
Pine from Aofeisi Quantum Bit | Official Account QbitAI
What can you achieve by training BERT on a single GPU in just one day?
Now, researchers have finally done this, exploring the true performance of language models under limited computational conditions.

In the past, most professionals focused on the performance of language models under extreme computational conditions.
However, such an environment for training language models is often unattainable for many researchers and practitioners.
Thus, this single-day single-GPU challenge has been dubbed by netizens as a benchmark they most wanted to see.
Even Lucas Beyer, the author of ViT and a researcher at Google Brain, has publicly recommended this, stating that it represents a refreshing change.

Let’s take a look at the specific process and results!
Challenge Process
The goal of this research is quite clear: to take the opposite approach and investigate how to achieve BERT’s performance level with limited computational resources.
Since the aim is to reduce computational requirements, the first step is to impose some constraints on the model.
This involves the previously mentioned limitations on time and the number of GPUs: a single day and a single GPU.
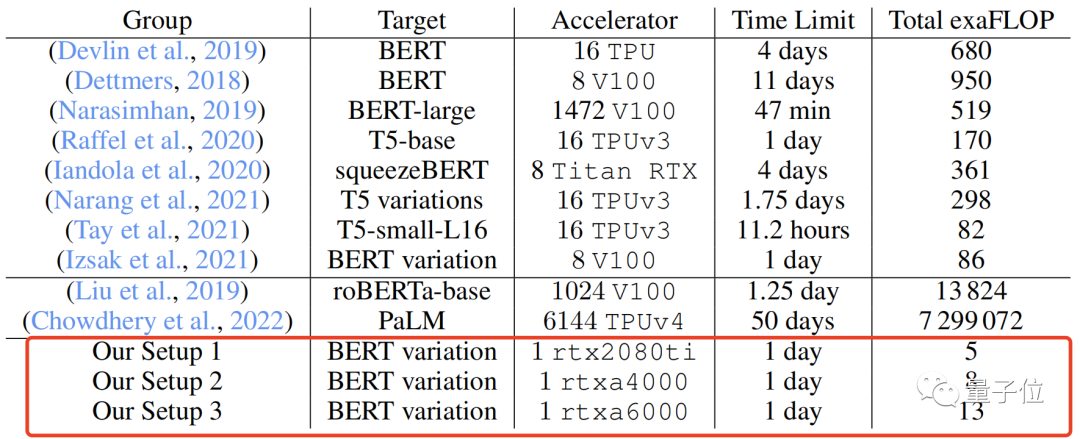
Regarding GPUs, the researchers selected three for testing: rtx2080ti, rtxa4000, and rtxa6000, each with 4 CPU cores and 32GB of memory.
After limiting the computational resources, adjustments on other parameters of the model must be made to further evaluate BERT’s practical applicability.
These adjustments include initial data settings, model architecture, training, and dataset improvements.
Throughout the adjustment process, the overall tone is centered around “practical use”, avoiding jumps to specialized settings. Therefore, the researchers kept all content at the implementation level within the PyTorch framework.

First, let’s discuss the initial data settings, which can be summarized as follows:
-
Package the tokenized data into random sequences of length 128, using
to separate unrelated segments; -
Remove the
token, as its inclusion during training did not significantly impact performance; -
Accumulate small batches of sequences of length 64 to 96 into larger batches for processing.
Next, the architecture modifications are discussed, with the following image showing the changes in MLM task loss for various models as the number of tokens increases.
The results clearly indicate that the decrease in loss for a model largely depends on its size rather than its type.
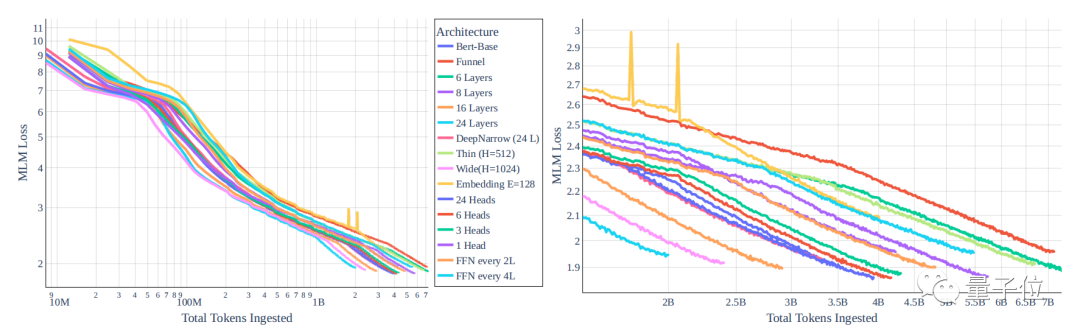
Moreover, since the performance of each token is tightly coupled with the model size, achieving significant performance gains by altering the size and type of the Transformer model is unlikely.
However, for all models of the same size, the efficiency of each gradient remains almost unchanged, allowing for the selection of architectures that can accelerate computation through rapid search without changing model size.
The specific optimizations and other adjustments are as follows:
-
Reduce the number of attention heads to lower gradient costs: disable all QKV biases;
-
Disable all linear layer biases, which accelerates gradient computation without significantly affecting model size;
-
Implement proportional sine position embeddings, which provide incremental benefits over learned or non-proportional sine embeddings;
-
Pre-normalization of LN is more beneficial than post-LN;
-
Removing non-linear heads has no impact.
Next, the training settings will be configured, so let’s look directly at the relevant adjustments:
-
The optimizer remains Adam;
-
Set the Learning Rate schedule and batch size;
-
Eliminate the Dropout phase. (as Dropout leads to a net reduction in updates per second)
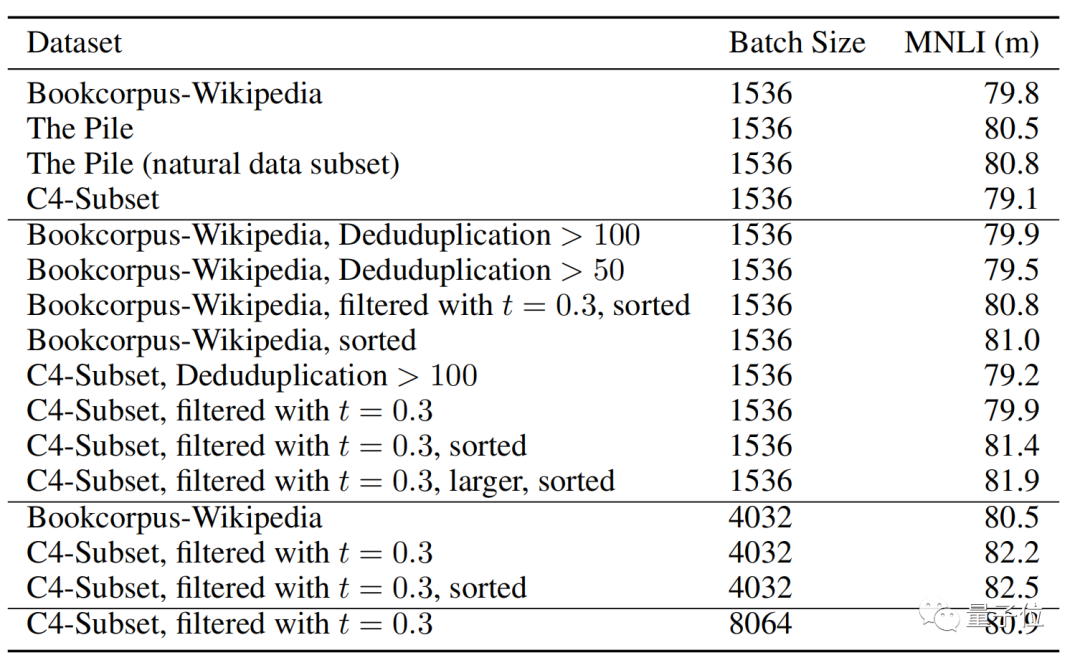
Regarding the dataset, the research team employed two data-based approaches to better reduce scale: filtering, processing, or sorting existing data in various ways and swapping data sources, as detailed in the table below.
Performance Approaching Original BERT
After adjusting various parameters, how does the performance of this single-GPU one-day BERT turn out? Let’s look directly at the final data!
The downstream performance evaluation was conducted via GLUE, and the table below shows the scores on three different graphics cards, which are very close to the original BERT.
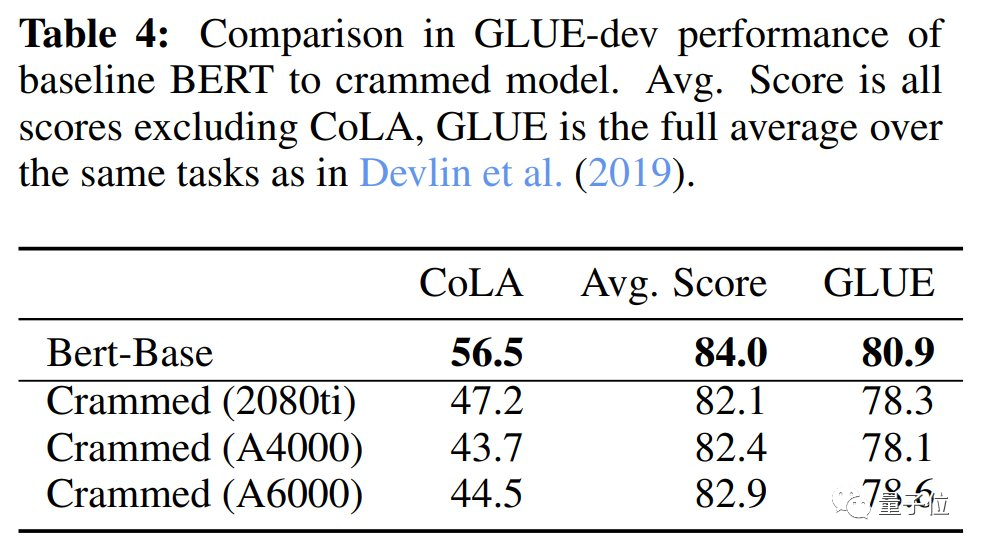
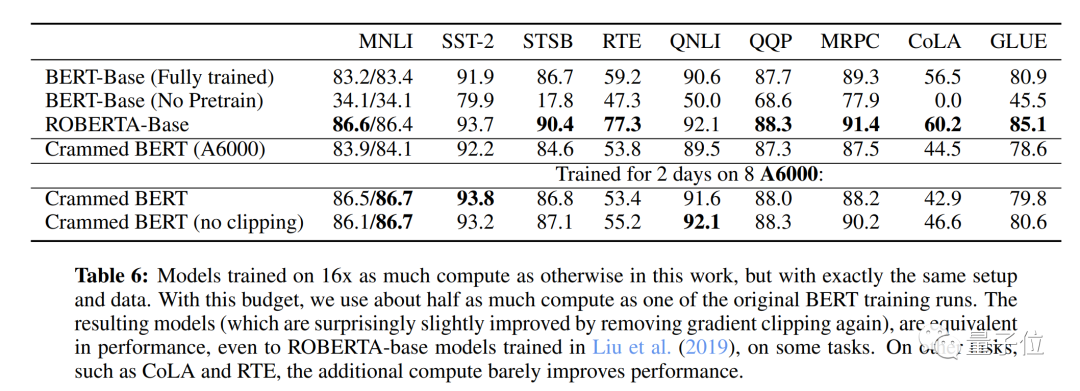
When the model training computation is 16 times greater, i.e., (2 days, on 8 GPUs), using the same data and settings, the final results show a significant improvement over the original BERT, reaching RoBERTa’s performance level.
For more information, you can click the link below to view the original paper!
Original Paper:https://arxiv.org/abs/2212.14034
Reference Link:https://twitter.com/giffmana/status/1608568387583737856
— End —
“2022 Artificial Intelligence Annual Selection” List Announced
Top 50 Leading Enterprises

Click here👇 to follow me, and remember to star it~
One-click triple connection: “Share”, “Like”, and “View”
See the latest advancements in technology daily~
