

New Intelligence Report
New Intelligence Report
Editor: QJP
[New Intelligence Guide] As NLP models become increasingly powerful and are deployed in real-world scenarios, understanding the predictions made by these models becomes more crucial. Recently, Google released a new language interpretability tool (LIT), which is a new approach to explain and analyze NLP models, making their results less of a black box.
For any new model, researchers might want to know in which situations the model performs poorly, why the model makes specific predictions, or whether the model behaves consistently under different inputs, such as variations in text style or pronoun gender.
Despite the recent surge in work on model understanding and evaluation, there are no visualization or interpretability tools available for analysis. Algorithm engineers must experiment with many techniques, such as examining document explanations, clustering metrics, and counterfactual input variations, to build a better interpretable model, which often requires its own software packages or custom tools.

For these problems that have troubled deep learning models for many years, Google’s language interpretability tool (LIT), released at the recently concluded 2020 EMNLP, provides answers.
The What-If Tool previously released by Google was built to address this challenge, supporting black box probing of classification and regression models, thus enabling researchers to more easily debug performance and analyze the fairness of machine learning models through interaction and visualization. However, a toolkit was still needed to tackle challenges specific to NLP models.
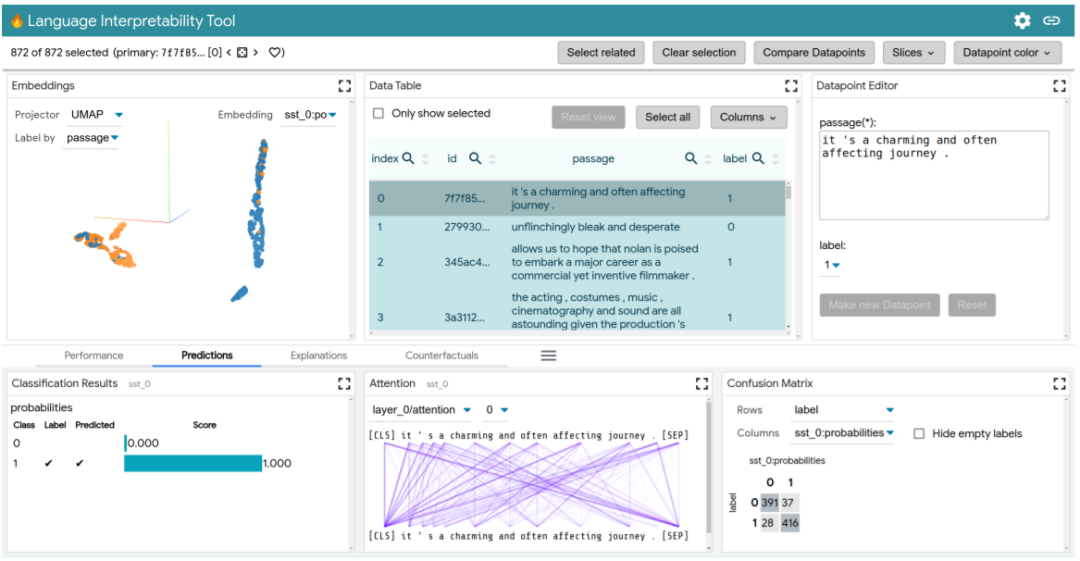
LIT is an interactive platform for understanding NLP models, which improves upon the shortcomings of the What-If Tool, greatly expanding its functionality to cover a wide range of NLP tasks, including sequence generation, span marking, classification, and regression, as well as customizable and extensible visualizations and model analyses.
LIT also supports local explanations, including significance maps, attention mechanisms, rich visualizations of model predictions, and aggregation analyses including metrics, embedding spaces, and flexible slicing.
It allows users to easily switch between visualizations to test local hypotheses and validate them on datasets. LIT provides support for counterfactual generation, where new data points can be dynamically added, and their impact on the model can be visualized. It also allows for side-by-side visualization of two models or two separate data points.
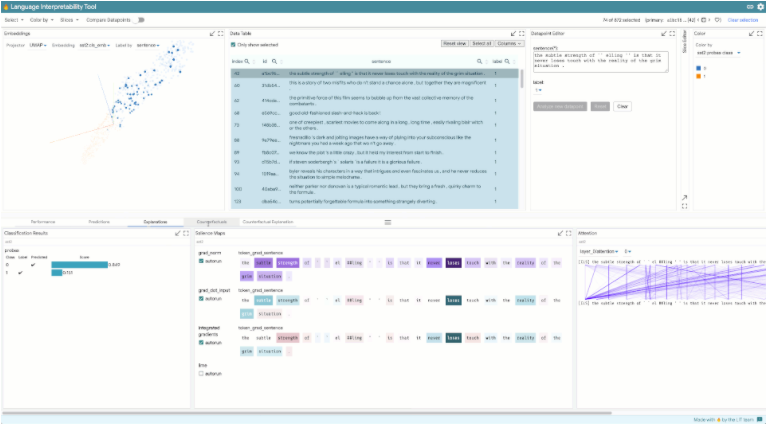
To better meet the diverse interests and priorities of users utilizing LIT, researchers built this tool from the ground up to be easily customizable and extensible.
Using LIT on specific NLP models and datasets requires writing only a small amount of Python code. Custom components, such as task-specific metric calculations or counterfactual generators, can be written in Python and added to the LIT instance via the provided API.
Moreover, the frontend itself can also be customized, using new modules directly integrated into the user interface.
To illustrate some of the features of LIT, demonstrations can be created using pre-trained models. Here are two examples:
The first is sentiment analysis, where a binary classifier can predict whether a sentence has a positive or negative sentiment. The various visualizations provided by LIT can help determine in which situations the model fails and whether these failures can generalize, which can then inform how best to improve the model.

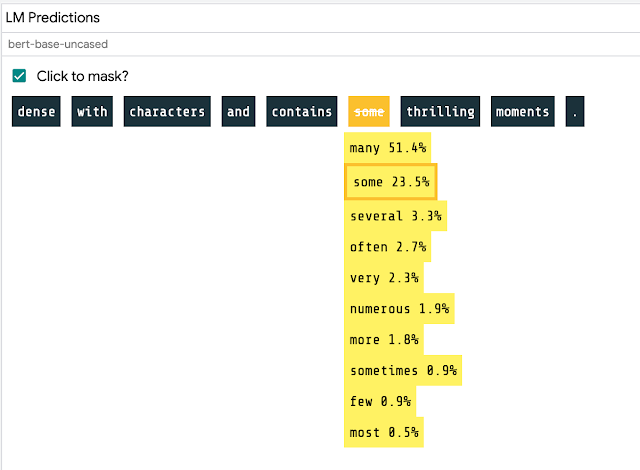
Masked language modeling is a “fill-in-the-blank” task where the model predicts different words that can complete a sentence. For example, given the prompt, “I took my _ _ for a walk,” the model might predict that the score for “dog” is high. In LIT, users can input sentences or select from a pre-loaded corpus, then click on specific tokens to see what a model like BERT understands about language or the world.
Although LIT is a new tool, we have already seen its value for model understanding. Its visualizations can be used to discover patterns in model behavior, such as discrete clusters in the embedding space or words that are significant to prediction outcomes.
Exploration in LIT can test for potential biases in the model, as we demonstrated in a case study of gender bias in a common reference model. This type of analysis can inform the next steps for improving model performance, such as applying MinDiff to mitigate systemic bias. It can also serve as a simple and quick way to create interactive demonstrations for any NLP model.

By using the provided demonstrations or your own models and datasets, a LIT server can be set up to examine this tool. Currently, research on LIT has only just begun, and new features and improvements are planned, including the addition of new interpretability techniques from cutting-edge machine learning and natural language processing research. The code is open source, allowing interested parties to make their own improvements and contributions.
Reference link:
https://ai.googleblog.com/2020/11/the-language-interpretability-tool-lit.html
