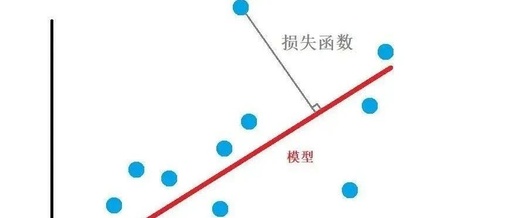

1.Loss Function essence
Machine Learning’s “Three Steps”:Select a family of models,define the loss function to quantify prediction errors,and find the optimal model parameters that minimize the loss through optimization algorithms.

Machine Learning vs Human Learning
-
Define a set of functions (model selection)
-
Goal: Determine a suitable hypothesis space or family of models.
-
Examples: Linear regression, logistic regression, neural networks, decision trees, etc.
-
Considerations: Complexity of the problem, nature of the data, computational resources, etc.
-
Evaluate the quality of functions (loss function)
-
Goal: Quantify the difference between model predictions and actual results.
-
Examples: Mean Squared Error (MSE) for regression; Cross-entropy loss for classification.
-
Considerations: Nature of the loss (convexity, differentiability, etc.), ease of optimization, robustness to outliers, etc.
-
Select the best function (optimization algorithm)
-
Goal: Find the model parameters that minimize the loss function within the function set.
-
Main methods: Gradient descent and its variants (stochastic gradient descent, batch gradient descent, Adam, etc.).
-
Considerations: Convergence speed, computational efficiency, complexity of parameter tuning, etc.
Essence of the Loss Function:Quantify the difference between model predictions and actual results.

Essence of the Loss Function
-
1. Concept of Loss Function:
-
The loss function is used to quantify the difference between model predictions and actual values.
-
It is a method for calculating the gap between predicted and actual values, encapsulated through deep learning frameworks (like PyTorch, TensorFlow).
-
2. Importance of the Loss Function:
-
In machine learning, the goal is to make predictions as close as possible to actual values, thus requiring minimization of the difference between predicted and actual values.
-
The choice of loss function is crucial for the speed and effectiveness of model training because different loss functions lead to varying gradient descent speeds.
-
3. Position of the Loss Function:
-
The loss function is located between the forward and backward propagation of the machine learning model.
-
During the forward propagation phase, the model generates predictions based on input features.
-
The loss function receives these predictions and calculates the difference from the actual values.
-
This difference is then used in the backward propagation phase to update the model’s parameters and reduce future prediction errors.

2. Principle of the Loss Function principles
Error reflects the prediction bias of a single data point, while loss represents the total prediction bias of the entire dataset. The loss function utilizes these two principles to aggregate errors to optimize the model and reduce overall prediction bias.
Error: The difference between the predicted result and the actual value for a single data point, used to evaluate the model’s prediction accuracy for a specific data point.
-
Definition: Error refers to the difference or deviation between the model’s prediction and the actual value for a single data point. This difference reflects the model’s prediction inaccuracy or bias.
-
Calculation: Error can be calculated using various mathematical formulas. Among them, absolute error is the absolute value of the difference between predicted and actual values, used to quantify the actual size of deviation from the real value; squared error is the square of the difference between predicted and actual values, commonly used in squared loss functions to emphasize larger errors.
-
Error bars: Error bars typically appear above, below, or on the sides of data points, with their length or size representing the magnitude of the error. This visualization method helps identify potential problem areas and guides further model improvement or data analysis.

Error Bars
Loss:Loss is a general indicator of the inaccuracy of a machine learning model’s predictions across the entire dataset. By minimizing the loss, model parameters can be optimized, improving prediction performance.
-
Definition: Loss is an indicator of the overall inaccuracy of a machine learning model’s predictions across the entire dataset. It reflects the differences between model predictions and actual values, aggregating these differences to provide a scalar value representing the overall inaccuracy of predictions.
-
Calculation: The specific calculation of loss is done through the loss function. The loss function takes the model’s predicted values and actual values as input and outputs a scalar value, which is the loss value, indicating the overall prediction error of the model across the dataset.
-
Loss Curve: The loss curve visually presents the trend of the model’s loss value changes during training. By plotting the training loss and validation loss over iterations, we can gain insights into whether the model encounters overfitting or underfitting issues, allowing adjustments to the model structure and training strategy.

Loss Curve
3. Algorithms of the Loss Function of the Loss Function

Algorithms of the Loss Function
Mean Squared Error Loss Function (MSE):By calculating the average of the squared differences between model predictions and actual values, it measures the accuracy of predictions in regression tasks, aiming to make predictions as close as possible to actual values.

Mean Squared Error Loss Function (MSE)
-
Application Scenarios: Mainly used for regression problems, i.e., tasks predicting continuous values.
-
Formula:

Mean Squared Error Loss Function (MSE) Formula
-
Characteristics:
-
When predicted values are close to actual values, the loss value is small.
-
When the predicted values deviate significantly from the actual values, the loss value increases rapidly.
-
Due to its simple gradient form, it is easy to optimize.
-
Optimization Goal: Minimize the Mean Squared Error Loss to make the model’s predictions as close as possible to actual values.
Cross-Entropy Loss Function (CE):Used to measure the difference between the predicted probability distribution of the model and the true labels in classification tasks, aiming to make model predictions closer to the true categories by minimizing the loss.

Cross-Entropy Loss Function (CE)
-
Application Scenarios: Mainly used for classification problems, especially multi-class problems.
-
Formula:

Cross-Entropy Loss Function (CE) Formula
-
Characteristics:
-
When the predicted probability distribution is close to the true probability distribution, the loss value is small.
-
It is very sensitive to small changes in predicted probabilities, especially when the true label probabilities are close to 0 or 1.
-
Suitable for models with probability outputs, such as logistic regression, softmax classifiers, etc.
-
Optimization Goal: Minimize the Cross-Entropy Loss to make the model’s predicted probabilities for each category as close as possible to the true probability distribution.