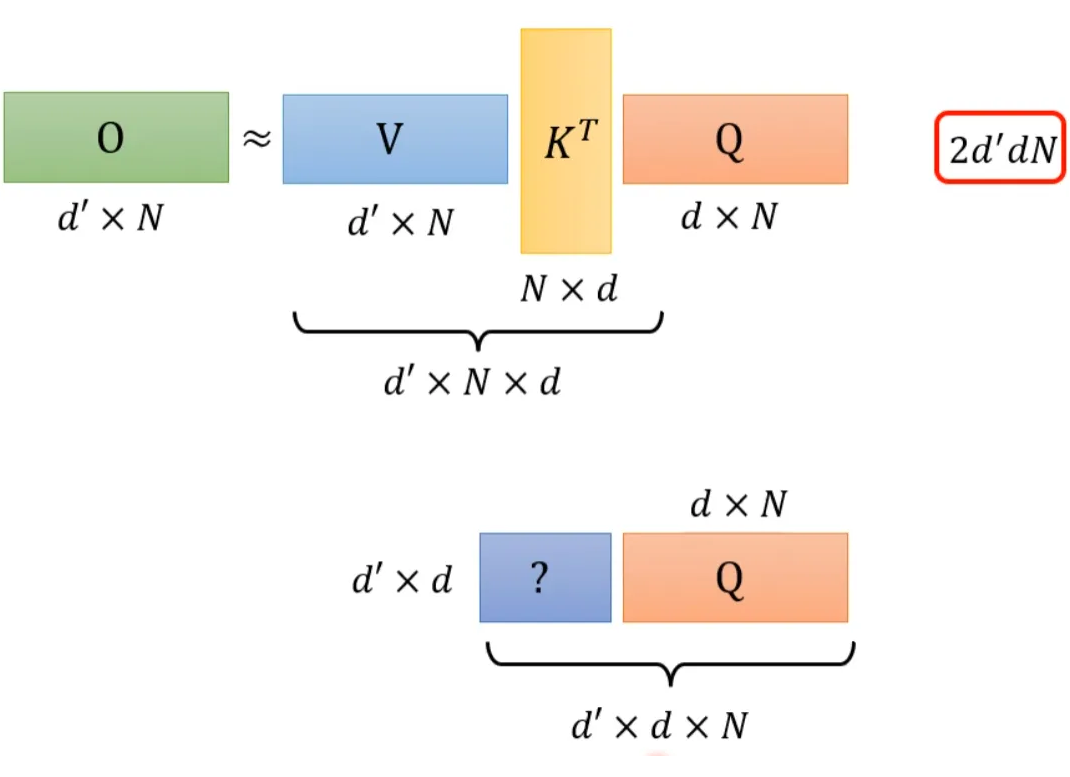MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and corporate researchers.
The community’s vision is to promote communication and progress among the academic and industrial circles of natural language processing and machine learning, especially for beginners.
Reprinted from | PaperWeekly
This summarizes the main content regarding the various attention mechanisms introduced by Professor Li Hongyi in his Spring 2022 machine learning course, which also supplements the 2021 course. The reference video can be found at:
https://www.bilibili.com/video/BV1Wv411h7kN/?p=51&vd_source=eaef25ec79a284858ac2a990307e06ae
In the transformer video of the 2021 course, Professor Li detailed some self-attention content, but self-attention actually has various forms of variations:
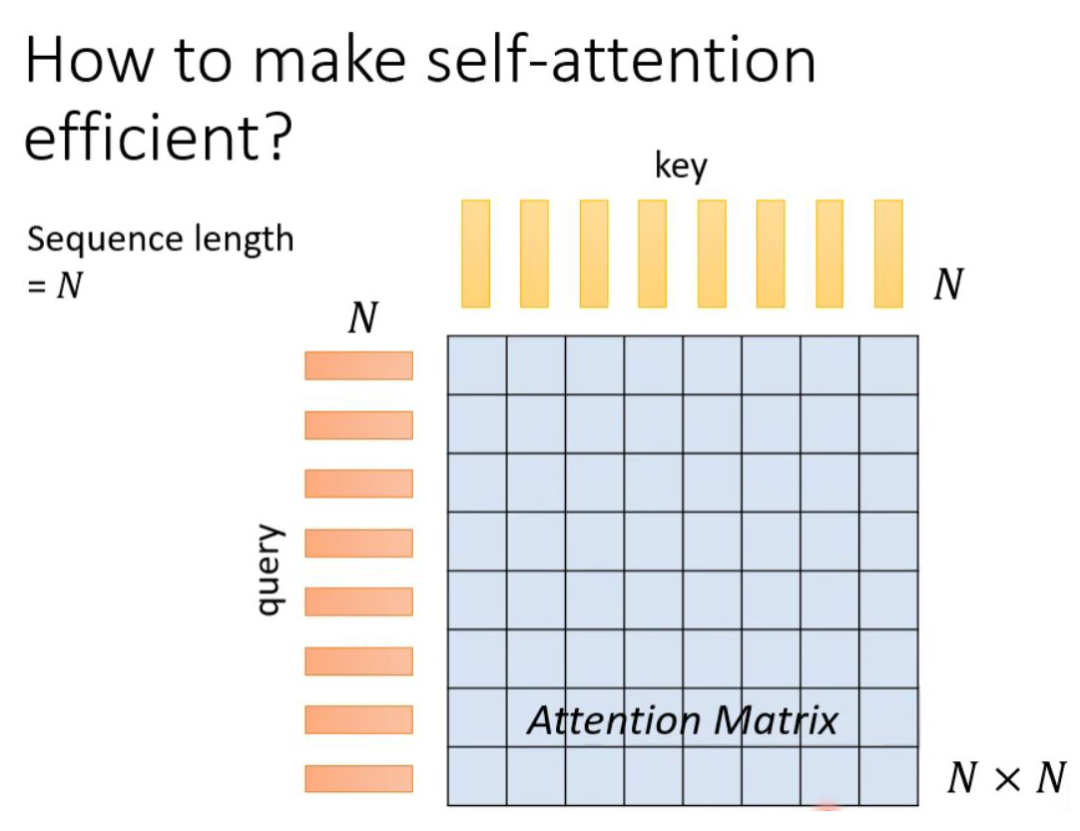
Let’s briefly review the previous self-attention. Assuming the input sequence (query) length is N, in order to capture the relationship between each value or token, N keys need to be generated correspondingly, and by performing a dot-product between the query and key, an Attention Matrix (attention matrix) can be produced, with dimensions N*N. The biggest problem with this approach is that when the sequence length is too long, the corresponding Attention Matrix dimension becomes too large, which complicates the computation.
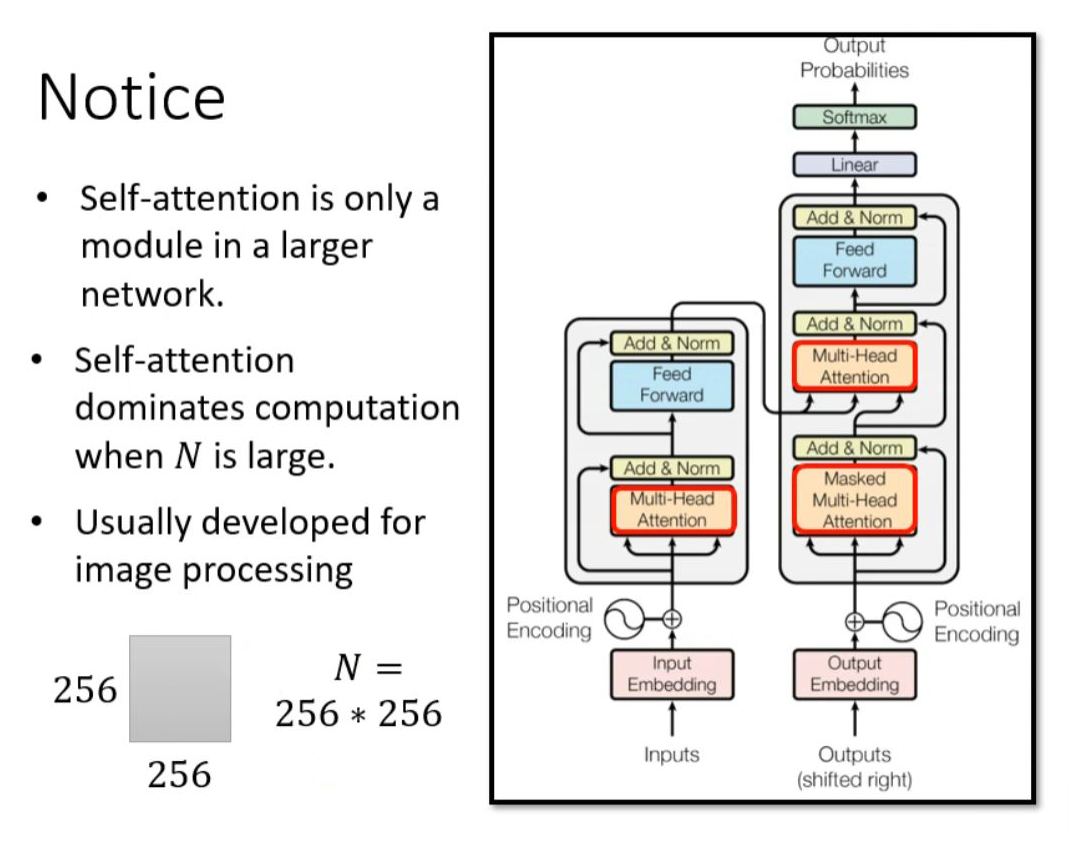
For transformers, self-attention is just one module in a larger network architecture. From the analysis above, we know that the computational load of self-attention is proportional to the square of N. When N is very small, simply increasing the computational efficiency of self-attention may not significantly impact the overall network’s computational efficiency. Therefore, improving the computational efficiency of self-attention to significantly enhance the overall network’s efficiency is predicated on N being particularly large, such as in image recognition (image processing).
How can we speed up the computation of self-attention? From the above analysis, we can see that the biggest issue affecting self-attention efficiency is the calculation of the Attention Matrix. If we can selectively compute certain values in the Attention Matrix based on some human knowledge or experience, or if we can determine some values without computation, we can theoretically reduce the computational load and improve computational efficiency.

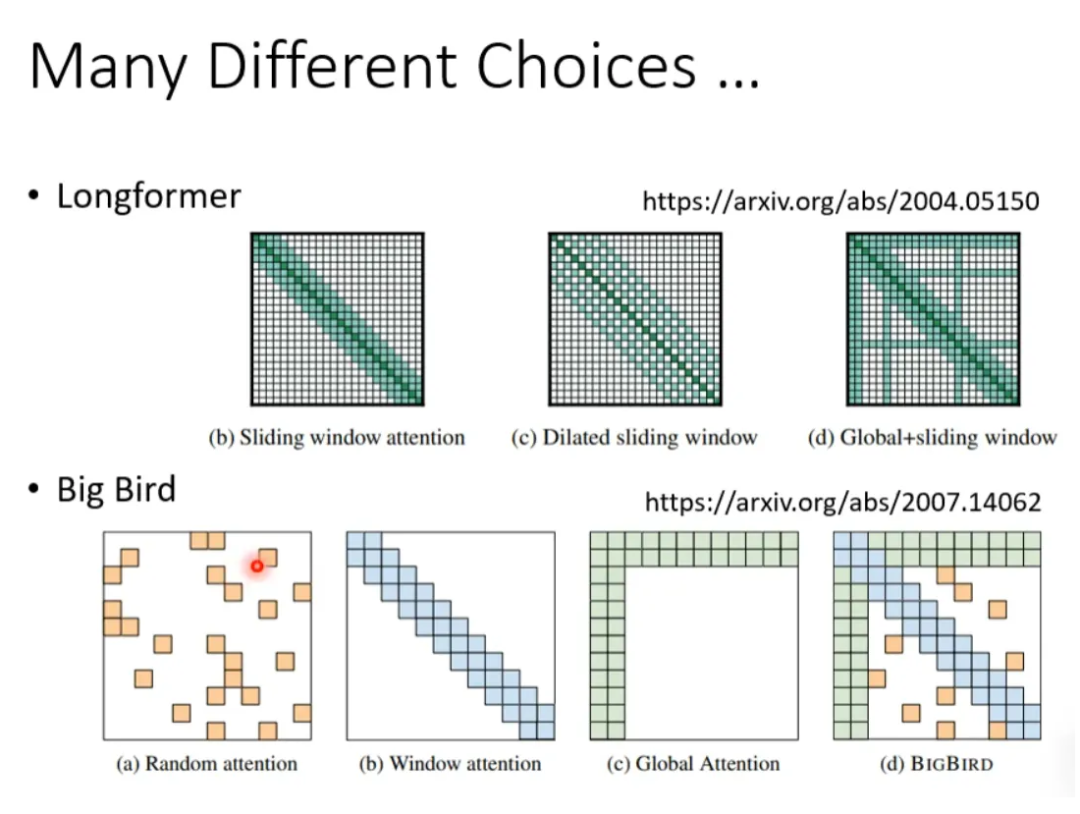
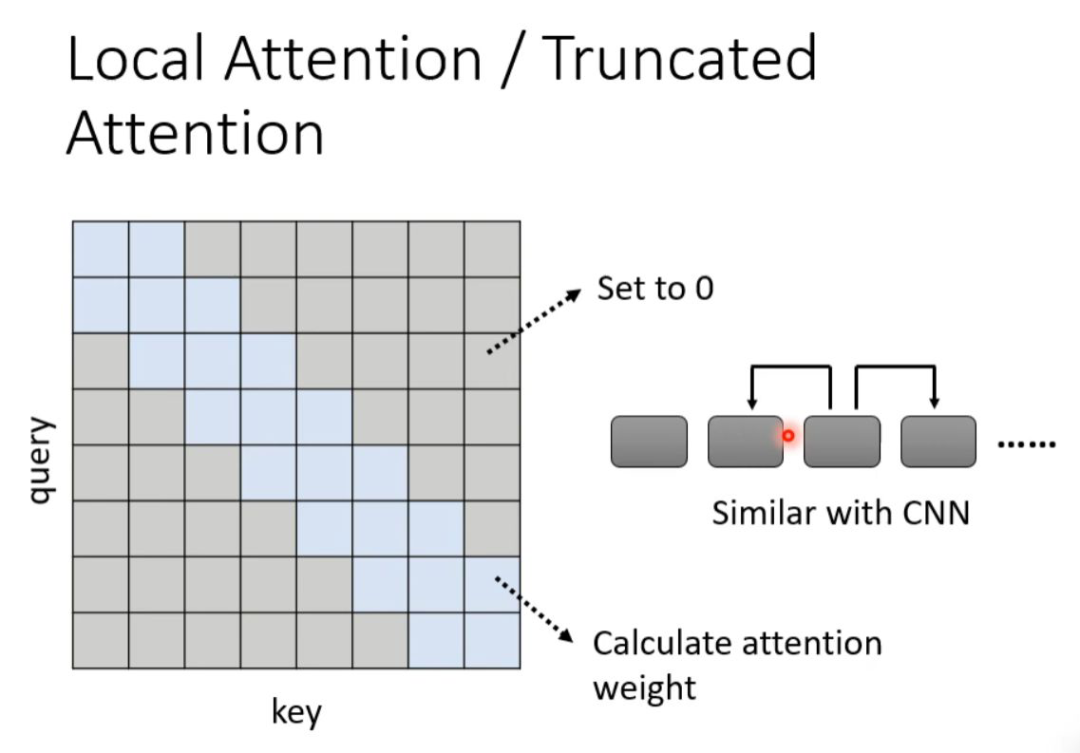
For example, when translating text, sometimes when translating the current token, it is not necessary to consider the entire sequence; it is sufficient to know the neighbors on both sides of this token, which allows for accurate translation, also known as local attention. This can greatly enhance computational efficiency, but the downside is that it only focuses on the local values around it, which is not too different from CNN.
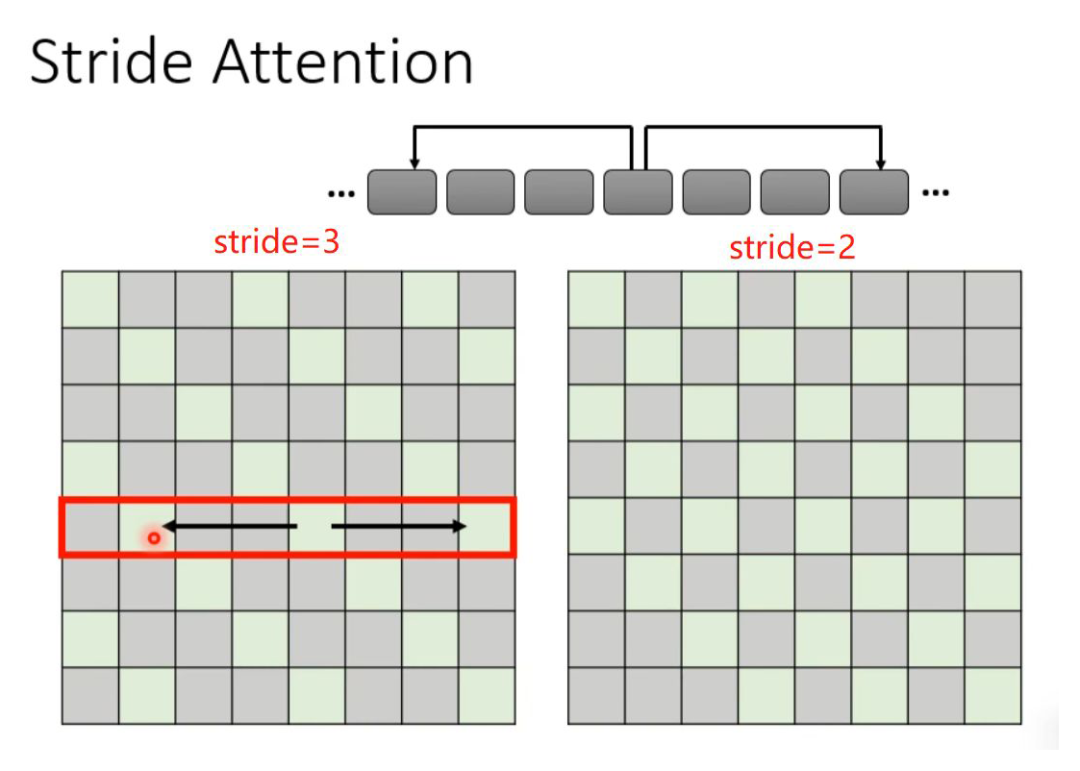
If local attention is deemed inadequate, another approach is to give the current token a certain interval (stride) of left and right neighbors to capture the relationships between the current token and both past and future tokens. Of course, the value of the stride can be determined by oneself.
Another method is global attention, where certain tokens in the sequence are selected as special tokens (such as punctuation marks), or special tokens are added to the original sequence. This allows special tokens to have global relationships with the sequence, while other tokens that are not special tokens do not have attention. For example, adding two special tokens at the beginning of the original sequence:
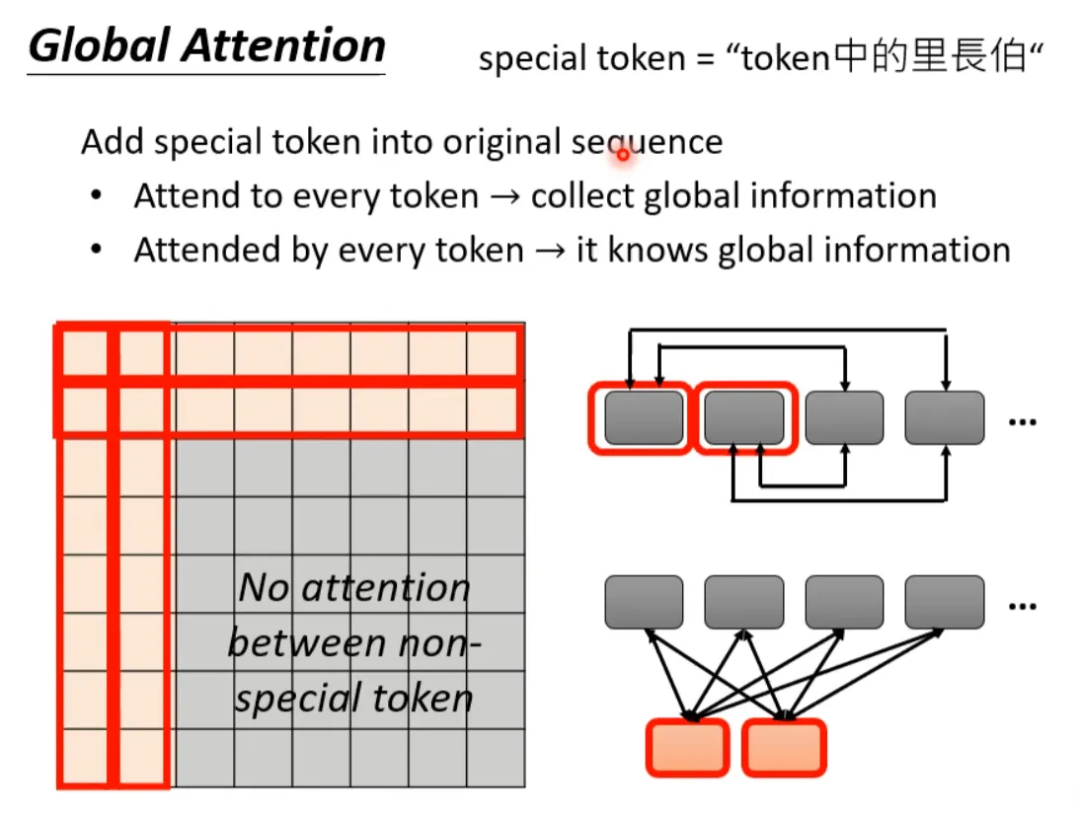
Which type of attention is the best? Only children make choices… For a network, some heads can perform local attention, while others can perform global attention… This way, no choice is needed. See the following examples:
-
Longformer combines the three types of attention mentioned above
-
Big Bird randomly selects attention assignments based on Longformer to further improve computational efficiency
The methods mentioned above are all set by humans to determine where attention needs to be calculated and where it does not, but is this the best method? Not necessarily. For the Attention Matrix, if certain position values are very small, we can directly set those positions to 0, thus not significantly affecting the actual prediction results. This means we only need to identify the values in the Attention Matrix that are relatively large. But how do we determine which positions have very small/very large values?
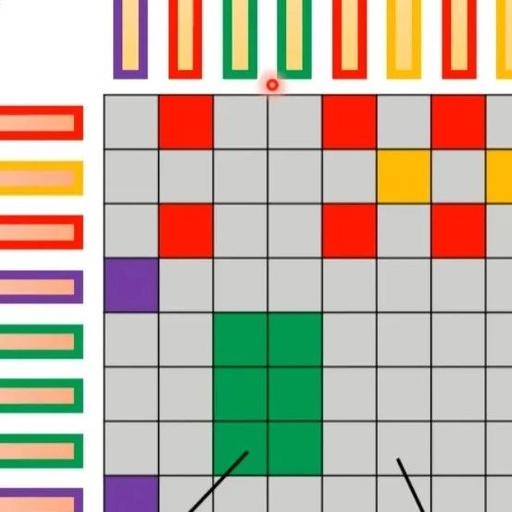
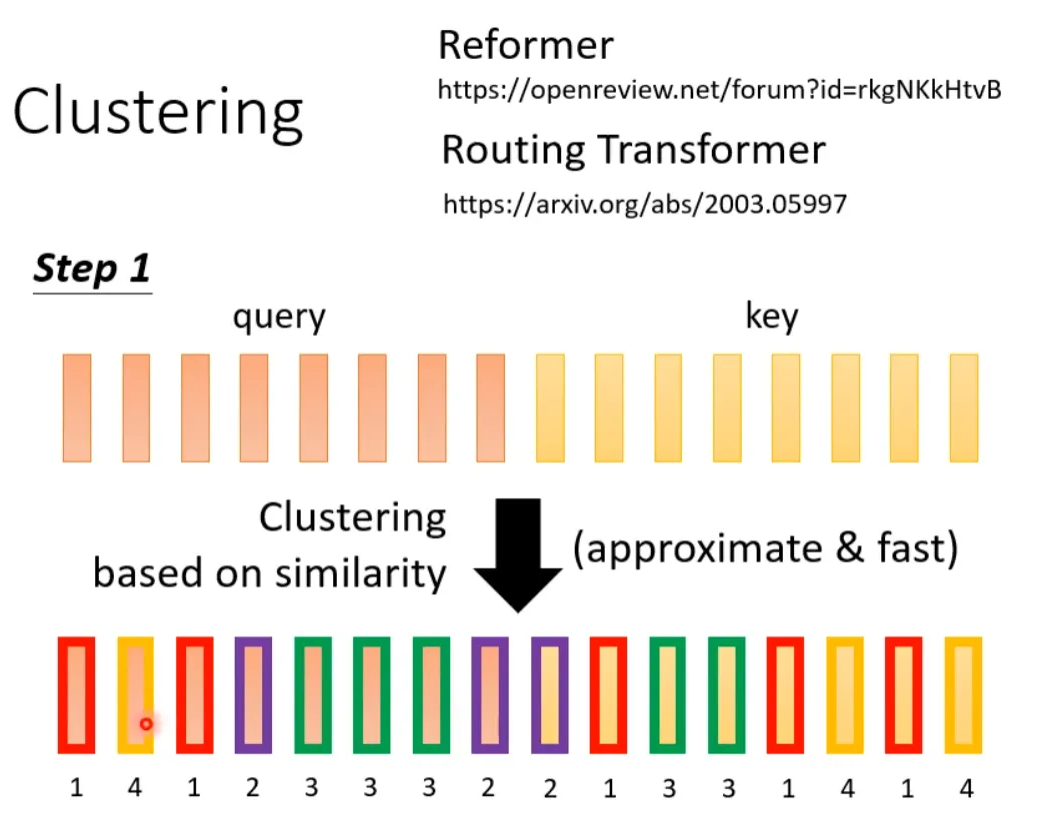
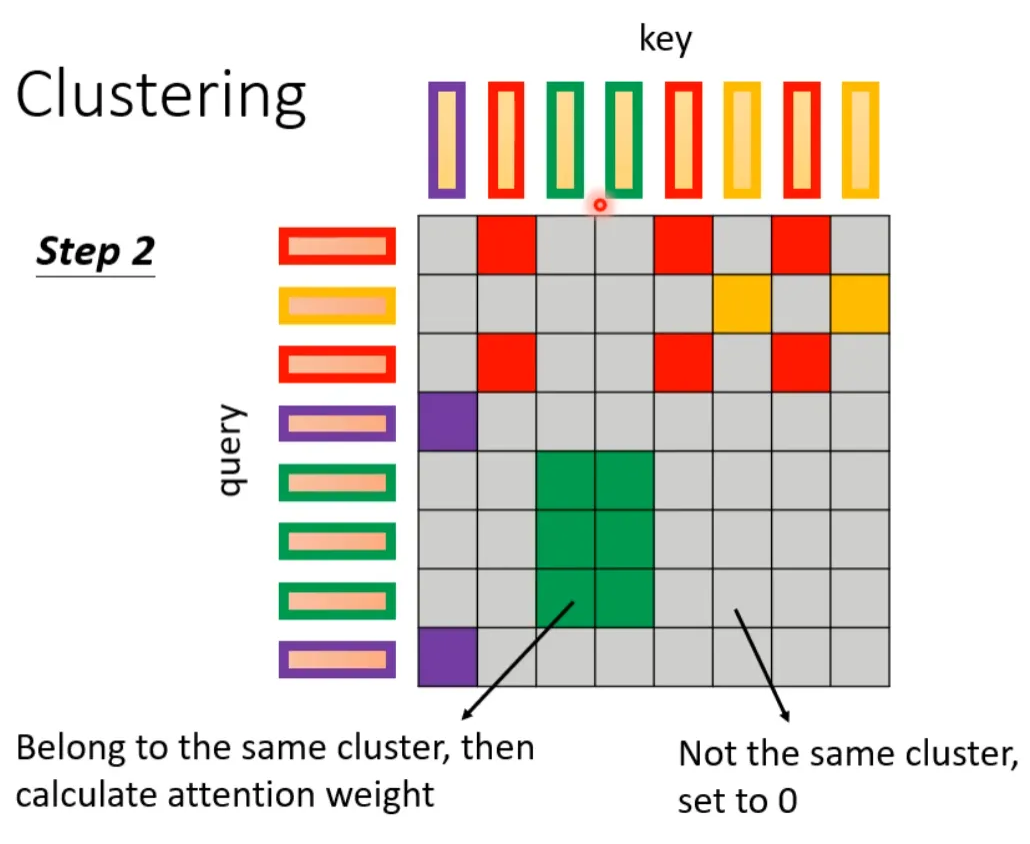
 The following two papers propose a clustering solution, where queries and keys are clustered first. Attention is calculated only for queries and keys that belong to the same class, while those that do not belong to the same class do not participate in the calculation, thus speeding up the Attention Matrix computation. For example, in the following case, there are four classes: 1 (red box), 2 (purple box), 3 (green box), 4 (yellow box). The two papers introduce methods for quickly clustering.
The following two papers propose a clustering solution, where queries and keys are clustered first. Attention is calculated only for queries and keys that belong to the same class, while those that do not belong to the same class do not participate in the calculation, thus speeding up the Attention Matrix computation. For example, in the following case, there are four classes: 1 (red box), 2 (purple box), 3 (green box), 4 (yellow box). The two papers introduce methods for quickly clustering.
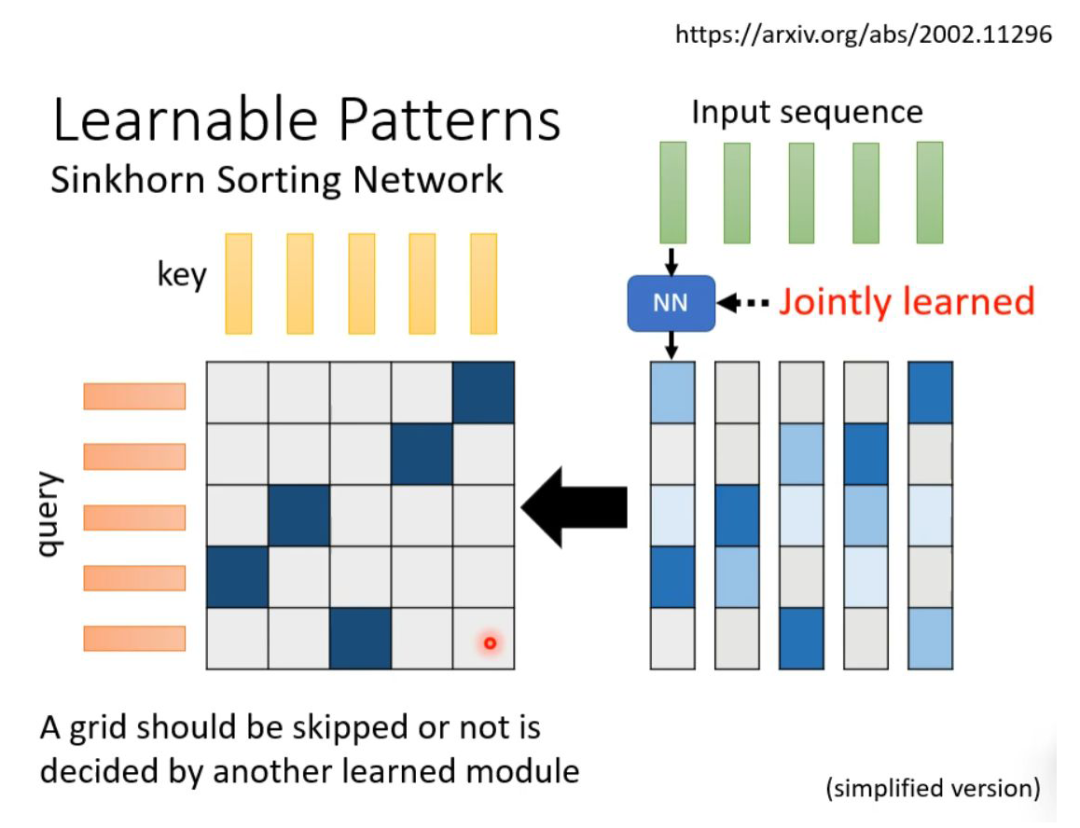
 Is there a way to learn whether to calculate attention or not? It is possible. We can train another network, where the input is the input sequence, and the output is a weight sequence of the same length. By concatenating all weight sequences and transforming them, we can obtain a matrix indicating where attention needs to be calculated and where it does not. One detail is that certain different sequences may output the same weight sequence through the neural network, which can greatly reduce the computational load.
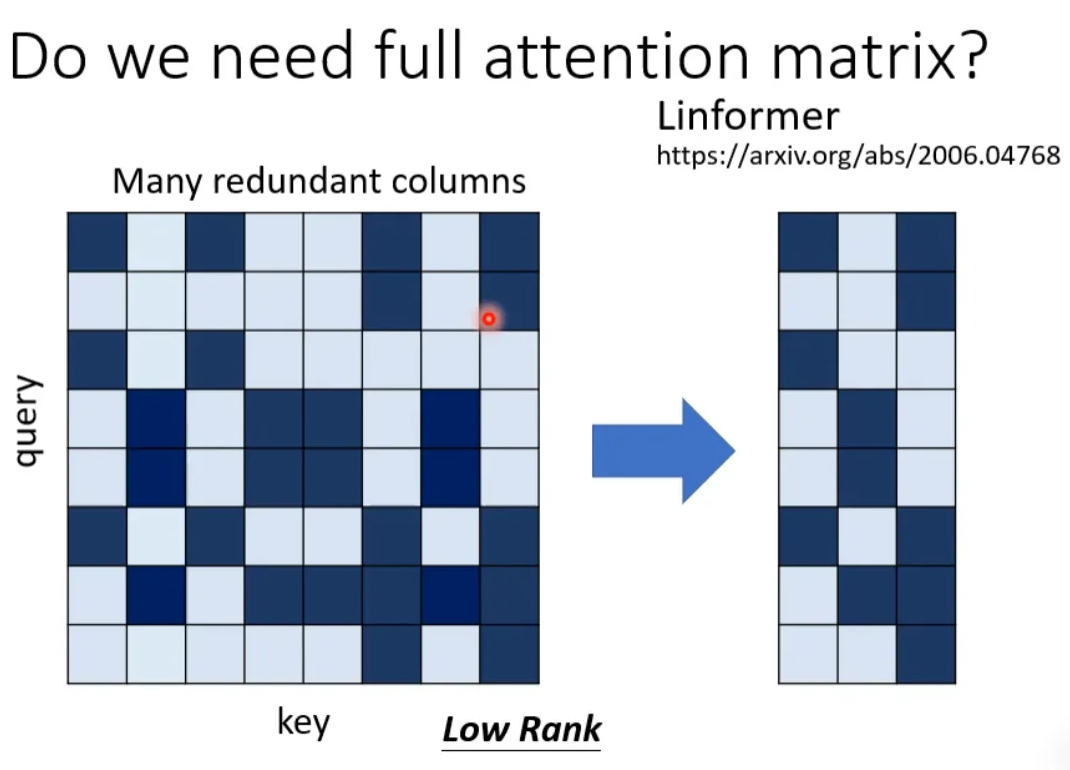
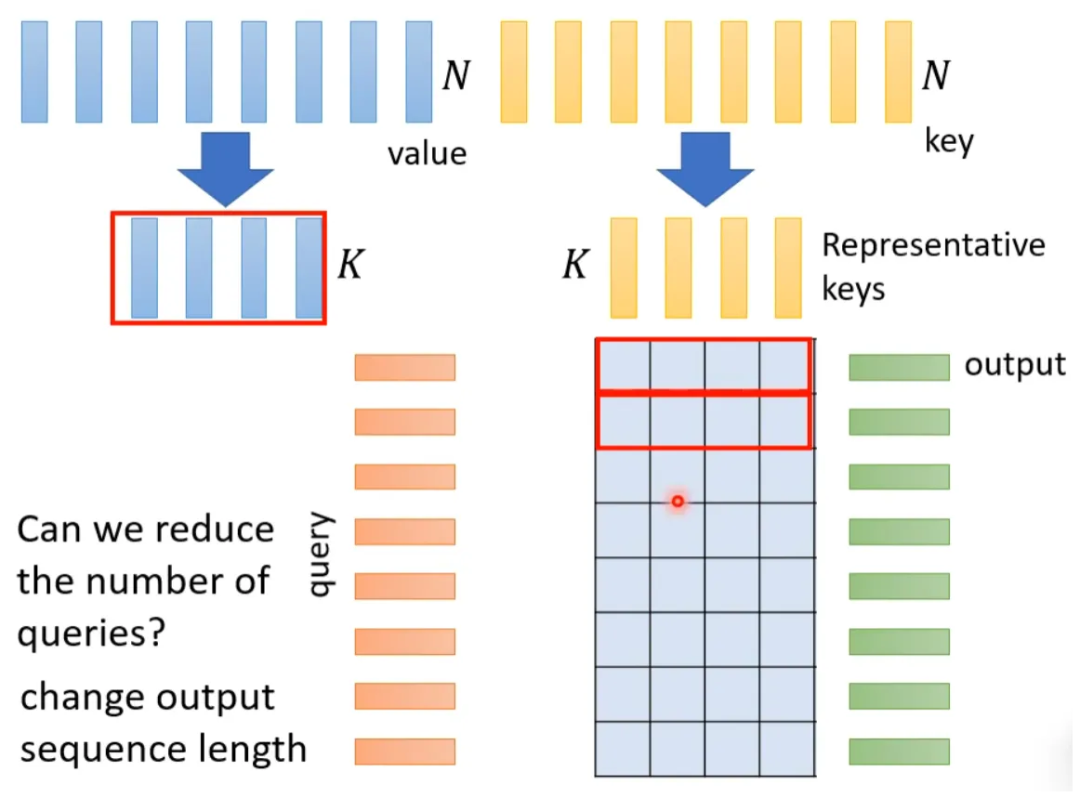
What we discussed above is an N*N matrix, but in reality, such a matrix is generally not full rank, which means we can reduce the dimensionality of the original N*N matrix, removing duplicate columns to obtain a smaller matrix.
Specifically, select K representative keys from N keys, each key corresponding to a value, and then perform a dot product with the query. Then perform gradient descent to update the values.
Why select representative keys instead of representative queries? Because queries correspond to outputs, thus the output will be shortened leading to information loss.
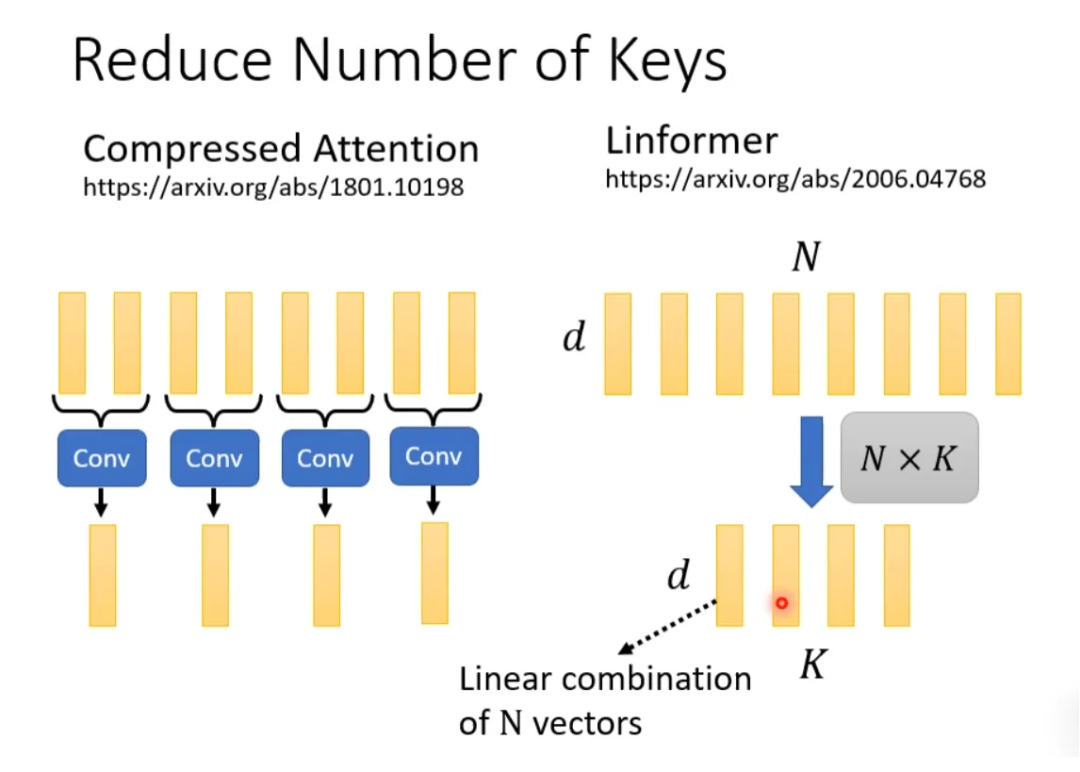
How to select representative keys? Here are two methods: one is to directly convolve (conv) the keys, and the other is to perform matrix multiplication with a matrix.
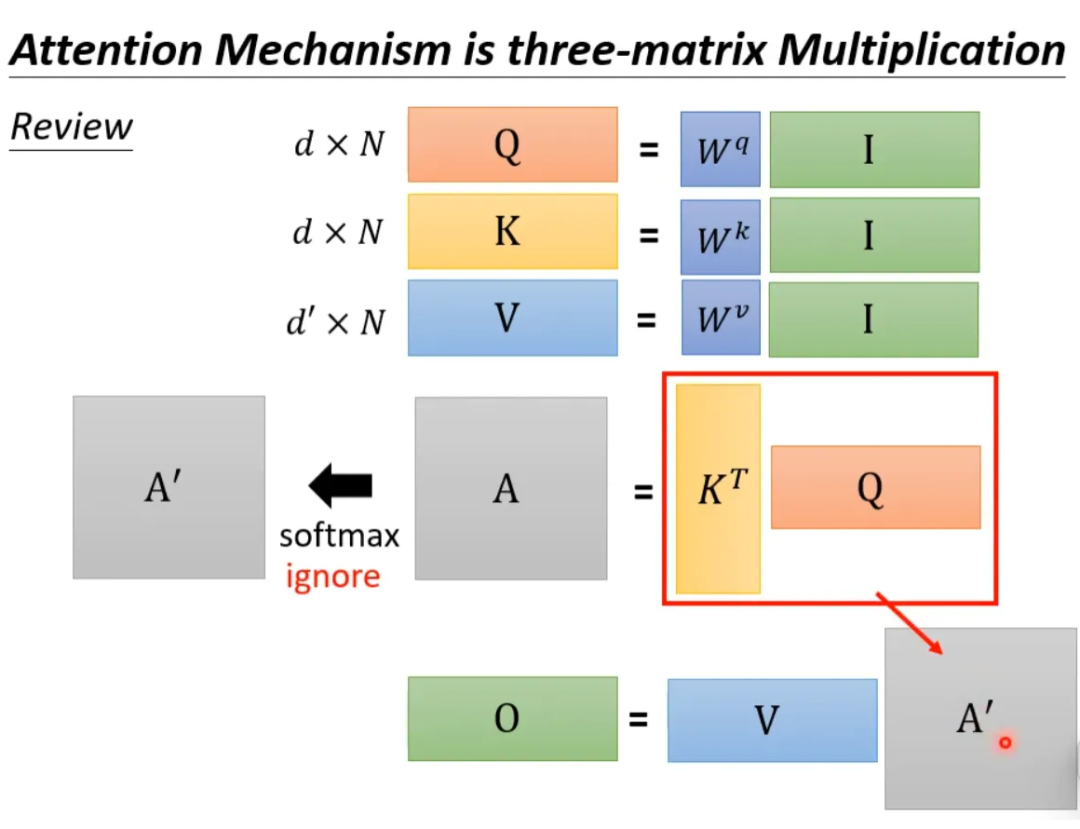
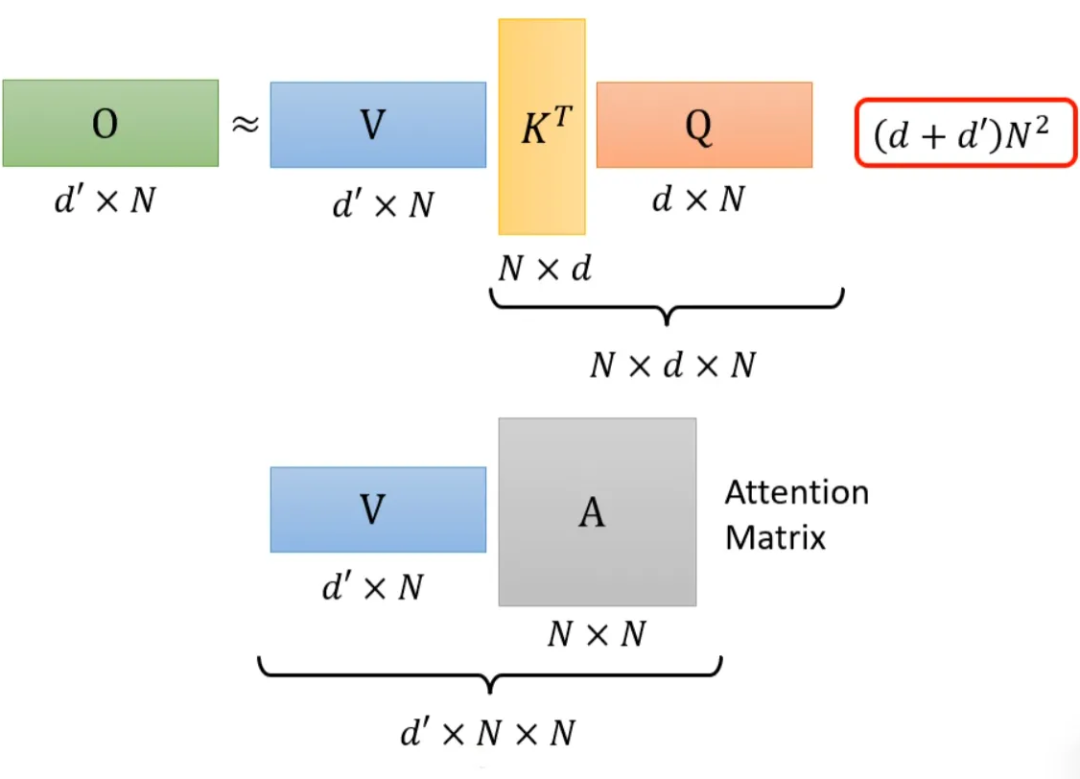
Let’s review the computation process of the attention mechanism, where I is the input matrix and O is the output matrix.
First, ignore softmax, and it can be expressed in the following form:
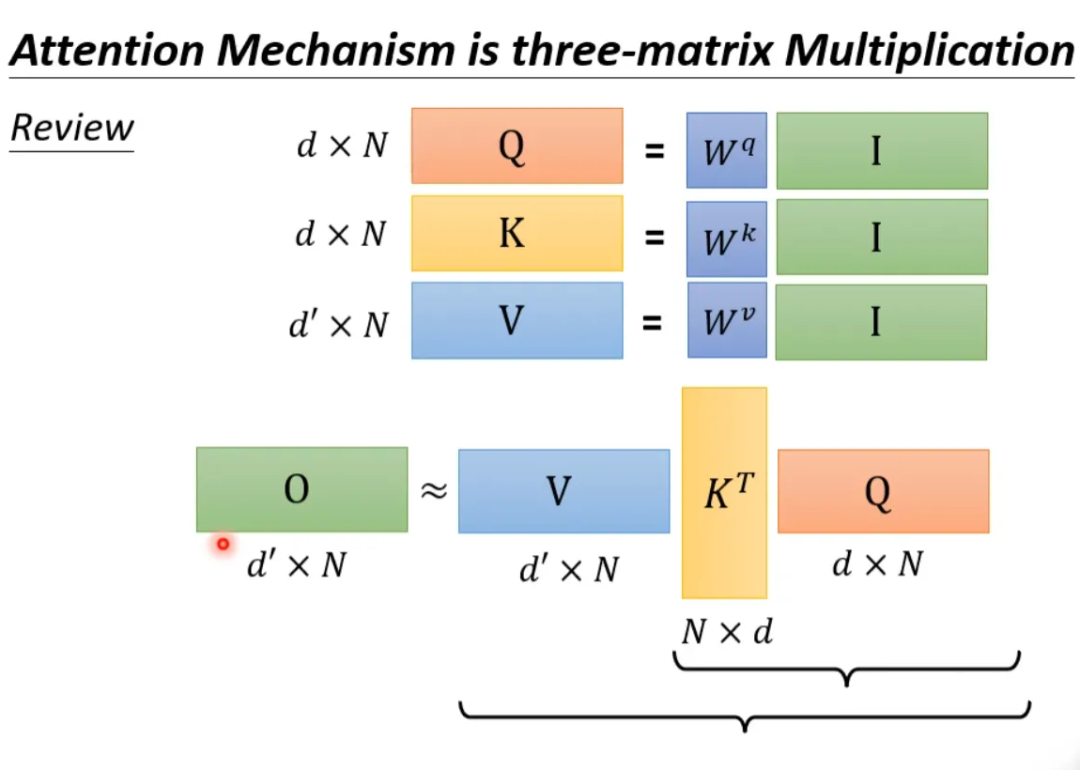
The above process can be accelerated. If we perform V*K^T first and then multiply by Q, it results in the same outcome, but the computational load is significantly reduced compared to K^T*Q being multiplied by V.
Appendix: Explanation of linear algebra regarding this part
Still using the previous example for explanation. If K^T*Q, it will perform N*d*N multiplications. V*A will perform d’*N*N multiplications, so the total required computational load is (d+d’)N^2.
If V*K^T, it will perform d’*N*d multiplications. Then multiplying by Q will perform d’*d*N multiplications, so the total required computational load is 2*d’*d*N.
And (d+d’)N^2 >> 2*d’*d*N, so by changing the order of operations, we can significantly improve computational efficiency.
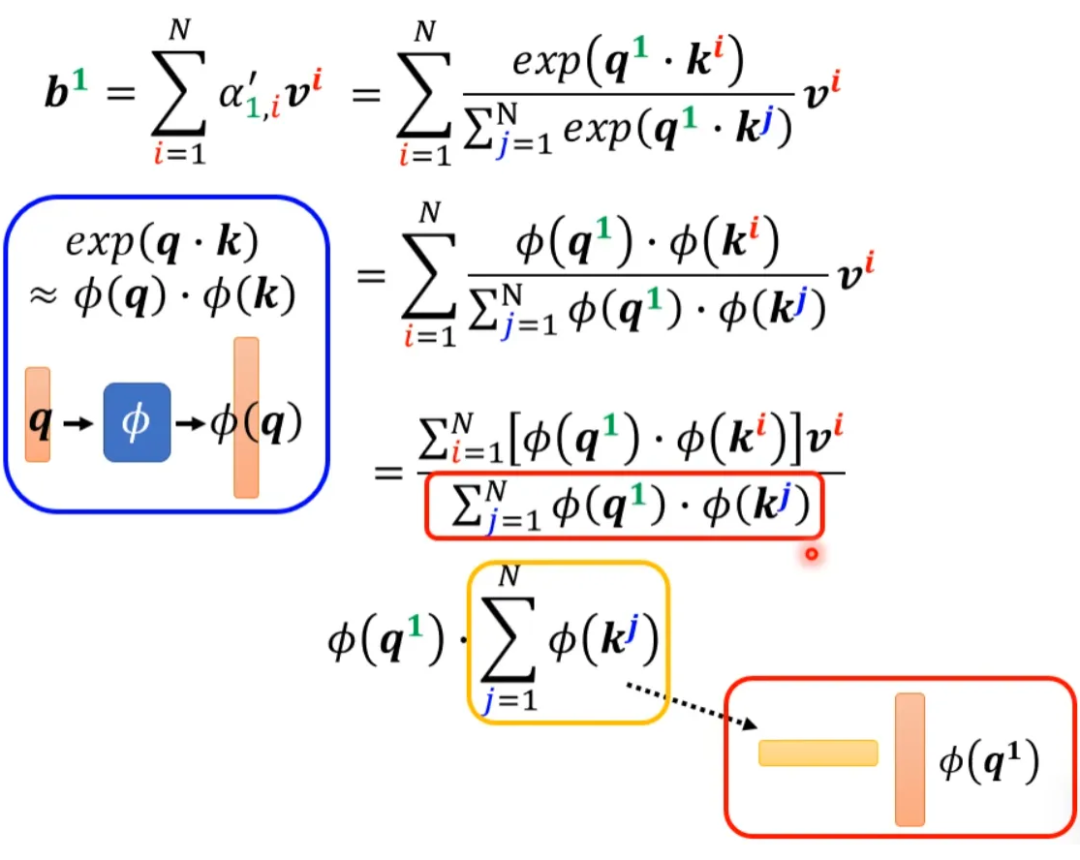
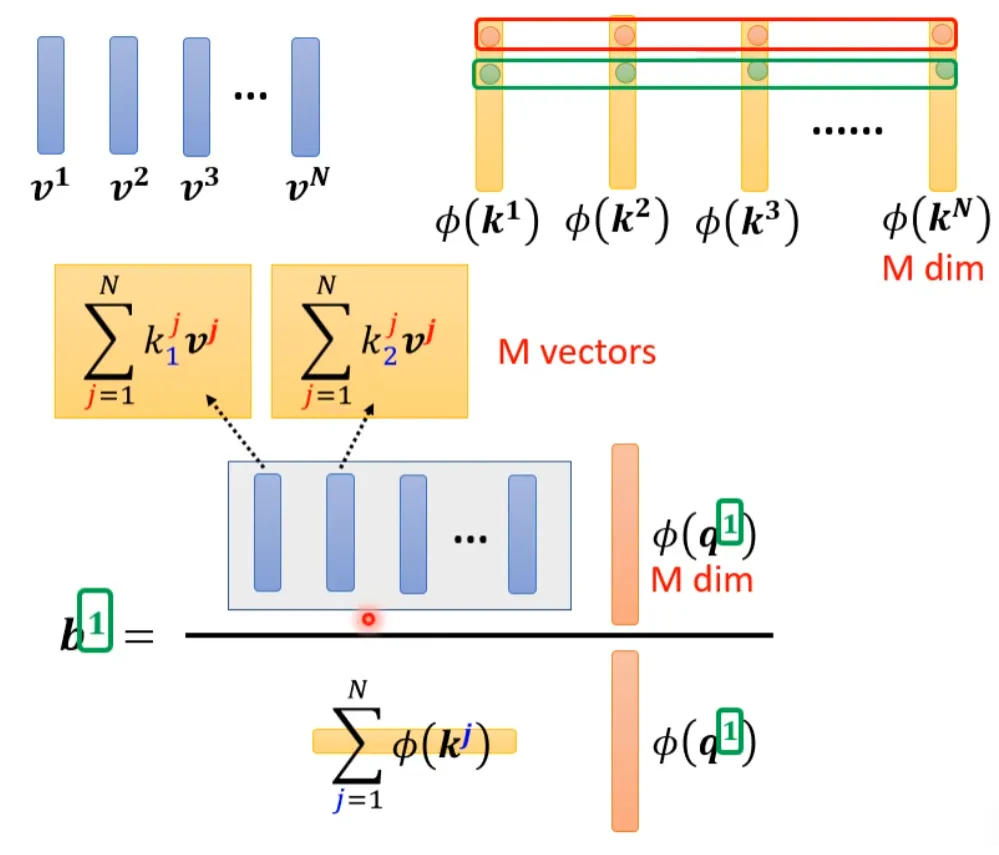
Now let’s bring back softmax. The original self-attention looks like this, taking the calculation of b1 as an example:
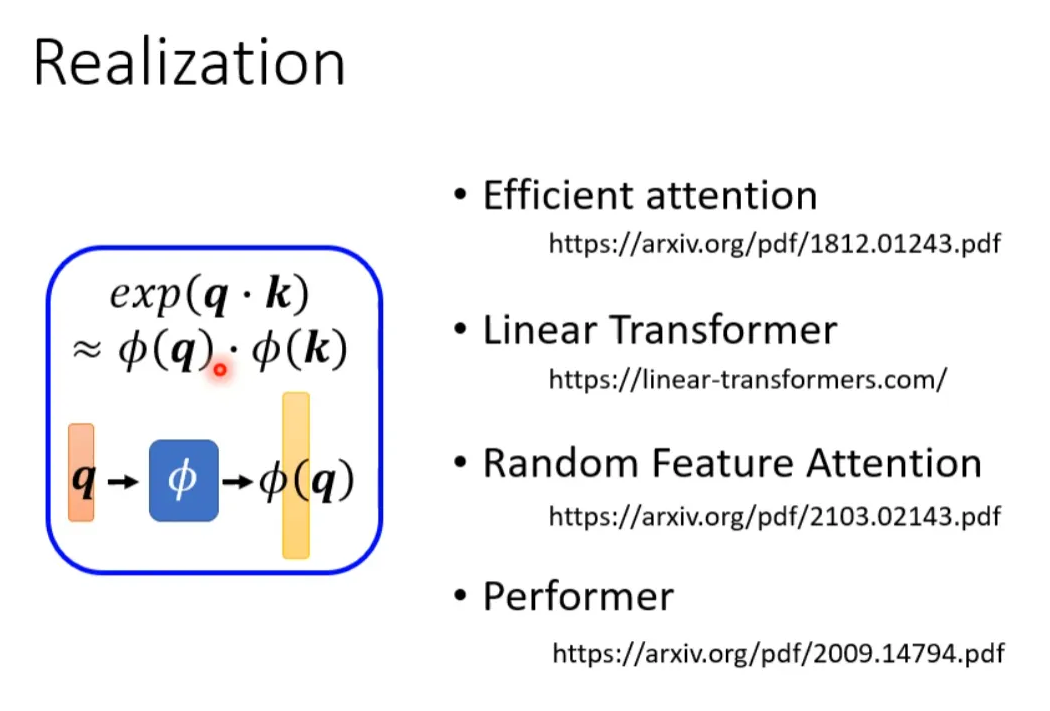
If we can transform exp(q*k) into the form of multiplying two mappings, we can further simplify the above expression:
▲ Simplification of the denominator
▲ Simplification of the numerator
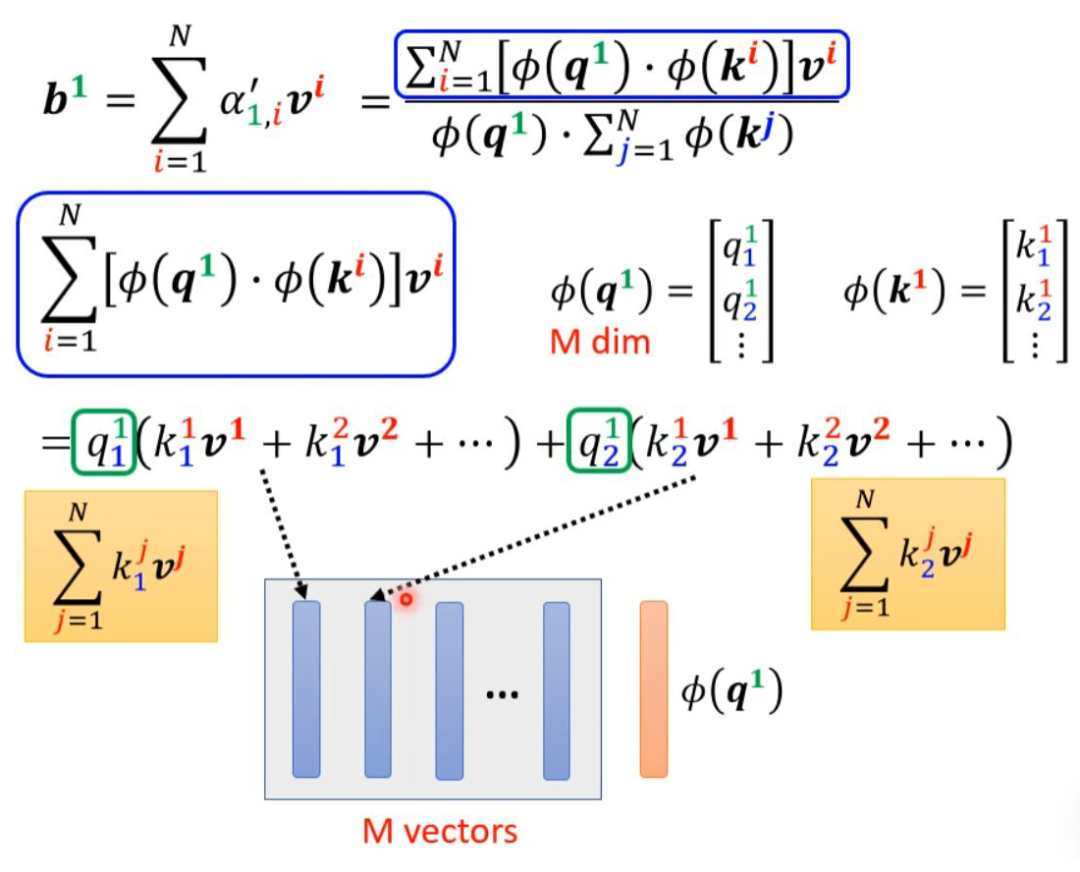
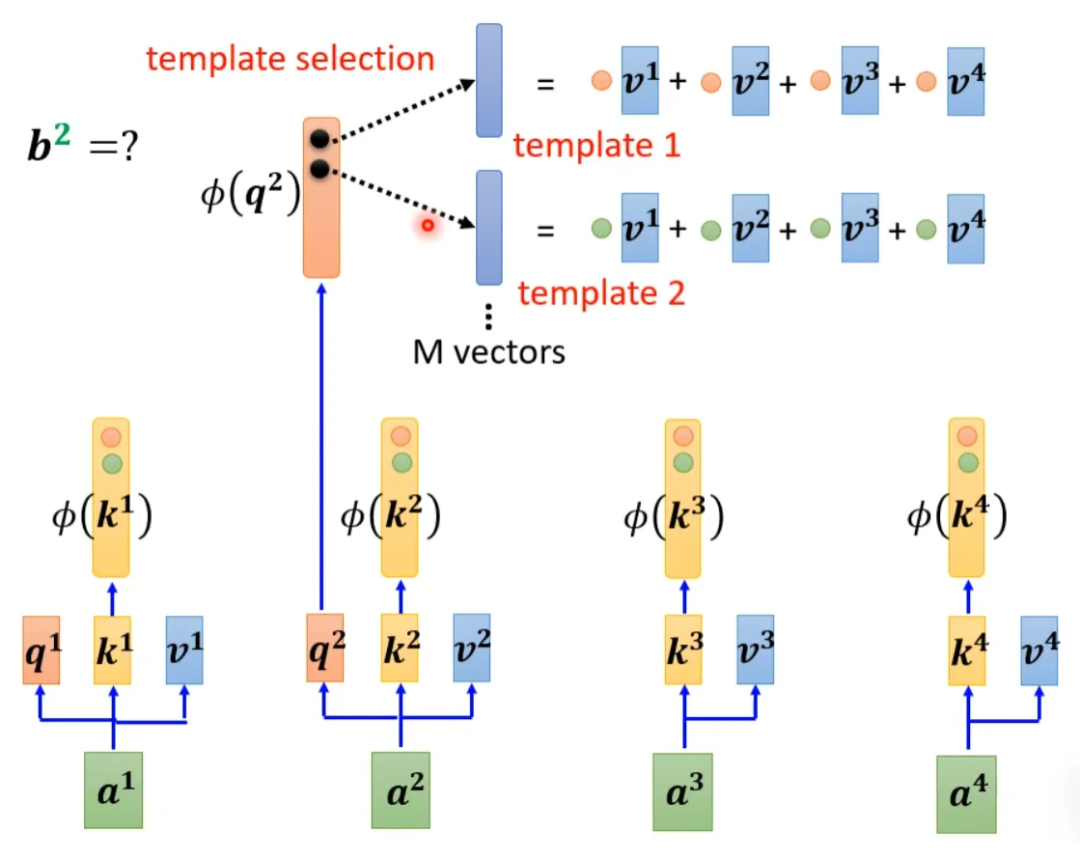
Taking the contents inside the parentheses as a vector, M vectors form an M-dimensional matrix, which is multiplied by φ(q1) to obtain the numerator.
Graphical representation is as follows:
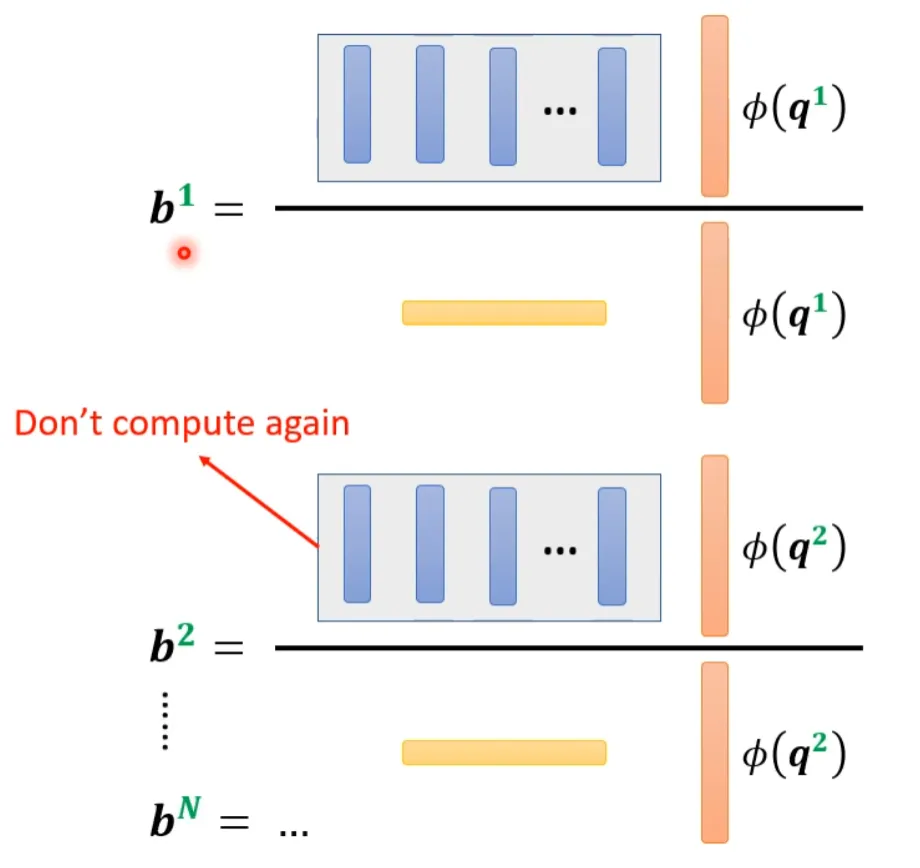
From the above, it can be seen that the blue vector and the yellow vector are actually irrelevant to the 1 in b1. This means that when calculating b2, b3…, the blue vector and yellow vector do not need to be recalculated.
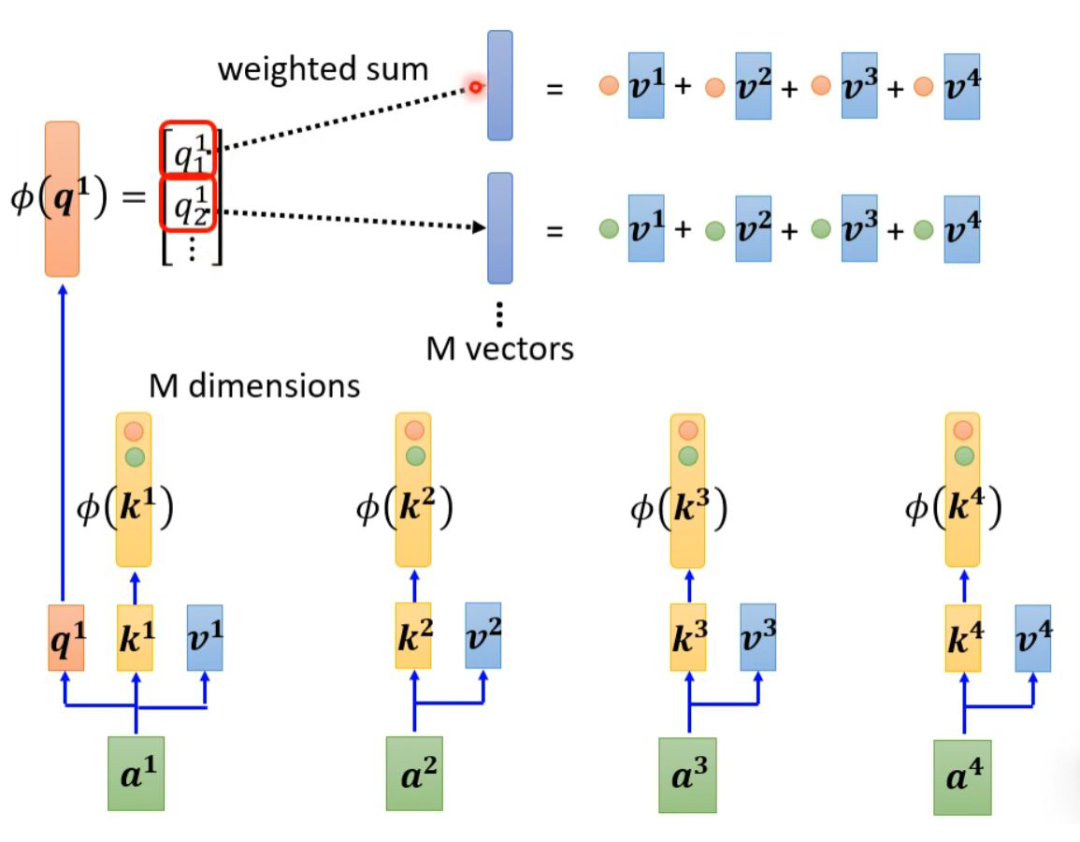
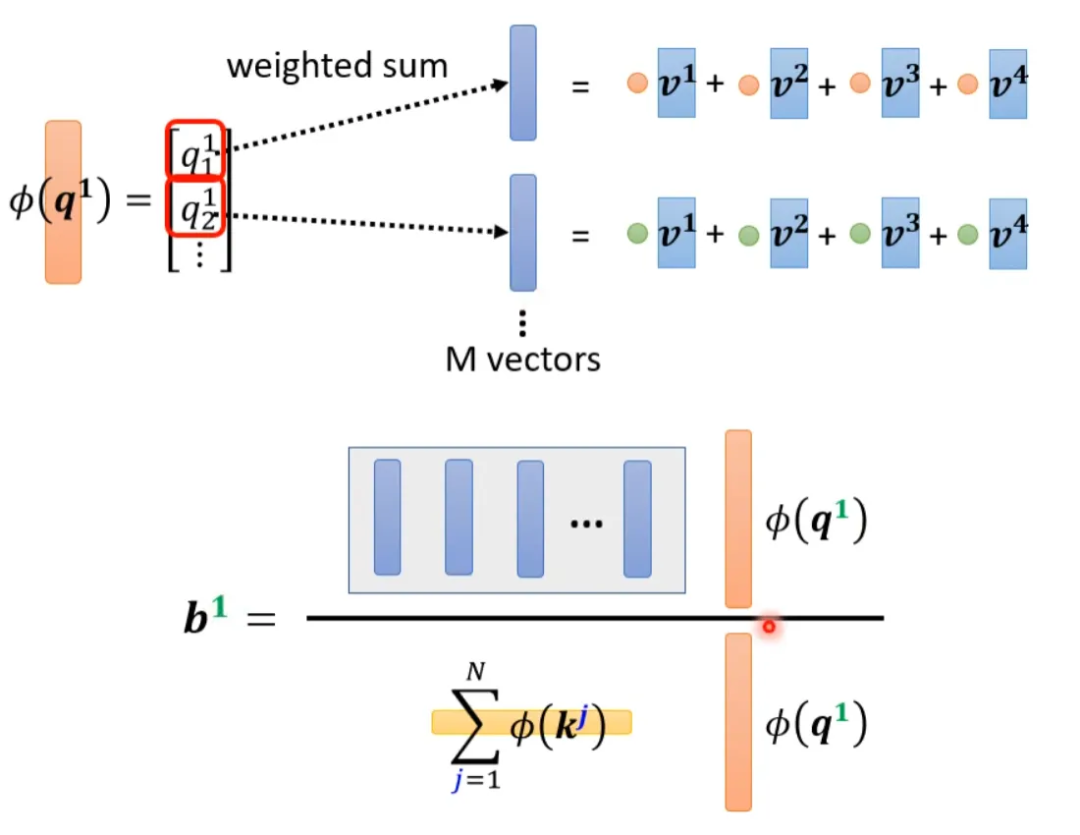
Self-attention can also be viewed from another perspective. This computation method yields results almost identical to those of the original self-attention, but with significantly reduced computational load. In simple terms, first find a transformation φ(), transform k, and then perform a dot product with v to obtain an M-dimensional vector. Then transform q and multiply it with the M-dimensional vector. The M-dimensional vector only needs to be computed once.
The calculation for b1 is as follows:
The calculation for b2 is as follows:
This can be understood as treating φ(k) and the vector calculated with v as a template, and using φ(q) to find out which template is the most important, and perform matrix operations to obtain the output b.
So how to choose φ? Different literature has different methods:
Do we always need q and k when computing self-attention? Not necessarily. In the Synthesizer literature, the attention matrix is not obtained through q and k, but learned as network parameters. Although different input sequences correspond to the same attention weights, performance does not degrade significantly. This raises a thought: what is the actual value of attention?
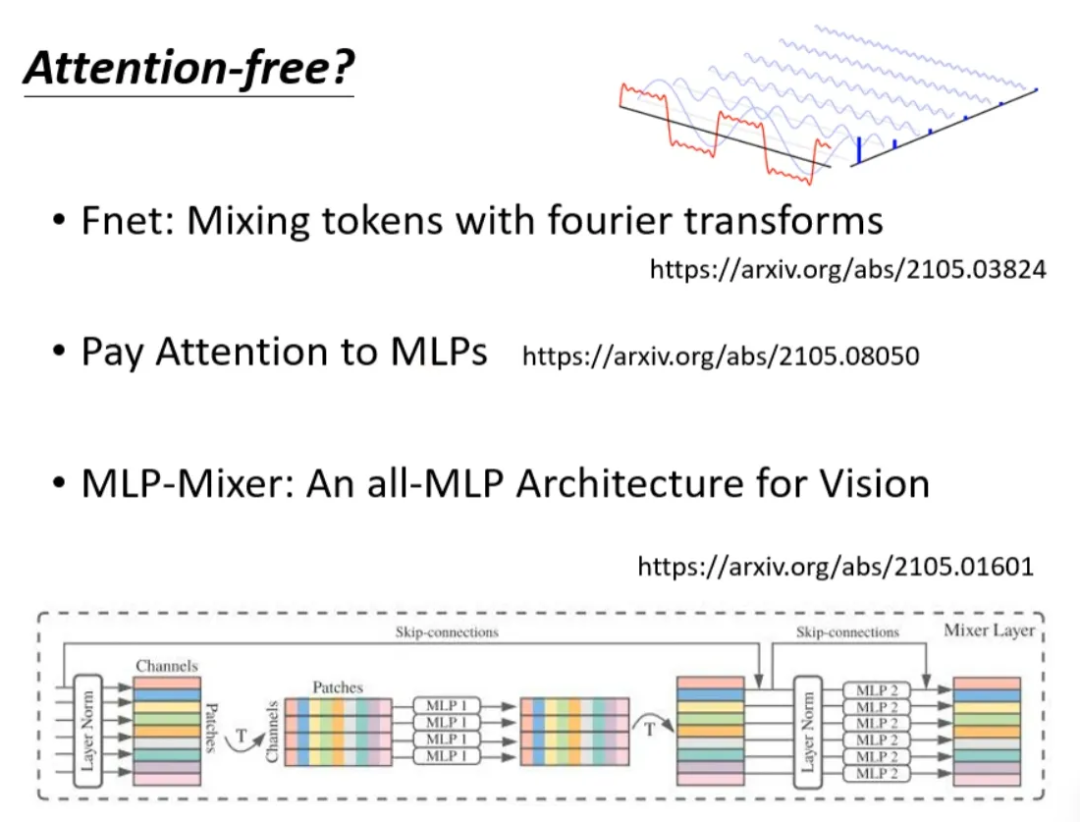
Is it necessary to use attention to process sequences? Can we try to discard attention? Are there attention-free methods? Below are several MLP methods used to replace attention in sequence processing.
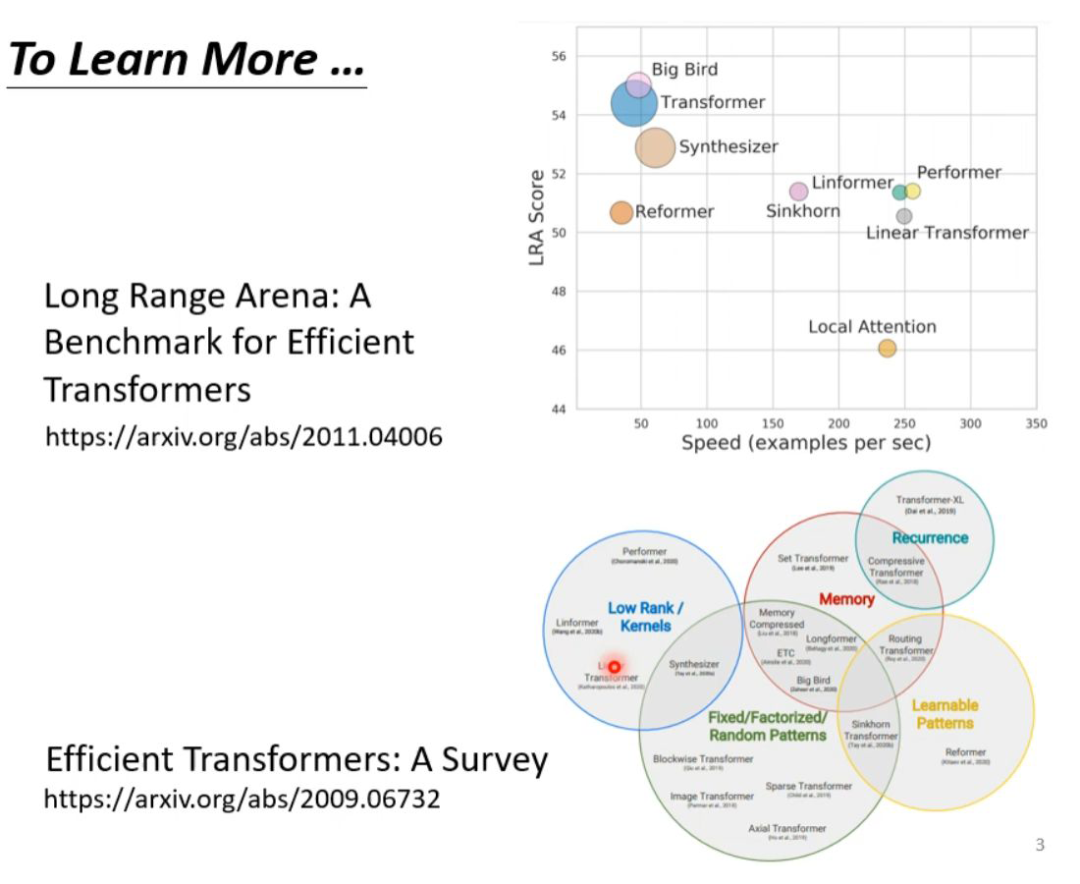
The last page summarizes all the methods discussed today. In the figure below, the vertical axis represents the LRA score, where a higher value indicates better network performance; the horizontal axis indicates how many sequences can be processed per second, with further right indicating faster speed; larger circles represent more memory usage (greater computational load).
That concludes the summary of Professor Li’s class on “Various Fascinating Self-Attention Mechanisms”.
Technical Group Invitation
Is there a way to learn whether to calculate attention or not? It is possible. We can train another network, where the input is the input sequence, and the output is a weight sequence of the same length. By concatenating all weight sequences and transforming them, we can obtain a matrix indicating where attention needs to be calculated and where it does not. One detail is that certain different sequences may output the same weight sequence through the neural network, which can greatly reduce the computational load.
What we discussed above is an N*N matrix, but in reality, such a matrix is generally not full rank, which means we can reduce the dimensionality of the original N*N matrix, removing duplicate columns to obtain a smaller matrix.
Specifically, select K representative keys from N keys, each key corresponding to a value, and then perform a dot product with the query. Then perform gradient descent to update the values.
Why select representative keys instead of representative queries? Because queries correspond to outputs, thus the output will be shortened leading to information loss.
How to select representative keys? Here are two methods: one is to directly convolve (conv) the keys, and the other is to perform matrix multiplication with a matrix.
Let’s review the computation process of the attention mechanism, where I is the input matrix and O is the output matrix.
First, ignore softmax, and it can be expressed in the following form:
The above process can be accelerated. If we perform V*K^T first and then multiply by Q, it results in the same outcome, but the computational load is significantly reduced compared to K^T*Q being multiplied by V.
Appendix: Explanation of linear algebra regarding this part
Still using the previous example for explanation. If K^T*Q, it will perform N*d*N multiplications. V*A will perform d’*N*N multiplications, so the total required computational load is (d+d’)N^2.
If V*K^T, it will perform d’*N*d multiplications. Then multiplying by Q will perform d’*d*N multiplications, so the total required computational load is 2*d’*d*N.
And (d+d’)N^2 >> 2*d’*d*N, so by changing the order of operations, we can significantly improve computational efficiency.
Now let’s bring back softmax. The original self-attention looks like this, taking the calculation of b1 as an example:
If we can transform exp(q*k) into the form of multiplying two mappings, we can further simplify the above expression:
▲ Simplification of the denominator
▲ Simplification of the numerator
Taking the contents inside the parentheses as a vector, M vectors form an M-dimensional matrix, which is multiplied by φ(q1) to obtain the numerator.
Graphical representation is as follows:
From the above, it can be seen that the blue vector and the yellow vector are actually irrelevant to the 1 in b1. This means that when calculating b2, b3…, the blue vector and yellow vector do not need to be recalculated.
Self-attention can also be viewed from another perspective. This computation method yields results almost identical to those of the original self-attention, but with significantly reduced computational load. In simple terms, first find a transformation φ(), transform k, and then perform a dot product with v to obtain an M-dimensional vector. Then transform q and multiply it with the M-dimensional vector. The M-dimensional vector only needs to be computed once.
The calculation for b1 is as follows:
The calculation for b2 is as follows:
This can be understood as treating φ(k) and the vector calculated with v as a template, and using φ(q) to find out which template is the most important, and perform matrix operations to obtain the output b.
So how to choose φ? Different literature has different methods:
Do we always need q and k when computing self-attention? Not necessarily. In the Synthesizer literature, the attention matrix is not obtained through q and k, but learned as network parameters. Although different input sequences correspond to the same attention weights, performance does not degrade significantly. This raises a thought: what is the actual value of attention?
Is it necessary to use attention to process sequences? Can we try to discard attention? Are there attention-free methods? Below are several MLP methods used to replace attention in sequence processing.
The last page summarizes all the methods discussed today. In the figure below, the vertical axis represents the LRA score, where a higher value indicates better network performance; the horizontal axis indicates how many sequences can be processed per second, with further right indicating faster speed; larger circles represent more memory usage (greater computational load).
That concludes the summary of Professor Li’s class on “Various Fascinating Self-Attention Mechanisms”.
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant on WeChat
Please note: Name – School/Company – Research Direction
(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue System)
to apply to join the Natural Language Processing/PyTorch and other technical groups
About Us
MLNLP community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from both domestic and international backgrounds. It has developed into a well-known community for machine learning and natural language processing, aimed at promoting progress among scholars, industry practitioners, and enthusiasts in machine learning and natural language processing.
The community provides an open platform for communication regarding further studies, employment, and research for related practitioners. Everyone is welcome to follow and join us.