
Natural Language Processing
Author: Zhang Junlin
Source: Deep Learning Frontier Notes Zhihu Column
Original Link: https://zhuanlan.zhihu.com/p/49271699
The theme of this article is the pre-training process in natural language processing (NLP). It will roughly explain how pre-training techniques in NLP have gradually developed into the BERT model, naturally illustrating how the ideas behind BERT were formed, its historical evolution, what it inherited, what innovations it brought, why it is so effective, and why the model innovation is not considered significant, while BERT is regarded as a significant advancement in NLP in recent years.We will discuss this step by step, with the narrative thread being the pre-training process of natural language, but the focus remains on BERT.To discuss the pre-training of natural language, we must first start with the pre-training in the field of images.
Pre-training in the Image Domain
Since deep learning gained popularity, the pre-training process has become a conventional practice in the image or video domain, with a long history, and this approach is very effective, significantly enhancing application performance.
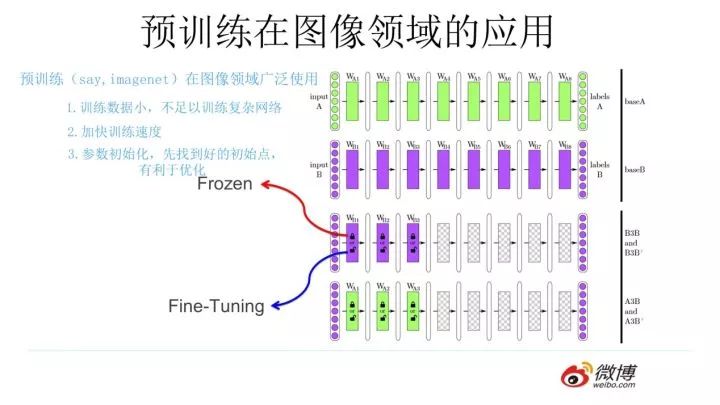
So how is pre-training done in the image domain? The above illustration shows this process. After designing the network structure, for images, it is generally a multi-layer stacked CNN structure. We can first pre-train this network using a training set, such as training set A or training set B, to learn the network parameters for task A or B and store them for later use.Assuming we are faced with a third task C, we can use the same network structure, and when initializing the parameters of the shallower CNN layers, we can load the parameters learned from task A or B, while the parameters of the higher CNN layers remain randomly initialized.Then we train the network with the training data for task C. There are two approaches: one is to keep the loaded parameters fixed during the training of task C, called “Frozen”; the other is to allow the lower-level parameters, although initialized, to continue to change throughout the training process of task C, generally referred to as “Fine-Tuning”, which means adjusting the parameters better to adapt to the current task C.This is generally how pre-training is done in the image or video domain.
There are several benefits to this approach. First, if the training set for task C is relatively small, current effective CNNs like ResNet/DenseNet/Inception, etc., have a large number of layers, starting from several million to tens of millions of parameters, with over a hundred million parameters being quite common. With limited training data, it is difficult to train such complex networks well. However, if a large number of parameters are pre-trained using a large training set like ImageNet, and then used to initialize most of the network structure parameters, followed by a fine-tuning process using the limited data for task C, it becomes much easier.This allows previously untrainable tasks to be solved. Even if there is a considerable amount of training data for the current task, adding a pre-training process can significantly speed up the convergence of training for the task. Thus, this pre-training method is a widely applicable solution, and its effectiveness has quickly made it popular in the image processing domain.
Now a new question arises: why is this pre-training approach feasible?

We now know that for hierarchical CNN structures, different layers of neurons learn different types of image features, forming a hierarchical structure from bottom to top, as shown in the above image. If we are dealing with a facial recognition task, after training the network, we can visualize the features learned by each layer of neurons to see what features each layer has learned. You will observe that the lowest layer of neurons learns features like lines, while the second hidden layer learns the contours of facial features, and the third layer learns the outline of the face, forming a hierarchical structure of features. The lower-level features are basic features that all images possess, such as edges and corners, while the features extracted at higher levels are more relevant to the specific task at hand.Because of this, the pre-trained network parameters, especially the lower-level parameters that extract features unrelated to specific tasks, possess greater generality for tasks. This is why pre-trained lower-level parameters are generally used to initialize new task network parameters.Higher-level features are more closely related to the task and can often be discarded or fine-tuned using new data sets to eliminate irrelevant feature extractors.
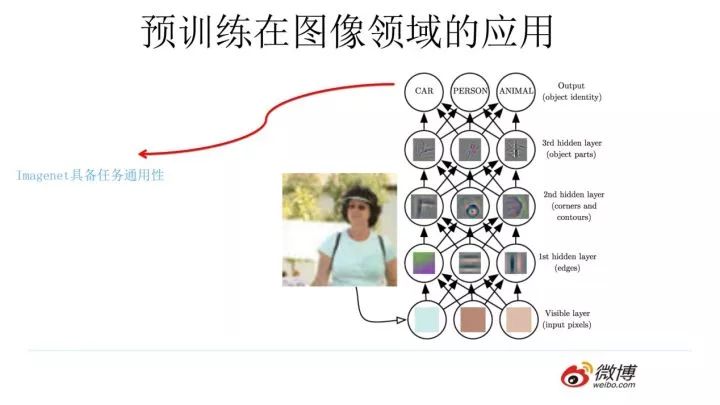
Generally, we prefer to use ImageNet for network pre-training for two reasons. First, ImageNet is a dataset with a vast amount of pre-labeled training data in the image domain, which is a significant advantage; the larger the quantity, the more reliable the parameters learned. Second, because ImageNet has 1000 categories, it is a general image dataset that is not too domain-specific, so it has good generality. After pre-training, it can be used anywhere, making it a versatile solution.Such a versatile solution is, of course, loved by everyone.
After hearing the above, if you are a person with research qualities, meaning you have curiosity, you must ask the following question: “Since pre-training in the image domain is so effective, why not do the same in natural language processing? Are NLP researchers less clever than those in computer vision? Even if you are not clever, you can learn from others’ practices, can’t you? This is innovation; perhaps it will succeed, and your success will come unexpectedly!”
Well, good question. In fact, NLP researchers are not any less clever than you think; many have tried this approach, but overall, it has not been very successful.Have you heard of word embedding? It was introduced in 2003, an old technology with a rich history.Word embedding is actually an early pre-training technique in NLP.Of course, it cannot be said that word embedding was unsuccessful; generally, it can improve performance by 1 to 2 points when added to downstream tasks, but it has not been a particularly dazzling success.
Haven’t heard of it? Then let me briefly tell you about this old topic.
The Archaeology of Word Embedding
This section will roughly discuss the story of Word Embedding, in a very general way, because there are already too many articles online discussing this technology, so I won’t go into details at this moment. However, since we need to discuss pre-training, we have to start with this, so let me briefly touch on it, mainly to lead into the more exciting parts that follow.Before discussing Word Embedding, let’s first briefly talk about language models because the general choice for pre-training in NLP is to use language model tasks.

What is a language model? Actually, you can understand it from the diagram above. To quantitatively measure which sentence resembles human language more, we can design a function as shown in the diagram. The core idea of function P is to predict the probability of which word follows a series of preceding words in the sentence (theoretically, in addition to the preceding context, we can also introduce the words that follow to predict the occurrence probability of the word). Each word in the sentence has a process of predicting itself based on the preceding context, and multiplying the occurrence probabilities of all these words results in a value that indicates how closely it resembles a human language sentence.I’ll set aside the language model for now; I have a vague feeling that you may not quite understand what I’m saying, but that’s the general idea. If you don’t understand, you can look it up online; there are plenty of resources available.
Suppose now you are tasked with designing a neural network structure to perform this language model task, that is, given a lot of corpora to train a neural network that, when given the first few words of a sentence, predicts which word should follow. How would you do it?
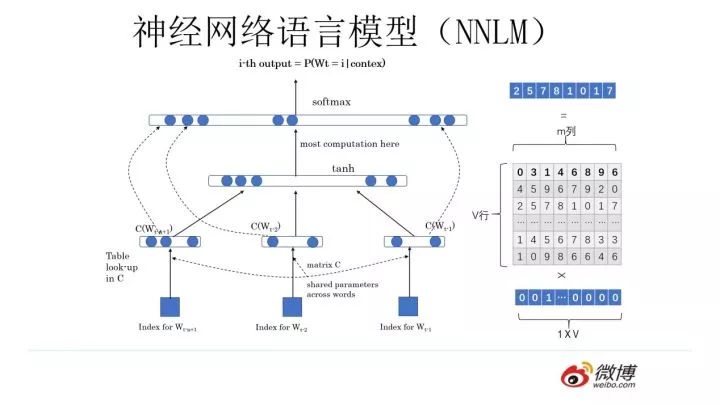
You can design the network structure as shown in the above diagram. This is actually the well-known Neural Network Language Model, abbreviated as NNLM, used for language modeling.This work has been around for a while and is an old piece of work, published by Bengio in 2003 in JMLR.It was born in 2003, gained popularity in 2013, and whether it will remain significant is still uncertain, but unfortunately, after its birth, it did not cause much of a stir and remained dormant for ten years, finally being brought back to light in 2013 by NLP archaeologists.Why did this technical adventure occur? You need to think about what year 2013 was; it was the glorious moment when deep learning began to penetrate the field of NLP, the first step of a long march, and NNLM can be considered the first shot of the Nanchang Uprising.Before deep learning gained prominence, very few people used neural networks for NLP problems. If you insisted on using neural networks for NLP ten years ago, others would probably think you had a problem.As the saying goes, no one can stop the wheel of historical development, and this is a good example.
That’s enough small talk; let’s get back to discussing NNLM’s approach.First, let’s talk about the training process. Looking back now, it seems quite simple; those of you who have seen RNNs, LSTMs, or CNNs might find this network a bit simplistic.The learning task is to input a word in a sentence  the preceding t-1 words, requiring the network to correctly predict the word BERT, maximizing:
the preceding t-1 words, requiring the network to correctly predict the word BERT, maximizing:
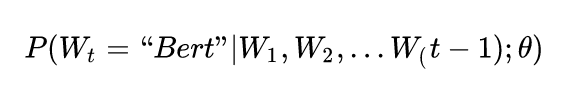
Any preceding word  using one-hot encoding (for example: 0001000) as the original word input, then multiplying by matrix Q to obtain the vector
using one-hot encoding (for example: 0001000) as the original word input, then multiplying by matrix Q to obtain the vector  , each word’s
, each word’s  concatenated, connecting to the hidden layer, then going through softmax to predict which word should follow. What is this? This is actually how the word’s Word Embedding values are learned, where matrix Q contains V rows, with V representing the vocabulary size, and each row represents the corresponding word’s Word embedding value. At the beginning of training, matrix Q is initialized with random values, and after training, the contents of matrix Q are correctly assigned, with each row representing a word’s corresponding Word embedding value. Therefore, you see, through this network learning the language model task, this network can not only predict the next word based on the preceding context but also learn a byproduct, which is the matrix Q, showing how the word’s Word Embedding is learned.
concatenated, connecting to the hidden layer, then going through softmax to predict which word should follow. What is this? This is actually how the word’s Word Embedding values are learned, where matrix Q contains V rows, with V representing the vocabulary size, and each row represents the corresponding word’s Word embedding value. At the beginning of training, matrix Q is initialized with random values, and after training, the contents of matrix Q are correctly assigned, with each row representing a word’s corresponding Word embedding value. Therefore, you see, through this network learning the language model task, this network can not only predict the next word based on the preceding context but also learn a byproduct, which is the matrix Q, showing how the word’s Word Embedding is learned.
The most popular tool for using language models to create Word Embedding in 2013 was Word2Vec, followed by Glove. How does Word2Vec work? Take a look at the diagram below.
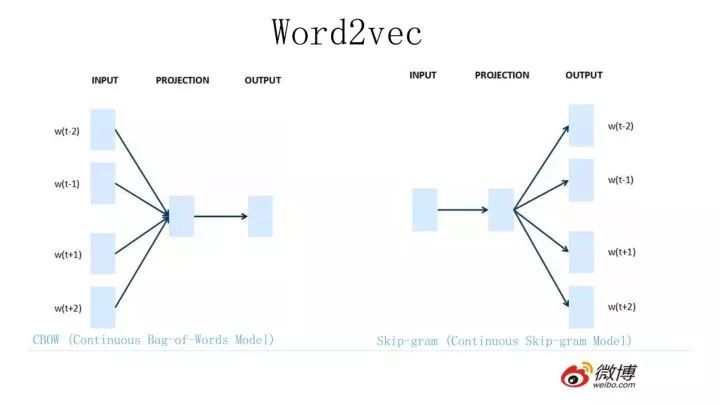
The network structure of Word2Vec is actually quite similar to that of NNLM, although the clarity of this diagram is somewhat lacking. However, they are essentially brothers.But it is important to note: despite the similar network structure and also being a language model task, their training methods are quite different.Word2Vec has two training methods: one called CBOW, where the core idea is to remove a word from a sentence and use its context to predict the missing word; the second is called Skip-gram, which is the reverse of CBOW, where the input is a specific word, and the task is to predict its surrounding context words.If you look back at how NNLM was trained, it was inputting a word’s context to predict that word.This is a significant difference.Why does Word2Vec handle it this way? The reason is simple: Word2Vec and NNLM have different main tasks. NNLM’s main task is to learn a network structure to solve language model tasks, which requires observing the context to predict the following words, while word embedding is merely an incidental byproduct.However, Word2Vec has a different goal; it is purely focused on learning word embedding, which is its main product, so it can train the network more freely.
Why discuss Word2Vec? Here, it mainly serves to introduce the training method of CBOW, which is related to BERT, and I will explain how they are related later. Of course, the authors of BERT did not mention this relationship; this is my speculation. As for whether my speculation is correct, you can judge for yourself later.

By using Word2Vec or Glove, and performing language model tasks, we can obtain the Word Embedding for each word. How effective is this method? The above image provides several examples found online, and it can be seen that some examples yield quite good results. Once a word is expressed as Word Embedding, it becomes very easy to find other semantically similar words.
Our theme is pre-training, so the question arises: can this method of Word Embedding be considered pre-training? This is actually a standard pre-training process.To understand this, we should look at how the learned Word Embedding is used in downstream tasks.
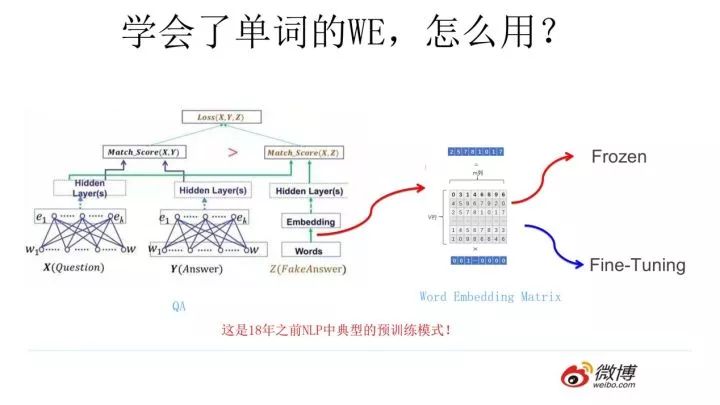
Suppose, as shown in the diagram above, we have a downstream NLP task, such as QA (Question Answering). In a QA task, given a question X and another sentence Y, we need to determine whether sentence Y is the correct answer to question X.For the QA task, the designed network structure is as shown above. I won’t elaborate on this because those who understand will understand, and those who don’t, it doesn’t matter, as this point is not critical to the main topic of this article. What is critical is how the network uses the learned Word Embedding.The usage method is actually similar to what was previously described for NNLM, where each word in the sentence is input in one-hot form, then multiplied by the learned Word Embedding matrix Q to directly retrieve the corresponding Word Embedding for that word.This may seem like a lookup operation and not like a pre-training approach, right? However, that’s not the case; the Word Embedding matrix Q is actually the network parameter matrix that maps from the one-hot layer to the embedding layer.So, you see, using Word Embedding is equivalent to initializing the network from the one-hot layer to the embedding layer with pre-trained parameter matrix Q.This is quite similar to the lower-level pre-training process discussed earlier in the image domain; the only difference is that Word Embedding can only initialize the parameters of the first layer of the network, while higher-level parameters remain untrained.When downstream NLP tasks use Word Embedding, they also have two approaches similar to images: one is Frozen, where the parameters of the Word Embedding layer remain fixed; the other is Fine-Tuning, where the parameters of the Word Embedding layer are updated during training with the new training set.
The above approach is the typical method used in the NLP field for pre-training before 2018. As mentioned earlier, Word Embedding is indeed helpful for many downstream NLP tasks, but its assistance has not been significant enough to dazzle the audience.Now a new question arises: why is the training and usage of Word Embedding not as effective as expected? The answer is simple: there are issues with Word Embedding.This may sound like a rather simplistic answer; the key issue is: what problems does Word Embedding have? This is actually a good question.

What shadow has loomed over Word Embedding for years? It is the issue of polysemy. We know that polysemy is a common phenomenon in natural language and reflects the flexibility and efficiency of language.What negative impact does polysemy have on Word Embedding? As shown in the above image, for example, the polysemous word “Bank” has two common meanings, but when encoding the word “bank” with Word Embedding, it cannot distinguish between these two meanings because, despite the different contextual words appearing, during the training phase with the language model, any context sentence processed through Word2Vec predicts the same word “bank”, occupying the same parameter space. This leads to both different contextual information being encoded into the same Word Embedding space.Thus, Word Embedding cannot distinguish between the different meanings of polysemous words, which is a significant issue.
You might think you’re clever and say this can be resolved. Indeed, many researchers have proposed various methods to address this problem, but looking back today, these methods seem too costly or cumbersome. Is there a simple and elegant solution?
ELMO offers a concise and elegant solution.
From Word Embedding to ELMO
ELMO stands for “Embedding from Language Models”. In fact, this name does not reflect its essential idea. The title of the paper proposing ELMO, “Deep contextualized word representation,” better embodies its essence. Where is the essence? In the phrase “deep contextualized”; one is deep, and the other is context, with context being more critical.Before ELMO, Word Embedding was essentially static, meaning that once a word’s representation was trained, it remained fixed. When used later, regardless of the new sentence’s contextual words, the Word Embedding of that word would not change with the context, leading to cases like the word “bank” where its previously learned Word Embedding mixed several meanings. When a new sentence appears, even when it is clear from the context (for example, the sentence contains words like “money”) that it represents the meaning of “bank”, the corresponding Word Embedding content does not change; it still mixes multiple meanings.This is why it is deemed static, and this is the problem.ELMO’s core idea is: I pre-train a word’s Word Embedding using a language model, and at this point, polysemy cannot be distinguished, but that’s okay.When I actually use the Word Embedding, the words have specific contexts, and I can adjust the word’s Word Embedding representation based on the semantic information of the context words. This way, the adjusted Word Embedding can better express its specific meaning in that context, naturally solving the polysemy issue.Thus, ELMO is a method that dynamically adjusts Word Embedding based on the current context.
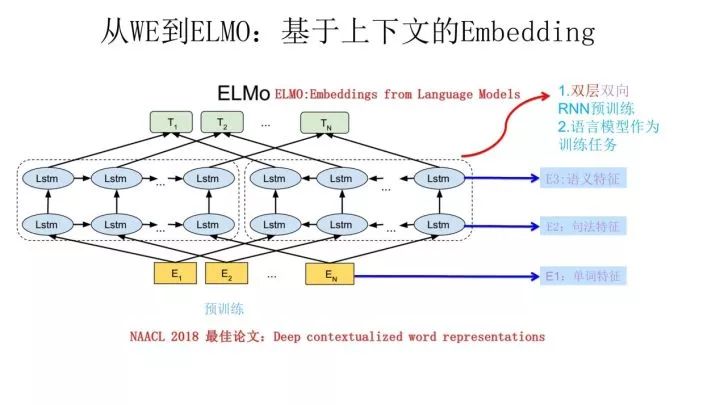
ELMO employs a typical two-stage process. The first stage uses a language model for pre-training; the second stage extracts the corresponding word’s Word Embedding from the pre-trained network during downstream tasks to supplement new features for those tasks.The above image illustrates its pre-training process, where the network structure uses a two-layer bidirectional LSTM. The current language model training task aims to correctly predict a word based on the context of the words  the word
the word  the preceding word sequence Context-before represents the preceding context, while the subsequent word sequence Context-after represents the following context. The leftmost forward double-layer LSTM represents the forward encoder, inputting the sequence of words from left to right, excluding the predicted word
the preceding word sequence Context-before represents the preceding context, while the subsequent word sequence Context-after represents the following context. The leftmost forward double-layer LSTM represents the forward encoder, inputting the sequence of words from left to right, excluding the predicted word  the preceding context; the rightmost reverse double-layer LSTM represents the backward encoder, inputting the sentence’s context in reverse order. Each encoder’s depth consists of two stacked LSTMs. This network structure is quite common in NLP.By using this network structure and a large corpus to perform language model tasks, we can pre-train this network. If this network is trained well, when inputting a new sentence Snew, each word in the sentence can obtain the corresponding three Embeddings: the lowest layer is the word’s Word Embedding, moving up to the first layer of the bidirectional LSTM, where the corresponding word position’s embedding encodes more syntactic information; further up is the second layer of LSTM, where the corresponding word position’s embedding encodes more semantic information.In other words, the pre-training process of ELMO not only learns the Word Embedding of words but also learns a two-layer bidirectional LSTM network structure, both of which are useful later.
the preceding context; the rightmost reverse double-layer LSTM represents the backward encoder, inputting the sentence’s context in reverse order. Each encoder’s depth consists of two stacked LSTMs. This network structure is quite common in NLP.By using this network structure and a large corpus to perform language model tasks, we can pre-train this network. If this network is trained well, when inputting a new sentence Snew, each word in the sentence can obtain the corresponding three Embeddings: the lowest layer is the word’s Word Embedding, moving up to the first layer of the bidirectional LSTM, where the corresponding word position’s embedding encodes more syntactic information; further up is the second layer of LSTM, where the corresponding word position’s embedding encodes more semantic information.In other words, the pre-training process of ELMO not only learns the Word Embedding of words but also learns a two-layer bidirectional LSTM network structure, both of which are useful later.
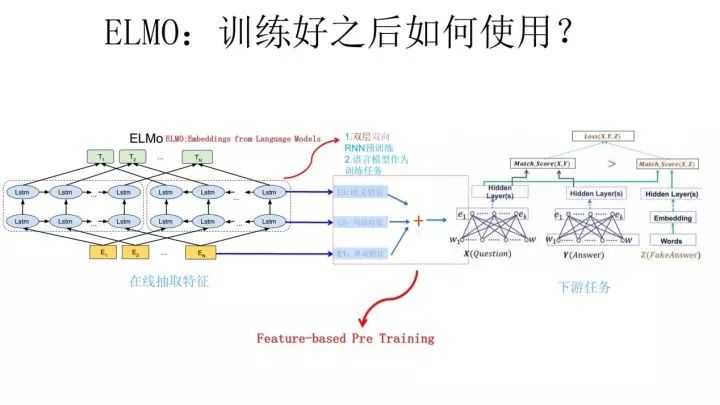
The above describes the first phase of ELMO: the pre-training phase. Now, how do we use the pre-trained network structure for downstream tasks? The above image shows the usage process for a downstream task, such as our QA task. For the question sentence X, we can input sentence X into the pre-trained ELMO network. Thus, each word in sentence X will obtain the corresponding three Embeddings in the ELMO network. Then, we assign a weight a to each of these three Embeddings, which can be learned, and we sum them up according to their weights to integrate them into one.Then, the integrated Embedding is used as the input for corresponding words in the network structure of the task, serving as a supplementary new feature for the downstream task.The same process applies to the answer sentence Y in the QA task shown in the above image.Since ELMO provides features for each word, this type of pre-training method is referred to as “Feature-based Pre-Training”.As for why this method can achieve the effect of distinguishing polysemous words, you can easily think of the reason.
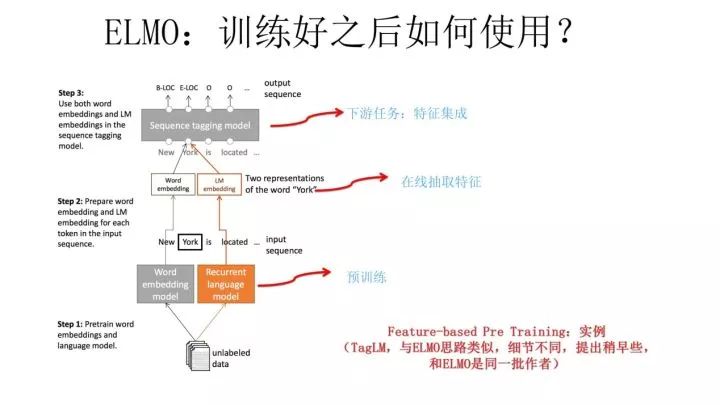
The above image shows the process of TagLM adopting a similar approach to ELMO for named entity recognition tasks, and the steps are basically the same as those of ELMO, so I won’t elaborate on it here. The paper on TagLM was presented at the ACL conference in 2017, and the authors are the same people from AllenAI who worked on ELMO. Therefore, TagLM can be seen as a precursor to ELMO.A few days ago, after I sent out this PPT, someone questioned that FastAI’s ULMFiT, proposed in April 2018, was the pioneering work that abandoned traditional Word Embedding and introduced a new model. I strongly disagree.Firstly, TagLM appeared earlier, and its model is essentially the same as ELMO; secondly, ULMFiT uses a three-stage model, adding a domain language model pre-training process after the general language model training, and the paper’s primary focus is on this part, which is relatively complex. This is not a particularly good idea because the limitation of domain language models is that their scale is often not very large, making it impractical to focus on this area. It seems more reasonable to concentrate on general language models; furthermore, although ULMFiT conducted experiments on six tasks, they all focused on classification problems that are relatively narrow, which is not as broad as the issues validated by ELMO. I believe this is due to the limitations imposed by the second domain language model.Therefore, overall, although ULMFiT is also a good piece of work, its importance is at least a notch lower than ELMO, but this is my personal opinion.Everyone has different academic tastes; I personally have always appreciated work that either effectively reflects the essence of a problem or has ideas that deviate significantly from existing frameworks. Thus, while reading the ULFMiT paper, I felt somewhat uncomfortable, thinking it missed the point and was overly complicated. However, reading the ELMO paper felt refreshing, and I silently applauded, thinking such an article deserved to win the Best Paper Award at NAACL 2018, which is far superior to many Best Papers at ACL. This is the instinctive feeling experienced by someone with experience when reading a good paper, often referred to as the dish matching the diner’s aesthetic taste.

Earlier, we mentioned that static Word Embedding cannot solve the polysemy problem. Has ELMO solved this problem by introducing contextually dynamic adjustments to the word’s embedding? Yes, it has, and even better than we expected.The above image provides an example: for Word Embedding trained by Glove, the polysemous word “play” finds that most of the semantically similar words are concentrated in the sports domain. This is obviously because the number of sentences containing “play” in the training data is overwhelmingly dominant in the sports context; however, using ELMO, the dynamically adjusted embedding not only identifies sentences with the same meaning corresponding to “performance” but also ensures that the word “play” found in those sentences corresponds to the same part of speech. This is beyond expectations.The reason this occurs is that the first layer of LSTM encodes a lot of syntactic information, which plays a crucial role here.

How effective is ELMO after these operations? The experimental results are shown in the above image, where performance improves to varying degrees across six NLP tasks, with the highest improvement reaching around 25%. Moreover, these six tasks cover a wide range of areas, including sentence semantic relationship judgment, classification tasks, reading comprehension, etc. This indicates that its applicability is very broad and has strong universality, which is a significant advantage.

Now, looking at the current time point, what shortcomings does ELMO have? First, a very obvious shortcoming is in feature extractor selection; ELMO uses LSTM instead of the new Transformer. The Transformer was proposed by Google in the paper “Attention is All You Need” for machine translation tasks in 2017, which caused a significant stir. Many studies have shown that the feature extraction capabilities of the Transformer are far superior to those of LSTM.If ELMO had used the Transformer as its feature extractor, it is likely that BERT would not have received as much attention as it has now.Another point is that ELMO’s approach of concatenating bidirectional features may be weaker than BERT’s integrated feature fusion method. However, this is just a suspicion inferred from reasoning, and currently, there is no specific experiment to prove this point.
If we compare the pre-training methods of ELMO with those in the image domain, we find that there are still significant differences between the two modes. In addition to the feature fusion-based pre-training methods represented by ELMO, there is another typical approach in NLP that looks quite similar to the methods in the image domain. This method is generally referred to as the “Fine-tuning based model”, and GPT is a typical pioneer of this model.
From Word Embedding to GPT
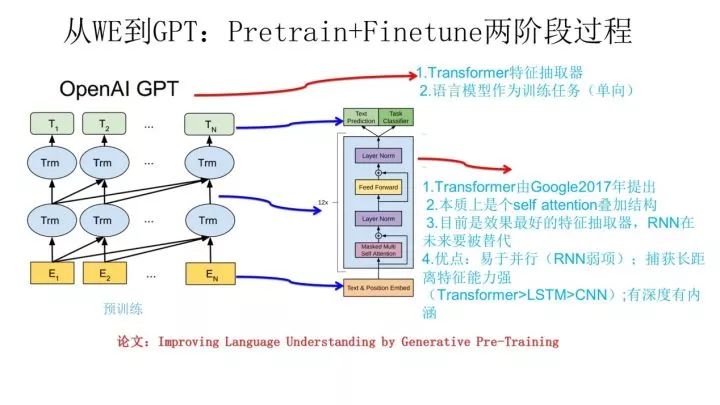
GPT stands for “Generative Pre-Training”, and from the name, it implies a generative pre-training approach.GPT also adopts a two-stage process: the first stage uses a language model for pre-training, and the second stage solves downstream tasks using the Fine-tuning method.The above image illustrates the pre-training process of GPT, which is actually similar to ELMO. The main differences are twofold: first, the feature extractor used is not RNN but Transformer, as mentioned earlier, its feature extraction capabilities are superior to RNN, making this choice evidently wise; secondly, although GPT’s pre-training is still based on a language model as the target task, it employs a unidirectional language model. The term “unidirectional” means that the task goal of the language model is to predict word Wi based on its context, where the preceding word sequence Context-before is the preceding context, while the following word sequence Context-after is the following context.When ELMO performs pre-training for the language model, it uses both preceding and following contexts to predict word Wi, while GPT only uses the preceding context of word Wi for prediction, ignoring the following context.This choice does not seem to be very good; the reason is simple: it does not incorporate the following context into the word embedding, which limits its effectiveness in more application scenarios, such as reading comprehension tasks, where it is permissible to see both preceding and following contexts for decision-making.If the following context is not embedded into the word embedding during pre-training, it is a loss, as much information is discarded.
Here, I will forcibly insert a brief explanation about the Transformer. Although I mentioned it earlier, I did not cover it completely, so I will add a few more words. First, the Transformer is a deep network composed of stacked “self-attention mechanisms”, and it is currently the strongest feature extractor in NLP. The attention mechanism has been greatly promoted here, evolving from being a supporting role in tasks to becoming the leading character, ultimately replacing RNN and CNN as the primary feature extractors and achieving great success.You might ask: what is the attention mechanism? Here, I would like to recommend my earlier work from 2016, revised in 2017, titled “Attention Models in Deep Learning”, which supplements the relevant foundational knowledge. If you are not familiar with the attention mechanism, you will surely fall behind the development trends of the times.For a good introduction to the Transformer, you can refer to the following two articles: one is Jay Alammar’s visual introduction to the Transformer, titled “The Illustrated Transformer”, which is very easy to understand; I recommend starting from this article; the other is the “Annotated Transformer” written by the NLP research group at Harvard University, which clearly explains both the code and principles. I believe these two articles are sufficient for you to understand the Transformer, so I won’t elaborate further.
Secondly, I predict that the Transformer will gradually replace RNN as the mainstream tool in NLP. RNN has always been constrained by its sequential dependency structure, which limits its parallel computing capabilities. Although many people are trying to correct this issue by modifying the RNN structure, I am not optimistic about this model because it is better to upgrade a horse-drawn carriage to a car than to change the tires. This is easy to understand, especially since the prototype of the car has already emerged. Why persist in changing tires?As for CNN, CNN has not formed a mainstream in NLP; its biggest advantage is ease of parallel computation, leading to speed. However, it naturally has deficiencies in capturing sequential relationships in NLP, especially long-distance features; it is not that it cannot do it, but that it does not do it well. Currently, many improved models exist, but few have been particularly successful.Considering all aspects, it is clear that the Transformer possesses good parallelism and is suitable for capturing long-distance features, leaving no reason for it to lag behind RNN and CNN in competitive races.
All right, enough of the digressions; let’s return to the main topic and continue discussing GPT.What I described above is how GPT performs the first stage of pre-training. Now, how does it utilize the pre-trained model for downstream tasks? It has its own personality, quite different from ELMO’s approach.
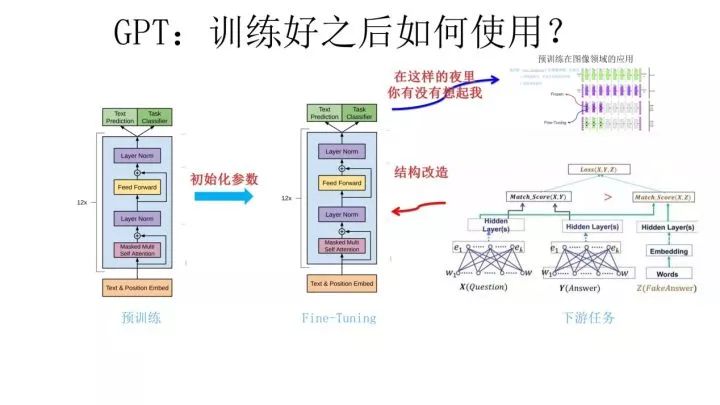
The above image illustrates how GPT uses the pre-trained model in the second stage. First, for different downstream tasks, you could originally design your own network structure freely, but now you cannot; you have to align your task’s network structure with that of GPT.Then, while performing downstream tasks, you initialize GPT’s network structure with the parameters pre-trained in the first step, allowing the linguistic knowledge learned during pre-training to be introduced into your current task, which is a great advantage.Finally, you can use your current task to train this network, fine-tuning the network parameters to make them more suitable for solving the current problem.That’s it.Do you see? Does this remind you of how pre-training is done in the image domain (please refer to the very easy-to-expose-age lyrics in the above image)? Yes, this follows that exact pattern.
Here, a new question arises: for various diverse NLP tasks, how can they be modified to align with GPT’s network structure?

The GPT paper provides a modification blueprint, which is quite simple: for classification problems, you don’t need to change much; just add a start and end symbol; for sentence relationship judgment tasks, such as entailment, simply add a separator between the two sentences; for text similarity judgment tasks, reverse the order of the two sentences for two inputs, indicating that the order of sentences is not important; for multiple-choice questions, input multiple routes, concatenating the article and answer options as input for each route.As shown in the above image, this modification is quite convenient; different tasks only require changes in the input part.
The effectiveness of GPT is astonishing; among 12 tasks, it achieved the best results in 9, and for some tasks, the performance improvement is very significant.
Now, looking at the current time point, what improvements can be made to GPT? Actually, the main issue is that it uses a unidirectional language model. If it were modified to a bidirectional language model task, it would likely not have many issues compared to BERT.Of course, even so, GPT is still an excellent piece of work, though its authors’ promotional abilities need improvement compared to BERT.
The Birth of BERT
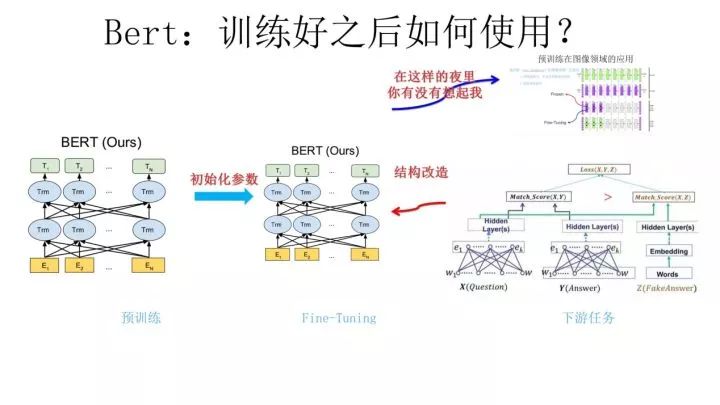
After a long journey, we finally arrive at the BERT model.
BERT adopts the same two-stage model as GPT: first, pre-training with a language model; second, using the Fine-Tuning model to solve downstream tasks.The main difference from GPT is that during the pre-training phase, it employs a bidirectional language model similar to ELMO, and the data scale for the language model is larger than that of GPT.Thus, there is no need to elaborate on BERT’s pre-training process.
In the second stage, the Fine-Tuning phase, the approach is the same as GPT. However, it also faces the issue of modifying the network structure for downstream tasks, and BERT has some differences from GPT in this regard, which I will briefly introduce below.
Before introducing how BERT modifies downstream tasks, let’s briefly discuss the various types of NLP problems to emphasize the universality of BERT.Generally speaking, most NLP problems can be classified into the four categories shown in the above image:one is sequence labeling, which is the most typical NLP task, such as Chinese word segmentation, part-of-speech tagging, named entity recognition, and semantic role labeling. It requires the model to provide a classification category for each word in the sentence based on the context.The second category is classification tasks, such as common text classification and sentiment analysis. For these tasks, regardless of how long the article is, a single classification category needs to be provided.The third category is sentence relationship judgment, such as entailment, QA, semantic rewriting, and natural language inference tasks. This pattern requires the model to determine whether two sentences have a certain semantic relationship.The fourth category is generative tasks, such as machine translation, text summarization, poetry writing, and image captioning. The characteristic of this category is that after inputting text content, it needs to generate another piece of text autonomously.
For such a diverse range of NLP tasks with distinct characteristics, how does BERT modify the input and output parts so that most NLP tasks can utilize the pre-trained model parameters of BERT? The above image provides examples: for sentence relationship tasks, it is quite simple; similar to GPT, just add a start and end symbol, and for the sentences, add a separator. For the output, simply connect a softmax classification layer to the last layer of the Transformer corresponding to the first start symbol. For classification problems, like GPT, you only need to add start and end symbols, and the output part can be modified similarly to the sentence relationship judgment task.For sequence labeling tasks, the input part is the same as single-sentence classification, but the output part requires classification for each word position in the last layer of the Transformer.From this, we can see that BERT conveniently covers most of the NLP tasks listed above, except for generative tasks, and the modifications are quite simple and intuitive.Although the BERT paper does not mention this, it is easy to think that for generative tasks such as machine translation, text summarization, and chatbots, similar modifications can also be made to incorporate BERT’s pre-training results.It simply requires attaching to the S2S structure, where the encoder part is a deep Transformer structure, and the decoder part is also a deep Transformer structure. Different pre-training data can be selected to initialize the encoder and decoder based on the task.This is a very intuitive modification method.Regardless, it is evident that the four major NLP task categories can be conveniently modified to fit BERT’s requirements.This is a significant advantage of BERT, meaning it can handle almost any downstream NLP task and demonstrates strong universality.
How effective is BERT in solving various NLP tasks using this two-stage approach? It achieves the best results across 11 different types of NLP tasks, with some tasks showing significant performance improvements.Ultimately, the effectiveness of a new model is paramount.
At this point, we can summarize the evolutionary relationships between several models.From the above image, it can be seen that BERT is intricately connected with ELMO and GPT. For instance, if we replace the pre-training phase of GPT with a bidirectional language model, we would obtain BERT; similarly, if we replace ELMO’s feature extractor with a Transformer, we would also arrive at BERT.Thus, you can see that BERT’s two key aspects are: first, it uses the Transformer as the feature extractor; second, it employs a bidirectional language model during pre-training.
Now a new question arises: for the Transformer, how can a bidirectional language model task be performed on this structure? At first glance, this seems challenging.However, I believe there is an intuitive idea: how about looking at ELMO’s network structure diagram? We just need to replace the two LSTMs with two Transformers, one for forward and one for reverse feature extraction, and that should work.Of course, this is my own modification; BERT did not do it this way.So, how did BERT do it? Did I not mention Word2Vec earlier? I certainly did not mention it aimlessly; I brought it up to introduce the CBOW training method. The so-called foreshadowing in writing is like the “grass snake gray line, hidden pulse for thousands of miles”; this is roughly what I mean.Earlier, I mentioned the CBOW method, whose core idea is: during language model tasks, I remove the word to be predicted and use its preceding context and following context to predict the word.In fact, how does BERT operate? BERT does just that.This illustrates the inheritance relationship between methods.Of course, the authors of BERT did not mention Word2Vec or the CBOW method; this is my judgment. They claimed to be inspired by the cloze task, which is also likely, but I believe that if they had not thought of CBOW, it would be unlikely.
From here, it can be seen that at the beginning of the article, I mentioned that BERT does not have significant innovations in its model; it is more of a culmination of important technologies in NLP in recent years, and the reasons for this are as follows. Of course, I am not sure how you view this or whether you agree with this perspective, and I am not concerned about your views.In fact, the effectiveness of BERT and its strong universality are its greatest highlights.
So, what innovations does BERT have from the perspective of model and method? These are the Masked language model and Next Sentence Prediction mentioned in the paper.As for the Masked language model, I have already explained that its essence is actually CBOW, but the details have been improved.
The Masked bidirectional language model operates as shown in the above diagram: 15% of the words in the corpus are randomly selected and removed, replaced by the [Mask] tag, and the model is required to correctly predict the removed word.However, there is a problem: during the training process, the model sees a lot of [mask] tags, but when it is actually used later, this tag will not be present. This could mislead the model into thinking that the output is aimed at the [mask] tag, which is problematic.To avoid this issue, BERT made a modification: among the 15% of selected words, only 80% are actually replaced with the [mask] tag, 10% are randomly replaced with another word, and in 10% of cases, the word remains unchanged.This is the specific approach of the Masked bidirectional language model.
As for the “Next Sentence Prediction”, it refers to the process of selecting two sentences during the pre-training of the language model. One is to select two sentences that are truly sequentially connected from the corpus; the other is to randomly select a second sentence from the corpus and attach it to the first sentence.We require the model to perform the previously mentioned Masked language model task while also predicting the relationship between the two sentences, determining whether the second sentence is truly a continuation of the first sentence.This is done because many NLP tasks are sentence relationship judgment tasks, and training at the word prediction level does not reach the sentence relationship level. Adding this task helps with downstream sentence relationship judgment tasks.Thus, it can be seen that its pre-training is a multi-task process.This is also an innovation of BERT.
The above image provides an example of a Chinese training instance randomly extracted when we used Weibo data and open-source BERT for pre-training, allowing us to experience the masked language model and next sentence prediction tasks.The training data looks like this.
Additionally, I will explain BERT’s input part, which is also somewhat unique.Its input is a linear sequence where two sentences are separated by a delimiter, with two identifier symbols added at the beginning and end. Each word has three embeddings: positional embedding, which is important in NLP because the order of words is a critical feature that needs to be encoded; word embedding, which is what we have been discussing; the third is sentence embedding, as the training data consists of two sentences, each sentence has an overall embedding corresponding to each word.By adding the three embeddings corresponding to each word, we form BERT’s input.
As for how BERT organizes the output during pre-training, you can refer to the annotations in the above image.
We have mentioned that BERT is particularly effective. So what factors contribute to this? As shown in the above image, comparative experiments have proven that the bidirectional language model plays the most significant role, especially for tasks that require considering the following context.In contrast, predicting the next sentence does not have as much impact on overall performance and is more closely related to specific tasks.
Finally, I would like to share my evaluation and views on BERT. I believe that BERT is a milestone work in NLP that will have a lasting impact on subsequent NLP research and industrial applications, which is beyond doubt.However, as mentioned above, it can be seen that from the perspective of models or methods, BERT borrows from ELMO, GPT, and CBOW, mainly proposing the Masked language model and Next Sentence Prediction. However, the Next Sentence Prediction does not fundamentally affect the overall situation, while the Masked LM clearly borrows from the idea of CBOW.Thus, it can be said that BERT’s model does not have significant innovations; it is more of a culmination of important advancements in NLP in recent years. If you understand the above text, you probably won’t have much disagreement with this viewpoint. If you have strong disagreement, I am always ready to wear the hat of a nitpicker.To summarize these advancements: First, the two-stage model, where the first stage involves pre-training the bidirectional language model, which is crucial to use bidirectional rather than unidirectional; the second stage involves fine-tuning for specific tasks or feature integration; second, the feature extractor must use the Transformer as the feature extractor rather than RNN or CNN; third, the bidirectional language model can adopt the CBOW method (though I consider this a detail and not particularly critical; the first two factors are more crucial).BERT’s greatest highlights are its strong effectiveness and universality, as it can be applied to almost all NLP tasks, and its effectiveness is expected to show significant improvement.It can be anticipated that in the NLP application field, the Transformer will dominate for a while, and this two-stage pre-training method will also lead various applications.
That’s it; this is the history of the development of natural language model pre-training.
Previous Highlights:
100 Questions in Deep Learning – 8: What is Batch Normalization?
100 Questions in Deep Learning – 7: What Detailed Issues Are There with Dropout?
100 Questions in Deep Learning – 6: What Classic Types of Convolutions Are There?
100 Questions in Deep Learning – 5: How to Read a Deep Learning Project Code?
100 Questions in Deep Learning – 4: What Reading Routes Should Be Followed for Deep Learning Papers?
100 Questions in Deep Learning – 3: What Linux Development Skills Should Be Mastered in Deep Learning?
100 Questions in Deep Learning – 2: What Git Development Skills Should Be Mastered in Deep Learning?
100 Questions in Deep Learning – 1: What Pits Are There in Deep Learning Environment Configuration?

A Growth Journey of an Algorithm Engineer


Long press the QR code to follow the Machine Learning Laboratory
