
Source: Internet
Introduction
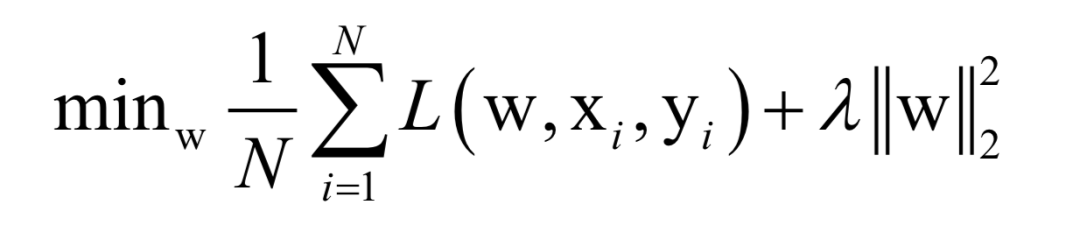
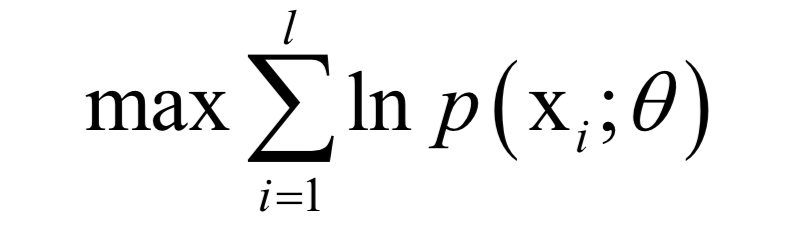
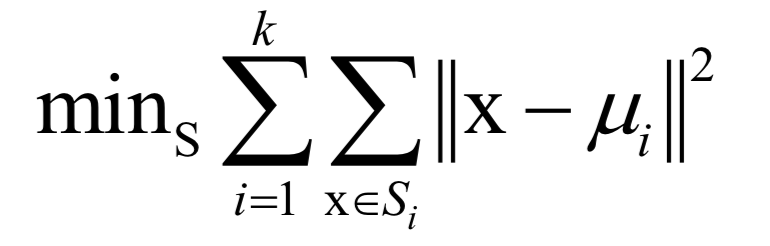
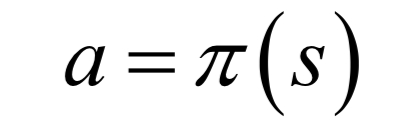
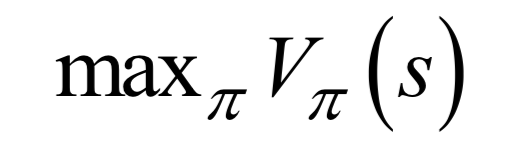
-
Analytical Solution
-
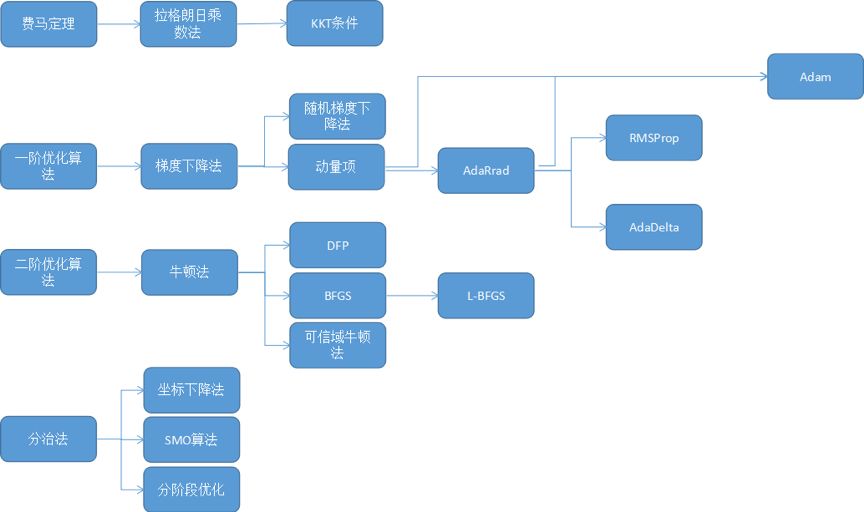
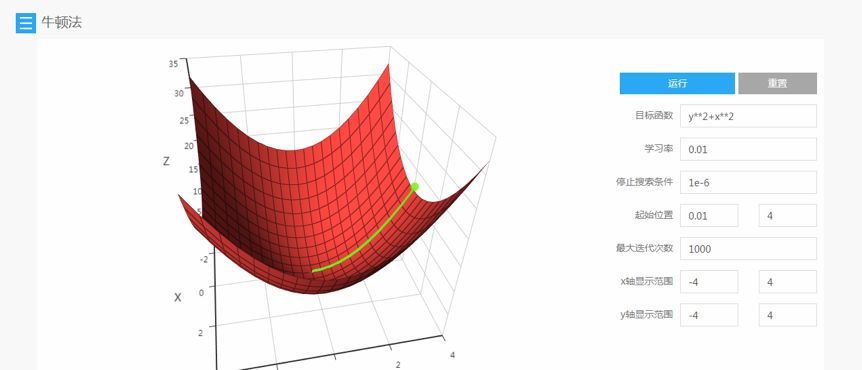
Numerical Optimization
-
Can correctly find extreme points in various situations
-
Fast speed
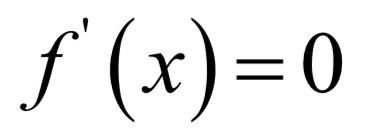

-
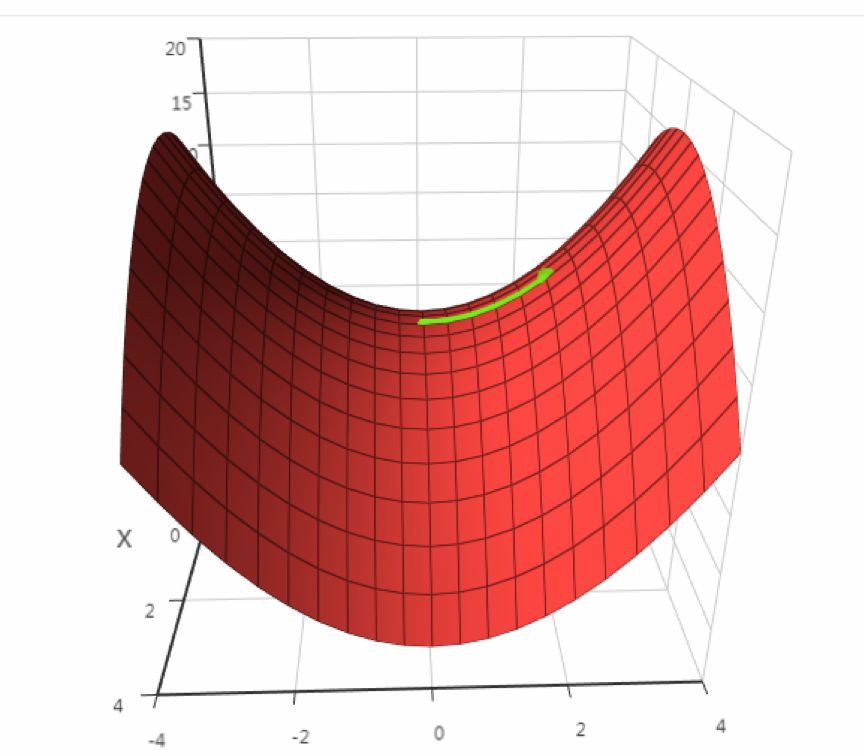
If f”(x) > 0, then it is a minimum at that point
-
If f”(x) < 0, then it is a maximum at that point
-
If f”(x) >= 0, further examination of higher-order derivatives is needed
-
If the Hessian matrix is positive definite, the function has a minimum at that point
-
If the Hessian matrix is negative definite, the function has a maximum at that point
-
If the Hessian matrix is indefinite, further examination is needed (this part is incorrect)
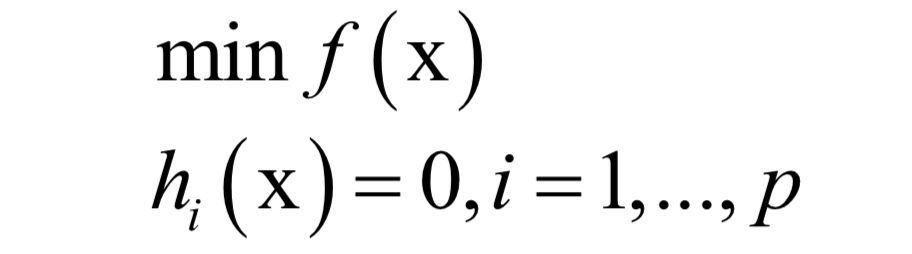
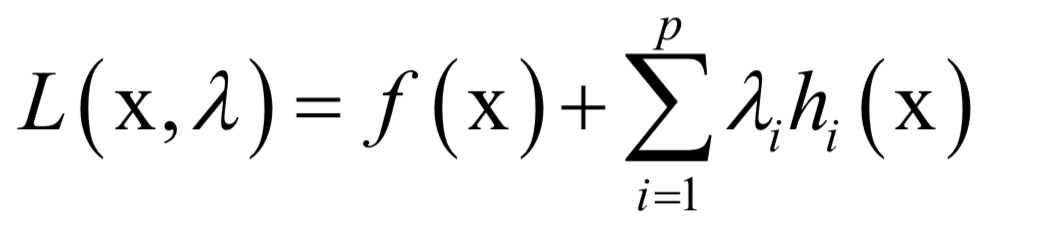
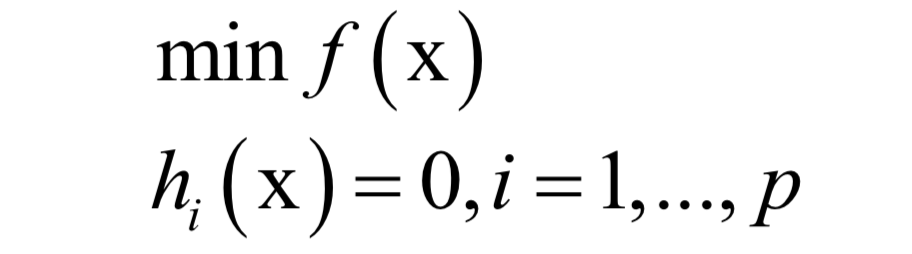
-
Principal Component Analysis
-
Linear Discriminant Analysis
-
Laplacian Eigenmaps in Manifold Learning
-
Hidden Markov Model
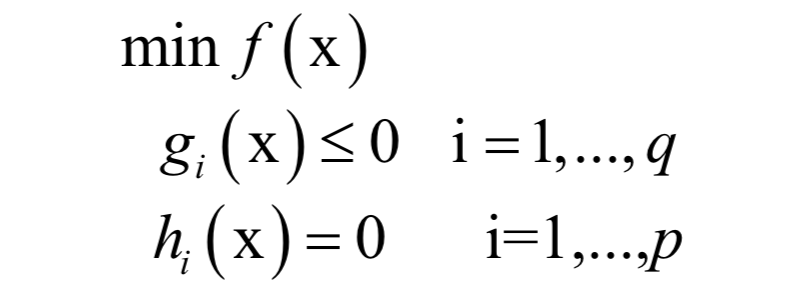
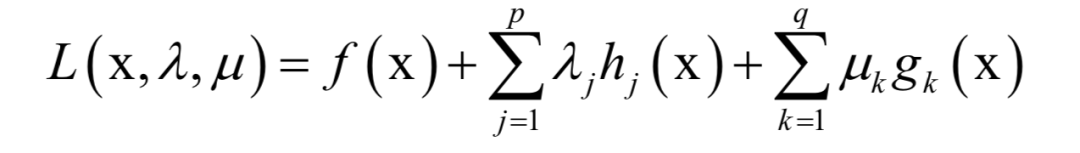
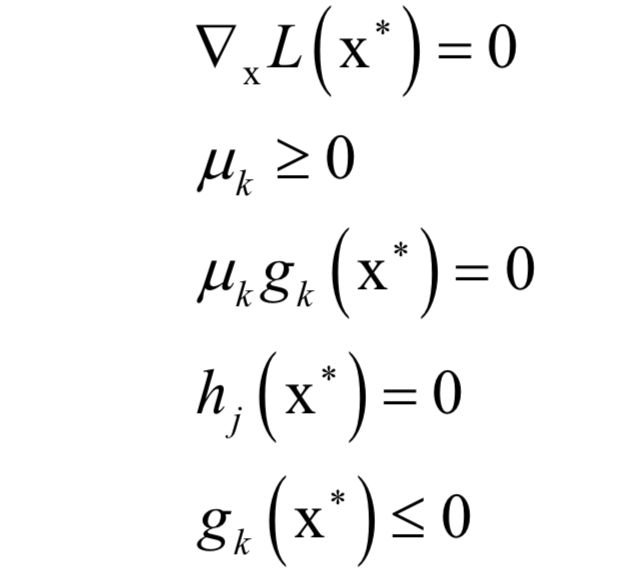
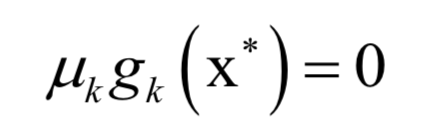
-
Support Vector Machine (SVM)
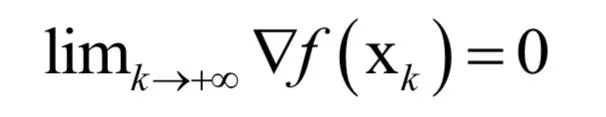
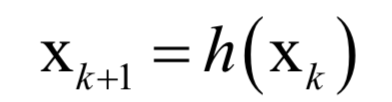
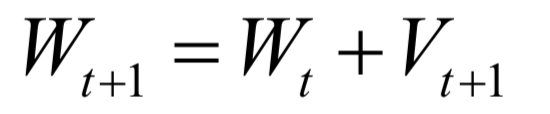
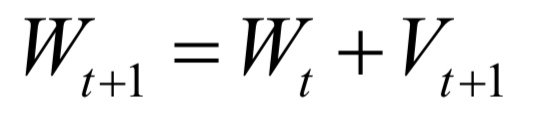
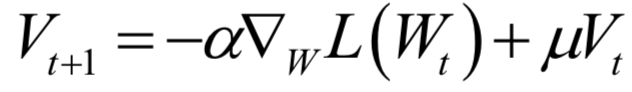
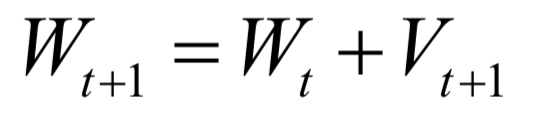
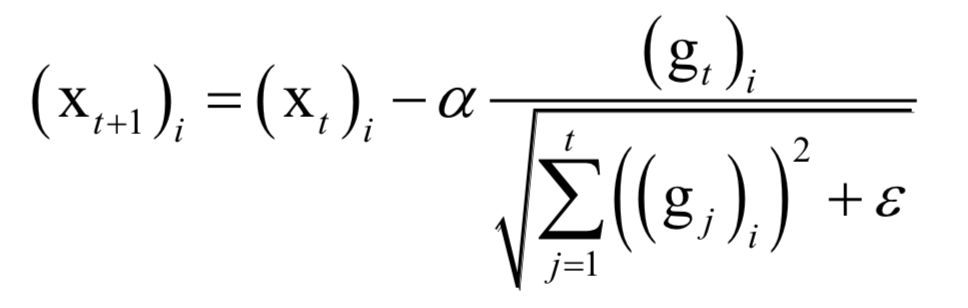
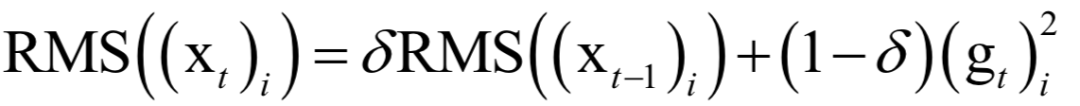
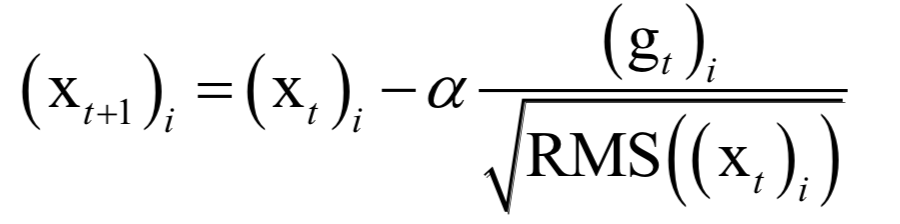
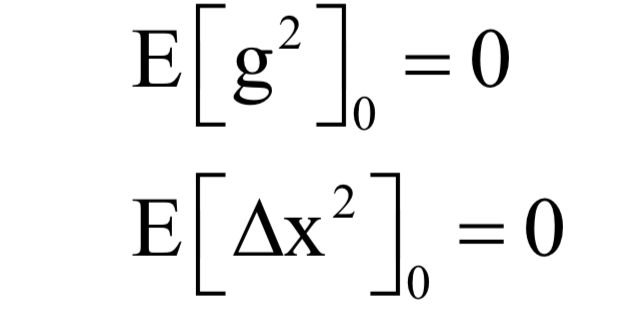
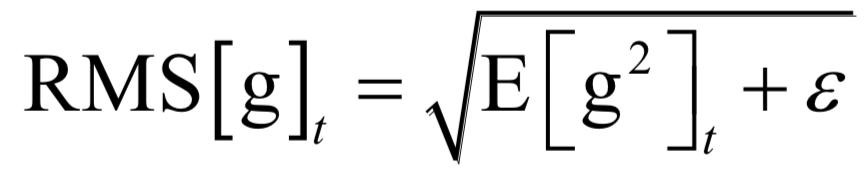
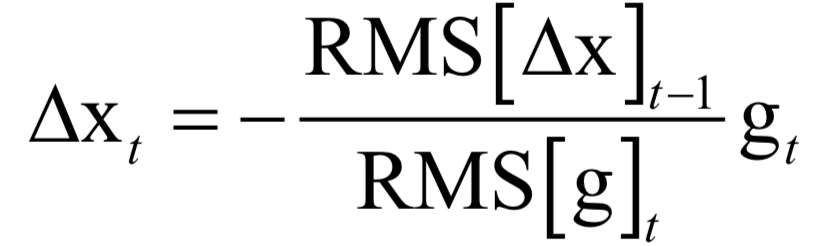
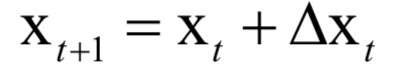
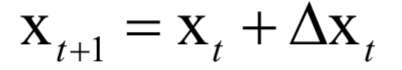
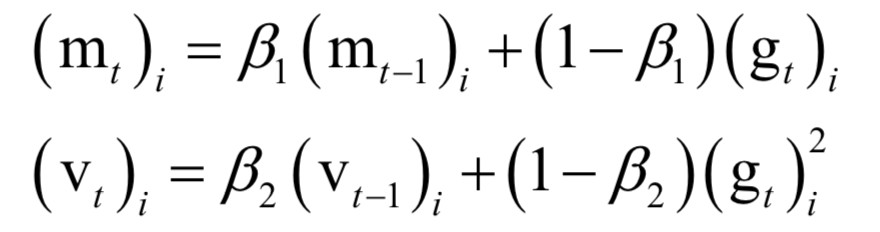
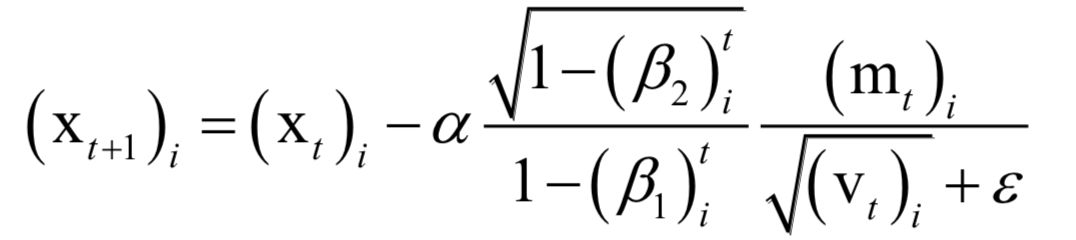
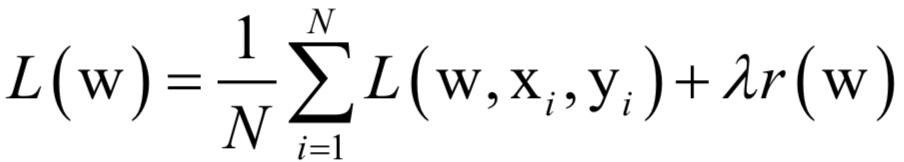
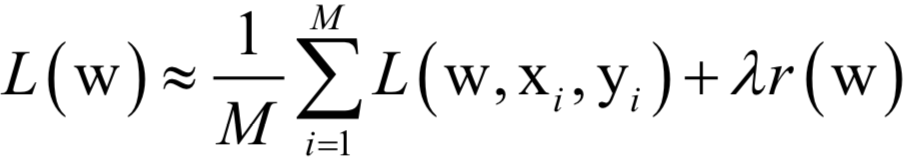
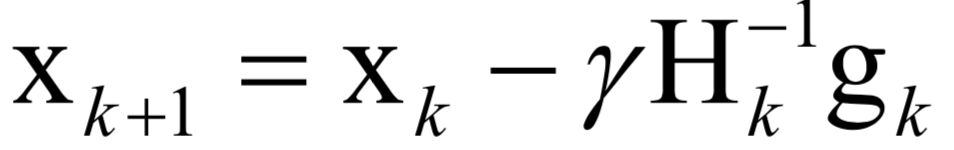
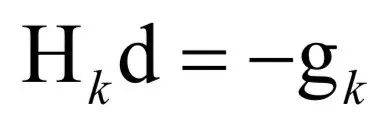
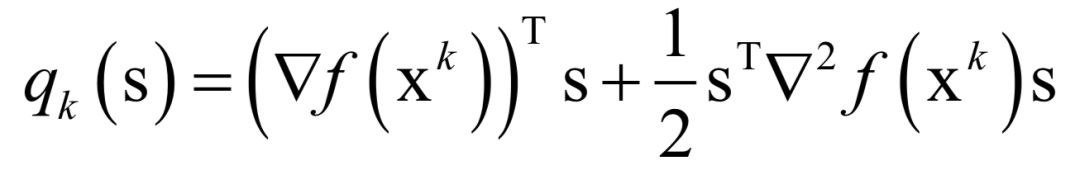
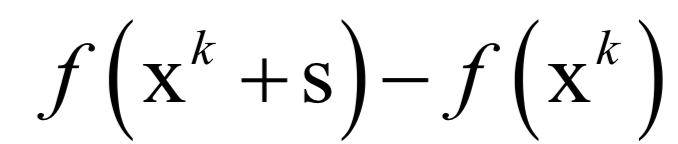
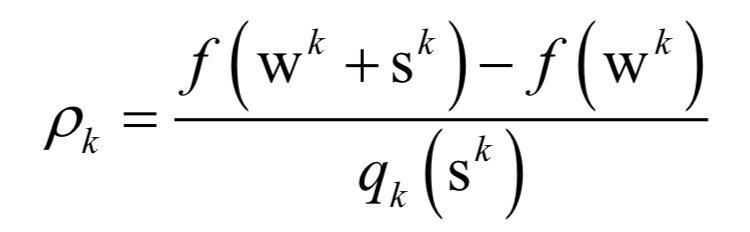
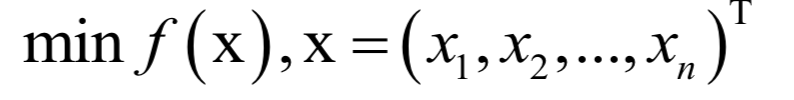
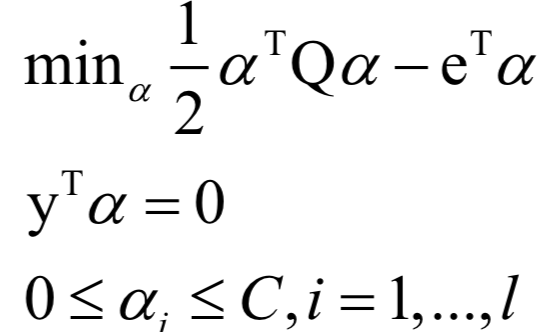
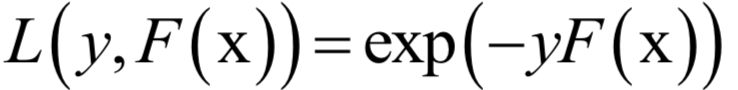
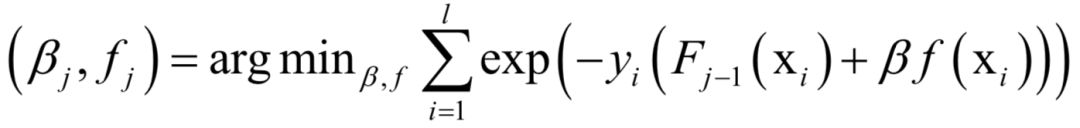
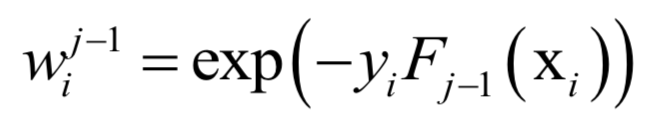
Editor / Fan Ruiqiang
Reviewed by / Wang Le
Checked by / Fan Ruiqiang
Click below
Follow us