This article is also published on my personal website, where the formula images display better. Welcome to visit: https://lulaoshi.info/machine-learning/attention/bert
Since the emergence of BERT (Bidirectional Encoder Representations from Transformer) [1], a new paradigm has opened up in the field of NLP. This article mainly introduces the principles of BERT and how to use the transformers library provided by HuggingFace to complete fine-tuning tasks based on BERT.
Pre-training
BERT is pre-trained on a large corpus. Pre-training mainly involves training a large model under conditions of sufficient data and computing power, which can then be fine-tuned (Fine-tune) for other tasks using the pre-trained model.
Training Objectives
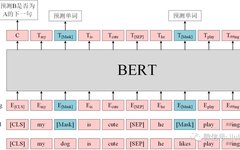
BERT uses data from corpora such as Wikipedia, totaling dozens of GB, which is a massive corpus. For a GB-level corpus, the cost of hiring people for annotation is extremely high. BERT employs two clever methods to train the model unsupervised: Masked Language Modeling and Next Sentence Prediction. These two methods allow for the acquisition of training data at a low cost without spending time and human resources on data annotation. Figure 1 shows an input-output example.
For Masked Language Modeling, given some input sentences (the bottom input layer in Figure 1), BERT will mask some words in the input sentences (the Masked layer in Figure 1). After passing through the intermediate word vectors and BERT layers, BERT’s goal is to enable the model to predict the masked words. Remember the “cloze test” we often encounter in English exams? Being able to answer the cloze test correctly indicates an understanding of the language logic behind the text. Essentially, BERT’s Masked Language Modeling is doing a “cloze test”: during pre-training, part of the words is randomly masked, and if the model can predict the masked words well, it has learned the intrinsic logic of the text.
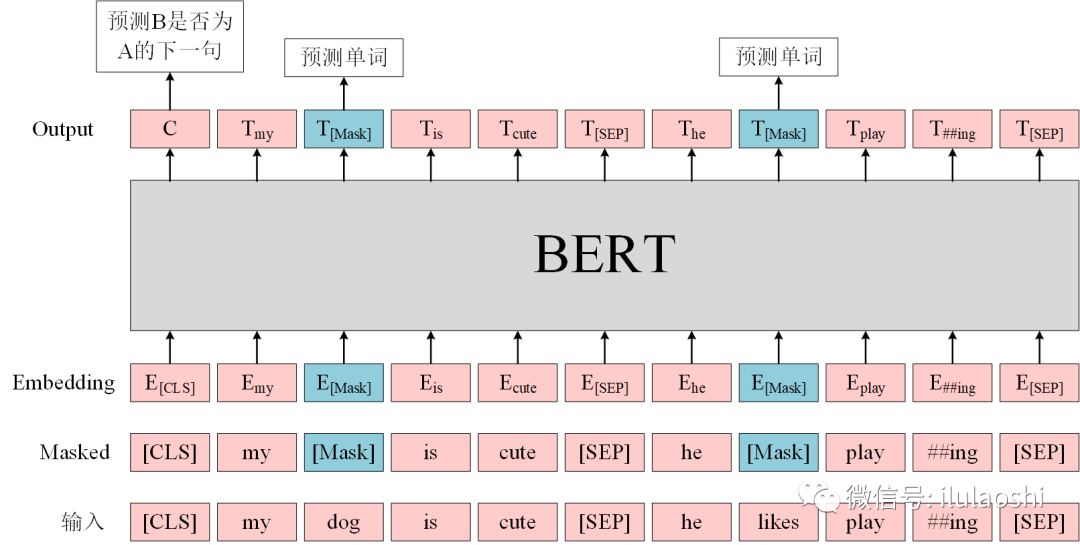
In addition to the “cloze test”, BERT also needs to perform the Next Sentence Prediction task: predicting whether sentence B is the next sentence of sentence A. Next Sentence Prediction is somewhat like the “paragraph ordering” questions in English exams, but simplified to consider only two sentences. If the model cannot correctly predict the Next Sentence based on the current sentence, but awkwardly combines two unrelated sentences, it indicates that the model has not understood the meaning behind the text.
Word Vectors
In deep learning-based NLP methods, words in the text are usually represented by one-dimensional vectors. If the cosine distance between two word vectors is small, it indicates that the two words are semantically similar.
Word vectors are generally derived from tokens. In English, words in a sentence are separated by spaces, periods, and other punctuation marks, making it easy to obtain words from the sentence. English words often have prefixes, suffixes, and roots, and after obtaining the English words, the roots need to be extracted. For example, as shown in Figure 1, “playing” is split into “play” and “##ing”. If English words are not processed for root extraction, the vocabulary becomes too large, making it difficult to fit. In English, “play” and “##ing” correspond to two tokens.
Chinese words are usually composed of multiple characters, and traditional Chinese text tasks typically use some segmentation tools to obtain strictly defined words. In the original BERT, for Chinese, no segmentation tools were used; instead, word vectors were obtained directly at the character level. Therefore, the original Chinese BERT (bert-base-chinese) inputs character vectors into the BERT model, where tokens are characters. Subsequent research has explored whether Chinese should undergo necessary segmentation to obtain vectors in word form for input into the BERT model.
For ease of explanation, this article does not explicitly distinguish between character vectors and word vectors; both are referred to as word vectors.
We first need to convert each token in the text into a one-dimensional word vector. Assuming the dimension of the word vector is hidden_size and the length of the sentence’s tokens is seq_len, or in other words, the sentence contains seq_len tokens, then the input is seq_len * hidden_size. Adding batch_size, the input becomes batch_size * seq_len * hidden_size. The above figure only shows one sample and does not reflect batch_size, or it can be understood as batch_size = 1, meaning only one text is processed at a time. For clarity, this article’s illustrations do not consider the batch_size dimension, but in actual model training, batch_size is usually greater than 1.
After a series of complex transformations by the BERT model, the output is still in the form of word vectors, used for semantic representation of the text. The input word vectors are seq_len * hidden_size, and the sentence contains seq_len tokens, converting each token into a word vector and feeding it into the BERT model. After processing by the BERT model, the output remains at the seq_len * hidden_size dimension. The output is still of length seq_len, where the word vector at the i position (0 < i < seq_len) represents the semantic representation of the i token after fitting. Subsequent tasks, such as named entity recognition, can use the word vectors at each position in the output.
In addition to using the masked method to intentionally cover some words, BERT also adds special symbols: [CLS] and [SEP]. The [CLS] is used at the beginning of the sentence and is the token at position i = 0 in the sentence sequence. BERT believes that the word vector corresponding to the token at position i = 0 in the output sequence contains information about the entire sentence and can be used for classifying the entire sentence. The [SEP] is used to separate two sentences.
Fine-Tuning
After pre-training, the obtained model can be fine-tuned for various tasks.
-
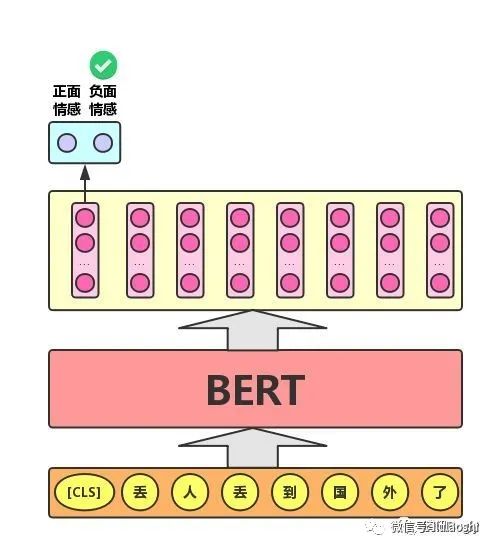
Single Text Classification Task. As mentioned earlier, the BERT model inserts a [CLS]symbol at the beginning of the text and uses the output vector corresponding to this symbol as the semantic representation of the entire text for text classification, as shown in Figure 2. For the[CLS]symbol, it can be understood that compared to other characters/words in the text, this symbol with no obvious semantic information will more “fairly” integrate the semantic information of each character/word in the text.
-
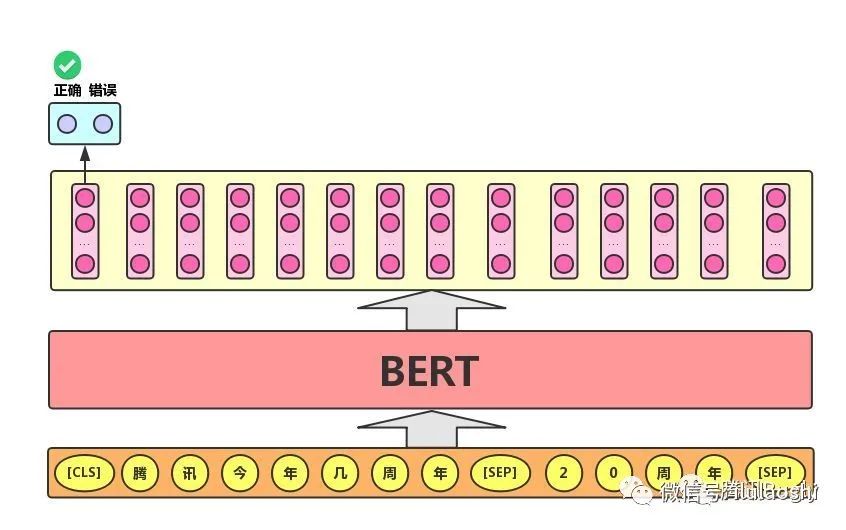
Sentence Pair Classification Task. The practical application scenarios for sentence pair classification include: question answering (determining whether a question matches an answer), sentence matching (whether two sentences express the same meaning), etc. For this task, the BERT model, in addition to adding the [CLS]symbol and using the corresponding output as the semantic representation of the text, separates the two sentences using the[SEP]symbol.
-
Sequence Labeling Task. The practical application scenarios for sequence labeling tasks include: named entity recognition, Chinese word segmentation, new word discovery (labeling whether each character is the first character, middle character, or last character of a word), answer extraction (start and end positions of the answer), etc. For this task, the BERT model uses the output vector corresponding to each token in the text to label (classify) that token, as shown in the following figure (B (Begin), I (Inside), E (End) represent the first character, middle character, and last character of a word, respectively).
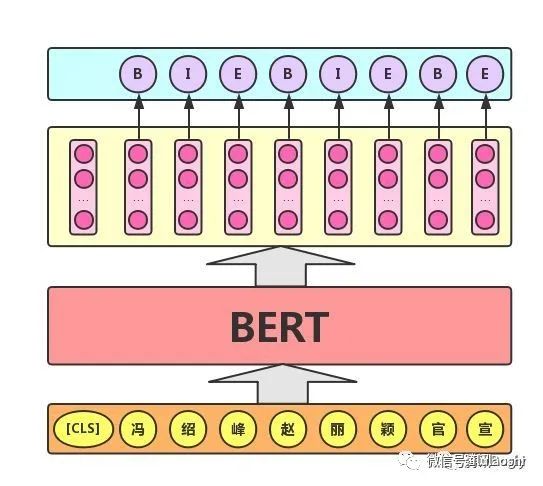
Model Structure
The Transformer is the core module of BERT, and the Attention mechanism is the most critical part of the Transformer. In the previous article, we introduced the Attention mechanism and Transformer, so we won’t elaborate on it here. BERT mainly uses the Transformer Encoder and does not use the Transformer Decoder.
By assembling multiple Transformer Encoders, BERT is constructed. In the paper, the authors assembled two sets of BERT models using 12 and 24 Transformer Encoders, with a total number of parameters of 110M and 340M, respectively.
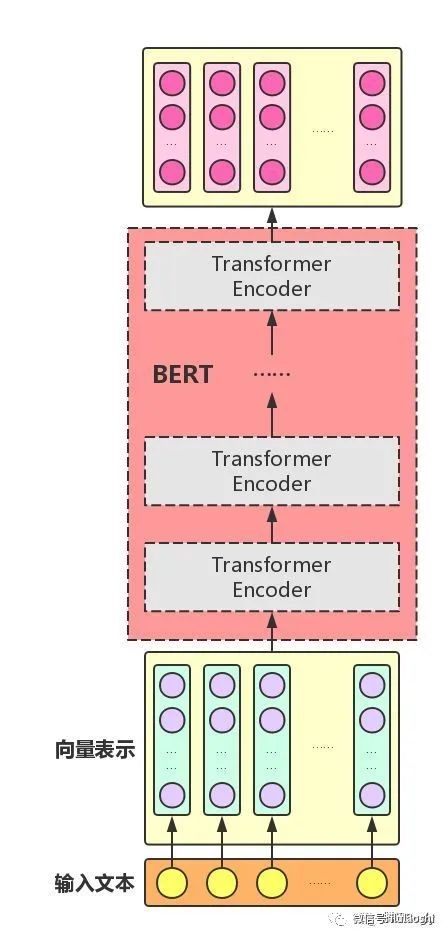
HuggingFace Transformers
Using BERT and other Transformer models cannot avoid the HuggingFace (https://huggingface.co/) Transformers ecosystem. HuggingFace provides APIs for various BERT models (transformers library), pre-trained models (HuggingFace Hub), and datasets (datasets). Initially, HuggingFace implemented BERT using PyTorch and provided pre-trained models. Over time, more and more people directly use the models provided by HuggingFace for fine-tuning and share their models with the HuggingFace community. The HuggingFace community has grown increasingly large, covering not only the PyTorch version but also providing the TensorFlow version. Mainstream pre-trained models are submitted to the HuggingFace community for others to use.
Fine-tuning using the transformers library mainly includes:
-
Tokenizer: Using the provided Tokenizer to process the raw text and obtain token sequences; -
Building the Model: Adding prediction interfaces required for downstream tasks on the provided model structure to construct the required model; -
Fine-tuning: Feeding the token sequences into the constructed model for training.
Tokenizer
The following two lines of code will create a BertTokenizer and load the required vocabulary.
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-cased')Using the obtained tokenizer for tokenization:
>>> encoded_input = tokenizer("I am a sentence")
>>> print(encoded_input)
{'input_ids': [101, 2769, 3221, 671, 1368, 6413, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1]}This results in a Python dict. Among them, input_ids is the easiest to understand, representing the index numbers of each token in the vocabulary. The vocabulary is a mapping from tokens to index numbers. You can use the decode() method to convert index numbers back into tokens.
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] I am a sentence [SEP]'As you can see, BertTokenizer automatically adds the [CLS] and [SEP] symbols to the original text, corresponding to the index numbers 101 and 102 in the vocabulary. After decode(), these two symbols are also parsed back out.
token_type_ids is mainly used for sentence pairs. For example, in the following case, two sentences are separated by [SEP]. A 0 indicates that the token corresponds to the first sentence, while a 1 indicates that it corresponds to the second sentence. Not all models and scenarios utilize token_type_ids.
>>> encoded_input = tokenizer("What is your surname?", "My surname is Li")
>>> print(encoded_input)
{'input_ids': [101, 2644, 6586, 1998, 136, 102, 1048, 6586, 1998, 3330, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}Sentences are usually variable in length. When multiple sentences form a batch, attention_mask plays a crucial role.
>>> batch_sentences = ["I am a sentence", "I am another sentence", "I am the last sentence"]
>>> batch = tokenizer(batch_sentences, padding=True, return_tensors="pt")
>>> print(batch)
{'input_ids':
tensor([[ 101, 2769, 3221, 671, 1368, 6413, 102, 0, 0],
[ 101, 2769, 3221, 1369, 671, 1368, 6413, 102, 0],
[ 101, 2769, 3221, 3297, 1400, 671, 1368, 6413, 102]]),
'token_type_ids':
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask':
tensor([[1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1]])}For a batch_size = 3 scenario like this, where different sentences have different lengths, padding=True indicates that shorter sentences will be padded with [PAD] symbols at the end, and return_tensors="pt" indicates that the returned tensors are in PyTorch format. The attention_mask informs the model which tokens need to be focused on during training and which tokens are meaningless symbols that have been padded and do not need the model’s attention.
Model
The following two lines of code will create a BertModel and load the required model parameters.
>>> from transformers import BertModel
>>> model = BertModel.from_pretrained("bert-base-chinese")BertModel is a torch.nn.Module used in PyTorch to wrap the network structure. BertModel contains a forward() method that implements the transformation of tokens into word vectors and the complex transformations of word vectors through multiple layers of Transformer Encoders.
The parameters of the forward() method include input_ids, attention_mask, token_type_ids, etc., which are basically the outputs from the previous Tokenizer section.
>>> bert_output = model(input_ids=batch['input_ids'])The forward method returns the model’s predicted results, which is a tuple(torch.FloatTensor), consisting of multiple Tensors. The tuple by default returns two important Tensors:
>>> len(bert_output)
2-
last_hidden_state: The semantic vector for each position in the output sequence, shaped as: (batch_size, sequence_length, hidden_size). -
pooler_output: The semantic vector corresponding to the [CLS]symbol, processed through a fully connected layer and tanh activation; this vector can be used for downstream classification tasks.
Downstream Tasks
BERT can perform many downstream tasks, and the transformers library implements some downstream tasks. We can also refer to the implementations in transformers to perform tasks we want to do. For example, for single text classification, the transformers library provides the BertForSequenceClassification class.
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
classifier_dropout = ...
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
...
def forward(
...
):
...
outputs = self.bert(...)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
...In this code snippet, BertForSequenceClassification adds nn.Dropout and nn.Linear layers on top of BertModel, and during prediction, the output from BertModel is passed to nn.Linear to complete a classification task. In addition to BertForSequenceClassification, there are BertForQuestionAnswering for question answering and BertForTokenClassification for sequence labeling, such as named entity recognition.
The various APIs in transformers have many other parameter settings, such as obtaining outputs from each layer of the Transformer Encoder, etc. You can visit their documentation (https://huggingface.co/docs/transformers/) for usage methods.
References
-
Devlin J, Chang M-W, Lee K, Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, 2019: 4171–4186. -
Thoroughly Understanding Google BERT (https://www.jianshu.com/p/46cb208d45c3) -
Illustrated BERT Model: Building BERT from Scratch (https://cloud.tencent.com/developer/article/1389555)