Produced by Big Data Digest
Source:GitHub
Compiled by:LYLM, Wang Zhuanzhuan, Li Lei, Qian Tianpei
In recent years, the development of machine learning language processing models has progressed rapidly, moving beyond the experimental stage and into application in some advanced electronic products.
For example, Google recently announced that the BERT model has become the main driving force behind its search products. Google believes this advancement (i.e., the application of natural language understanding in the search field) is the biggest breakthrough in machine learning over the past five years and one of the greatest advancements in the history of search.
Recently, Jay Alammar published a new article that briefly introduces how to use the BERT model to complete sentence classification tasks, serving as a foundational introductory tutorial that deeply demonstrates the relevant core concepts.
At the same time, he created an IPython notebook for this article, which can be viewed on GitHub or run in Colab.
GitHub:https://github.com/jalammar/jalammar.github.io/blob/master/notebooks/bert/A_Visual_Notebook_to_Using_BERT_for_the_First_Time.ipynb
Colab:
https://colab.research.google.com/github/jalammar/jalammar.github.io/blob/master/notebooks/bert/A_Visual_Notebook_to_Using_BERT_for_the_First_Time.ipynb
Dataset:SST2
The dataset used in this example is SST2, which contains movie reviews and corresponding labels (1 for positive, 0 for negative).

Dataset:
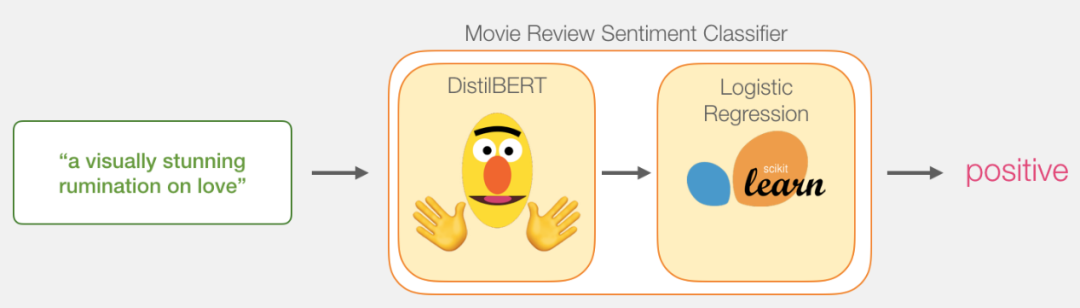
Model:Sentence Sentiment Classification
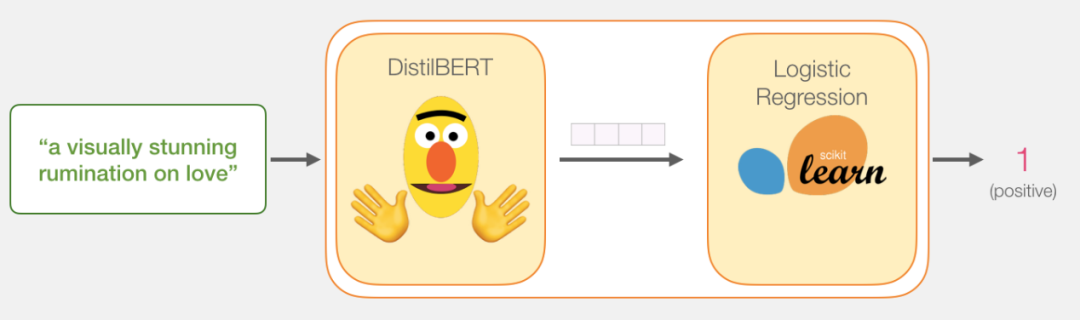
Our goal is to create a model that takes sentences as input (such as the reviews in the dataset) and outputs 1 (positive sentiment) or 0 (negative sentiment). As shown below:

In fact, the model consists of two sub-models.
The DistilBERT model is responsible for processing the sentences and passing the extracted information to the next model, which is an open-source distilled version of BERT developed by the HuggingFace team, lighter and faster, with performance comparable to BERT.
The next model is a basic logistic regression model from scikit-learn that receives the results processed by DistilBERT and classifies the sentences as positive or negative (1 or 0, respectively).
The data passed between the two models is a 768-dimensional vector. We can consider this vector as the embedding of the sentence for classification.
If you have read my previous article “Illustrated BERT”, this vector is the output result mentioned at the first position (marked as [CLS]).
“Illustrated BERT”:
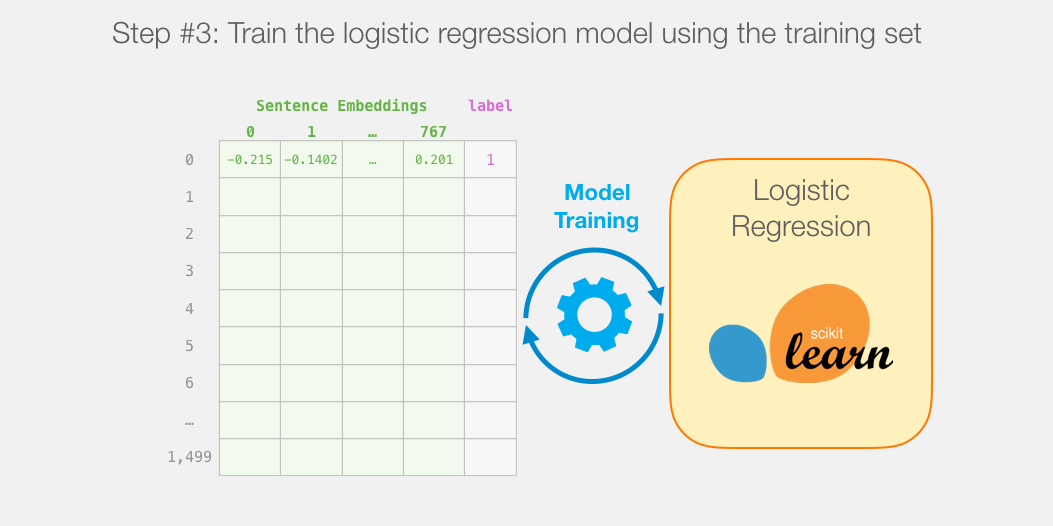
Model Training
Although we will use two models, we only need to train the logistic regression model. The DistilBERT model will use a pre-trained model suitable for English language processing. This model has not been specifically trained and fine-tuned for the sentence classification task, but based on the general objectives of the BERT model, it still has certain capabilities for sentence classification, especially the output of the first position (associated with the [CLS] marker). I believe this is determined by the secondary training objective of the BERT model, which is next sentence classification. This objective seems to train the model to encapsulate the entire sentence’s meaning as the output of the first position. The Transformers library includes implementations of the DistilBERT model and its pre-trained versions.
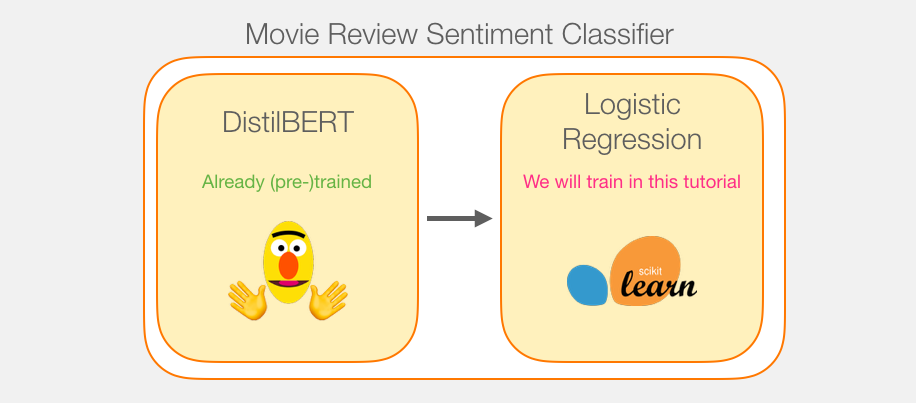
Tutorial Overview
This is a brief overview of the steps in this tutorial. First, we will use the trained DistilBERT model to generate sentence embeddings for 2000 sentences in the dataset.
After this step, we will no longer use DistilBERT, and the rest will be the work of scikit-learn. As is customary, we will split the dataset into training and testing sets.
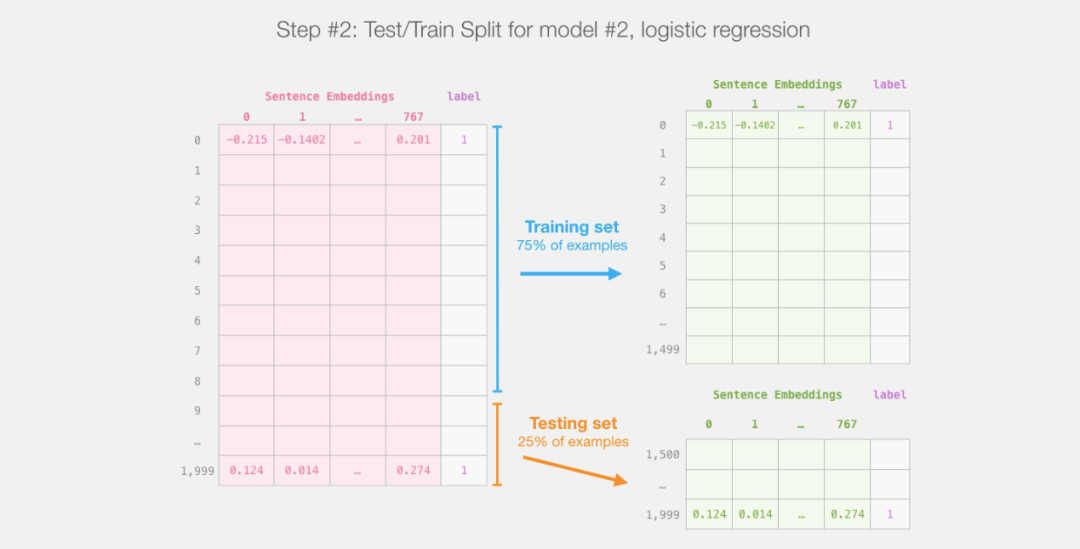
Then we will train the logistic regression model using the training set.
How to calculate a single prediction result?
Before diving into the code to understand how to train the model, let’s take a look at how a trained model calculates prediction results.
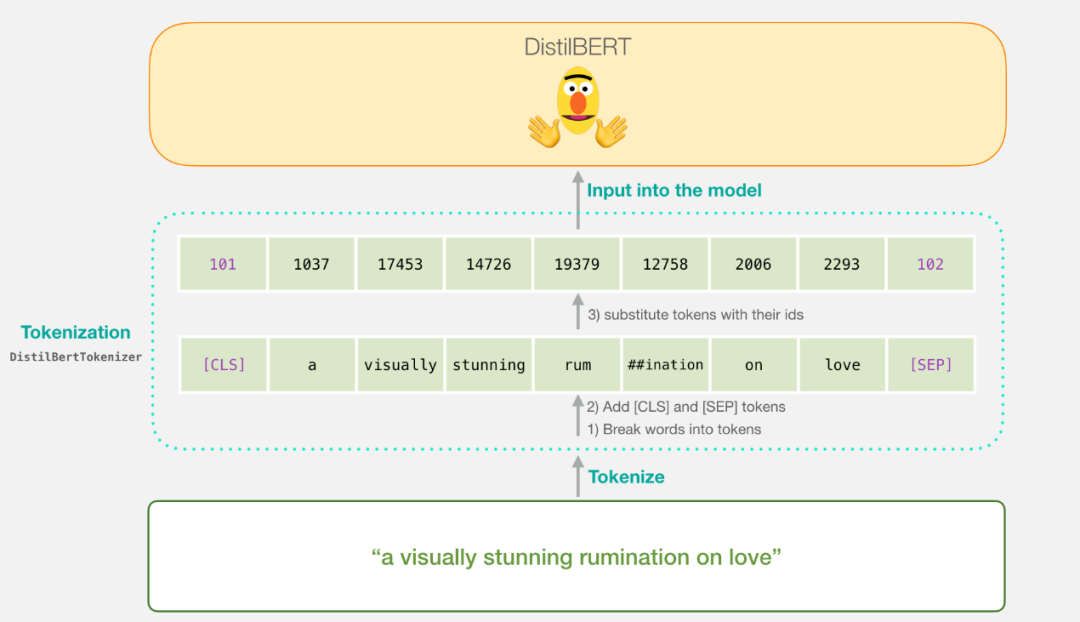
First, let’s try to classify the sentence “A visually stunning rumination on love”. The first step is to use the BERT tokenizer to convert the English words into standard tokens. The second step is to add the special tokens required for sentence classification (such as the [CLS] at the beginning and the [SEP] at the end of the sentence).

In the third step, the tokenizer will replace each token with its ID from the embedding table (the embedding table is obtained from the trained model), and the background knowledge of word embeddings can be referenced in my “Illustrated Word2Vec”.

“Illustrated Word2Vec”:
Note that the tokenizer completes the above steps in just one line of code:
At this point, the input sentence has been transformed into a vector of appropriate dimensions, which can be directly passed into the DistilBERT model.
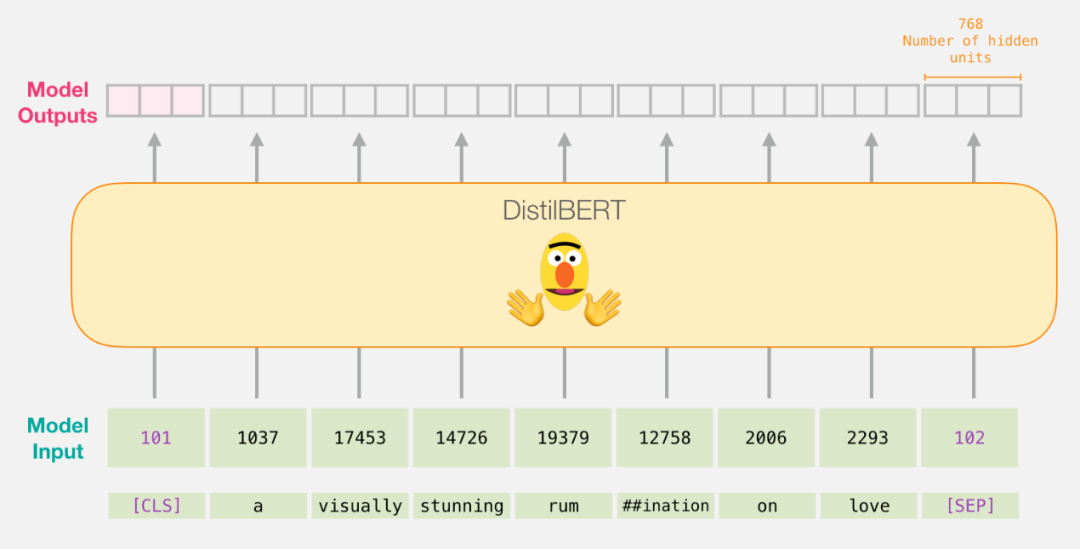
If you have read the article “Illustrated BERT”, this step can be represented as follows:
The process of inputting the vector into the DistilBERT model to obtain the output is the same as that of the BERT model. The output is a vector related to the input, where each vector consists of 768 (floating point) values.
Since this is a sentence classification task, we will ignore all other vectors except the first one (the vector associated with the [CLS] token). We will use the first vector as input for the logistic regression model.
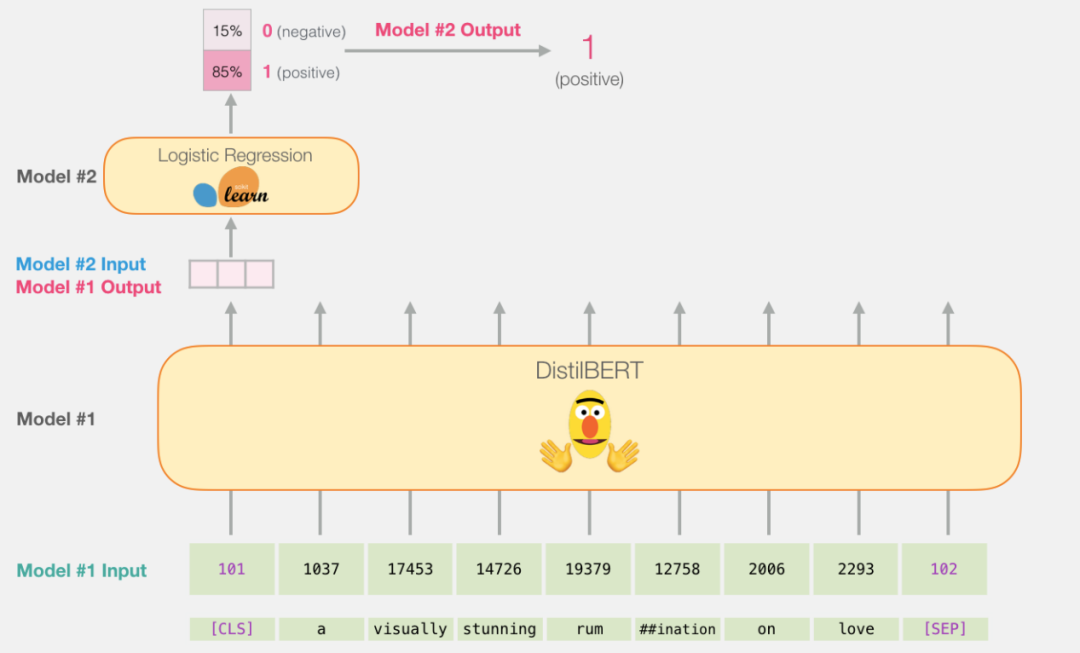
After that, the logistic regression model’s job is to classify the vector based on what it learned during the training phase. The prediction process is shown below:
We will discuss the model training and the code for the entire process in the next section.
Code
In this section, we will focus on the code used to train this sentence classification model. The IPython notebook containing all this code can be found on Colab and GitHub.
Import Required Packages
import numpy as np
import pandas as pd
import torch
import transformers as ppb # pytorch transformers
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
The dataset file we use can be found on GitHub, so we will directly import it under the pandas framework.
df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)We can use df.head() to view the first five rows of the dataset to see what the data looks like.
df.head()
Which outputs:The output is as follows:

Import Pre-trained DistilBERT Model and Tokenizer
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
## Want BERT instead of distilBERT? Uncomment the following line:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
# Load pretrained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)Now we can tokenize the dataset. Please note that the operation here is slightly different from the example above. The example above only tokenized one sentence. Here, we will process the tokenization of all sentences in batches (considering resource issues, the IPython notebook file only processes a small subset of data, about 2000).
Tokenization
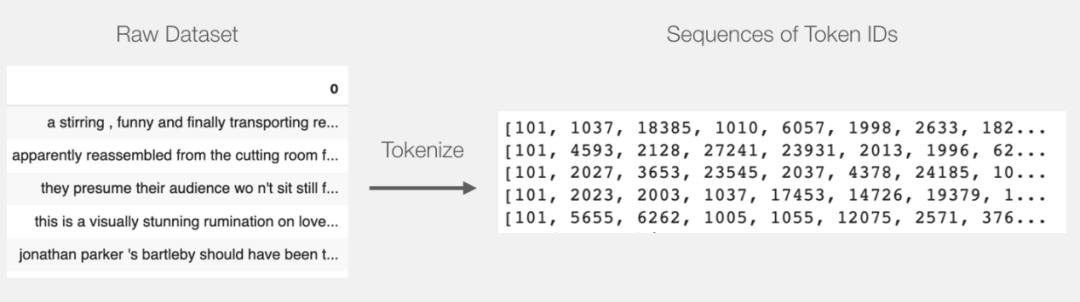
tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
This turns every sentence into the list of ids.The above command turns each sentence into a list of IDs.
The dataset is a list of lists (or pandas Series/DataFrame). Before DistilBERT processes this as input, we need to ensure that all vectors have the same length, so we need to pad the vectors of shorter sentences with zero tokens. The padding step can be referenced in the notebook, which involves basic Python string and array operations.
After padding, we can input the matrix/tensor into the BERT model:

Processing with DistilBERT Model
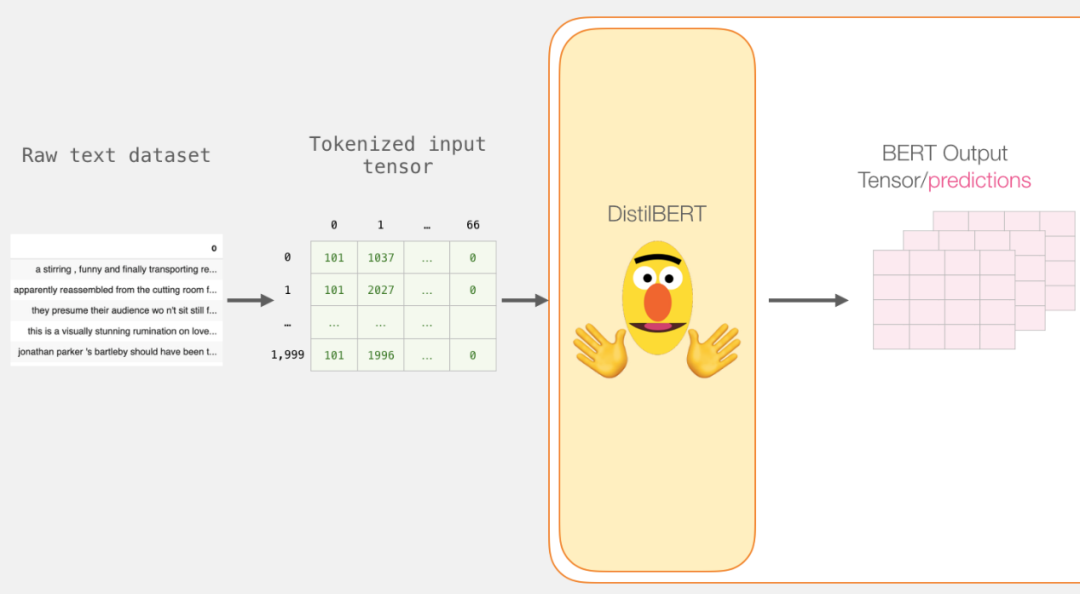
Now, we need to obtain a tensor from the padded token matrix to serve as input for DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
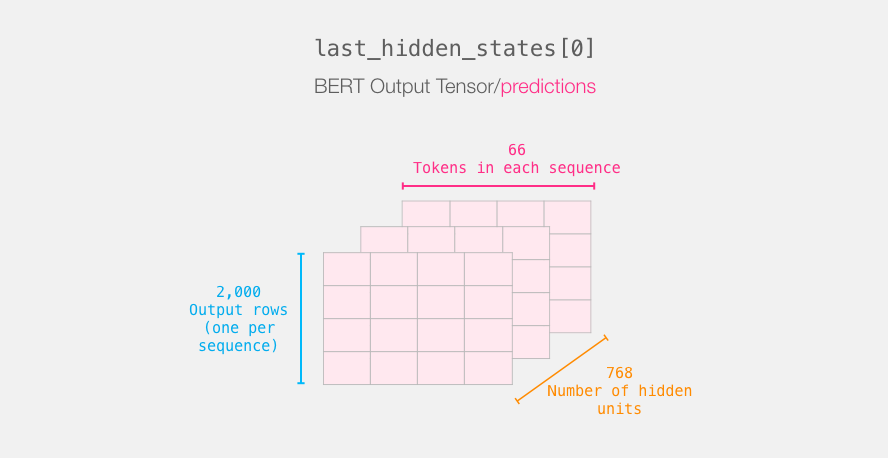
last_hidden_states = model(input_ids)After running this step, last_hidden_states stores the output of DistilBERT. It is a multi-dimensional tuple (number of examples, maximum number of tokens in the sequence, number of hidden units in the DistilBERT model). In our case, it is 2000 (because we limited it to 2000 examples), 66 (the number of tokens in the longest sequence among these 2000 examples), and 768 (the number of hidden units in the DistilBERT model).
Parsing BERT Output Tensor
Let’s parse this 3D output tensor and first look at its dimensions:
Sentence Processing Flow
Each sentence in the dataset corresponds to a row, and the following image summarizes the processing flow for the first sentence:
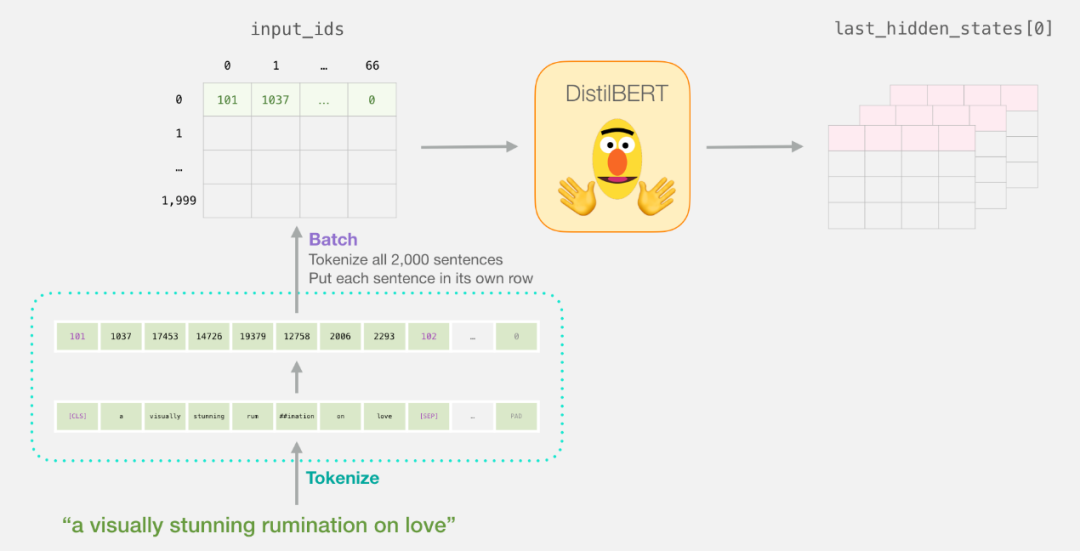
Important Slice of Output
For the sentence classification problem, we are only interested in the output of the BERT related to the [CLS] token, so we will only select a slice of this 3D dataset.
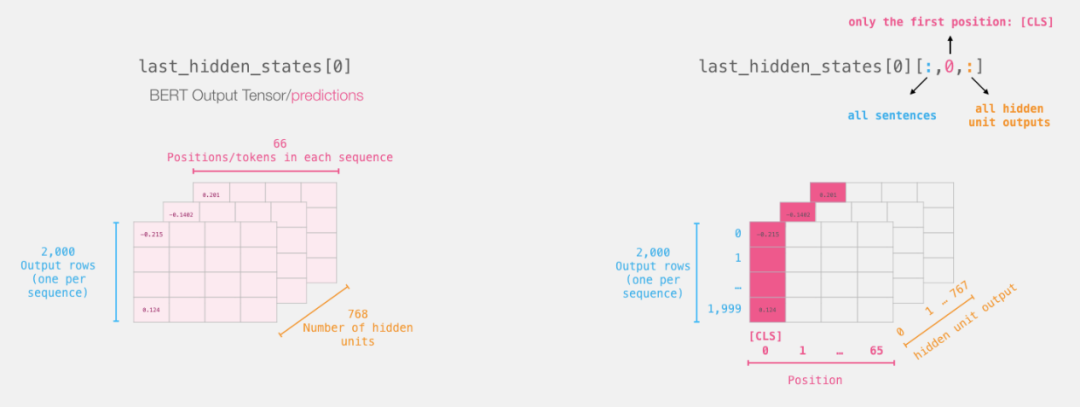
The following code shows how to slice the 3D tensor to obtain the 2D tensor we are interested in:
# Slice the output for the first position for all the sequences, take all hidden unit outputs
features = last_hidden_states[0][:,0,:].numpy()Now we have obtained the features as a 2D numpy array, which contains the sentence embeddings for all sentences in the dataset.
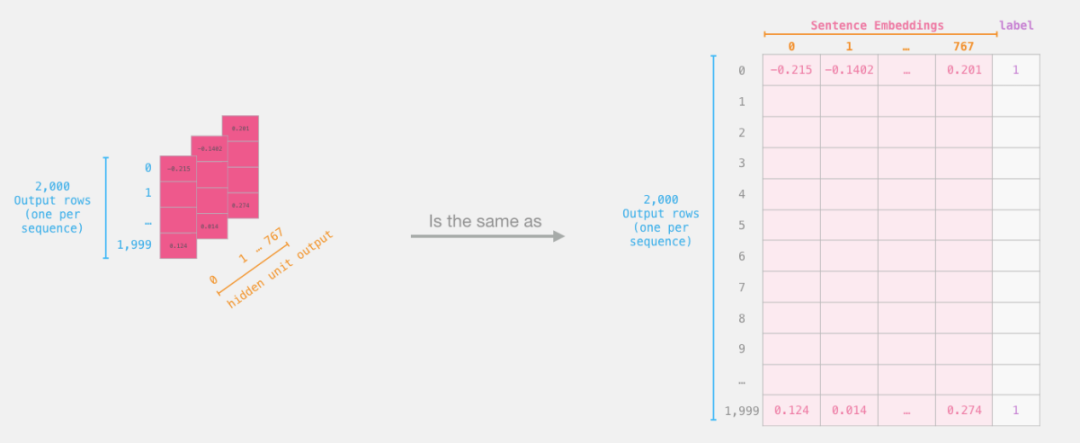
Logistic Regression Dataset
Now that we have the output from BERT, we have the complete dataset required to train the logistic regression model. The 768 columns of data are the feature set, and the labels can be obtained from the original dataset.
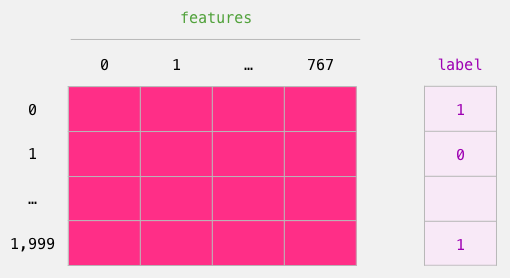
The labeled dataset we use to train logistic regression. Here, the features are the BERT output vector from the [CLS] token (position 0) obtained from the slicing above. Each row corresponds to a sentence in our dataset, and each column corresponds to the outputs of the hidden units in the feedforward neural network at the top of the BERT/DistilBERT model.
After completing the traditional machine learning training and testing set split, we obtained the final logistic regression model and can train it on the dataset.
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)Training and testing set split:
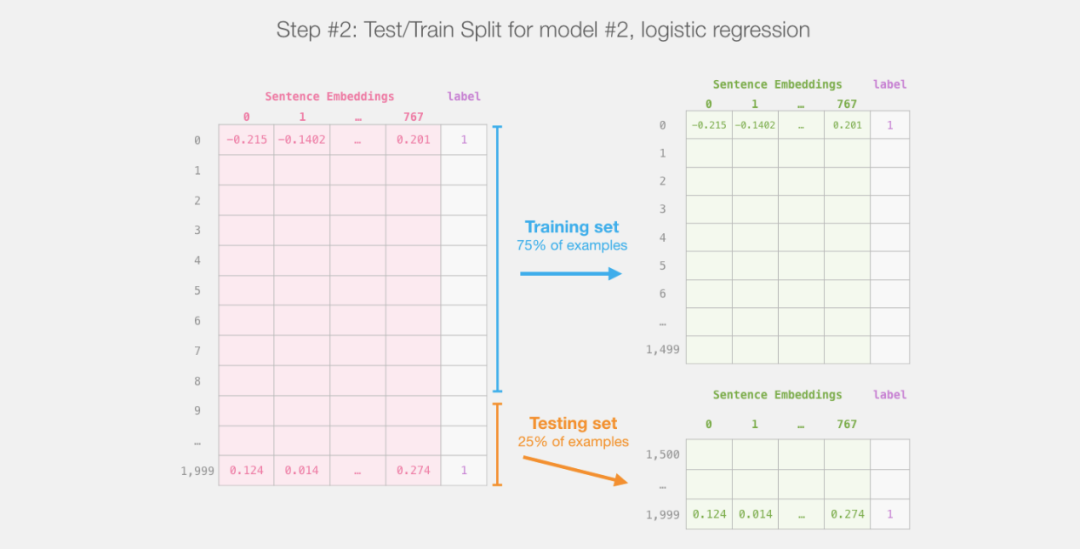
The next step is to train the logistic regression model using the training set.
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)After obtaining the trained model, we will evaluate it:
lr_clf.score(test_features, test_labels)The model’s accuracy is around 81%.
Score Benchmark
As a reference, the highest accuracy score for this dataset is currently 96.8. The DistilBERT model can be fine-tuned to improve its score on this task, a process known as fine-tuning, which updates BERT’s weights to enhance its performance in sentence classification (which we refer to as downstream tasks). The accuracy score of the fine-tuned DistilBERT can reach 90.7, while the standard BERT model can achieve 94.9.
IPython Notebook
The IPython notebook file on GitHub can be run directly on Colab.
Well, the introductory experience with the BERT model has perfectly concluded. The next step is to run the notebook file and try fine-tuning. You can also go back to the beginning and try using BERT instead of DistilBERT to understand how it works.
Original link:


Recruiting Intern/Full-Time Editor
Join us and experience every detail of writing for a professional technology media outlet, growing alongside some of the best talents in the most promising industry. Located in Beijing, Tsinghua East Gate, reply with “Recruitment” on the Big Data Digest homepage dialogue page for more details. Please send your resume directly to [email protected]