rail network, with 70 percent of rail journeys starting or ending in London – a major global centre of higher education teaching and research and has the largest concentration of higher education institutes in Europe – home to designers Vivienne Westwood, Galliano, Stella McCartney, Manolo Blahnik, and Jimmy Choo, among others – the setting for many works of literature – a major centre for television production, with studios including BBC Television Centre, The Fountain Studios and The London Studios – also a centre for urban music – the ‘greenest city’ in Europe with 35,000 acres of public parks, woodlands and gardens – not the capital of England, as England does not have its own government
By referring to the spaCy documentation and textacy documentation, you will find a plethora of examples using parsed text. Next, let’s look at another example: Suppose you are building a website, and if your website has a search bar, you would certainly want to autocomplete common search queries like Google does, as shown in the image below:
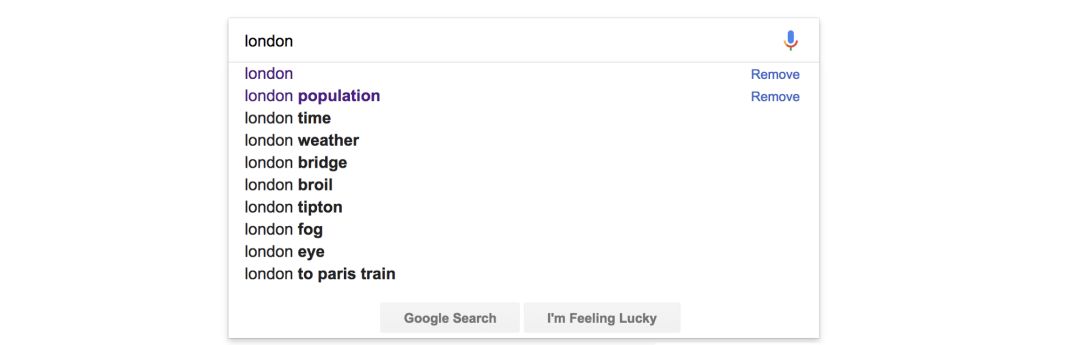
Google’s autocomplete for the text query “London”
To achieve this, we need a list to provide suggestions to users. We can use NLP to quickly generate this data. Below is a method to extract frequently mentioned noun chunks from the document:
import spacyimport textacy.extract# Load the large English NLP modelnlp = spacy.load(‘en_core_web_lg’)# The text we want to examinetext = ”’London is [.. shortened for space ..]”’# Parse the document with spaCydoc = nlp(text)# Extract noun chunks that appearnoun_chunks = textacy.extract.noun_chunks(doc, min_freq=3)# Convert noun chunks to lowercase stringsnoun_chunks = map(str, noun_chunks)noun_chunks = map(str.lower, noun_chunks)# Print out any nouns that are at least 2 words longfor noun_chunk in set(noun_chunks): if len(noun_chunk.split(‘ ‘)) > 1: print(noun_chunk)
If you run this code on the Wikipedia page about London, you will get results like:
westminster abbey natural history museum west end east end st paul‘s cathedral royal albert hall london underground great fire british museum london eye…. etc ….