
Author: Dr. Zhang Junlin, Senior Algorithm Expert at Sina Weibo
Zhihu Column:Notes on the Frontiers of Deep Learning
This article has been authorized, you can click “Read the original” at the end of the article to go directly:
https://zhuanlan.zhihu.com/p/65470719
In the past two months, I have been paying close attention to the current application status of BERT in various fields, as well as the problems existing in BERT and their corresponding solutions. Therefore, I have collected a lot of related papers, and I am sorting out these two questions and forming two articles. This part of the content was originally part of the first article “Application Part”, but later I found that the article was too long, so I separated it from the article introducing the current state of BERT applications. This part involves relatively few specific technologies and is more abstract, so I extracted it separately, and the theme is also relatively scattered. What I discuss here is purely personal thought, with limited perspective, and mistakes are inevitable, so please refer to it cautiously.
Choosing Between Fish and Bear’s Paw: Comparison and Selection of BERT Application Models
We know that the natural language pre-training models ELMO, GPT, and BERT provide directional guidance for NLP. Generally, when applying these pre-trained models, a two-stage strategy is adopted: First, use a general language model task and self-supervised learning methods to select a specific feature extractor to learn the pre-trained model; the second stage is to address the specific supervised learning task at hand, adopting feature integration or fine-tuning application modes, clearly expressing what you want BERT to do, and then you can efficiently solve the problems and tasks at hand.
Such is the large application framework of BERT, but there are actually several unresolved application model issues that have not been thoroughly discussed, such as the following two questions. Understanding these questions is actually very important because it provides clear guidance for subsequent BERT applications in the field. What are the two questions?
Question 1: When downstream tasks utilize pre-trained models, there are two possible choices: Feature Ensemble or Fine-tuning mode. So for BERT applications, which of these two modes has better application results? Or do both modes yield similar results? This is one question, and if there is a clear answer to this question, then when applying it, one can directly choose the better scheme.
We know that ELMO uses feature integration when applying pre-trained models for downstream tasks: this means that the input sentence to be judged passes through the pre-trained double-layer bidirectional LSTM network of ELMO, and then the high-level LSTM activation embedding corresponding to each input word’s position (or a weighted sum of several layers of embeddings at the corresponding position of the input word) is used as the input corresponding to the downstream task’s words. This is a typical method of applying pre-trained models, focusing more on the contextual feature representation of words.
GPT and BERT, on the other hand, adopt another application mode: Fine-tuning. This means that after obtaining the pre-trained model and the corresponding network structure (Transformer), the second stage still uses the same network structure as the pre-training process, taking some training data from the task at hand and directly training the model on this network to specifically adjust the network parameters obtained during the pre-training phase, which is generally referred to as Fine-tuning. This is another typical application mode.
Of course, in practical applications, as long as a pre-trained model is available, the application mode is optional. In fact, ELMO can also be modified to a Fine-tuning mode, and GPT and BERT can also be modified to a feature integration application mode. So, is there a difference in effectiveness between these two application modes?
There is a paper that specifically discusses this issue, titled: “To Tune or Not to Tune? Adapting Pre-trained Representations to Diverse Tasks.” This paper is quite interesting, and students with time can take a closer look.
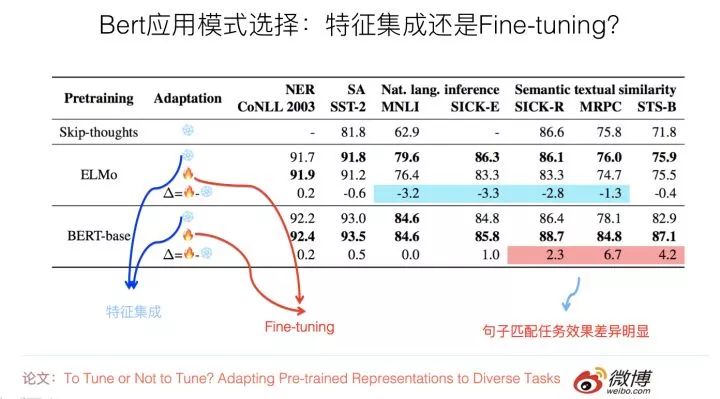
The purpose of this paper is to compare the differences between the two application modes of ELMO and BERT, hoping to conclude which mode is more suitable for downstream tasks. It uses seven different NLP tasks for evaluation, and if we summarize the experimental results (refer to the above figure), the conclusions of this issue are as follows: For ELMO, the feature integration application method stably outperforms Fine-tuning across different datasets; whereas for BERT, the conclusion is exactly the opposite: the performance of the Fine-tuning application mode is comparable to or slightly better than that of the feature integration mode in most tasks, but for tasks involving sentence pair matching, the Fine-tuning effect is significantly better than that of the feature integration method. This may be because BERT’s pre-training process includes the Next Sentence Prediction task, which considers inter-sentence relationships, making it more aligned with downstream sentence pair tasks.
Another piece of evidence comes from a recent paper from Tsinghua University (Understanding the Behaviors of BERT in Ranking). Although its theme is not specifically to discuss the above issues, it has some related experiments that can illustrate the problem to some extent, so I will list the conclusions of that paper here. Its conclusion is: For tasks like QA that involve sentence matching, if BERT is only used as a feature representation tool, meaning that BERT’s input side only inputs the Question or the Passage separately, and extracts the high-level [CLS] token from BERT as the semantic representation of the Question or Passage, this application method performs far worse than inputting both the Question and Passage into BERT simultaneously, allowing the Transformer to perform the matching process between the Question and Passage itself. The application effect will be better, and the difference between the two is significant. This indirectly indicates that in QA tasks, the Fine-tuning mode is far better than the feature integration mode.
This somewhat indicates that at least for sentence matching tasks, the Fine-tuning application mode is far superior to the feature integration representation application mode. Of course, since there have not been many works comparing the two modes, the cautious approach is to limit this conclusion to sentence pair matching tasks; there is currently no particularly clear conclusion for other non-sentence pair matching tasks, which is worth exploring further through more experiments.
BERT’s original paper also briefly compared the two modes; my impression is that the Fine-tuning mode is slightly better than the feature integration mode.
In summary of the above three works, I believe the current conclusion we can draw is: For sentence matching tasks, or NLP tasks where the input consists of multiple different components, when applying BERT, using Fine-tuning is significantly better than the feature integration mode. Therefore, when encountering such types of tasks, you do not need to hesitate; directly using Fine-tuning is generally safe. For other types of tasks, when applying BERT, the Fine-tuning mode is slightly better than the feature integration mode, or the effects of both are similar.
To put it more concisely, the conclusion is: For BERT applications, a safe and reliable approach is to recommend adopting the Fine-tuning mode rather than the feature integration mode.
Question 2: Assuming we have chosen the Fine-tuning application mode, during the standard BERT Fine-tuning process or inference in applications, generally speaking, the input information for the classification layer comes from the highest layer output of BERT’s Transformer feature extractor. We know that the Transformer Base version has 12 layers, and one intuitive and meaningful idea is that perhaps not only the highest layer of the Transformer contains effective classification feature information, but the 11 lower intermediate layers of the Transformer may also encode features of the input sentences at different levels of abstraction. Therefore, if we integrate the response values of the multi-layer intermediate layers of the Transformer corresponding to each word before classification, and based on these integrated features, connect to the classification layer, intuitively it seems effective, as it feels like the information is richer after incorporating multi-layer features.
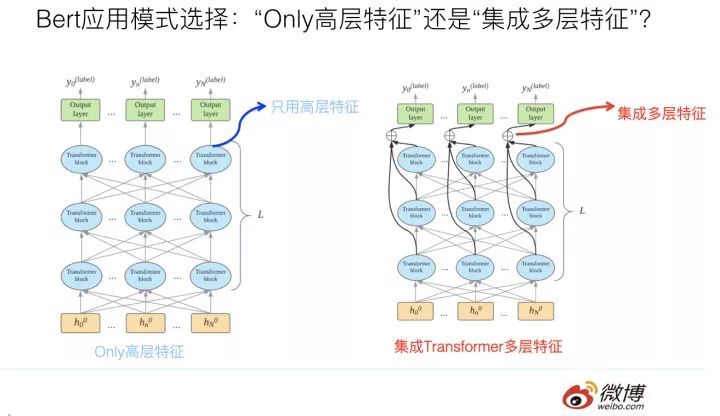
So what is the reality? How does this mode of integrating multi-layer features compare to the mode of using only the highest layer features of the Transformer? This question is also quite interesting.
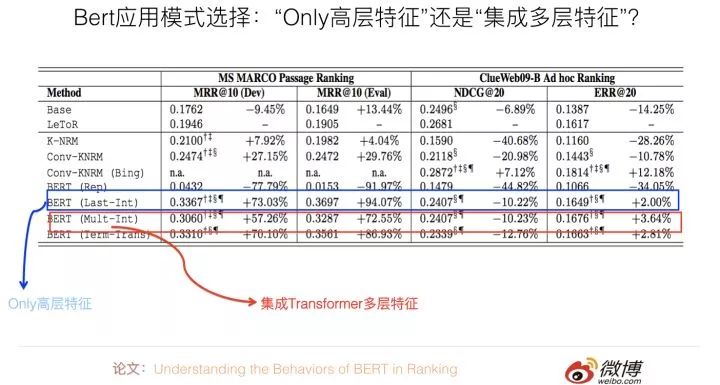
The Tsinghua University paper: Understanding the Behaviors of BERT in Ranking can actually be used to answer the above question. It adopts several different feature integration methods before the classification layer and compares the performance differences in QA tasks. If we summarize, the conclusion is as follows: Directly using the highest layer Transformer embedding corresponding to the first starting token [CLS] as the input to the classification layer, serving as the text matching feature representation, is both simple and effective. Other comparison schemes, including integrating the embeddings of various words from the highest layer of the Transformer, or integrating the response values from different layers of the Transformer, or more complex schemes, do not perform as well as this simplest scheme (refer to the above figure, where the only high-level features clearly outperform the others in one dataset, while in another dataset, the two effects are similar). I believe this indicates that for sentence pair matching tasks, this [CLS] token has already encoded enough feature information needed for sentence matching, so no additional features are needed for supplementation.
Of course, the conclusions of the above experimental results are still limited to QA tasks; I estimate that they can at most extend to sentence pair matching tasks. As for other types of NLP tasks, such as single sentence classification or sequence labeling tasks, additional evidence is needed to clarify or analyze comparisons.
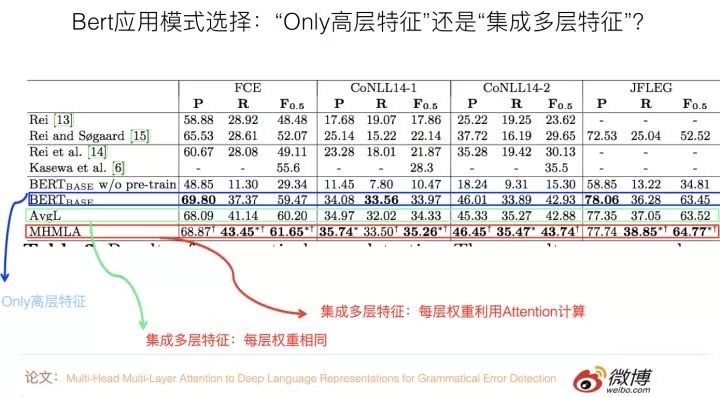
Regarding sequence labeling tasks, there is a paper: “Multi-Head Multi-Layer Attention to Deep Language Representations for Grammatical Error Detection” that is used to verify the different effects of these two modes. It focuses on grammatical error detection tasks, which is a type of sequence labeling task, meaning that each input word needs to correspond to a classification result output. The experimental results it presents prove that in this task, the specific way of integrating multi-layer features affects the results. If, when integrating features from each layer, the importance of each layer’s features is considered the same (averaged), then the effect is similar to that of using only the highest layer features, with no significant difference in performance across different datasets. However, if attention is used to adaptively learn the weights of each layer’s features, then the effect is consistently better than the mode of using only high-level features. This indicates that in sequence labeling tasks, it tends to choose the multi-layer feature integration application mode.
Last year when we used BERT to improve the tagging of Weibo (text classification task), we also attempted to integrate features from different layers, and at that time, the F1 score for application effectiveness improved by about 2 percentage points (relative to using only the highest layer features of BERT). However, apart from that, I have not seen other published works explaining this issue.
Therefore, I think the current conclusion about this question seems to be: For sentence matching and other multi-input NLP tasks, directly using the high-level [CLS] token of BERT as the basis for output information is the best and simplest mode. For sequence labeling tasks, multi-layer feature integration may be more suitable for application scenarios, but when integrating features from each layer, it should be done more carefully. For single sentence classification and other tasks, since there is no more work or experiments to clarify this issue, a clear conclusion has not yet been reached; this area still requires further verification work. My intuition is that this may be related to the type of task, and different types of tasks may yield different conclusions, possibly due to deeper reasons at play.
Predicaments and Hopes: What Has BERT Really Brought to the NLP Field?
Undoubtedly, BERT is a significant technological advancement in the NLP field. In my view, the importance of BERT may be even greater than the progress of introducing deep learning into the NLP field, because when deep learning was first introduced to NLP, frankly speaking, its performance did not show a significant advantage compared to traditional models. However, the performance of BERT is unexpectedly good; it can completely be compared to the skip connection represented by ResNet in the CV field, representing two shining stars of deep learning in two different domains.
Although I will mention it later, here I can summarize it in one sentence: From the application effects across various fields of NLP, it can be seen that after using BERT, in many areas, metrics generally show varying degrees of growth; in different fields, the situation varies, with some areas showing substantial growth and many fields experiencing a 30% or even 100% increase. These facts present themselves, indicating that BERT’s technological breakthrough has brought great hope for NLP research and application, while also pointing out the direction for development: that is, through the pre-training model, fully utilizing a large amount of unlabeled language data, leveraging the strong feature absorption capability of self-supervised models, to encode language knowledge as features. Using this knowledge to promote the effectiveness of many downstream NLP tasks compensates for the shortcomings of supervised tasks, which often lack sufficient training data to fully encode language knowledge.
Since the future looks so bright, we can completely focus on hope and direction, seemingly there is nothing to discuss about the so-called “predicaments.” However, this is not the case; everything in the world is created by humans. If our object of thought is the researchers within it, then for many people in the field, there are obvious predicaments or troubles. This reflects another kind of gap between ideals and reality. How far is this distance? I believe that those with a certain life experience understand the answer: it is as far as the distance between the sky and the sea. To someone standing by the sea, looking far away seems infinitely close, while up close, it feels infinitely far away. Just like each of us hopes to live out a “beautiful appearance and an interesting soul,” but as we live, under the gravitational pressure of life, we may end up with an “interesting appearance and a beautiful soul,” or even, we may not even retain a beautiful soul.
Recently, I have been feeling a bit sentimental, and I digressed, so let’s return.
So what are the troubles brought by the emergence of BERT for many people in the field?
Now, there is plenty of evidence that directly applying BERT often leads to a significant increase in metrics for many tasks. Before BERT was introduced, I believe many people were racking their brains trying various different NLP improvement methods; perhaps their ideas varied, but a method that could lead to such a high degree of improvement in applications like BERT did, I believe there should be fundamentally no such method. Otherwise, aside from BERT, we should have seen another new model launched by the “Model Shock Department,” but the stark reality is that there isn’t, so my hypothesis seems to be quite valid.
Following this hypothesis, what does it imply? It indicates that a large number of NLP papers that were in gestation, just born, or even just conceived, have lost the necessity to be published due to the emergence of BERT. “There has always been a new person laughing, but who remembers the old person crying.” When I first saw the BERT paper, I seemed to hear many helpless and bitter laughs, and this laughter should come from the inventors of these technological innovations.
From another perspective, the emergence of BERT has rapidly raised the benchmarks or comparative baselines in many NLP application fields, which raises a real issue for many NLP researchers, especially graduate students who are eager to publish papers. What issue? It is that under the pressure of a drastically raised baseline method overnight, if they do not innovate methods based on BERT, the probability of proposing a new method that outperforms BERT is very low. This means that with BERT, the difficulty of innovation has greatly increased. This is not a problem for application personnel, but for those who are required to innovate, the threshold has been raised.
You may ask: Why has the original method failed when using BERT as a reference? Can’t I still apply my original ideas to innovate based on BERT? Of course, some ideas may have a chance of success regardless of external influences, but for the vast majority of methods, I believe this route is not feasible. Why? Because the slight benefits produced by your method that you have been working on for half a year are likely to have been covered or consumed by the benefits brought by BERT itself. This means that without BERT, your improvement might seem somewhat effective, but you want to overlay it onto BERT, hoping to reap the technical dividends brought by BERT while also showcasing the advantages of your method; the probability of achieving this good intention is very low. If you are still optimistic about this issue, then I think you should set an alarm clock to wake yourself up early. Upon seeing this, do you realize the distance between the ideals and reality I mentioned above?
However, on the other hand, the increased difficulty of innovation depends on how you view this issue. In fact, from the perspective of long-term development of the field, it is beneficial. The benefit is that, not limited to the NLP field, more than 98% of the so-called innovations in most AI fields, if we look at the long term, have little value. How to judge? Innovations that will not be mentioned in a few years belong to this category. If this hypothesis holds, then the emergence of BERT will force practitioners not to waste time on ideas that do not have much long-term value in the field, and compel you to address truly valuable problems. When there was no BERT, it was only possible to rely on self-awareness or research taste to achieve this; with BERT, you have no choice but to do so. From this perspective, the emergence of a breakthrough model has a very positive effect on optimizing the allocation of human resources in the field. Therefore, many things depend on the perspective you take; different perspectives may lead to opposite conclusions.
However, I think that apart from the differing conclusions drawn from various observational perspectives, BERT may indeed have a drawback: many very new ideas, when first proposed, may not achieve the crushing effects similar to BERT, or even the effects may not be very noticeable, needing subsequent improvements to realize their effectiveness. However, faced with the high baseline set by BERT, many potentially high-potential ideas may never see the light of day. This means that the high wall of BERT may obscure the sunlight of many low-hanging fruits, causing them to wither before they even grow.
Another fact that can easily lead to frustration is: the emergence of BERT indicates that using a heavy model like Transformer and leveraging almost infinite natural language text resources for self-supervised training appears to be a viable path, and this is a broad avenue leading to the peak of NLP. However, the complexity of the model combined with excessive data also implies that if we want to continue along this path, the resource consumption during the pre-training phase will be extremely high. This money game is not something that ordinary NLP practitioners like you and I can afford. It’s like this: to draw an analogy, the superheroes in Marvel movies are all extraordinarily capable, but if we delve into the source of their superpowers, it becomes a class issue. The saying goes, “The rich rely on technology, while the poor rely on mutation,” which resonates deeply. In the era of BERT, that translates to “The rich rely on machines, while the poor rely on luck.” Please check your bank balance and see where you stand.
However, on the other hand, some things should just be accepted as facts; don’t overthink them. Overthinking yields nothing but frustration. Although life is often filled with helplessness, we must always maintain the innocence of a child. After all, while we feel helpless… we gradually get used to it…
Where Do We Go From Here: Possible NLP Innovation Paths in the BERT Era
Since we have discussed possible predicaments and hopes, let’s delve deeper: What innovation paths can those required to innovate choose in the BERT era? This question is actually quite important.
In my opinion, there are several paths that can be taken in the future, each with different levels of difficulty. I will list them, and you can evaluate how you plan to proceed. Once again, this is purely personal opinion, so please refer to it cautiously.
The first path is a broad avenue. That is to say, propose a new model or method that is comparable to or better than BERT without relying on it at all. This is undoubtedly a golden path, but how likely is it to succeed? You can evaluate it yourself. Of course, I personally strongly support comrades who have no short-term pressures, whether it be pressure to achieve innovation results or economic pressure, to take this path. I also express my respect for those who can choose to walk this path; it is quite challenging, and I believe that some will steadfastly choose this path.
This path is determined by the depth of understanding of the field; speed is not critical.
The second path is to utilize the BERT pre-trained model directly for various applications to empirically demonstrate BERT’s effectiveness in various fields. Of course, when applying BERT, there may be some model modifications to adapt to the characteristics of the field, but undoubtedly, such improvements will not be significant. This is a relatively easy path, and naturally, many people will walk this path, so this path is a race against speed. Currently, a large number of follow-up works on BERT belong to this category, which is quite normal. The subsequent application articles will summarize this type of work.
The third path is to conduct various experimental studies to gain a deeper understanding of BERT’s characteristics. In fact, we currently do not have a profound understanding of BERT and Transformer, and we urgently need to achieve this. If we can deepen our understanding of them, that is also very valuable, as it will make further significant improvements to BERT more targeted. Moreover, only by understanding the essential characteristics of BERT can we potentially throw BERT aside and propose a better new model. This path is not particularly difficult, but it seems that not many people are pursuing it. I suggest that interested students consider this path more.
The fourth path is to directly improve the BERT model. This involves optimizing it for the areas where BERT currently falls short or transforming it to make it applicable to a wider range of applications. This path is pragmatic and has the potential to yield significant innovations. Many follow-up works on BERT are also focused here. The difficulty of innovation in this area varies greatly; some may be quite conventional, while others may require clever ideas. Currently, this area of work is relatively abundant, and the subsequent “BERT Improvement” article will mainly focus on this.
The fifth path is to come up with improvements that seem unrelated to BERT but are based on it, hoping that new technologies will still be effective after being added to BERT. That is, their technical dividends and BERT’s technical dividends do not overlap; this is also a good path and should be feasible, although it is certainly not easy.
The sixth path is to identify tasks or application areas where BERT does not perform well, meaning that BERT’s strengths cannot be leveraged in these areas. Since BERT cannot penetrate these areas, there is no obstruction or impact on conventional technological innovation. If you choose this path, your primary task is to identify these areas. Moreover, within these areas, referencing the fundamental ideas of BERT can likely lead to significant improvements in models.
Are there any other possible paths? It seems there are not many left. Well, the paths above include both easy and thorny options; you can choose one of the possible options and then walk confidently down that path. Good luck.