

Source | Zhihu
Address | https://zhuanlan.zhihu.com/p/69389583
Author | Lao Song’s Tea Book Club
Editor | Machine Learning Algorithms and Natural Language Processing Public Account
This article is for academic sharing only. If there is an infringement, please contact the backend to delete the article.
Introduction
Recently, I have almost completely focused on how to leverage BERT, mainly exploring BERT’s performance on classification and reading comprehension tasks. I have encountered many pitfalls and thought to document them to help everyone use BERT better.
Key Points to Note
Text Length
One of the first things I noticed is that as the text length increases, the required GPU memory capacity also exhibits a linear increase, and the running time approaches linear. Therefore, we often have to make a trade-off, as the impact of text length varies across different tasks.
In terms of classification, after reaching a certain text length, the model’s performance does not change significantly, so increasing the text length further becomes less meaningful.
The 512 Token Curse
When you set your text length to exceed 512, the following error occurs:
RuntimeError: Creating MTGP constants failed.In the pytorch-pretrained-BERT implementation of BERT, the maximum supported text length is 512, which is determined by Position Embedding. This means that if your text length is long, you need to use truncation or batch reading methods to load it.
Don’t Run the Entire Dataset Initially
During early coding tests, the dataset is often large, and the loading process takes a long time. We must wait until loading is complete to see if the model can run, but in reality, we often need to try and error continuously. If we run the entire dataset each time, especially after using BERT (which tokenizes slowly), the efficiency is simply atrocious.
Therefore, I highly recommend first splitting out a demo-level subset. I usually take 1000, 1000, 1000, run the complete set once, and then proceed to run the actual dataset.
How to Fine-Tune BERT for Text Classification [2]
How to Truncate Text
Since BERT supports a maximum length of 512 tokens, how to truncate the text becomes a key issue. [2] discusses three methods:
-
head-only: Keep the first 510 tokens (leaving two positions for [CLS] and [SEP])
-
tail-only: Keep the last 510 tokens
-
head + tail: Select the first 128 tokens and the last 382 tokens
The author tested on the IMDB and Sogou datasets and found that head + tail yielded the best results. Therefore, in practice, all three approaches are worth trying, as they might provide slight improvements.
Multi-Layer Strategy
Another method is to divide the text into multiple segments, each not exceeding 512 tokens, which allows for capturing all text information. But is this really useful for classification tasks?
I personally believe the effect is minimal. Just like when we read an article, we generally understand the theme and classification by reading the beginning and end. There are very few cases where ambiguity arises, and experiments have indeed shown no significant improvement.
[2] first divides the text into  segments, and then encodes each segment separately, using three strategies to merge the information:
segments, and then encodes each segment separately, using three strategies to merge the information:
-
Multi-layer + mean: Average across segments
-
Multi-layer + max: Maximum across segments
-
Multi-layer + self-att: Add an Attention layer for merging
Experiments showed no improvement in results, and I found limited improvement (0.09%) in my tests on the CNews dataset. I will test a few more datasets later; see my repository: Bert-TextClassification.
Catastrophic Forgetting
Catastrophic Forgetting refers to the phenomenon in transfer learning where learning new knowledge causes the forgetting of previously important old knowledge. As BERT is a representative of transfer learning in NLP, does it have a serious Catastrophic Forgetting problem?
[2] found that a lower learning rate, such as 2e-5, is key for BERT to overcome the Catastrophic Forgetting issue, and in the pytorch-pretrained-BERT implementation, the learning rate is 5e-5, which aligns with this view.
Is Pre-training Necessary?
While fine-tuning is powerful, whether pre-training can further improve performance and how to conduct pre-training remains an unknown topic.
First question: Can pre-training improve performance? The answer is most likely yes, but the specific improvement still depends on the dataset itself. From experiments in [2], most datasets show varying degrees of performance improvement.
Second question: How to conduct pre-training, or which data to use for pre-training? There are mainly three strategies:
-
Pre-train on a specific dataset. Experiments in [2] indicate that this method is likely to improve performance.
-
Pre-train on domain-specific data. Generally, this tends to yield better results than strategy 1 and the data is easier to obtain, but if the data sources vary, it may introduce noise.
-
Pre-train on cross-domain data. This strategy does not yield as significant improvements as the previous two, as BERT has already been trained on high-quality, large-scale cross-domain data.
Overall, strategy 2 is the best, provided you ensure the quality of the data.
How Many GPUs Do We Need?
Pytorch Multi-GPU Parallelism
Let’s first discuss the internal processing mechanism of Pytorch under multi-GPU conditions; this is helpful for tuning parameters.
Like most deep learning frameworks, Pytorch uses data parallelism (see Figure 1) to handle model training across multiple GPUs, but with its unique characteristics.
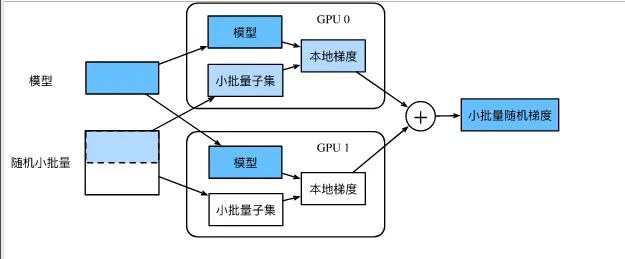
Specifically, Pytorch first loads the model onto the main GPU (usually device_id=0), then copies the model to each GPU, and divides a batch of data according to the number of GPUs, inputting the corresponding data into each GPU. Each GPU performs forward computation independently. During backpropagation, Pytorch needs to aggregate the model output information from each GPU back to GPU 0 (this is my understanding, feel free to correct me; I will conduct experiments to analyze this later), which causes GPU 0 to occupy relatively more memory, and the gradient computation process is concentrated on GPU 0. After gradient computation, the gradients are copied to the other GPUs for backpropagation updates.
Practical experiments show that for classification tasks, the difference is not significant, but for language model tasks, due to the large output layer, it may cause the GPU to crash. As shown in the figure below:

How Many GPUs Should We Use?
For small datasets, it is recommended to use 1 or 2 GPUs. In multi-GPU scenarios, we need to consider communication time, which is relatively slow. From my experience, for small datasets, having too many GPUs actually takes more time. For medium to large datasets, you need to judge for yourself and try to find the optimal number of GPUs that saves time while providing enough memory.
Using Multiple GPUs in Pytorch
When using multiple GPUs, the model-related calls differ mainly in the following aspects:
# Model definitionif n_gpu > 1: model=nn.DataParallel(model,device_ids=[0,1,2])# Loss calculationif n_gpu > 1: loss = loss.mean() # mean() to average on multi-gpu.# Model savingmodel_to_save = model.module if hasattr( model, 'module') else modeltorch.save(model_to_save.state_dict(), output_model_file)We see that the most significant change still lies in the model distribution, which is essential to understand nn.DataParallel.
Load Balancing Issues in Multi-GPU Scenarios
In specific single-machine multi-GPU setups, GPU 0 tends to occupy more memory than the other GPUs. This is due to the model outputs and related gradient tensors ultimately being aggregated on GPU 0, as mentioned earlier. This is the load balancing issue of Pytorch.
The load balancing issue in Pytorch is not severe for general tasks like classification, but it is critical for tasks with large output layers like language models. This also indirectly proves my previous statement: Language models are not something that can be handled by just any laboratory or company.
I personally have not been deeply troubled by this issue, so I haven’t explored it extensively, as gradient accumulation is a very effective trick.
Regarding the load balancing issue in Pytorch, there are generally two solutions:
-
The first is to use distributed
DistributedDataParallel. -
The second is to write your own solution. You can refer to [1], but I won’t elaborate since I haven’t delved deeply into it.
Conclusion
This article is more like notes, summarizing the pitfalls I have encountered recently. I believe everyone will encounter these issues to some extent, so I share it to provide some thoughts. I am too lazy to write more, so that’s it.
If you find it useful, please give a thumbs up before you leave. After all, writing articles is not easy.
Reference
[1] https://zhuanlan.zhihu.com/p/48035735
[2] How to Fine-Tune BERT for Text Classification?
Download 1: Four Essentials
Reply "Four Essentials" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to obtain learning materials for TensorFlow, Pytorch, machine learning, and deep learning!
Download 2: Repository Sharing
Reply "Code" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to access 195 NAACL + 295 ACL 2019 papers that have open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Exciting news! The Machine Learning Algorithms and Natural Language Processing exchange group has officially been established! There are abundant resources in the group, and everyone is welcome to join for learning!
Extra benefits! Resources include Qiu Xipeng's deep learning and neural networks, official Chinese tutorials for Pytorch, data analysis using Python, machine learning notes, official Chinese documentation for pandas, Effective Java (Chinese version), and 20 other welfare resources.
How to obtain: After entering the group, click on the group announcement to get the download link. Please modify your remarks to [School/Company + Name + Direction] when adding.
For example - HIT + Zhang San + Dialogue System.
Please avoid adding if you are a vendor. Thank you!
Recommended Reading:
12 Golden Rules for Solving NER Problems in Industry
Three Steps to Master the Core of Machine Learning: Matrix Derivation
Distillation Techniques in Neural Networks, Starting with Softmax