The attention mechanism is potentially a very useful method. In this issue, let’s understand the principles and methods behind the attention mechanism.
The original text is in English from https://blog.heuritech.com/2016/01/20/attention-mechanism/
With the development of deep learning and artificial intelligence, many researchers are interested in the “attention mechanism” in neural networks. This article aims to provide a high-level explanation of the content of the attention mechanism in deep learning and to detail some technical steps for computing attention. For more technical details, please refer to the English version, especially the recent review by Cho et al. [3]. Unfortunately, these models are not always directly implementable by themselves, and so far only a few open-source codes have been released.
Neuroscience and computational neuroscience [1,2] have extensively studied the neural processes involved in attention [1,2]. In particular, the visual attention mechanism: many animals focus on specific parts of their visual input to compute appropriate responses. This principle has a significant impact on neural computation, as we need to select the most relevant information rather than using all available information. A large portion of the input is irrelevant to the computational neural response.
A similar idea: “focusing on specific parts of the input” has been applied in deep learning for tasks such as speech recognition, translation, reasoning, and object visual recognition.
Let’s take an example to explain the attention mechanism. The task we want to achieve is image captioning: we want to generate captions for a given image.
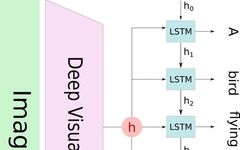
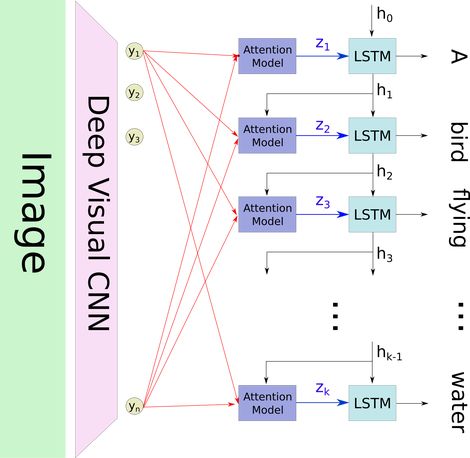
The “classic” image captioning system uses a pre-trained convolutional neural network to encode the image, which generates a hidden state h. It then decodes this hidden state using a recurrent neural network (RNN) and generates each word of the caption recursively. This approach has been applied by several groups, including [11] (see the image below):
The problem with this method is that when the model tries to generate the next word of the caption, that word often only describes a part of the image. Using the entire representation of the image h to modulate the generation of each word cannot effectively produce different words for different parts of the image. This is where the attention mechanism is useful.
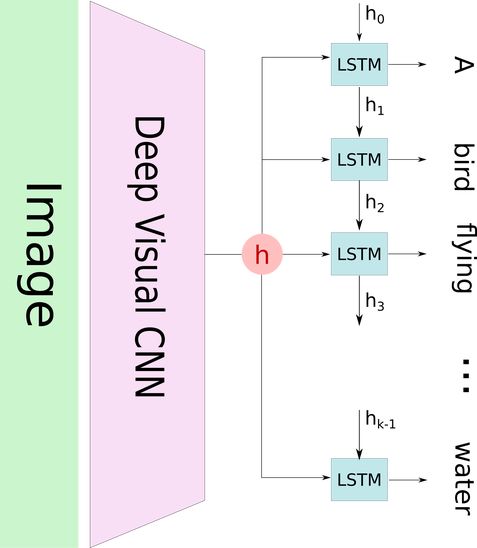
By utilizing the attention mechanism, the image is first divided into n parts, and we use the convolutional neural network (CNN) representations of each part h_1, …, h_n to compute. When the RNN generates a new word, the attention mechanism focuses on the relevant parts of the image, so the decoder only uses specific parts of the image.
In the image below (top row), we can see which part of the image (in white) is used for generating each word of the caption.


We will now explain the general working principle of attention models. A review article on the application of attention models [3] details the implementation of attention-based encoder-decoder networks, which can be referenced for more detailed knowledge.
Detailed Explanation of the Attention Mechanism: The attention model is a method that takes n parameters y_1, …, y_n (in the previous example, y_i would be h_i) and context c. It returns a vector z, which should be a “summary” of y_i, focusing on information relevant to context c. More formally, it returns a weighted arithmetic mean of y_i, selecting weights based on the relevance of each y_i given the context c.
In the example given above, the context is the beginning of the sentence being generated, y_i is the representation of the image parts (h_i), and the output is the filtered representation of the image, focusing on the interesting part of the currently generated word.
An interesting feature of the attention model is that the weights of the arithmetic mean are accessible and can be visualized. This is exactly what we showed in the previous figures; if this image has a high weight, the pixels are whiter.
But what exactly is this black box doing? The entire attention model’s diagram would look like this:
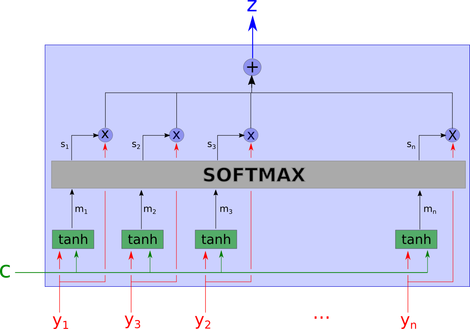
This network seems complex, but we will explain it step by step.
First, we recognize the inputs. c is the context, and y_i is the “part of the data” we are looking at.
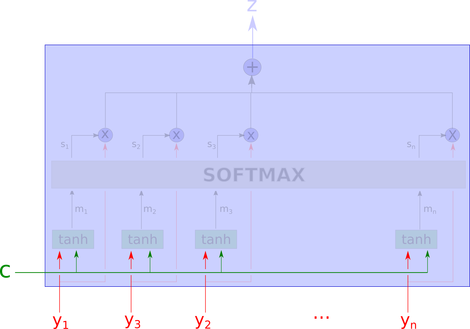
In the next step, the network uses the tanh layer to compute m_1, … m_n. This means we calculate the “aggregation” of the values of y_i and c. An important note here is that the calculation of each m_i does not look at other y_j where j is not equal to i. They are computed independently.
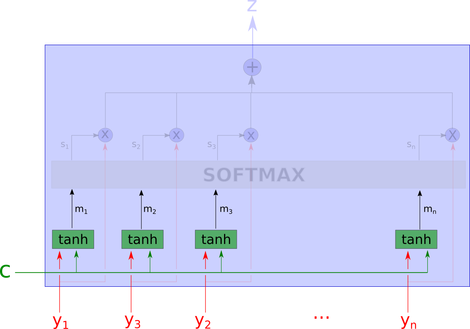
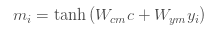
Then we pass m_1, m_2, ..m_n to the next layer, computing softmax, which is typically used in the last layer of classifiers.

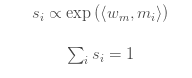
Here, s_i is the softmax of m_i projected in the learning direction. Thus, depending on the context, softmax can be considered the maximum relevance of the variables.
The output z is the weighted arithmetic mean of all y_i, where the weights represent the relevance of each variable based on context c.
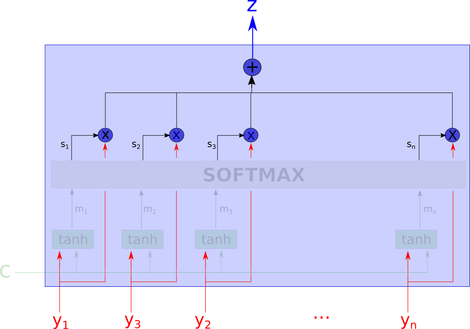
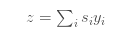
Please note that what we have implemented above is “soft-attention”, which is a fully differentiable deterministic mechanism that can be inserted into existing systems, and the gradients propagate through the attention mechanism while they propagate through the rest of the network.

Back to Image Captioning: We can identify the graphics used for the “classic” model of image captioning, but with a new layer of attention model. What happens when we want to predict a new word for the caption? If we predict the i-th word, the hidden state of the LSTM is h_i. We use h_i as context to select the “relevant” parts of the image. Then, the output of the attention model z_i is used as the input to the LSTM, which is the filtered representation of the image, retaining only the relevant parts of the image. Then, the LSTM predicts a new word and returns a new hidden state h_{i + 1}.
Attention Without RNN: So far, we have only described the attention model in the encoder-decoder framework (i.e., with RNN). However, when the order of inputs is not important, independent hidden states h_j can be considered. For example, in Raffel et al. [10], the attention model is completely feedforward.
References
[1] Itti, Laurent, Christof Koch, and Ernst Niebur. « A model of saliency-based visual attention for rapid scene analysis. » IEEE Transactions on Pattern Analysis & Machine Intelligence 11 (1998): 1254-1259.
[2] Desimone, Robert, and John Duncan. « Neural mechanisms of selective visual attention. » Annual review of neuroscience 18.1 (1995): 193-222.
[3] Cho, Kyunghyun, Aaron Courville, and Yoshua Bengio. « Describing Multimedia Content using Attention-based Encoder–Decoder Networks. » arXiv preprint arXiv:1507.01053 (2015)
[4] Xu, Kelvin, et al. « Show, attend and tell: Neural image caption generation with visual attention. » arXiv preprint arXiv:1502.03044 (2015).
[5] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. « Neural machine translation by jointly learning to align and translate. » arXiv preprint arXiv:1409.0473(2014).
[6] Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. « End-to-end memory networks. » Advances in Neural Information Processing Systems. (2015).
[7] Graves, Alex, Greg Wayne, and Ivo Danihelka. « Neural Turing Machines. » arXiv preprint arXiv:1410.5401 (2014).
[8] Joulin, Armand, and Tomas Mikolov. « Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets. » arXiv preprint arXiv:1503.01007 (2015).
[9] Hermann, Karl Moritz, et al. « Teaching machines to read and comprehend. » Advances in Neural Information Processing Systems. 2015.
[10] Raffel, Colin, and Daniel PW Ellis. « Feed-Forward Networks with Attention Can Solve Some Long-Term Memory Problems. » arXiv preprint arXiv:1512.08756 (2015).
[11] Vinyals, Oriol, et al. « Show and tell: A neural image caption generator. » arXiv preprint arXiv:1411.4555 (2014).
Join Our Group for Discussions
Follow computer vision and machine learning technologies, feel free to join the 52CV group, scan the code to add 52CV to get you into the group,
(Please be sure to note: 52CV)

For those who prefer QQ discussions, you can add the official QQ group: 928997753.
(I won’t be online all the time, so if I can’t verify you in time, please forgive me)
For more CV technical content, please visit:
“I Love Computer Vision” Technical Collection Summary (January 20, 2019)

Long press to followI Love Computer Vision