
0 Introduction
With the widespread adoption of large-scale machine learning, the emergence of ultra-large deep learning models, and the rapid development of distributed learning methods such as federated learning, distributed machine learning model training and deployment technologies have increasingly become essential skills for researchers and developers. PyTorch, as the most widely used deep learning framework, has also developed a set of solutions for distributed learning. This article explains the concept, implementation details, and application methods of the torch.distributed parallel computing package in depth, and helps you quickly get started with PyTorch distributed training.
1 Torch.distributed Concepts and Definitions
Definition: First, we provide the official definition of Torch.distributed.
-
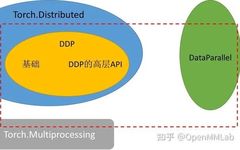
The torch.distributed package provides primitives for supporting multi-process parallel communication between multiple computing nodes running on one or more machines in PyTorch. It can easily parallelize computations across processes and machine clusters. -
torch.nn.parallel.DistributedDataParallel (DDP) is built on this functionality to provide synchronous distributed training as a wrapper for any PyTorch model.
It is worth noting that the core function of torch.distributed is to perform multi-process level communication (rather than multi-threading), achieving the goal of distributed training across multiple GPUs and machines. This is significantly different from multi-threaded training based on DataParallel.
Communication Methods: The underlying communication of torch.distributed primarily uses the Collective Communication (c10d) library to support the sending of tensors across processes within a group, and mainly supports two types of communication APIs:
-
Collective communication APIs: Distributed Data-Parallel Training (DDP) -
P2P communication APIs: RPC-Based Distributed Training (RPC)
These two communication APIs correspond to two distributed training methods in PyTorch: Distributed Data-Parallel Training (DDP) and RPC-Based Distributed Training (RPC). This article focuses on the communication methods and APIs of Distributed Data-Parallel Training (DDP).
Basic Concepts: Below are some key concepts in torch.distributed for reference. These concepts are crucial when writing programs.
-
Group (Process Group) is a subset of all our processes. -
Backend is the process communication library. PyTorch supports NCCL, GLOO, MPI. This article will not elaborate on the differences between these communication backends; interested readers can refer to the official documentation. -
world_size is the number of processes in the process group. -
Rank is a unique identifier assigned to each process in the distributed process group. They are always consecutive integers from 0 to world_size.
2 Torch.distributed Examples
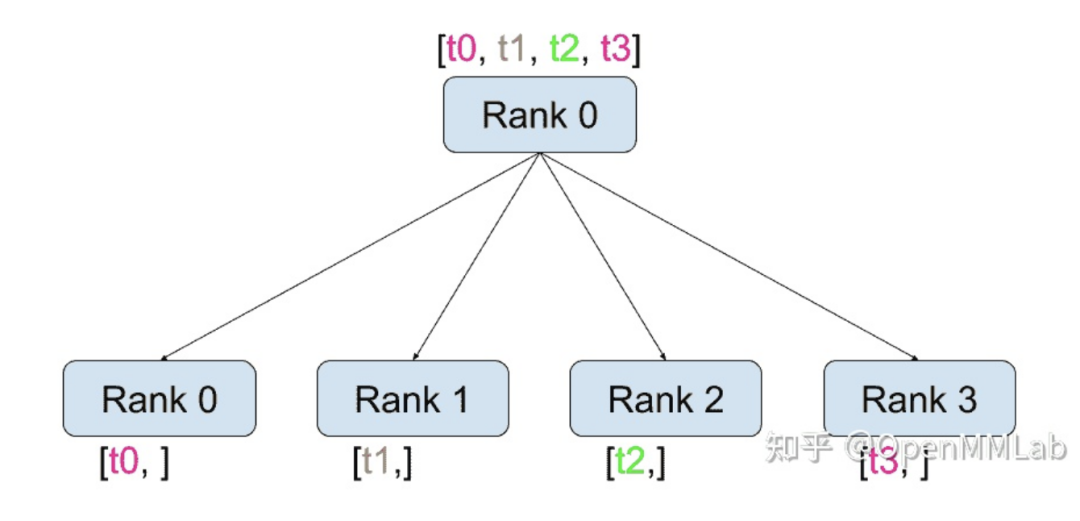
Example 1: Initialization
"""run.py:"""#!/usr/bin/env pythonimport osimport torchimport torch.distributed as distfrom torch.multiprocessing import Process
def run(rank, size): """ Distributed function to be implemented later. """ pass
def init_process(rank, size, fn, backend='gloo'): """ Initialize the distributed environment. """ os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29500' dist.init_process_group(backend, rank=rank, world_size=size)fn(rank, size)
if __name__ == "__main__": size = 2 processes = [] for rank in range(size): p = Process(target=init_process, args=(rank, size, run)) p.start() processes.append(p)
for p in processes: p.join()
This program performs three tasks:
-
Creates two processes -
Each joins a process group -
Each runs the run function. At this point, run is an empty function; subsequent examples will expand the content of this function and complete multi-process communication operations within it.
Example 2: Point-to-Point Communication
The simplest multi-process communication method is point-to-point communication. Information is sent from one process to another.
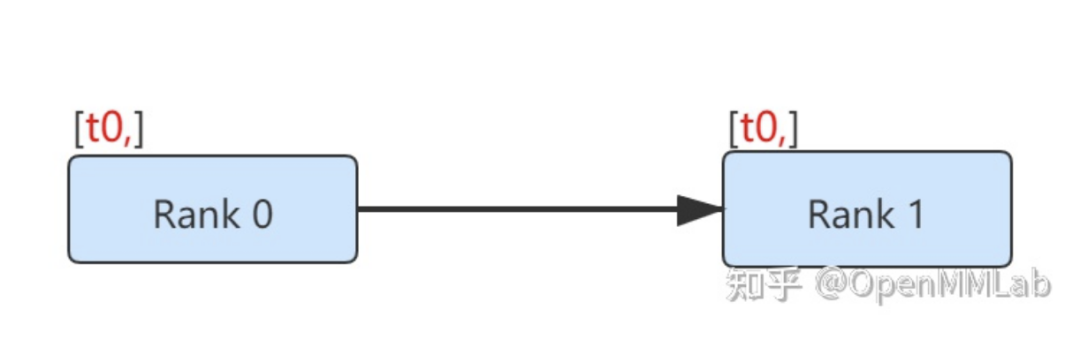
def run(rank, size): tensor = torch.zeros(1) if rank == 0: tensor += 1 # Send the tensor to process 1 dist.send(tensor=tensor, dst=1) else: # Receive tensor from process 0 dist.recv(tensor=tensor, src=0) print('Rank ', rank, ' has data ', tensor[0])
In the above example, both processes start from tensor(0), then process 0 increments the tensor and sends it to process 1, so they both end with tensor(1). Note that process 1 needs to allocate memory to store the data it will receive.
Also note that send/recv are blocking: both processes stop until the communication is complete. We also have another non-blocking communication method, see the next example.
"""Non-blocking point-to-point communication."""
def run(rank, size): tensor = torch.zeros(1) req = None if rank == 0: tensor += 1 # Send the tensor to process 1 req = dist.isend(tensor=tensor, dst=1) print('Rank 0 started sending') else: # Receive tensor from process 0 req = dist.irecv(tensor=tensor, src=0) print('Rank 1 started receiving') req.wait() print('Rank ', rank, ' has data ', tensor[0])
We keep ourselves in a sleep state during the execution of the child process by calling the wait function. Since we do not know when the data will be passed to other processes, we should neither modify the sent tensor nor access the received tensor until req.wait() is complete to prevent uncertain writing.
Example 3: Inter-Group Communication
In contrast to point-to-point communication, collective communication allows communication patterns across all processes in a group. For example, to obtain the sum of all tensors from all processes, we can use the dist.all_reduce(tensor, op, group) function for inter-group communication.
""" All-Reduce example."""
def run(rank, size): """ Simple point-to-point communication. """ group = dist.new_group([0, 1]) tensor = torch.ones(1) dist.all_reduce(tensor, op=dist.reduce_op.SUM, group=group) print('Rank ', rank, ' has data ', tensor[0])
This code first forms a process group of processes 0 and 1, then adds the respective tensors from each process (tensor(1)). Since we need the sum of all tensors in the group, we use dist.reduce_op.SUM as the reduction operator. In general, any commutative mathematical operation can be used as an operator. PyTorch comes with 4 such operators that all run at the element level:
-
dist.reduce_op.SUM -
dist.reduce_op.PRODUCT -
dist.reduce_op.MAX -
dist.reduce_op.MIN
In addition to dist.all_reduce(tensor, op, group), there are currently 6 inter-group communication methods in PyTorch.
distributed.scatter(tensor, scatter_list=None, src=0, group=None, async_op=False): scatters the tensor scatter_list[i] to the i-th process. For example, when implementing distributed training, we would divide the data into four parts and send them to different machines to compute gradients. The scatter function can be used to send information from the src process to other processes.
| tensor | Data to be sent |
| scatter_list | List storing the data to be sent (only specified in the src process) |
| dst | Rank of the sending process |
| group | Specify the process group |
| async_op | Whether the op is asynchronous |
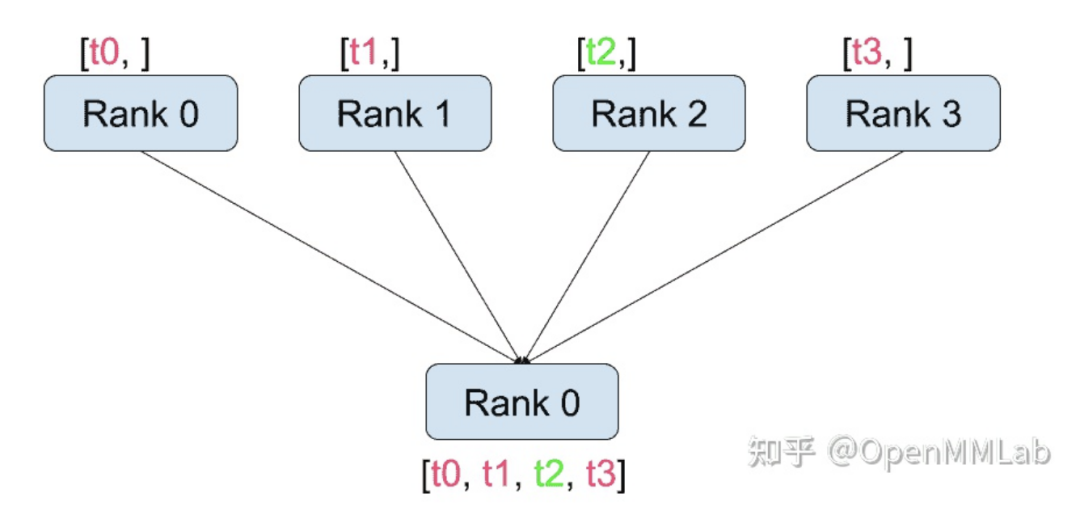
distributed.gather(tensor, gather_list=None, dst=0, group=None, async_op=False): gathers tensors from all processes to dst. For example, in distributed training, the gradients computed by different processes need to be aggregated into one process and averaged to obtain a unified gradient. The gather function can aggregate information from other processes into the dst process.
| tensor | Data to be received |
| gather_list | List storing the received data (only specified in the dst process) |
| dst | Rank of the gathering process |
| group | Specify the process group |
| async_op | Whether the op is asynchronous |
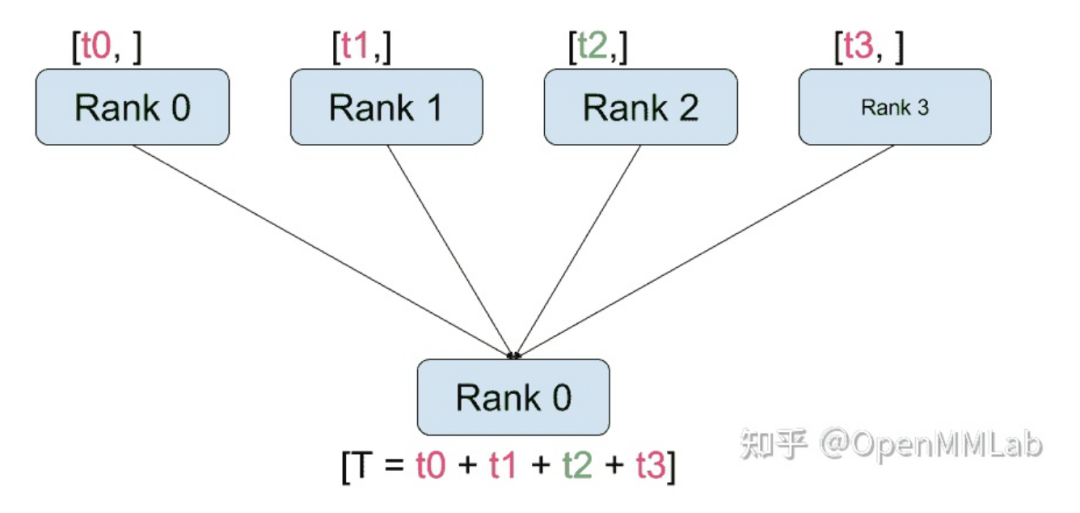
distributed.reduce(tensor, dst, op, group): applies op to all tensors and stores the result in dst.
distributed.all_reduce(tensor, op, group): similar to reduce, but the result is stored in all processes.
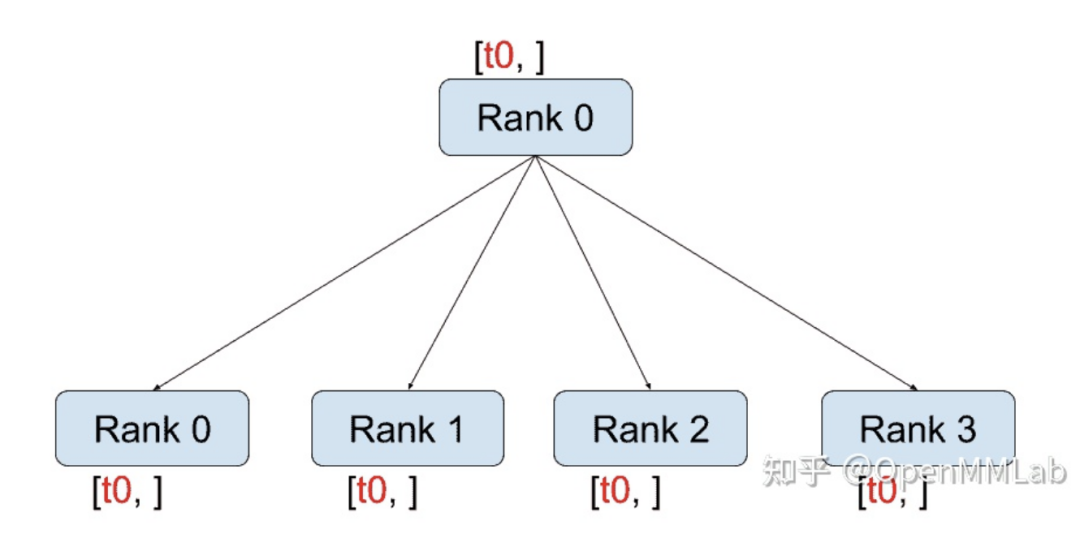
distributed.broadcast(tensor, src, group): copies tensor from src to all other processes.
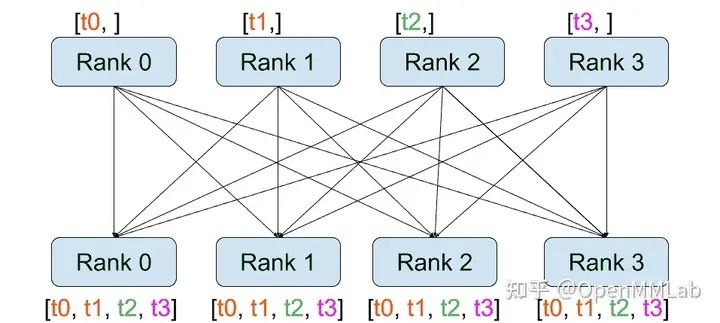
distributed.all_gather(tensor_list, tensor, group): copies tensors from all processes to tensor_list.
Example 4: Distributed Gradient Descent
The distributed gradient descent script allows all processes to compute the gradients of their models on their data batches and then average their gradients. To ensure similar convergence results when changing the number of processes, we must first partition the dataset.
""" Dataset partitioning helper """class Partition(object):
def __init__(self, data, index): self.data = data self.index = index
def __len__(self): return len(self.index)
def __getitem__(self, index): data_idx = self.index[index] return self.data[data_idx
class DataPartitioner(object):
def __init__(self, data, sizes=[0.7, 0.2, 0.1], seed=1234): self.data = data self.partitions = [] rng = Random() rng.seed(seed) data_len = len(data) indexes = [x for x in range(0, data_len)] rng.shuffle(indexes)
for frac in sizes: part_len = int(frac * data_len) self.partitions.append(indexes[0:part_len]) indexes = indexes[part_len:]
def use(self, partition): return Partition(self.data, self.partitions[partition])
Using the above code snippet, we can now easily partition any dataset with the following few lines:
""" Partitioning MNIST """def partition_dataset(): dataset = datasets.MNIST('./data', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])) size = dist.get_world_size() bsz = 128 / float(size) partition_sizes = [1.0 / size for _ in range(size)] partition = DataPartitioner(dataset, partition_sizes) partition = partition.use(dist.get_rank()) train_set = torch.utils.data.DataLoader(partition, batch_size=bsz, shuffle=True) return train_set, bsz
Assuming we have 2 processes, then each process’s train_set would be 60000/2 = 30000 samples. We also divide the batch size by the number of processes to keep the overall batch size at 128.
Now we can write the usual forward-backward optimization training code and add a function call to average the gradients of the model.
""" Distributed Synchronous SGD Example """def run(rank, size): torch.manual_seed(1234) train_set, bsz = partition_dataset() model = Net() optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz)) for epoch in range(10): epoch_loss = 0.0 for data, target in train_set: optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) epoch_loss += loss.item() loss.backward() average_gradients(model) optimizer.step() print('Rank ', dist.get_rank(), ', epoch ', epoch, ': ', epoch_loss / num_batches)
We still need to execute the average_gradients(model) function, which only requires a model and computes the average gradients across all ranks.
""" Gradient averaging. """def average_gradients(model): size = float(dist.get_world_size()) for param in model.parameters(): dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM) param.grad.data /= size
3 PyTorch Parallel/Distributed Training
Based on mastering the basics of torch.distributed, we can use different distributed or parallel training methods according to the specific conditions of our machine and tasks:
-
If the data and model can fit on a single GPU and training speed is not a concern, use single-device training. -
If there are multiple GPUs on a single server and you want to change less code to speed up training, use single-machine multi-GPU DataParallel. -
If there are multiple GPUs on a single server and you want to add more code and speed up training, use single-machine multi-GPU DistributedDataParallel. -
If the application requires multiple servers, use multi-machine DistributedDataParallel with launch scripts. -
If errors are expected (e.g., OOM) or resources can dynamically join and leave during training, use torch.elastic for distributed training.
3.1 DataParallel
class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)DataParallel automatically splits your data and sends job orders to multiple models on multiple GPUs. After each model completes the work, DataParallel collects and merges the results before returning them to you. DataParallel replicates the same model across all GPUs, where each GPU consumes a different partition of the input data. When using this method, the batch size should be larger than the number of GPUs used. It is important to note that DataParallel performs parallel training through multithreading, so it does not use the thread communication APIs in torch.distributed. Its operation process is shown in the figure below.
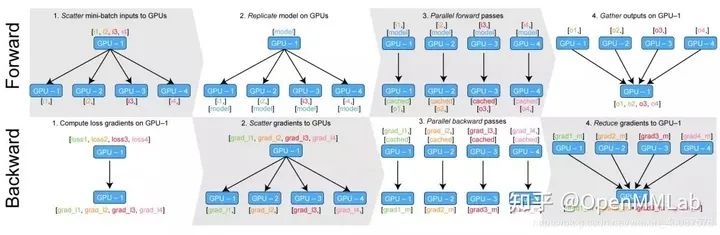
Example 5 DataParallel
Create a dump dataset and define the model.
class RandomDataset(Dataset):
def __init__(self, size, length): self.len = length self.data = torch.randn(length, size)
def __getitem__(self, index): return self.data[index]
def __len__(self): return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True)
class Model(nn.Module): # Our model
def __init__(self, input_size, output_size): super(Model, self).__init__() self.fc = nn.Linear(input_size, output_size)
def forward(self, input): output = self.fc(input) print("\tIn Model: input size", input.size(), "output size", output.size())
return output
Define the model, place it on the device, and wrap it with a DataParallel object.
model = Model(input_size, output_size)if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") # dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs model = nn.DataParallel(model)
model.to(device)
Run the model and output.
for data in rand_loader: input = data.to(device) output = model(input) print("Outside: input size", input.size(), "output_size", output.size())In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2]) In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
We can see that in the model, the data is evenly divided into multiple parts along the batch size dimension. After the output, the data from multiple GPUs is merged.
3.2 DistributedDataParallel
After understanding DataParallel, we will introduce a high-level API based on the process communication functions in torch.distributed.
CLASS torch.nn.parallel.DistributedDataParallel(module, device_ids=None, output_device=None, dim=0, broadcast_buffers=True, process_group=None, bucket_cap_mb=**25**, find_unused_parameters=False, check_reduction=False, gradient_as_bucket_view=False)Since DataParallel can perform parallel model training, why is there still a need to propose DistributedDataParallel? Here we need to understand the implementation principles and differences between the two methods:
-
If the model is too large to fit on a single GPU, it must be split across multiple GPUs using model parallelism. DistributedDataParallel can be used with model parallelism; however, DataParallel is difficult to train large models since it must fit the model in a single GPU. -
DataParallel is a single-process, multi-threaded parallel training method and can only run on a single machine, while DistributedDataParallel is multi-process and is suitable for both single-machine and multi-machine training. DistributedDataParallel also pre-copies the model instead of copying it during each iteration, avoiding the global interpreter lock. -
If both your data and model are too large to fit on a single computer, and your model is too large to fit on a single GPU, you can combine model parallelism (splitting a single model across multiple GPUs) with DistributedDataParallel. In this case, each DistributedDataParallel process can use the model in parallel, while all processes will use the data in parallel.
Example 6 DistributedDataParallel
First, we need to create a series of processes using functions from torch.multiprocessing.
torch.multiprocessing.spawn(fn, args=(), nprocs=1, join=True, daemon=False, start_method='spawn')This function runs the function fn using args as a list of parameters and creates nprocs processes.
If one of the processes exits with a non-zero exit status, the other processes will be killed, and an exception will be raised to terminate the reason. If an exception is caught in the subprocess, it will be forwarded and included in the traceback of the exception raised in the parent process.
This function will be called in the form of fn(i, args), where i is the process index and args is the tuple of passed parameters.
Based on the created processes, we initialize the process group.
import osimport tempfileimport torchimport torch.distributed as distimport torch.nn as nnimport torch.optim as optimimport torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size): os.environ['MASTER_ADDR'] = 'localhost' os.environ['MASTER_PORT'] = '12355'
# initialize the process group dist.init_process_group("gloo", rank=rank, world_size=world_size)
# Explicitly setting seed to make sure that models created in two processes # start from same random weights and biases. torch.manual_seed(42)
def cleanup(): dist.destroy_process_group()
Here we use
torch.distributed.init_process_group(backend, init_method=None, timeout=datetime.timedelta(0, 1800), world_size=-1, rank=-1, store=None, group_name='')This API initializes the default distributed process group and also initializes the distributed package.
This function has two main calling methods:
-
Explicitly specify store, rank, and world_size. -
Specify init_method (URL string), which indicates where/how to discover peers. (Optional) Specify rank and world_size, or encode all required parameters in the URL and ignore them.
Now, let’s create a toy model, wrap it with DDP, and provide some dummy input data. Note that since DDP broadcasts the model state from process 0 to all other processes in the DDP constructor, there is no need to worry about different DDP processes starting from different initial model parameters.
class ToyModel(nn.Module): def __init__(self): super(ToyModel, self).__init__() self.net1 = nn.Linear(10, 10) self.relu = nn.ReLU() self.net2 = nn.Linear(10, 5)
def forward(self, x): return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size): setup(rank, world_size) # Assume we have 8 GPU in total # setup devices for this process, rank 1 uses GPUs [0, 1, 2, 3] and # rank 2 uses GPUs [4, 5, 6, 7]. n = torch.cuda.device_count() // world_size device_ids = list(range(rank * n, (rank + 1) * n))
# create model and move it to device_ids[0] model = ToyModel().to(device_ids[0]) # output_device defaults to device_ids[0] ddp_model = DDP(model, device_ids=device_ids)
loss_fn = nn.MSELoss() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad() outputs = ddp_model(torch.randn(20, 10)) labels = torch.randn(20, 5).to(device_ids[0]) loss_fn(outputs, labels).backward() optimizer.step() cleanup()
def run_demo(demo_fn, world_size): mp.spawn(demo_fn, args=(world_size,), nprocs=world_size, join=True)if __name__ == "__main__": run_demo(demo_basic, 2)
Example 7 Combining DDP with Model Parallelism
DDP can also be used with multi-GPU models, but it does not support intra-process replication. You need to create a process for each model copy, which can generally improve performance compared to multiple model copies per process. DDP wrapping multi-GPU models is particularly useful when training large models with substantial data. When using this feature, care should be taken to implement multi-GPU models without using hard-coded devices, as different model copies will be placed on different devices.
For example, the following model explicitly places different modules on different GPUs.
class ToyMpModel(nn.Module): def __init__(self, dev0, dev1): super(ToyMpModel, self).__init__() self.dev0 = dev0 self.dev1 = dev1 self.net1 = torch.nn.Linear(10, 10).to(dev0) self.relu = torch.nn.ReLU() self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x): x = x.to(self.dev0) x = self.relu(self.net1(x)) x = x.to(self.dev1) return self.net2(x)
When passing multi-GPU models to DDP, do not set device_ids and output_device. Input and output data will be placed on the appropriate devices by the application or the model’s forward() method.
def demo_model_parallel(rank, world_size): setup(rank, world_size)
# setup mp_model and devices for this process dev0 = rank * 2 dev1 = rank * 2 + 1 mp_model = ToyMpModel(dev0, dev1) ddp_mp_model = DDP(mp_model)
loss_fn = nn.MSELoss() optimizer = optim.SGD(ddp_mp_model.parameters(), lr=0.001)
optimizer.zero_grad() # outputs will be on dev1 outputs = ddp_mp_model(torch.randn(20, 10)) labels = torch.randn(20, 5).to(dev1) loss_fn(outputs, labels).backward() optimizer.step()
cleanup()if __name__ == "__main__": run_demo(demo_model_parallel, 4)
Example 8 Saving and Loading Checkpoints
When using DDP, one optimization method is to save the model in only one process and load it into all processes, thereby reducing write overhead.
def demo_checkpoint(rank, world_size): setup(rank, world_size)
# setup devices for this process, rank 1 uses GPUs [0, 1, 2, 3] and # rank 2 uses GPUs [4, 5, 6, 7]. n = torch.cuda.device_count() // world_size device_ids = list(range(rank * n, (rank + 1) * n))
model = ToyModel().to(device_ids[0]) # output_device defaults to device_ids[0] ddp_model = DDP(model, device_ids=device_ids)
loss_fn = nn.MSELoss() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint" if rank == 0: # All processes should see same parameters as they all start from same # random parameters and gradients are synchronized in backward passes. # Therefore, saving it in one process is sufficient. torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# Use a barrier() to make sure that process 1 loads the model after process # 0 saves it. dist.barrier() # configure map_location properly rank0_devices = [x - rank * len(device_ids) for x in device_ids] device_pairs = zip(rank0_devices, device_ids) map_location = {'cuda:%d' % x: 'cuda:%d' % y for x, y in device_pairs} ddp_model.load_state_dict( torch.load(CHECKPOINT_PATH, map_location=map_location))
optimizer.zero_grad() outputs = ddp_model(torch.randn(20, 10)) labels = torch.randn(20, 5).to(device_ids[0]) loss_fn = nn.MSELoss() loss_fn(outputs, labels).backward() optimizer.step()
# Use a barrier() to make sure that all processes have finished reading the # checkpoint dist.barrier() if rank == 0: os.remove(CHECKPOINT_PATH)
cleanup()
4 Conclusion
This article explained the concepts, implementation details, and application methods of the torch.distributed parallel computing package, and helped you quickly get started with PyTorch distributed training. We focused on analyzing the usage methods and principles of the two parallel training APIs: DataParallel and DistributedDataParallel.
References
https://pytorch.org/docs/stable/distributed.html
https://pytorch.apachecn.org/docs/1.7/59.html
Recommended Reading:
Overview of Causal Inference and Basic Methods Introduction (Part 1)
Overview of Causal Inference and Basic Methods Introduction (Part 2)
Research Progress in Multi-Label Text Classification
Click the card below to follow the WeChat account “Machine Learning Algorithms and Natural Language Processing” to get more information: