
I’ve been looking at word2vec for a long time, but I’ve found many different versions of explanations. Moreover, the original paper does not mention many details, so I plan to look at the source code directly. On one hand, it can deepen my understanding; on the other hand, I can make appropriate improvements in the future!
First, here is the flowchart of the execution process in the source code, which will be interpreted in detail according to this flowchart:

The flowchart for the training part is as follows:
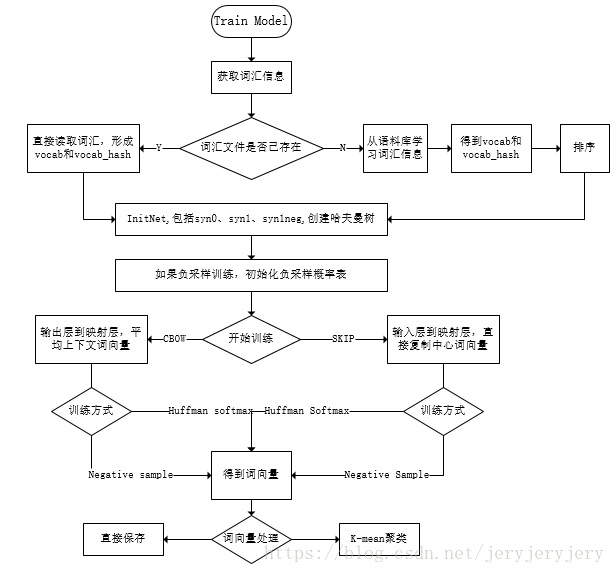
The explanation will follow this training process!
1. Training Parameters
Note that these parameters are all global parameters, including the following parameters:
-
size: Corresponds to layer1_size in the code, indicating the dimension of the word vector, default value is 100. -
train: Corresponds to train_file in the code, indicating the path of the corpus file. -
save-vocab: Corresponds to save_vocab_file in the code, the path to save the vocabulary. -
read-vocab: Corresponds to read_vocab_file in the code, indicating the path of the existing vocabulary file, read directly without learning from the corpus. -
debug: Corresponds to debug_mode in the code, indicating whether to choose the debug model, value greater than 1 indicates on, default is 2. Turning on debug will print some information. -
binary: Corresponds to the global variable binary in the code, indicating the file saving method, 1 indicates binary saving, 0 indicates text saving, default is 0. -
cbow: Corresponds to cbow in the code, 1 indicates training using the cbow model, 0 indicates training using the skip model, default is 1. -
alpha: Corresponds to alpha in the code, indicating the learning rate. The default for the skip model is 0.025, and for the cbow model, it is 0.05. -
output: Corresponds to output_file in the code, indicating the path to save the word vectors. -
window: Corresponds to window in the code, indicating the size of the training window. Default is 5. -
sample: Corresponds to sample in the code, indicating the down-sampling threshold. -
hs: Corresponds to hs in the code, indicating training using the Huffman softmax mode. Default is 0, indicating that hs is not used. -
negative: Corresponds to negative in the code, indicating training using negative sampling mode, default is 5. A value of 0 indicates no negative sampling training; if used, the value is generally between 3 and 10. -
threads: Corresponds to num_threads in the code, the number of training threads, generally 12. -
iter: Corresponds to iter in the code, the number of training iterations, default is 5. -
min-count: Corresponds to min_count in the code, indicating the minimum occurrence frequency, words below this frequency will be removed from the vocabulary. Default value is 5. -
classes: Corresponds to classes in the code, indicating the number of clustering centers, default is 0, indicating clustering is not enabled.
All of the above parameters correspond to some global variables in the code, for specific meanings of global variables, refer to the above parameter descriptions!
2. Pre-generating expTable
In the process of word2vec calculation, whether predicting the center word using context or predicting context using the center word, predictions need to be made; and the prediction method used in word2vec is logistic regression classification, which requires the sigmoid function. The specific function form is:
During training, a large number of sigmoid value calculations are needed. If the value of exex is calculated temporarily every time, it will affect performance; when the accuracy requirement is not very strict, we can use approximate calculations. In word2vec, the interval 「[-MAX_EXP, MAX_EXP]」 (the default value of MAX_EXP in the code is 6) is evenly divided into 「EXP_TABLE_SIZE」 parts, and the sigmoid values of each interval are precomputed and stored in expTable. When needed, we only need to determine which interval it belongs to and directly look it up in the array. The initialization code for 「expTable」 is as follows:
expTable = (real *)malloc((EXP_TABLE_SIZE + 1) * sizeof(real)); // Initialize expTable, approximate sigmoid(x) values, x interval is [-MAX_EXP, MAX_EXP], divided into EXP_TABLE_SIZE parts
// Divide [-MAX_EXP, MAX_EXP] into EXP_TABLE_SIZE parts
for (i = 0; i < EXP_TABLE_SIZE; i++) {
expTable[i] = exp((i / (real)EXP_TABLE_SIZE * 2 - 1) * MAX_EXP); // Precompute the exp() table
expTable[i] = expTable[i] / (expTable[i] + 1); // Precompute f(x) = x / (x + 1)
}
3. Building the Vocabulary
During the process of building the vocabulary, first check whether there is a ready-made vocabulary. If there is, read it directly; if not, proceed with training.
「Vocabulary Training Process」 is divided into the following steps: 「1. Read a word」, 「2. Calculate the hash value corresponding to the word」, 「3. Get the index of the word in the vocabulary through the hash value」, 「4. Add the word to the vocabulary」, 「5. Sort the vocabulary in descending order based on word frequency」, 「6. Save the trained vocabulary」. The following introduces the above steps one by one. First, here is the 「structure」 corresponding to each word in the vocabulary:
// Structure corresponding to each word in the vocabulary
struct vocab_word {
long long cn; // Word frequency
int *point; // Records the index of the parent node in the Huffman tree, from top to bottom
char *word, *code; // word represents the word; code represents the Huffman encoding table, records whether the parent node is a left node or a right node
char codelen; // Length of the code table
};
「1. Read a word corresponding code」
// Reads a single word from a file, assuming space + tab + EOL to be word boundaries
// Read a single word from the file, assuming words are separated by space or tab or EOL
void ReadWord(char *word, FILE *fin) {
int a = 0, ch;
while (!feof(fin)) {
ch = fgetc(fin); // Read a word
if (ch == 13) continue; // If it is a newline character
if ((ch == ' ') || (ch == '\t') || (ch == '\n')) { // Represents the end boundary of a word
if (a > 0) { // If a word has been read but encountered a newline character,
if (ch == '\n') ungetc(ch, fin); // Return to the stream
break;
}
if (ch == '\n') { // Only read a newline character
strcpy(word, (char *)"</s>"); // Assign </s> to word
return;
} else continue;
}
word[a] = ch;
a++;
if (a >= MAX_STRING - 1) a--; // Truncate too long words // Truncate
}
word[a] = 0; // The last character is '\0'
}
「2. Calculate the hash value corresponding to the word」
// Returns hash value of a word
// Returns a hash value corresponding to a word
int GetWordHash(char *word) {
unsigned long long a, hash = 0;
for (a = 0; a < strlen(word); a++) hash = hash * 257 + word[a];
hash = hash % vocab_hash_size;
return hash;
}
「3. Get the index of the word in the vocabulary using the hash value」 uses open addressing method, for more information on open addressing method, refer to here.
// Open addressing method to get the position of the word
int SearchVocab(char *word) {
unsigned int hash = GetWordHash(word); // Get the index
while (1) {
if (vocab_hash[hash] == -1) return -1;
if (!strcmp(word, vocab[vocab_hash[hash]].word)) return vocab_hash[hash];
hash = (hash + 1) % vocab_hash_size; // Open addressing method
}
return -1;
}
In word2vec, the 「ReadWordIndex() function」 directly integrates steps 1, 2, and 3, the code is as follows:
// Reads a word and returns its index in the vocabulary
int ReadWordIndex(FILE *fin) {
char word[MAX_STRING];
ReadWord(word, fin); // Read a word from the file stream
if (feof(fin)) return -1;
return SearchVocab(word); // Return the index in the vocabulary
}
「4. Add the word to the vocabulary」
// Adds a word to the vocabulary
// Add word to the vocabulary
int AddWordToVocab(char *word) {
unsigned int hash, length = strlen(word) + 1;
if (length > MAX_STRING) length = MAX_STRING; // Specify that each word does not exceed MAX_STRING characters
vocab[vocab_size].word = (char *)calloc(length, sizeof(char));
strcpy(vocab[vocab_size].word, word); // Structure word
vocab[vocab_size].cn = 0;
vocab_size++;
// Reallocate memory if needed // Dynamically expand memory
if (vocab_size + 2 >= vocab_max_size) {
vocab_max_size += 1000; // Increase vocabulary size by 1000
vocab = (struct vocab_word *)realloc(vocab, vocab_max_size * sizeof(struct vocab_word));
}
hash = GetWordHash(word);
while (vocab_hash[hash] != -1) hash = (hash + 1) % vocab_hash_size; // Get the actual hash value corresponding to the word
vocab_hash[hash] = vocab_size - 1; // Get the index of the word in vocab through hash value
return vocab_size - 1; // Return the index corresponding to the word
}
「5. Sort the vocabulary」 Sorting requires first defining a comparator, here a descending order comparator is constructed, the code is as follows:
// Used later for sorting by word counts
// Construct a comparator for sorting, descending order
int VocabCompare(const void *a, const void *b) {
return ((struct vocab_word *)b)->cn - ((struct vocab_word *)a)->cn;
}
// Sorts the vocabulary by frequency using word counts
void SortVocab() {
int a, size;
unsigned int hash;
// Sort the vocabulary and keep </s> at the first position
qsort(&vocab[1], vocab_size - 1, sizeof(struct vocab_word), VocabCompare);
for (a = 0; a < vocab_hash_size; a++) vocab_hash[a] = -1;
size = vocab_size;
train_words = 0;
for (a = 0; a < size; a++) {
// Words occurring less than min_count times will be discarded from the vocab
// Words with frequency lower than a certain level will be discarded
if ((vocab[a].cn < min_count) && (a != 0)) {
vocab_size--;
free(vocab[a].word);
} else {
// Hash will be re-computed, as after the sorting it is not actual
// Because the order is disrupted after sorting, the hash value will be recalculated
hash=GetWordHash(vocab[a].word);
while (vocab_hash[hash] != -1) hash = (hash + 1) % vocab_hash_size;
vocab_hash[hash] = a;
train_words += vocab[a].cn;
}
}
// Reallocate memory size
vocab = (struct vocab_word *)realloc(vocab, (vocab_size + 1) * sizeof(struct vocab_word));
// Allocate memory for the binary tree construction
for (a = 0; a < vocab_size; a++) {
vocab[a].code = (char *)calloc(MAX_CODE_LENGTH, sizeof(char));
vocab[a].point = (int *)calloc(MAX_CODE_LENGTH, sizeof(int));
}
}
「6. Save the trained vocabulary」
// Save the learned vocabulary file
void SaveVocab() {
long long i;
FILE *fo = fopen(save_vocab_file, "wb");
for (i = 0; i < vocab_size; i++)
fprintf(fo, "%s %lld\n", vocab[i].word, vocab[i].cn); // Save word and frequency
fclose(fo);
}
There is also a vocabulary pruning function in the code. When the vocabulary size exceeds a certain value, pruning will be performed, first removing words with low frequency, then pruning words with high frequency until the vocabulary size meets the requirements, the code is as follows:
// Reduces the vocabulary by removing infrequent tokens
// Words with frequency less than min_reduce will be pruned
void ReduceVocab() {
int a, b = 0;
unsigned int hash;
// Only an array is used to achieve the pruning process
for (a = 0; a < vocab_size; a++) if (vocab[a].cn > min_reduce) {
vocab[b].cn = vocab[a].cn;
vocab[b].word = vocab[a].word;
b++;
} else free(vocab[a].word);
vocab_size = b;
// Re-set hash values
for (a = 0; a < vocab_hash_size; a++) vocab_hash[a] = -1;
for (a = 0; a < vocab_size; a++) {
// Hash will be re-computed, as it is not actual
hash = GetWordHash(vocab[a].word);
while (vocab_hash[hash] != -1) hash = (hash + 1) % vocab_hash_size;
vocab_hash[hash] = a;
}
fflush(stdout);
min_reduce++; // The minimum frequency number will be increased after each pruning
}
If there is already a trained vocabulary, it can be read directly without learning from the corpus, the code is as follows:
// Read directly from the existing vocabulary file, no need to learn temporarily
void ReadVocab() {
long long a, i = 0;
char c;
char word[MAX_STRING];
FILE *fin = fopen(read_vocab_file, "rb");
if (fin == NULL) { // Check if the file exists
printf("Vocabulary file not found\n");
exit(1);
}
for (a = 0; a < vocab_hash_size; a++) vocab_hash[a] = -1; // Default vocab_hash values are -1
vocab_size = 0;
while (1) { // Keep reading until the end of the file
ReadWord(word, fin); // Read a single word from the file stream into word
if (feof(fin)) break;
a = AddWordToVocab(word); // Add the word to the vocabulary
fscanf(fin, "%lld%c", &vocab[a].cn, &c); // Read frequency into vocav.cn, newline character
i++;
}
SortVocab();
if (debug_mode > 0) {
printf("Vocab size: %lld\n", vocab_size);
printf("Words in train file: %lld\n", train_words);
}
fin = fopen(train_file, "rb");
if (fin == NULL) {
printf("ERROR: training data file not found!\n");
exit(1);
}
fseek(fin, 0, SEEK_END); // Position the reading pointer at the end of the file
file_size = ftell(fin); // Get the offset from the head, retrieve the file size
fclose(fin);
}
The vocabulary generation process is completed by the 「LearnVocabFromTrainFile() function」 which integrates the above steps, the code is as follows:
// Integrate the file operations above
void LearnVocabFromTrainFile() {
char word[MAX_STRING];
FILE *fin;
long long a, i;
for (a = 0; a < vocab_hash_size; a++) vocab_hash[a] = -1; // Initial hash values are -1
fin = fopen(train_file, "rb");
if (fin == NULL) {
printf("ERROR: training data file not found!\n");
exit(1);
}
vocab_size = 0;
AddWordToVocab((char *)"</s>"); // Add '</s>' to the vocabulary, newline character is represented by this
while (1) {
ReadWord(word, fin);
if (feof(fin)) break;
train_words++;
if ((debug_mode > 1) && (train_words % 100000 == 0)) {
printf("%lldK%c", train_words / 1000, 13);
fflush(stdout);
}
i = SearchVocab(word); // Find the position of the word
if (i == -1) { // If not added to the vocabulary
a = AddWordToVocab(word);
vocab[a].cn = 1;
} else vocab[i].cn++; // Already added to the vocabulary
if (vocab_size > vocab_hash_size * 0.7) ReduceVocab(); // Pruning words operation
}
SortVocab(); // Sorting
if (debug_mode > 0) {
printf("Vocab size: %lld\n", vocab_size);
printf("Words in train file: %lld\n", train_words);
}
file_size = ftell(fin);
fclose(fin);
}
4. Initializing the Network
Initializing the network includes the following processes: 「1. Initialize network parameters」, 「2. Construct the Huffman tree」, 「3. Initialize negative sampling probability table」.
1. Initialize network parameters
The parameters in the network mainly include 「syn0, syn1 and syn1neg」.
syn0: The word vectors we need, represented by a one-dimensional array of type real(float) in the source code, note that it is a one-dimensional array!
The capacity size is vocab_size * layer1_size, i.e., vocabulary size * word vector dimension.
syn1: The Huffman tree, including leaf nodes and non-leaf nodes. The leaf nodes correspond to words in the vocabulary, while non-leaf nodes are the path nodes generated during the construction of the Huffman tree.
syn1 represents the vectors of non-leaf nodes in the Huffman tree, which have the same dimension as word vectors, with a total of (n-1) non-leaf nodes,
where n represents the number of words in the vocabulary. Note that syn1 is also a one-dimensional real(float) array, with a capacity of vocab_size * layer1_size.
syn1neg: This is another vector representation of the word. Previously, it was mentioned in Stanford's natural language processing video that each word will train two vectors, and now it indeed seems to be the case,
but this vector is needed for optimization during negative sampling. It is also a one-dimensional float array, with a size of vocab_size * layer1_size.123456789
The initialization code is as follows:
// Initialize the network
void InitNet() {
long long a, b;
unsigned long long next_random = 1;
// Allocate memory for syn0, aligned memory, size is vocab_size * layer1_size * sizeof(real), that is, each vocabulary corresponds to a layer1_size vector
a = posix_memalign((void **)&syn0, 128, (long long)vocab_size * layer1_size * sizeof(real));
if (syn0 == NULL) {printf("Memory allocation failed\n"); exit(1);}
// If using Huffman softmax construction, then syn1 needs to be initialized, size is vocab_size * layer1_size * sizeof(real), each word corresponds to one
if (hs) {
a = posix_memalign((void **)&syn1, 128, (long long)vocab_size * layer1_size * sizeof(real));
if (syn1 == NULL) {printf("Memory allocation failed\n"); exit(1);}
for (a = 0; a < vocab_size; a++) for (b = 0; b < layer1_size; b++)
syn1[a * layer1_size + b] = 0;
}
// If using negative sampling for training, then syn1neg needs to be initialized, size is vocab_size * layer1_size * sizeof(real), each word corresponds to one
if (negative>0) {
a = posix_memalign((void **)&syn1neg, 128, (long long)vocab_size * layer1_size * sizeof(real));
if (syn1neg == NULL) {printf("Memory allocation failed\n"); exit(1);}
for (a = 0; a < vocab_size; a++) for (b = 0; b < layer1_size; b++)
syn1neg[a * layer1_size + b] = 0;
}
// Initialize the word vectors corresponding to each word in syn0
for (a = 0; a < vocab_size; a++) for (b = 0; b < layer1_size; b++) {
next_random = next_random * (unsigned long long)25214903917 + 11; // Generate a large number
syn0[a * layer1_size + b] = (((next_random & 0xFFFF) / (real)65536) - 0.5) / layer1_size;//& 0xFFFF indicates truncation to [0, 65536]
}
// Construct the Huffman tree needed for Huffman softmax
CreateBinaryTree();
}
The range of each value in syn0 is: [-0.5m, 0.5m][−0.5m, 0.5m], where m represents the vector dimension; syn1 is initialized to 0; syn1neg is also initialized to 0.
2. Constructing the Huffman Tree
// Create binary Huffman tree using the word counts
// Frequent words will have short unique binary codes
void CreateBinaryTree() {
long long a, b, i, min1i, min2i, pos1, pos2, point[MAX_CODE_LENGTH];
char code[MAX_CODE_LENGTH];
// The allocated space size is (vocab_size * 2 + 1) * sizeof(long long), because of the characteristic of the Huffman tree, the total number of nodes is 2 * n + 1, where n is the number of nodes, there should be an error here, it should be 2 * n - 1
long long *count = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); // Frequency corresponding to each node
long long *binary = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); // Record whether each node is a left node or a right node
long long *parent_node = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); // Parent node position
for (a = 0; a < vocab_size; a++) count[a] = vocab[a].cn;
// Set the rest to infinity
for (a = vocab_size; a < vocab_size * 2; a++) count[a] = 1e15;
pos1 = vocab_size - 1;
pos2 = vocab_size;
// Following algorithm constructs the Huffman tree by adding one node at a time
// Like a genius code, the Huffman tree is constructed in one pass, ## Note, this a also represents an order, all count values are sorted in ascending order ##
for (a = 0; a < vocab_size - 1; a++) {
// First, find two smallest nodes 'min1, min2', note that the words in vocab are already sorted by cn, in descending order
// pos1 indicates the frequency corresponding to the original word, while pos2 indicates the frequency formed by merging the minimum values
// Take two smallest values consecutively, the code operation is exactly the same for both times
if (pos1 >= 0) {
if (count[pos1] < count[pos2]) {
min1i = pos1;
pos1--;
} else {
min1i = pos2;
pos2++;
}
} else {
min1i = pos2;
pos2++;
}
if (pos1 >= 0) {
if (count[pos1] < count[pos2]) {
min2i = pos1;
pos1--;
} else {
min2i = pos2;
pos2++;
}
} else {
min2i = pos2;
pos2++;
}
count[vocab_size + a] = count[min1i] + count[min2i];
parent_node[min1i] = vocab_size + a; // Record the position of the merged parent node
parent_node[min2i] = vocab_size + a;
binary[min2i] = 1; // Left is 0, right is 1
}
// Now assign binary code to each vocabulary word
// After the Huffman tree is built, the code values need to be assigned. Note that this Huffman tree is stored using an array, not the linked list we commonly use
for (a = 0; a < vocab_size; a++) {
b = a;
i = 0;
while (1) {
code[i] = binary[b]; // For each node, get the code value from bottom to top, realized by each node's binary
point[i] = b; // Point records the path of nodes to the root node
i++;
b = parent_node[b];
if (b == vocab_size * 2 - 2) break;
}
vocab[a].codelen = i; // Record the length of the code corresponding to the word
vocab[a].point[0] = vocab_size - 2; // The maximum value is the root node
for (b = 0; b < i; b++) {
vocab[a].code[i - b - 1] = code[b]; // Reverse, from top to bottom
vocab[a].point[i - b] = point[b] - vocab_size; // Note that this index corresponds to the non-leaf nodes in the Huffman tree, corresponding to the index in syn1, because non-leaf nodes are in the latter (vocab_size + 1) positions of vocab_size * 2 + 1
}
}
free(count);
free(binary);
free(parent_node);
}
What concise and brilliant code. 「It mainly utilizes the order of the vocabulary, which is sorted in descending order. Therefore, initially, pos1 = vocab_size – 1 is the word with the smallest frequency in the original vocabulary. Each time two minimum values are merged, we place the newly generated node in the latter vocab-size + 1 positions, and also fill it in order, so the final count array representing the Huffman tree has a characteristic of increasing values from the center to both ends. Therefore, each time we take the minimum value, we only need to compare which end has the smallest current value to get the two minimum values.」
3. Initializing the Negative Sampling Probability Table
If the negative sampling method is used, at this time, it is also necessary to initialize the probability of selecting each word. In the vocabulary composed of all words, each word has varying frequencies. We hope that 「for those high-frequency words, the probability of being selected as negative samples should be higher, while for those low-frequency words, we hope their probability of being selected as negative samples should be lower」.
// Generate negative sampling probability table
void InitUnigramTable() {
int a, i;
double train_words_pow = 0;
double d1, power = 0.75;
table = (int *)malloc(table_size * sizeof(int));
// pow(x, y) calculates x to the power of y; train_words_pow represents the total probability of words, not directly using the frequency of each word, but the frequency raised to the 0.75 power
for (a = 0; a < vocab_size; a++) train_words_pow += pow(vocab[a].cn, power);
i = 0;
d1 = pow(vocab[i].cn, power) / train_words_pow;
// Each word occupies a different number of slots in the table, obviously, high-frequency words occupy more slots
for (a = 0; a < table_size; a++) {
table[a] = i;
if (a / (double)table_size > d1) {
i++;
d1 += pow(vocab[i].cn, power) / train_words_pow;
}
if (i >= vocab_size) i = vocab_size - 1;
}
}
5. Model Training
Regarding the principles of the CBOW and SKIP models of word2vec, I strongly recommend the great blog explanation. Although there are errors in details, the overall idea is correct. First, several important variables are defined, the variable explanations are as follows:
last_word: The index of the word currently being trained in the window.
sentence_length: The length of the current training sentence.
sentence_position: The position of the current center word in the sentence.
sen: An array that stores the index of each word in the sentence in the vocabulary.
neu1: The context vector representation corresponding to the mapping layer in the cbow mode, which is the average of all word vectors in the context.
neu1e: Because in the skip mode, the mapping layer vector is just a copy of the input layer vector, so neu1e is only used to record the gradients of the context words to the input layer.123456
Each time a sentence is read, the index of each word in the sentence is recorded. If down-sampling is enabled, some words will be randomly skipped, discarding frequent words while maintaining the order. The code is as follows:
if (sentence_length == 0) {
while (1) {
word = ReadWordIndex(fi); // Get the index corresponding to the word in the vocabulary
if (feof(fi)) break; //
if (word == -1) continue;
word_count++; // Total occurrences of the sentence
if (word == 0) break; // If encountering a newline character, jump out directly, the first word '</s>' represents a newline character
// The subsampling randomly discards frequent words while keeping the ranking same
// Down-sampling randomly discards frequent words while maintaining the ranking same
if (sample > 0) {
real ran = (sqrt(vocab[word].cn / (sample * train_words)) + 1) * (sample * train_words) / vocab[word].cn;
next_random = next_random * (unsigned long long)25214903917 + 11;
// The larger the frequency of the word, the smaller the corresponding ran, making it easier to be discarded and skipped
if (ran < (next_random & 0xFFFF) / (real)65536) continue;
}
sen[sentence_length] = word; // The words included in the current sentence, storing the index
sentence_length++; // Actual length of the sentence, minus the skipped words
if (sentence_length >= MAX_SENTENCE_LENGTH) break;
}
sentence_position = 0;
}123456789101112131415161718192021
Then the training begins, first initializing neu1 and neu1e values. The starting position of the window is determined by b = next_random % window, 「In theory, we take a total of window context words on both sides of the center word, but in the code, it does not guarantee that both sides are exactly window words, but rather left is (window – b) words, and right is (window + b) words, the total is still 2 * window words. 「During training, there are two training models, namely the CBOW model and the SKIP model; for each model, there are two training modes, namely the Huffman softmax mode (hs) and the negative mode (negative sampling)」, which will be explained below.
1. CBOW Model
In the CBOW model, there are a total of three layers: 「input layer, mapping layer, and output layer」. As shown in the figure below:
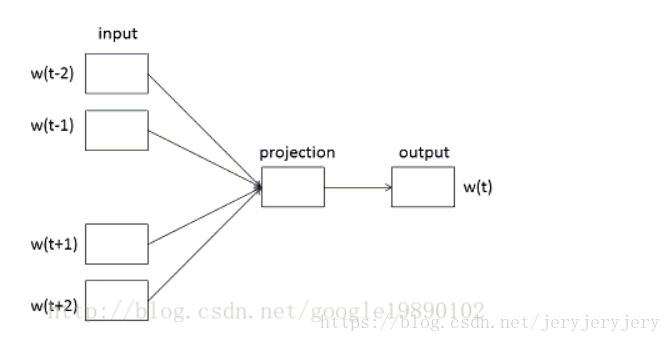
In hs mode and negative mode, the processing from the input layer to the mapping layer is the same, only the processing from the mapping layer to the output layer is inconsistent. The specific operation from the input layer to the mapping layer is: **Sum the vectors of each word in the context window, then average them to get a vector with the same dimension as the word vector, assumed to be the context vector, this vector is the vector of the mapping layer.** The code is as follows:
if (cbow) { // Train the cbow architecture
// in -> hidden
cw = 0;
// Randomly select a word, then calculate the sum of the corresponding vectors of the context words
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c]; // Get the index of the c-th word in the sentence
if (last_word == -1) continue;
// Note that syn0 is a one-dimensional array, not a two-dimensional one, so the position of the corresponding vector of a word is located by last_word * layer1_size, where last_word represents the previous word in the context
for (c = 0; c < layer1_size; c++) neu1[c] += syn0[c + last_word * layer1_size]; // neu1 represents the mapping layer vector, context accumulates average
cw++;
}
if (cw) {
// Context representation is the average of all corresponding word vectors
for (c = 0; c < layer1_size; c++) neu1[c] /= cw;
......
}
......
}
1.1 hs mode
In Huffman softmax, the probability from the context vector to the center word is a series of binary classification problems, as it requires multiple decisions whether to go left or right from the root node to the leaf node corresponding to the center word. For the center word w, the total probability from the root node to the center word node is:
That is:
The log-likelihood function is:
where j indicates the indices of the non-leaf nodes passed from the root node to the center word w (the Huffman tree is stored in a one-dimensional array, and non-leaf nodes correspond to indices in the array), indicates the Huffman code corresponding to that non-leaf node, represents the context vector of the mapping layer, indicates the vector of the non-leaf node. Here, are variables, at this time, we take the partial derivatives of both:
Then:
The derivative can perform gradient ascent to find the maximum value. The implementation code is as follows:
if (hs) for (d = 0; d < vocab[word].codelen; d++) {
f = 0;
l2 = vocab[word].point[d] * layer1_size; // Offset to the position of the word in the array
// Propagate hidden -> output, propagation process
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2]; // Note that syn1 is also a one-dimensional array, the position corresponding to different words needs to be determined by the offset l2
if (f <= -MAX_EXP) continue; // When f value does not belong to [-MAX_EXP, MAX_EXP]
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]; // Check which part f belongs to, ((f + MAX_EXP) / (2 * MAX_EXP)) * EXP_TABLE_SIZE
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha; // Needs derivation, get this gradient ratio
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2]; // This part is the final gradient value
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c]; // Add the gradient value, update syn1
}
The code to update word vectors is as follows:
// hidden -> in
// Update the word vector of the input layer
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++)
syn0[c + last_word * layer1_size] += neu1e[c];
}
1.2 negative mode
In the negative sampling process, there is only one positive sample, which is the center word, while the other words are negative samples. The probabilities of all samples are multiplied to maximize. For a single sample u:
Then the sum of the probabilities of all samples is:
The log-likelihood function is:
That is:
where u indicates the randomly selected word sample, is the vector corresponding to that word sample, represents the context vector of the mapping layer, indicates whether word u is the current window center word w, 1 indicates yes, 0 indicates no. Represents the set of negative samples with respect to the center word w. Among them, and are variables, we take the partial derivatives of both:
Then
The derivative can perform gradient ascent to find the maximum value. The implementation code is as follows:
// NEGATIVE SAMPLING
if (negative > 0) for (d = 0; d < negative + 1; d++) {
if (d == 0) { // One positive sample
target = word;
label = 1;
} else {
next_random = next_random * (unsigned long long)25214903917 + 11; // Randomly select a negative sample, negative samples are all words except the center word
target = table[(next_random >> 16) % table_size];
if (target == 0) target = next_random % (vocab_size - 1) + 1; // If target is 0, this equation ensures it is not 0
if (target == word) continue; // If it is a positive sample, skip
label = 0;
}
l2 = target * layer1_size; // syn1neg is a one-dimensional array, a certain word needs to calculate the offset first
f = 0;
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1neg[c + l2]; // Negative sampling actually generates two vectors for each word
if (f > MAX_EXP) g = (label - 1) * alpha;
else if (f < -MAX_EXP) g = (label - 0) * alpha;
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2];
for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * syn0[c + l1];
}
「The code to update word vectors is as follows:」
// hidden -> in
// Update the word vector of the input layer
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c];
}
2. SKIP Model
In the skip model, there are also three layers: input layer, mapping layer, and output layer. The structure is as follows:
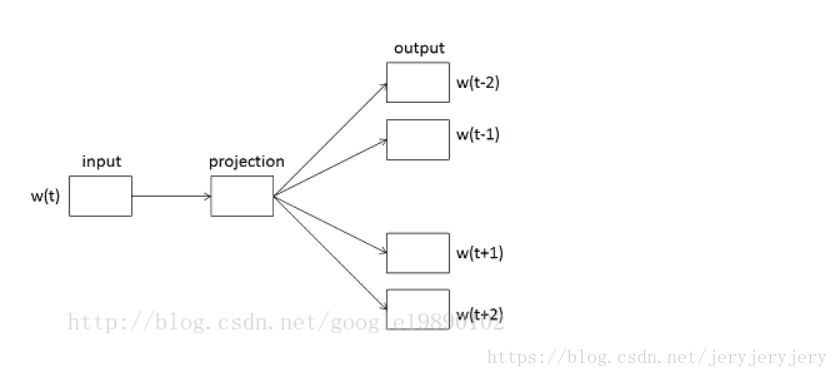
The optimization in the skip model is similar to that in the cbow model, mainly differing in the processing between the input layer and the mapping layer. 「In cbow, the context word vectors are averaged, while in the skip model, the center word vector is directly copied. In the skip model, the optimization process calculates the probability between the center word and context words individually, maximizing it, so the optimization calculations are basically similar to those in cbow」, the code is as follows:
else { // Train skip-gram
// Still ensure a context of size 2 * window, but the center word does not have to have exactly window words on both sides, determined by b
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a; // c indicates the current traversal position of the context
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c]; // Used to record the previous word
if (last_word == -1) continue; // If the word is not in the vocabulary, skip directly
l1 = last_word * layer1_size; // Offset, because syn0 is a one-dimensional array, the position corresponding to each word needs to be determined by the offset of the previous words
for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
// HIERARCHICAL SOFTMAX
// No need to average like cbow
if (hs) for (d = 0; d < vocab[word].codelen; d++) {
f = 0;
l2 = vocab[word].point[d] * layer1_size; //
// Propagate hidden -> output
for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1[c + l2];
if (f <= -MAX_EXP) continue;
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha;
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * syn0[c + l1];
}
// NEGATIVE SAMPLING
if (negative > 0) for (d = 0; d < negative + 1; d++) {
if (d == 0) { // Positive sample
target = word;
label = 1;
} else { // Negative sample
next_random = next_random * (unsigned long long)25214903917 + 11;
target = table[(next_random >> 16) % table_size];
if (target == 0) target = next_random % (vocab_size - 1) + 1;
if (target == word) continue;
label = 0;
}
l2 = target * layer1_size; // Offset
f = 0;
for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1neg[c + l2];
if (f > MAX_EXP) g = (label - 1) * alpha; // Calculate gradient
else if (f < -MAX_EXP) g = (label - 0) * alpha;
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2]; // Complete gradient
for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * syn0[c + l1];// Update
}
// Learn weights input -> hidden
// Update input layer weights
for (c = 0; c < layer1_size; c++) syn0[c + l1] += neu1e[c];
}
}
6. Result Processing
The results can be saved directly or analyzed using the k-means clustering algorithm, the code is as follows:
// Train the model
void TrainModel() {
long a, b, c, d;
FILE *fo;
pthread_t *pt = (pthread_t *)malloc(num_threads * sizeof(pthread_t));
printf("Starting training using file %s\n", train_file);
starting_alpha = alpha; // Set the learning rate
if (read_vocab_file[0] != 0) ReadVocab(); else LearnVocabFromTrainFile(); // Get the vocabulary, if already present read directly, else learn
if (save_vocab_file[0] != 0) SaveVocab();
if (output_file[0] == 0) return; // Must have output file parameter
InitNet(); // Initialize network parameters
if (negative > 0) InitUnigramTable(); // If negative sampling is used, then the negative sampling probability table
start = clock(); // Timer
for (a = 0; a < num_threads; a++) pthread_create(&pt[a], NULL, TrainModelThread, (void *)a);
for (a = 0; a < num_threads; a++) pthread_join(pt[a], NULL);
fo = fopen(output_file, "wb");
if (classes == 0) { // classes check whether to use kmean clustering, 0 means no
// Save the word vectors
fprintf(fo, "%lld %lld\n", vocab_size, layer1_size);
for (a = 0; a < vocab_size; a++) {
fprintf(fo, "%s ", vocab[a].word);
if (binary) for (b = 0; b < layer1_size; b++) fwrite(&syn0[a * layer1_size + b], sizeof(real), 1, fo);
else for (b = 0; b < layer1_size; b++) fprintf(fo, "%lf ", syn0[a * layer1_size + b]);
fprintf(fo, "\n");
}
} else {
// Run K-means on the word vectors
// Number of class centers, number of iterations,
int clcn = classes, iter = 10, closeid;
int *centcn = (int *)malloc(classes * sizeof(int)); // Number of words owned by each center point
int *cl = (int *)calloc(vocab_size, sizeof(int)); // Category labels for each word
real closev, x;
real *cent = (real *)calloc(classes * layer1_size, sizeof(real)); // Cluster centers, note that it is represented using a one-dimensional array, each center needs to be located using an offset
for (a = 0; a < vocab_size; a++) cl[a] = a % clcn; // Initialize the category of each word
for (a = 0; a < iter; a++) { // Start training
for (b = 0; b < clcn * layer1_size; b++) cent[b] = 0; // Initialize the position of the center points
for (b = 0; b < clcn; b++) centcn[b] = 1; // Initialize the number of words owned by each center point
// Calculate the total value of each center point for each dimension, equal to the corresponding dimensions of all words belonging to this category
for (c = 0; c < vocab_size; c++) {
for (d = 0; d < layer1_size; d++) cent[layer1_size * cl[c] + d] += syn0[c * layer1_size + d];
centcn[cl[c]]++; // Number of words included +1
}
// For each category, update the total value of each dimension of the center point, which is the average
for (b = 0; b < clcn; b++) {
closev = 0;
for (c = 0; c < layer1_size; c++) { // Traverse each dimension
cent[layer1_size * b + c] /= centcn[b]; // Average of each word for each dimension
closev += cent[layer1_size * b + c] * cent[layer1_size * b + c]; // Calculate the square of the modulus for each center point
}
closev = sqrt(closev); // Modulus of each center point
for (c = 0; c < layer1_size; c++) cent[layer1_size * b + c] /= closev; // Normalization processing
}
// Update the category to which each word belongs, depending on which center point is closest to assign it to the corresponding category
for (c = 0; c < vocab_size; c++) {
closev = -10; // Record the distance to the nearest center point
closeid = 0; // Record the ID of the nearest category
for (d = 0; d < clcn; d++) {
x = 0;
for (b = 0; b < layer1_size; b++) x += cent[layer1_size * d + b] * syn0[c * layer1_size + b];
if (x > closev) {
closev = x;
closeid = d;
}
}
cl[c] = closeid;
}
}
// Save the K-means classes
for (a = 0; a < vocab_size; a++) fprintf(fo, "%s %d\n", vocab[a].word, cl[a]);
free(centcn);
free(cent);
free(cl);
}
fclose(fo);
}
int ArgPos(char *str, int argc, char **argv) {
int a;
for (a = 1; a < argc; a++) if (!strcmp(str, argv[a])) {
if (a == argc - 1) {
printf("Argument missing for %s\n", str);
exit(1);
}
return a;
}
return -1;
}
Complete commented code: https://github.com/liuwei1206/word2vec/blob/master/word2vec%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90/word2vec.c
Reference blogs:
https://blog.csdn.net/itplus/article/details/37969979
https://blog.csdn.net/google19890102/article/details/51887344