A Survey of Query Optimization in Large Language Models
Paper Link:https://arxiv.org/pdf/2412.17558
Published by: Tencent
Large Language Models (LLMs) are becoming increasingly popular, but they also face challenges such as “hallucination” when dealing with domain-specific tasks or those requiring specialized knowledge. Retrieval-Augmented Generation (RAG) technology has emerged as a key method for enhancing model performance, with Query Optimization (QO) playing a central role. This paper provides a detailed overview and classification of query optimization techniques.
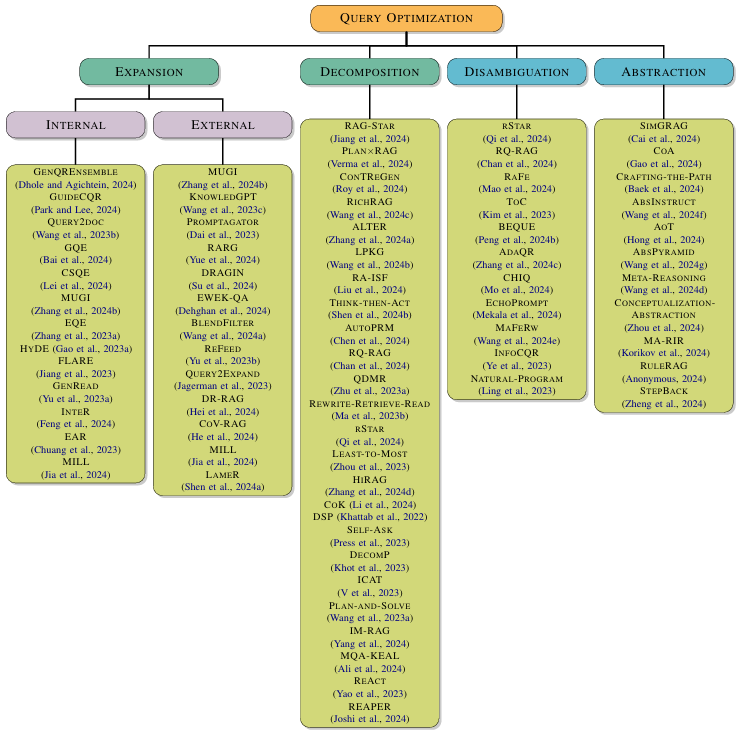
The following summarizes all the query optimization methods discussed in this paper. Each optimization method is backed by a paper, and more details can be found in the original text.
Summary:
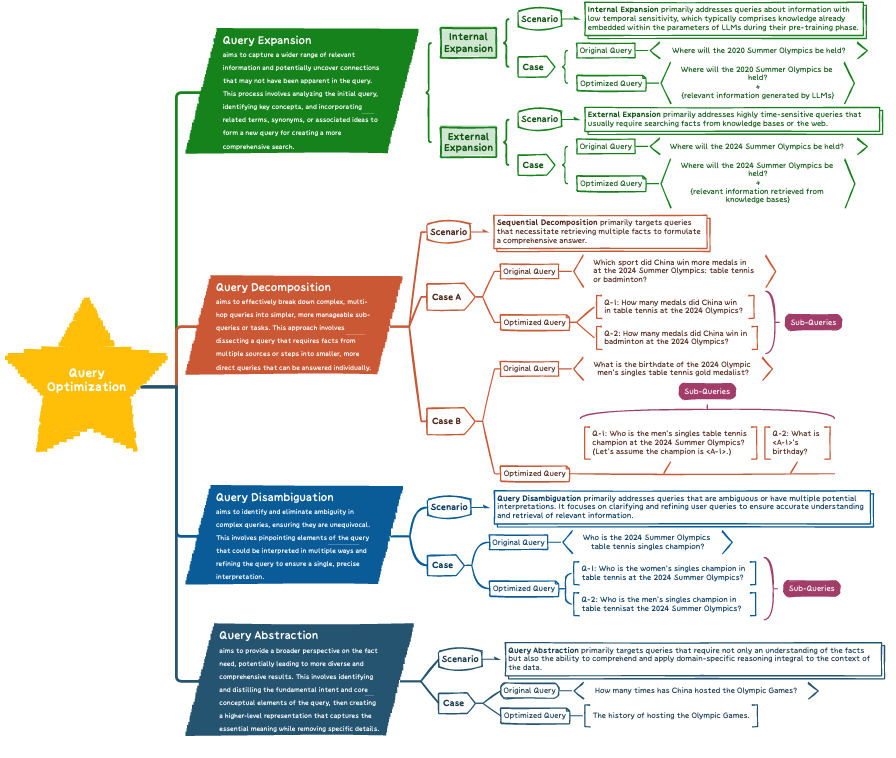
1. Query Expansion – Internal Expansion
● GENREAD: Utilizes designed instructions to prompt LLMs to generate contextual documents based on the initial query, which are then read by the LLM to produce the final response.
● QUERY2DOC: Generates pseudo-documents through few-shot prompting of LLMs to expand the original query, enhancing the performance of sparse and dense retrieval systems.
● REFEED: First generates initial outputs, then uses a retrieval model to fetch relevant information from a large document set, incorporating it into contextual examples to improve outputs.
● INTER: The retrieval model leverages the knowledge base generated by LLMs to expand knowledge within the query while the LLM optimizes prompts using retrieved documents, creating a collaborative loop.
● HYDE: Uses zero-shot prompting of language models to generate hypothetical documents, which are then encoded by an unsupervised contrastive encoder to identify similar real documents and filter out inaccurate content.
● FLARE: Predicts future content based on the original query and retrieves relevant information. If the generated temporary next sentence contains low confidence markers, it is treated as a new query for further retrieval.
● MILL: Leverages the zero-shot reasoning ability of LLMs to generate diverse sub-queries and corresponding documents, achieving optimal expansion and comprehensive retrieval through mutual verification.
● GENQRENSEMBLE: Employs ensemble-based prompting techniques to generate multiple sets of keywords using zero-shot instructions, enhancing retrieval effectiveness.
● ERRR: Extracts parameter knowledge from LLMs and refines queries using a dedicated query optimizer.
Summary:
2. Query Expansion – External Expansion
● LameR: Combines the query with potential answers to prompt LLMs, with potential answers obtained through standard retrieval procedures on the target set.
● GuideCQR: Optimizes queries using key information from the initial retrieval documents for conversational query reconstruction.
● CSQE: Facilitates the incorporation of knowledge from the corpus into queries, using the relevance assessment capabilities of LLMs to identify key sentences that expand queries.
● MUGI: Utilizes LLMs to generate multiple pseudo-references, combining them with the query to enhance the performance of sparse and dense retrievers.
Summary:
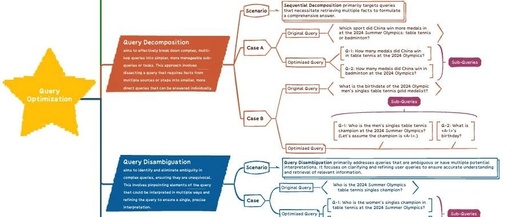
3. Problem Decomposition
● DSP: Passes natural language text between LLMs and retrieval models through complex pipelines, breaking down problems into smaller transformations for easier handling.
● LEAST – TO – MOST: Uses few-shot prompting to decompose complex problems into a series of simpler sub-problems, then solves them sequentially.
● PLAN – AND – SOLVE: Creates a plan that divides the entire task into smaller sub-tasks, then executes them according to the plan.
● SELF – ASK: Introduces the concept of combinatorial gap, emphasizing the challenges faced by models in integrating answers from sub-queries.
● EAR: Applies query expansion models to generate diverse queries, using query re-rankers to select queries that may yield better retrieval results.
● COK: First proposes and prepares preliminary reasoning and answers, identifies relevant knowledge areas, and if there is no consensus on the answer, gradually refines the reasoning.
● ICAT: Induces LLMs to decompose complex queries or generate step-by-step reasoning abilities from relevant task data sources without fine-tuning or manual labeling.
● REACT: Prompts LLMs to interleave generating verbal reasoning traces and actions, achieving dynamic reasoning and interaction with external environments.
● AUTOPRM: Breaks down complex problems into manageable sub-queries and then applies reinforcement learning to iteratively improve the sub-query solvers.
● RA – ISF: Iteratively processes sub-queries, combining text relevance and self-knowledge answering capabilities to mitigate the impact of irrelevant prompts.
● LPKG: Extracts instances based on predefined patterns in open-domain knowledge graphs, transforming complex queries and sub-queries into natural language, enhancing query planning capabilities.
● ALTER: Generates multiple sub-queries using question enhancers, examining the original question from different angles to handle complex table reasoning tasks.
● IM – RAG: Introduces a refiner to improve retrieval outputs, bridging the gap between the reasoning and information retrieval modules, facilitating multi-round communication.
● REAPER: Uses a single smaller LLM to generate plans containing tool calls, call sequences, and parameters for efficient retrieval of complex queries.
● HIRAG: Decomposes the original query into multi-hop queries, answering sub-queries based on retrieval knowledge, and then integrates answers using chain-of-thought methods.
● MQA – KEAL: Stores knowledge edits as structured knowledge units in external memory, iteratively querying external memory and/or target LLMs after decomposing multi-hop queries to generate final responses.
● RICHRAG: Introduces a sub-aspect explorer to analyze input queries, combining multi-faceted retrieval to fetch relevant documents for answering queries.
● CONTREGEN: Proposes a context-driven tree-based retrieval method to enhance the depth and relevance of retrieved content.
● PLAN×RAG: Constructs reasoning plans represented as directed acyclic graphs, decomposing the main query into relevant atomic sub-queries for information sharing.
● RAG – STAR: Integrates retrieval information to guide a tree-based cautious reasoning process, utilizing Monte Carlo tree search to plan intermediate sub-queries and generate answers.
Summary:
4. Query Disambiguation
● ECHOPROMPT: Introduces a query rephrasing sub-task that encourages the model to rephrase the query in its own words before reasoning.
● TOC: Recursively constructs a disambiguation tree for ambiguous queries using few-shot prompting and external knowledge, generating comprehensive answers.
● INFOCQR: Adopts a “rewrite-edit” framework, first rewriting the original query and then editing to eliminate ambiguity.
● ADAQR: Proposes a preference optimization method that trains the rewriter based on retriever preferences to optimize query rewriting.
● MAFERW: Integrates multi-faceted feedback from retrieval documents and generated responses as rewards to explore optimal query rewriting strategies.
● CHIQ: Utilizes the NLP capabilities of LLMs (e.g., resolving co-reference relations and expanding context) to reduce ambiguity in dialogue history, improving the relevance of search queries.
Summary:
5. Query Abstraction
● STEP – BACK: Uses carefully designed prompts to manipulate the initial query, guiding the LLM reasoning process to align outputs more closely with the original query intent.
● COA: Abstracts general chain-of-thought reasoning into reasoning chains with abstract variables, enabling LLMs to utilize domain-specific tools for solving.
● AOT: Constructs the entire reasoning process using an abstract framework, integrating different levels of abstraction, clarifying the objectives and functions of each step.
● Baek et al.: Generates higher-level abstract information as context for existing queries, enriching direct information about the query subject.
● MA – RIR: Defines aspects of queries to facilitate more focused and effective reasoning on different aspects of complex queries.
● META – REASONING: Deconstructs the entity and operation semantics in queries into general symbolic representations, learning universal reasoning patterns.
● RULERAG: Recalls documents supporting queries based on logical rules, generating final responses.
● SIMGRAG: Resolves the alignment issue between query text and knowledge graph structures through a two-stage process, first converting the query into graph patterns, then quantifying the alignment degree.