

Source: Artificial Intelligence Lecture Hall
This article is about 2600 words long and is recommended for a 9-minute read.
This article will help you understand missing values, the reasons behind missing values, the patterns, and how to use KNNImputer to estimate missing values.
KNN, like random forests, gives the impression of being used for classification and regression. Since everyone has already seen that random forests can perform dimensionality reduction, there is no need to be surprised by today’s topic: KNN missing value imputation.
Overview
-
Learn to use KNNImputer to estimate missing values in data; -
Understand missing values and their types.
Introduction
The KNNImputer from scikit-learn is a widely used method for estimating missing values. It is widely regarded as an alternative to traditional imputation techniques.
In today’s world, data is collected from multiple sources for analysis, generating insights, verifying theories, and so on. This data, collected from different resources, often may lack some information. This could be due to problems in the data collection or extraction process, or it may be human error.
Handling these missing values becomes an important step in data preprocessing. The choice of imputation method is critical as it can significantly impact one’s work.
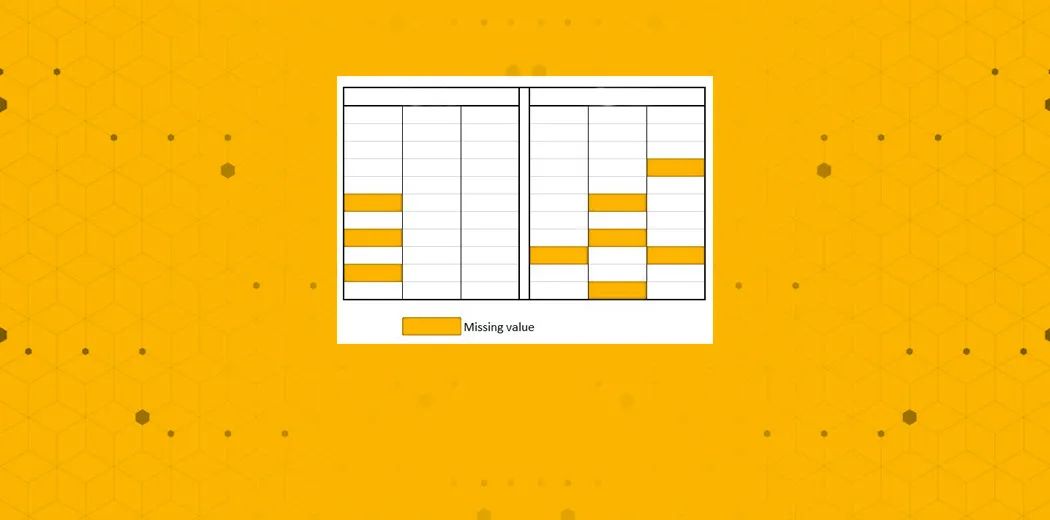
Most statistical and machine learning algorithms are based on complete observations of the dataset. Therefore, handling missing information becomes crucial. Few statistical literatures address the sources of missing values and ways to overcome this issue. The best approach is to estimate these missing observations with estimates.
In this article, we introduce guidelines for estimating missing values in a dataset using observations from neighboring data points. For this, we use the very popular KNNImputer based on the k-Nearest Neighbors algorithm in scikit-learn.
Table of Contents
-
Degrees of Freedom Issues; -
Patterns of Missing Values; -
A Shared Sense of Identity (Essence of kNN Algorithm); -
Distance Calculation in the Presence of Missing Values; -
Imputation Method Using KNNImputer.
Degrees of Freedom Issues
Missing values in a dataset are a big hornet’s nest for any data scientist. Variables with missing values can be a very important issue because there is no simple way to handle them.
Typically, if the proportion of missing observations in the data is small relative to the total number of observations, we can simply delete those observations. However, this is not the most common scenario. Deleting rows with missing values may lead to discarding useful information or patterns.
In statistical terms, this leads to a reduction in degrees of freedom as the number of independent pieces of information decreases.
Patterns of Missing Values
Missing values may occur for various reasons when collecting observations about variables, such as –
-
Mechanical/Equipment Errors; -
Errors by Some Researchers; -
Unavailable Respondents; -
Accidental Deletion of Observations; -
Partial Forgetfulness of Respondents; -
Accounting Errors, etc.
The types of missing values can generally be classified as:
-
Missing Completely at Random (MCAR);
This occurs when the missing values have no implicit dependency on any other variables or any observational characteristics. If a doctor forgets to record the ages of every 10 patients entering the ICU, the presence of missing values will not depend on the characteristics of the patients.
-
Missing at Random (MAR);
In this case, the probability of missing values depends on the characteristics of the observable data. In survey data, high-income respondents are less likely to inform researchers about the number of properties they own. The missing values for the variable number of properties owned will depend on the income variable.
-
Missing Not at Random (MNAR);
This occurs when the missing values depend on both the characteristics of the data and the missing values themselves. In this case, it is challenging to determine the mechanism of missing values. For example, missing values for variables like blood pressure may partially depend on blood pressure readings, as patients with low blood pressure are less likely to check their blood pressure regularly.
A Shared Sense of Identity (Essence of kNN Algorithm)
Univariate methods for missing value imputation are simple methods of estimation but may not always provide accurate estimates. For example, suppose we have variables related to the density of cars on the road and the level of pollutants in the air, and the observations of pollutant levels are sparse. Estimating pollutant levels using the mean/median of pollutant levels may not necessarily be an appropriate strategy.
In such cases, algorithms like k-Nearest Neighbors (kNN) can assist in estimating the values of missing data. Sociologists and community researchers believe that humans live in communities because neighbors generate a sense of security, attachment to the community, and relationships that exhibit community identity through participation in various activities.
A similar imputation method applicable to data is k-Nearest Neighbors (kNN), which identifies neighboring points through distance measures and can estimate missing values using the complete values of neighboring observations.
Example:
Suppose your essential food stock at home is running low, and due to a lockdown, nearby stores are closed. Hence, you ask your neighbors for help, and you will take anything they offer you. This is an example of imputation from 1-nearest neighbor (with the help of the nearest neighbor).
Conversely, if you identify 3 neighbors to seek help from and choose a combination of items provided by those 3 nearest neighbors, this is an example of imputation from 3 nearest neighbors. Similarly, missing values in a dataset can be estimated using the observations of k nearest neighbors in the dataset. The neighboring points in the dataset are determined by some distance measure, typically Euclidean distance.
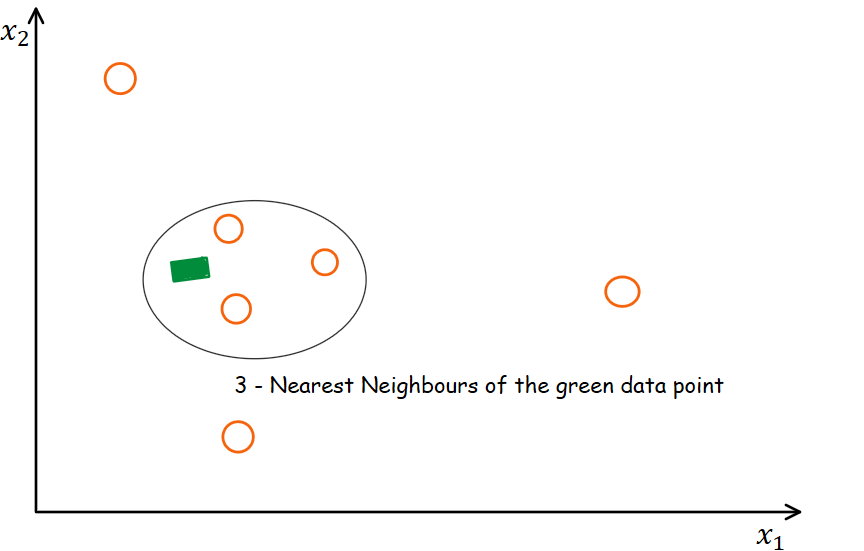
Consider the diagram above representing how kNN works. In this case, the elliptical area represents the neighboring points of the green square data point. We use distance measures to identify neighbors.
The idea behind the kNN method is to identify the “k” samples that are similar or close in space within the dataset. We then use these “k” samples to estimate the value of the missing data point. The missing value of each sample is estimated using the mean of the “k” neighbors found in the dataset.
Distance Calculation in the Presence of Missing Values
Let us look at an example to understand this. Consider a pair of observations in two-dimensional space (2,0), (2,2), (3,3). The graphical representation of these points is as follows:
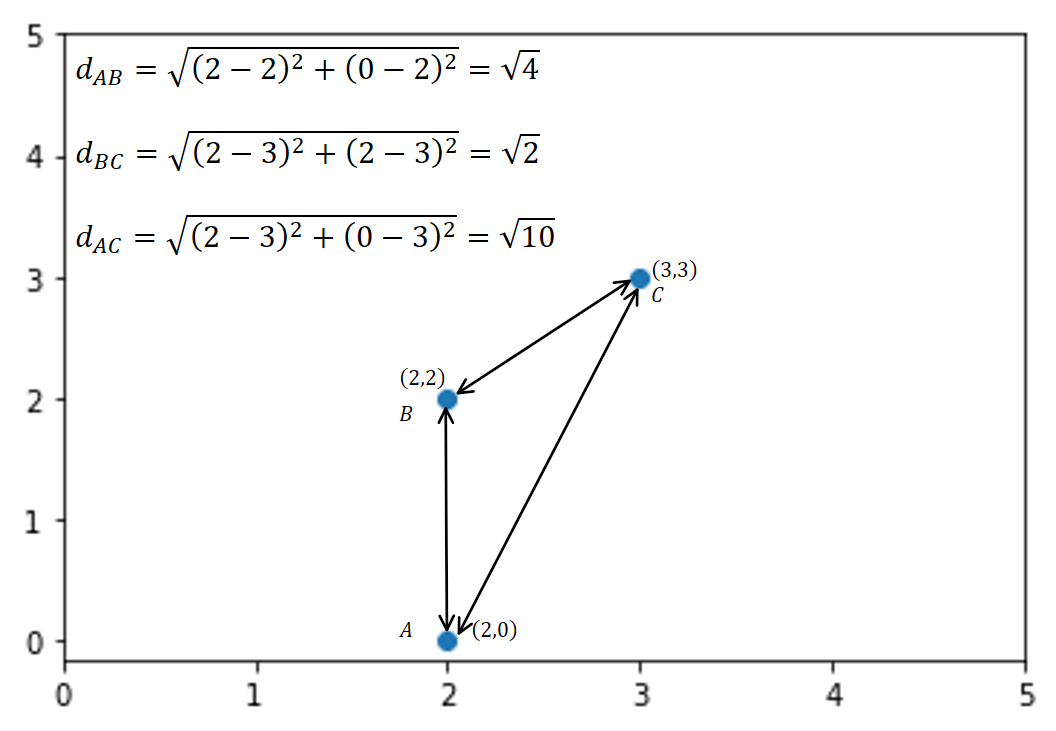
The point with the shortest distance based on Euclidean distance is considered the nearest neighbor. For point A, the 1-nearest neighbor is point B. For point B, the 1-nearest neighbor is point C.
In the presence of missing coordinates, the Euclidean distance is calculated by ignoring the missing values and proportionally increasing the weight of the non-missing coordinates.
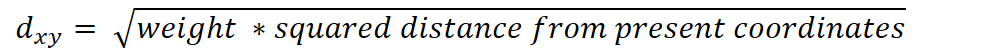
Where:
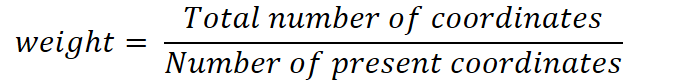
For example, the Euclidean distance between the two points (3, NA , 5) and (1, 0, 0) is:

Now we use the sklearn package’s pairwise metric module’s sklearn nan_euclidean_distances function to calculate the distance between two points with missing values.

Although nan_euclidean_distances applies to two one-dimensional arrays provided by X and Y parameters, it can also apply to a single array with multiple dimensions.
Therefore, the distance matrix is a 2 X 2 matrix representing the Euclidean distance between pairs of observations. Additionally, the diagonal elements of the resulting matrix are 0, as they represent the distance between each observation and itself.
Imputation Method Using KNNImputer
We will use the KNNImputer function from the impute module of sklearn. KNNImputer helps estimate the missing values present in observations by finding the nearest neighbors using the Euclidean distance matrix.

In this case, the above code shows that observation 1 (3, NA, 5) and observation 3 (3, 3, 3) are the closest in terms of distance (~2.45). Therefore, estimating the missing value in observation 1 (3, NA, 5) using the 1-nearest neighbor will yield an estimate of 3, which is the same as the estimate for the second dimension of observation 3 (3, 3, 3).
Additionally, estimating the missing value in observation 1 (3, NA, 5) with the 2 nearest neighbors will yield an estimate of 1.5, which is the average of the second dimensions of observations 2 and 3, namely (1, 0, 0) and (3, 3, 3).

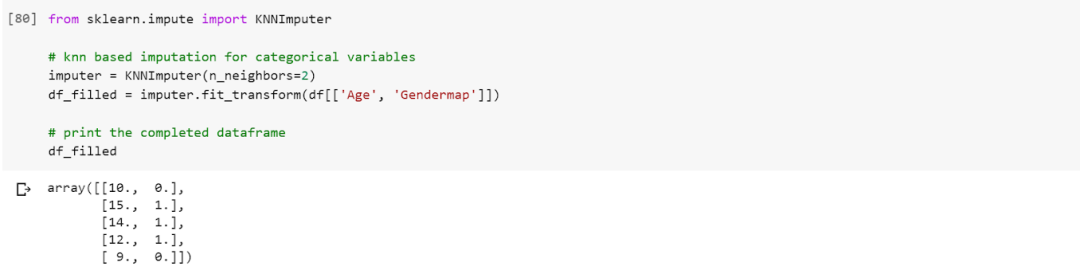
So far, we have discussed using kNNImputer to handle missing values in continuous variables. Next, we create a dataframe that contains missing values in categorical variables. To estimate missing values in categorical variables, we must encode the categorical values as numerical since KNNImputer only works with numerical variables. We can perform this using a mapping from categories to numeric variables.

Conclusion
In this article, we learned about missing values, the reasons behind missing values, the patterns, and how to use KNNImputer to estimate missing values. In conclusion, choosing k to use the kNN algorithm for estimating missing values may be a point of contention. Moreover, research indicates that after performing imputation with different k values, cross-validation must be used to test the model. Although missing value imputation is an evolving research area, kNN is a simple and effective strategy.
