

Original Article from New Intelligence
Original Article from New Intelligence
Editors: Zhang Jia, Jin Lei
[New Intelligence Overview] The Google NLP model BERT, which once broke 11 records, has recently faced skepticism from netizens: the model’s success in some benchmark tests is merely due to exploiting false statistical cues in the dataset, and without them, it might perform worse than random results. This research has sparked widespread discussion on Reddit.
The NLP myth is being questioned.
Since Google released BERT last year, this model, which has shattered 11 records and surpassed human performance, has continued to attract attention.
However, a Reddit user recently raised doubts:BERT’s success in some benchmark tests is merely due to exploiting false statistical cues in the dataset. Without them, it might perform worse than random results.
Reddit link:
https://www.reddit.com/r/MachineLearning/comments/cfxpxy/berts_success_in_some_benchmarks_tests_may_be/
This paper was completed by researchers from National Cheng Kung University in Taiwan.

Paper link:
https://arxiv.org/pdf/1907.07355.pdf
The researchers stated:
We were surprised to find that BERT achieved peak performance of 77% on parameter inference understanding tasks, only 3 points lower than the average untrained human baseline. However, we demonstrate that this result can be entirely explained by exploiting false statistical cues in the dataset.
We analyzed the nature of these cues and demonstrated that a series of models were utilizing them. This analysis reports the construction of an adversarial dataset, where all models achieved random accuracy.
A Reddit user lysecret commented on this research:

He believes this is a very simple yet effective way to show that such models cannot truly “understand” but rather smartly exploit (bad) statistical cues. However, for most people (except Elon Musk), it might be assumed that models like BERT do just that.
Argument mining is the task of identifying the argumentative structure in natural language texts. For example, which text segments represent claims and include reasons that support or attack those claims.
This is a challenging task for machine learners, as even humans find it difficult to determine when two text segments are in an argumentative relationship, as evidenced by research on argument annotation. One approach to solving this problem is to focus on warrants—forms of world knowledge that allow for reasoning.
Consider a simple argument:“(1) It is raining; therefore (2) you should take an umbrella.” The warrant “(3) getting wet is bad” permits this inference. Knowing (3) helps establish the inferential link between (1) and (2).
However, it is difficult to find it anywhere, as warrants are often implicit. Thus, in this approach, machine learners must not only use warrants for reasoning but also discover them.
Argument Reasoning Comprehension Task (ARCT) postpones the discovery of warrants and focuses on reasoning. An argument containing claim C and reason R is provided. The task is to select the correct warrant W from distractors, called alternative warrants A.
The alternative warrants are written as R∧A→¬C. Another possible warrant from the previous example might be “(4) being wet is good,” in which case we have (1)∧(4)→“(¬2) you should not take an umbrella.” An example from the dataset is shown in Figure 1.

Figure 1: An example data point in the ARCT test set and how to read it. The inference from R and A to ¬C is derived by design.
ARCT SemEval shared task validates the challenge of this problem. Even when warrants are provided, learners still need to rely on further world knowledge.
For example, to correctly classify the data point in Figure 1, one must at least know how consumer choice and network redirection relate to the concept of monopoly, and that Google is a search engine. Except for one participating system, the accuracy of all systems participating in the shared task could not exceed 60% (binary classification).
Therefore, it is surprising that BERT achieved 77% accuracy on the test set at its best run (Table 1), only 3 points lower than the average (untrained) human baseline. Expecting it to perform so well without the world knowledge required for this task seems unreasonable. This raises the question:What has BERT learned about argument understanding?
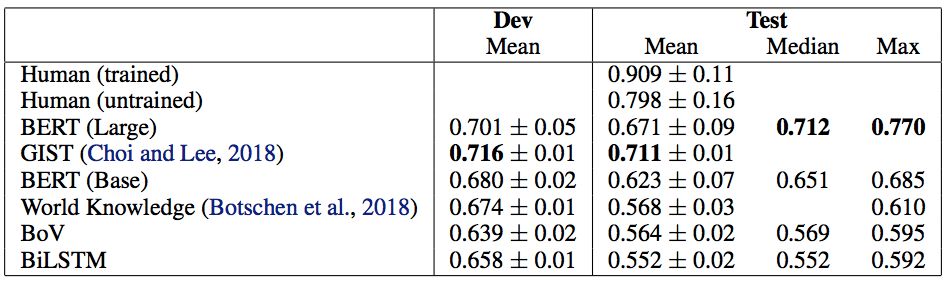
Table 1: Baselines and BERT results. Our results come from 20 different random seeds (± standard deviation given). The average of BERT Large is affected by 5/20 random seeds and cannot be trained, which is a problem raised by Devlin et al. Therefore, we believe the median is a better indicator of BERT’s average performance. The non-degraded average of BERT (large) is 0.716±0.04.
To investigate BERT’s decisions, the staff examined data points and found them easy to classify across multiple runs. A similar analysis was performed on SemEval submissions, and consistent with their results, it was found that BERT utilized the presence of cue words in warrants, particularly “not”. Through experiments designed to isolate these effects, the researchers demonstrated BERT’s remarkable ability to exploit false statistical cues in this work.
However, the results indicate that ARCT can eliminate the main problems. Due to R∧A→¬C, we can add a copy of each data point where the claim is negated and the label is reversed.
This means that the distribution of statistical cues in the warrants will reflect on both labels, thus eliminating the signal. On this adversarial dataset, all models performed randomly, and BERT achieved a maximum test set accuracy of 53%.
Therefore, the adversarial dataset provides a more reliable assessment of parameter understanding and should be used as a standard for future work on this dataset.
If a model is exploiting distributional cues on labels, then it should perform relatively well if trained only on warrants (W).
The same reasoning applies to removing only claims, keeping reasons and warrants (R, W) or removing reasons (C, W).
The latter setup allows the model to additionally consider cues in the reasons and claims, as well as cues related to the combination with warrants.
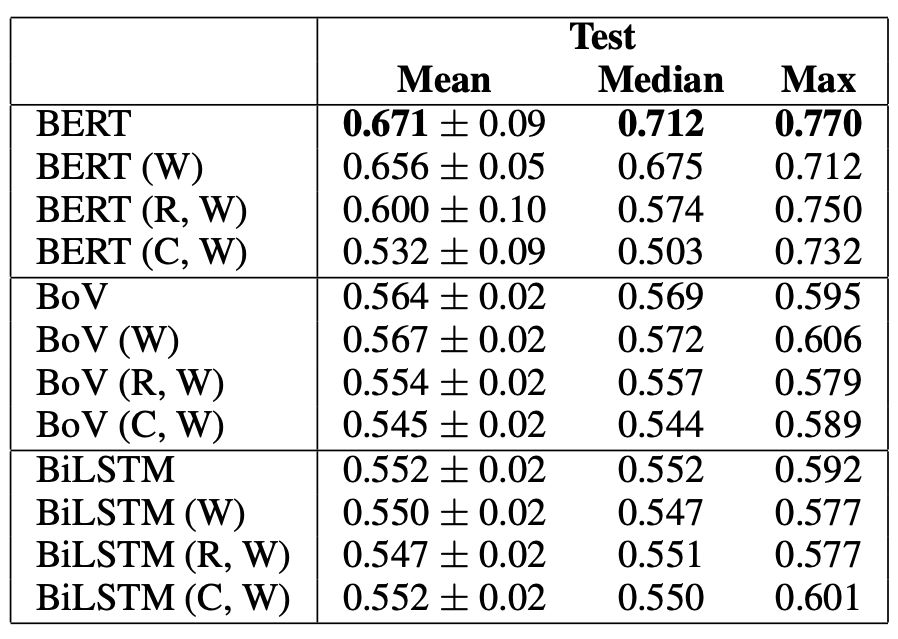
Table 3 Experimental results using BERT Large, BoV, and BiLSTM as baselines
Experimental results are shown in Table 3. BERT’s accuracy could reach a maximum of 71% when trained only on warrants (W). This is 6 points lower than its peak of 77%.
And (R, W) increased by 4 points compared to (W), while (C, W) increased by 2 points, which accounts for those 6 points mentioned earlier.
Based on this evidence, the researchers found that BERT’s entire performance can be explained by exploiting false statistical cues.
Adversarial Test Set
Due to the original design of the dataset, the main issue of eliminating statistical cues on labels in ARCT is addressed.
Given R∧A→¬C, adversarial examples can be generated by negating claims and reversing the labels of each data point (as shown in Figure 4).

Figure 4 Original and adversarial data points. Claims are negated, and warrants are swapped. The label assignments for W and A remain unchanged.
Adversarial examples are then combined with the original data. This eliminates the issue by mirroring the distribution of cues around the two labels.
Most claims in the validation and test sets have already been negated elsewhere in the dataset. The remaining claims were manually negated by a native English-speaking staff member.
The researchers attempted two experimental setups.
First, evaluate models trained and validated on the original data on the adversarial set. Due to overfitting on cues in the original training set, all results were worse than random.
Second, the model was trained from scratch on the adversarial training and validation sets, and then evaluated on the adversarial test set. The results are shown in Table 4.
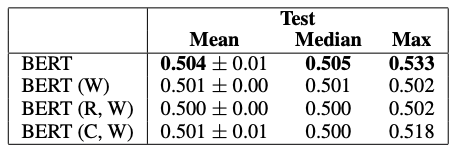
Table 4 Results of BERT Large on adversarial test sets with adversarial training and validation sets.
BERT’s peak performance dropped to 53%, with an average and median of 50%. These results conclude that the adversarial dataset has successfully eliminated expected cues, providing a more reliable assessment of machine parameter understanding.
This result aligns more closely with the researchers’ intuition about this task: good performance should be unachievable due to little or no knowledge of the realities behind these arguments.
Task Description and Baselines
Let t_i = 1, . . . , n index each point in dataset D, where |D| = n. In each case, two candidate warrants are randomly assigned binary labels j ∈ {0, 1}, such that each has the same correct probability. The input is the representation of c(i), reason r(i), warrant zero w0(i), and warrant one w1 (i). The label y(i) is the binary indicator corresponding to the correct authorization. The general architecture of all models is shown in Figure 2. Learning shared parameters θ to classify each warrant independently using parameters, obtaining logit:
zj(i)=θ[ c(i); r(i); wj (i) ]
Then they are concatenated and passed through softmax to determine the probability distribution p(i)= softmax([z0(i), z1(i)]). The prediction is y(i)= arg maxj p(i). The baselines include a bag of vectors (BoV), bidirectional LSTM (BiLSTM), SemEval winning model GIST, the best model of Botschen et al., and human performance (Table 1). For all our experiments, we used grid search to select hyperparameters, dropout regularization, and Adam for optimization. When validation accuracy dropped, we annealed the learning rate by 1/10. The final parameters came from the epoch with the maximum validation accuracy. The inputs for BoV and BiLSTM were 300-dimensional GloVe embeddings trained on 640B. The code to reproduce all experiments and detailed descriptions of all hyperparameters is available on GitHub (https://github.com/IKMLab/arct2).
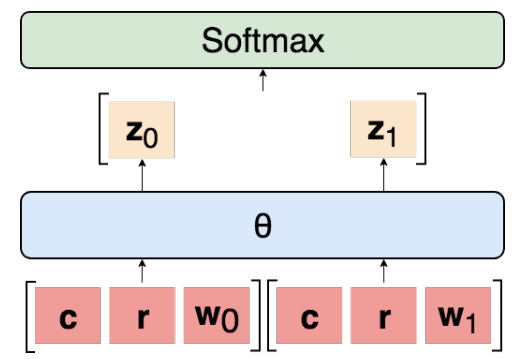
Figure 2: The general architecture of the model in our experiments. Logits are computed independently for each pair of argument-warrant, then concatenated and passed through softmax.
BERT
Our BERT classifier is shown in Figure 3. Claims and reasons are concatenated to form the first text segment, paired with each warrant and processed independently. The final layer CLS vector is passed to a linear layer to obtain logit zj(i). The entire architecture is meticulously tuned. The learning rate is set to 2e-5, allowing for a maximum of 20 training epochs, obtaining parameters from the epoch with the best validation set accuracy. We used the Hugging Face PyTorch implementation.
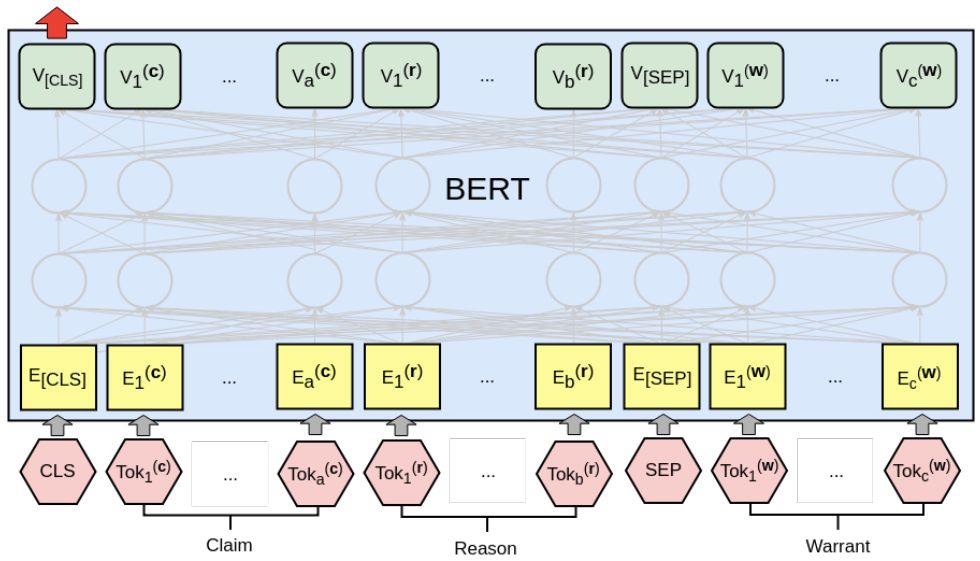
Figure 3: Processing arguments with BERT pairs argument-warrant. Reason (a-length words) and claim (b-length) together form the first sentence, while the warrant (length c) is the second sentence. The final CLS vector is then passed to a linear layer to compute logit zj(i).
Devlin et al. reported that BERT sometimes fails to train on small datasets, resulting in degraded results. ARCT is very small, with only 1210 training observations. In 5/20 runs, we encountered this phenomenon, seeing near-random accuracy on validation and test sets. These situations occurred when training accuracy was not significantly higher than random (<80%). Removing degraded curves, BERT’s average was 71.6±0.04. This exceeds previous technical standards – the median was 71.2%, which is a better average than the overall mean as it is not affected by degradation. However, our main finding is that these results are meaningless and should be discarded. In the following sections, we will focus on BERT’s peak performance of 77%.
Statistical Cues
The main source of false statistical cues in ARCT is the uneven distribution of labels. Next, we will show the existence and nature of these cues.
While more complex cues may exist, the researchers only considered unigrams and bigrams.
The researchers aimed to calculate the usefulness of model utilization of cues k, as well as its prevalence in the dataset (indicating the strength of the signal).
First, several concepts are defined:
-
Applicability of cues: αk, defined as the number of data points appearing on one label;
-
Productivity of cues:πk, defined as the proportion of applicable data points predicting the correct answer;
-
Coverage of cues:ξk, defined as the proportion of applicability among the total number of data points.
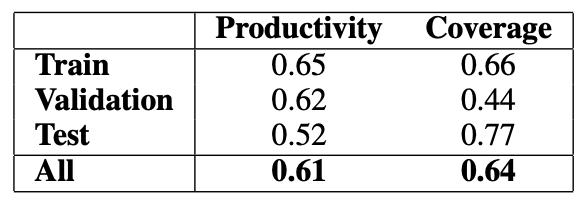
Table 2 shows the productivity and coverage of the strongest unigram cue (“not”) found by researchers to predict labels in ARCT. It provides a particularly strong training signal. While it is less efficient in the test set, it is just one of many such cues.
Researchers also found many other unigrams, although overall productivity was lower, most were high-frequency words like “is,” “do,” and “are.” Bigrams used with “not,” such as “will not” and “can,” were also found to be effective.
About the Authors
The authors of the paper are all from the Intelligent Knowledge Management Laboratory, Department of Computer Science and Information Engineering, National Cheng Kung University. The first author, Timothy Niven, is currently studying at the university.

Professor Hung-Yu Kao
The second author, Hung-Yu Kao, received his Bachelor’s and Master’s degrees in Computer Science from National Tsing Hua University in 1994 and 1996, respectively. In July 2003, he obtained his Ph.D. from the Department of Electrical Engineering at National Taiwan University. He is currently the director of the Institute of Medical Informatics (IMI) and the Department of Computer Science and Information Engineering (CSIE) at National Cheng Kung University. His research interests include web information retrieval/extraction, search engines, knowledge management, data mining, social network analysis, and bioinformatics. He has published over 60 research papers in international journals and conference proceedings.
