
Follow the public account “ML_NLP”
Set as “starred” to receive heavy content promptly!

Attention has become a hot topic in the entire AI field, whether in machine vision or natural language processing, it is inseparable from Attention, transformer, or BERT. Below, I imitate the EM nine layers tower and propose the Attention Nine Layers Tower. I hope to communicate with everyone, and feel free to share your ideas in the comments.
The Attention Nine Layers Tower – Understanding the Nine Realms of Attention is as follows:
-
Seeing the Mountain as a Mountain – Attention is a type of attention mechanism -
Seeing the Mountain and Stones – Mathematically, Attention is a widely used weighted average -
Seeing the Mountain and Peaks – In Natural Language Processing, Attention is all you need -
Seeing the Mountain and Water – The BERT series of large-scale unsupervised learning has pushed Attention to new heights -
Water Turns Back to Mountain – In Computer Vision, Attention is an effective non-local information fusion technology -
High Mountains and Deep Waters – In Computer Vision, Attention will be all you need -
Mountain Waters Reincarnated – In Structured Data, Attention is a powerful tool for assisting GNN -
Mountains Within Mountains – The relationship between logical interpretability and Attention -
Mountain and Water Unified – Various variants of Attention and their inherent connections 1. Attention is a type of attention mechanism
As the name suggests, attention originally refers to the application of biological attention mechanisms in artificial intelligence. What are the benefits of the attention mechanism? Simply put, it can focus on the features needed to complete the target scene. For example, there is a series of features. The target scene may only need, then attention can effectively “notice” these two features while ignoring others. Attention first appeared in Recurrent Neural Networks (RNN) [1], where the author Sukhbaatar provided the following example:

In the above image, if we need to combine sentences (1) to (4) to correctly answer question Q. We can see that Q has no direct relation to (3), but we need to get the correct answer bedroom from (3). A natural idea is to guide the model’s attention, starting from the question, to look for clues from the four sentences to answer the question.

As shown in the image, through the word apple in the question, we moved to the fourth sentence, then shifted attention to the third sentence to confirm bedroom in the answer.
At this point, we should have grasped the earliest understanding of attention, reaching the first layer – Seeing the Mountain as a Mountain.
Now our question is, how to design such a model to achieve this effect?
The earliest implementation was based on explicit memory, storing the results at each step, “artificially implementing” the transfer of attention.
Still using the above example,

As shown in the image, by processing the memory and updating what is noticed, attention is achieved. This method is relatively simple but very hand-crafted, and has gradually been abandoned. We need to upgrade our cognition to reach a more abstract level.
2. Attention is a weighted average
The classic definition of Attention comes from the groundbreaking work “Attention is all you need” [2]. Although some earlier works also discovered similar techniques (such as self-attention), this paper gained supreme honor for proposing the bold and gradually validated assertion that “attention is all you need.” This classic definition is represented by the formula below.
The meaning of the formula will be discussed later, but first, let’s talk about its significance. This formula is essentially the classic definition that researchers have encountered in the last five years. This formula’s status in natural language processing is akin to Newton’s laws in classical mechanics; it has become the basic formula for building complex models.
This formula seems complex, but once understood, it is very simple and fundamental. First, let’s discuss the meaning of each letter. Literally: Q represents query, K represents key, V represents value, and is the dimension of K. At this point, someone may ask, what are query, key, and value? Because these three concepts were introduced in this paper, what is placed in the position of Q in this paper is called query, what is placed in the position of K is called key, and what is placed in the position of V is called value. This is the best interpretation. In other words, this formula is similar to Newton’s laws; it can serve as a definitional formula.
To facilitate understanding, I will provide a few examples to explain these three concepts.
1. In the search field, when looking for videos on Bilibili, the key is the sequence of keywords in the Bilibili database (e.g., dance, parody, Ma Baoguo, etc.), the query is the keyword sequence you enter, such as Ma Baoguo, parody, and the value is the sequence of videos you find.
2. In recommendation systems, when buying things on Taobao, the key is all the product information in the Taobao database, the query is the product information you have recently focused on, such as high heels, tight pants, and the value is the product information pushed to you.
The above two examples are quite specific; in artificial intelligence applications, key, query, and value are often latent variable features. Therefore, their meanings are often not so obvious; what we need to grasp is this computational structure.
Returning to the formula itself, this formula essentially represents a weighted average according to the relationship matrix.
The relationship matrix is , and softmax normalizes the relationship matrix into a probability distribution, and then resamples V according to this probability distribution to finally obtain the new attention result.
The following figure shows the specific meaning of Attention in NLP. Now we consider the feature of a word it; its feature will be weighted based on the features of other words. For example, the animal may have a closer relationship with it (because it refers to the animal), so their weights are high, and this weight will affect the next layer’s feature of it. For more interesting content, please refer to The Annotated Transformer [3] and illustrate self-attention [4].

Having reached this point, one can roughly understand the basic module of attention, reaching the second layer, seeing the mountain and stones.
3. In Natural Language Processing, Attention is all you need.
The importance of the paper “Attention is all you need” lies not only in proposing the concept of attention but more importantly, in proposing the Transformer structure entirely based on attention. Being entirely based on attention means no recurrence and no convolution; it uses attention entirely. The following image compares the computational load of attention with recurrent and convolutional methods.

It can be seen that attention reduces the sequence operation to O(1) compared to recurrent methods, although the complexity of each layer increases. This is a typical computer science idea of trading space for time; due to improvements in computational structure (such as adding constraints and sharing weights) and hardware upgrades, this space is not a significant concern.
Convolution is also a model that does not require sequential operations, but its problem lies in relying on a 2D structure (thus naturally suited for images), and its computational load is still proportional to the logarithm of the input’s edge length, which is Ologk(n). However, the benefit of attention is that it can ideally reduce the computational load to O(1).
This means that here, we can already see that attention indeed has greater potential than convolution.
The Transformer model described below is essentially a simple stacking of attention modules. Since many articles have already explained its structure, this article will not elaborate further. It has dominated fields like machine translation, demonstrating its immense potential. Understanding the Transformer gives one an initial grasp of the power of attention, entering the realm of seeing the mountain and peaks.
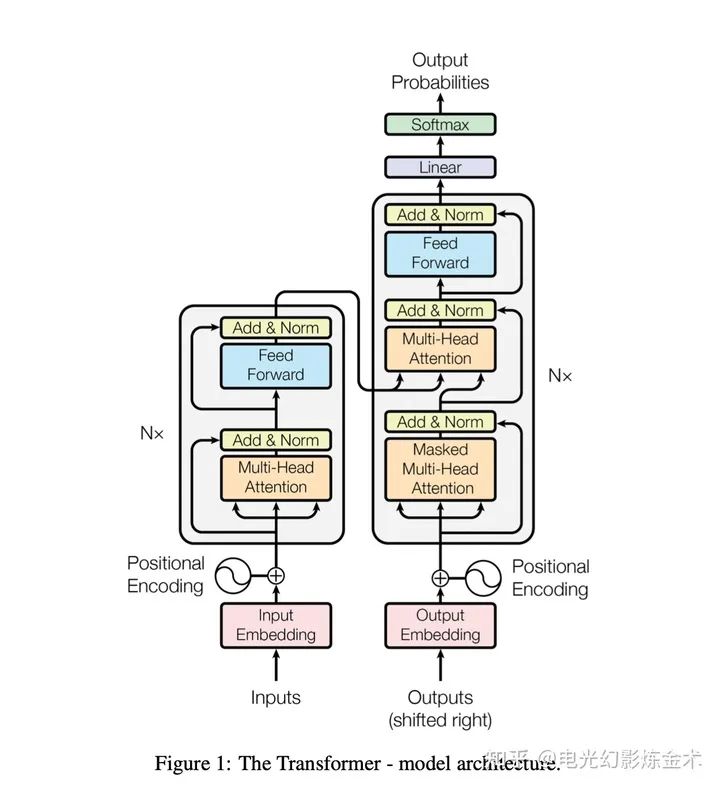
The introduction of BERT [5] has pushed attention to a whole new level. BERT creatively proposed a method of unsupervised pre-training on large-scale datasets followed by fine-tuning on target datasets, using a unified model to solve a large number of different problems. BERT performs exceptionally well, achieving remarkable improvements across 11 natural language processing tasks. It improved by 7.7% on GLUE, 4.6% on MultiNLI, and 5.1% on SQuAD v2.0.
BERT’s approach is actually quite simple; it essentially involves large-scale pre-training. It learns semantic information from large-scale data and then applies this semantic information to small-scale datasets. BERT’s contributions mainly include: 1) Proposing a bidirectional pre-training method; 2) Demonstrating that one unified model can solve different tasks without designing different networks for different tasks; 3) Achieving improvements across 11 natural language processing tasks.
Points (2) and (3) do not require much explanation. Here, let’s explain point (1). The previous OpenAI GPT inherited the concept of attention is all you need, using unidirectional attention (see the right image below), meaning the output can only attend to previous content. However, BERT (see the left image below) uses bidirectional attention. This simple design of BERT allows it to significantly outperform GPT. This is also a typical example in AI where a small design leads to a significant difference.
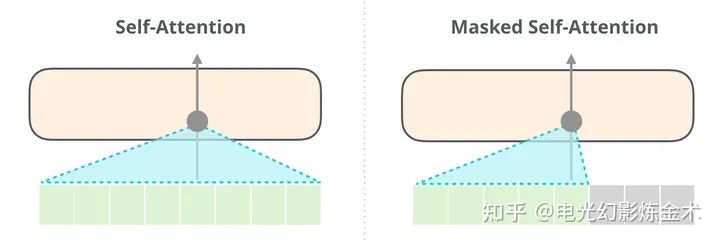
Comparison of BERT and GPT
BERT proposed several simple unsupervised pre-training methods. The first is Mask LM, which involves blocking part of a sentence and predicting the other part. The second is Next Sentence Prediction (NSP), which predicts what the next sentence is. These simple pre-training methods allow BERT to capture some fundamental semantic information and logical relationships, helping BERT achieve extraordinary results in downstream tasks.
Understanding how BERT unified the NLP landscape brings one into the new realm of seeing the mountain and water.
5. Water Turns Back to Mountain – Attention is an effective non-local information fusion technology in computer vision.
Can the attention mechanism assist in computer vision? Returning to our initial definition, attention itself is a weighting process, which means it can fuse different information. CNNs inherently have a limitation; each operation can only focus on local information (nearby information) and cannot fuse information from afar (non-local information). However, attention can help weight and integrate distant information, playing a supportive role. Networks based on this idea are called non-local neural networks [6].

For example, the information of the ball in the image may relate to the information of the person, and this is where attention comes into play.
The proposed non-local operation is very similar to attention. Suppose there are two points of image features and can calculate the new feature as:
The normalization term in the formula, and functions f and g can be flexibly chosen (note that the attention discussed earlier is actually a specific case of f and g). In the paper, f is taken as a Gaussian relationship function, and g is taken as a linear function. The proposed non-local module was added to the CNN baseline methods, achieving SOTA results on multiple datasets.
Subsequently, some literature proposed other methods combining CNNs and attention [7], which also achieved improvement. Having seen this, we have gained a new level of understanding of attention.
6. High Mountains and Deep Waters – Attention will be all you need in computer vision.
In NLP, the transformer has dominated the field; can the transformer also dominate in computer vision? This idea itself is non-trivial because language is serialized one-dimensional information, while images are inherently two-dimensional information. CNNs are naturally adapted to such two-dimensional information, but transformers are designed for one-dimensional information. The previous section already mentioned that many works have considered combining CNNs and attention. So, can we design a pure transformer network for visual tasks?
Recently, more and more articles indicate that Transformers can adapt well to image data and are expected to achieve dominance in the visual domain.
The first application of the visual Transformer came from Google, called Vision Transformer [8]. The title is also interesting: an image is worth 16×16 words. The core idea of this paper is to convert an image into 16×16 words and then input it into the Transformer for encoding, followed by using a simple small network for downstream task learning, as shown in the diagram below.
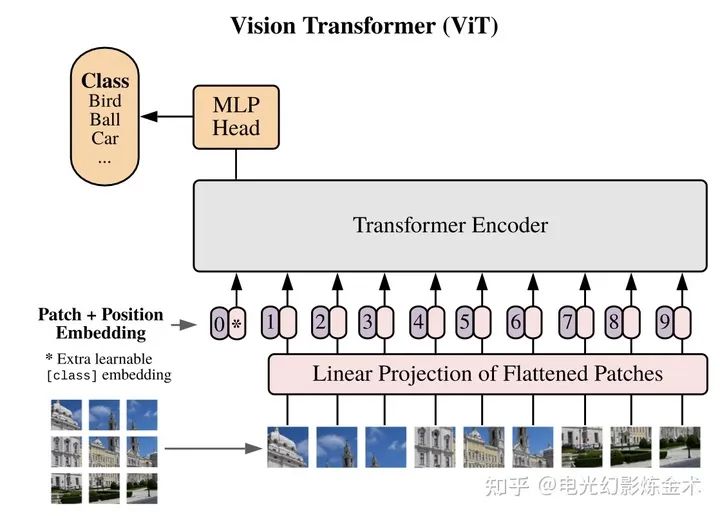
Vision transformer primarily applies the transformer to image classification tasks. So, can the transformer be used for object detection? The model proposed by Facebook, DETR (detection transformer), gives a positive answer [9]. The architecture of DETR is also very simple, as shown in the diagram below. The input is a series of extracted image features, processed through two transformers, outputting a series of object features, which are then regressed to bbox and cls through a forward network. A more detailed introduction can be found in @Tuo Fei Lun‘s article:https://zhuanlan.zhihu.com/p/266069794
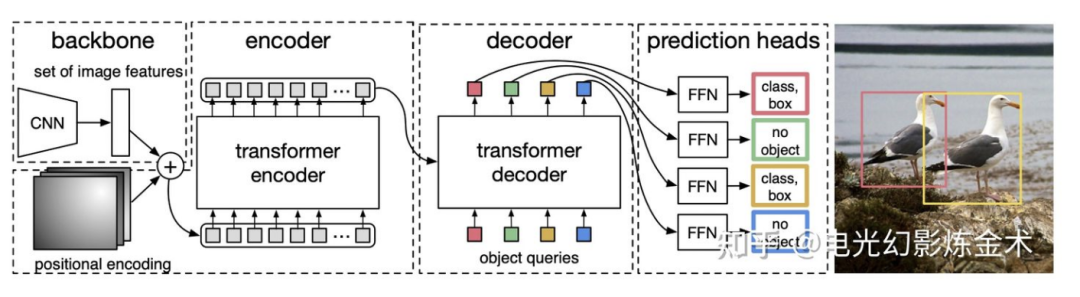
In other areas of computer vision, Transformers are also blossoming with new vitality. Currently, it has become an inevitable trend for Transformers to replace CNNs, meaning that Attention is all you need will also hold true in computer vision. Upon reaching this point, you will find that attention is high and deep water, very mysterious.
7. Mountain Waters Reincarnate – Attention is a powerful tool for assisting GNN in structured data.
In the previous layers, we have seen that attention can be well applied in one-dimensional data (like language) and two-dimensional data (like images). But can it also perform excellently in high-dimensional data (like graph data)?
The classic article that first applied attention to graph structures is Graph Attention Networks (GAT, oh, this cannot be called GAN) [10]. The fundamental problem solved by graph neural networks is how to obtain a feature representation of a graph given the structure of the graph and the features of the nodes, to achieve good results in downstream tasks (like node classification). Therefore, readers who have climbed to the seventh layer should be able to think that attention can be well used for such relational modeling.
The structure of GAT is not complicated, even though there are a few mathematical formulas. Just look at the diagram below.
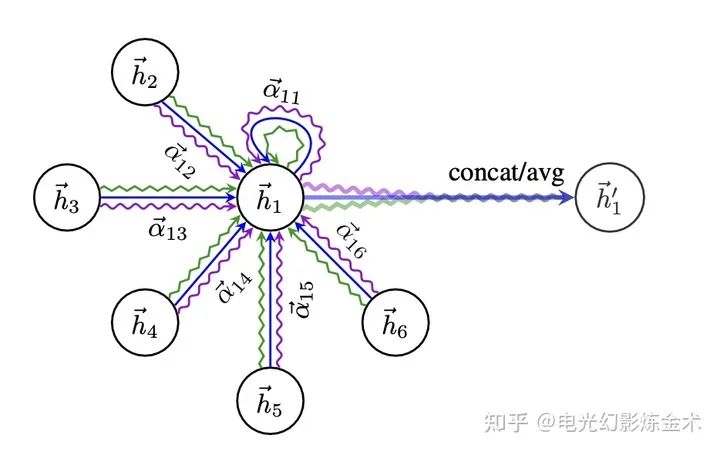
The network structure of GAT
Between each pair of nodes, attention is first performed to obtain a set of weights; for example, the weight between 1 and 2 is represented in the diagram. Then, this set of weights is used to perform a weighted average, followed by using leakyRelu as an activation function. Finally, the outputs of multiple heads can be averaged or concatenated.
Understanding that GAT is actually a straightforward application of attention brings you to the seventh layer, Mountain Waters Reincarnate.
8. Mountains Within Mountains – The relationship between logical interpretability and Attention
Even though we have discovered that attention is very useful, how to deeply understand attention is an unresolved issue in the research community. Furthermore, what constitutes a deep understanding is a completely new question. Consider this: when was CNN proposed? LeNet was introduced in 1998. We still haven’t fully understood CNN, and attention is even newer to us.
I believe that attention can be better understood than CNN. Why? In simple terms, the weighted analysis of attention naturally possesses visualizable properties. Visualization is a powerful tool for understanding high-dimensional spaces.
Two examples: the first example is BERT in NLP; analysis shows [11] that the learned features exhibit very strong structural characteristics.
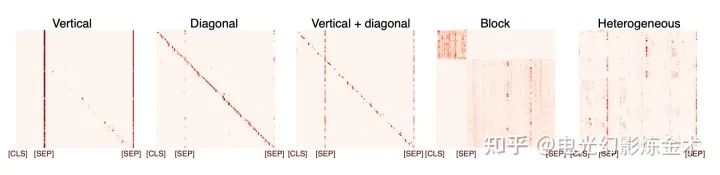
Another recent work by FACEBOOK, DINO [12], shows the attention map obtained from unsupervised training on the right. Isn’t it stunning?

At this point, the reader has reached a new realm, Mountains Within Mountains.
9. Mountain and Water Unified – Various variants of Attention and their inherent connections
Just as CNN can build very powerful detection models or more advanced models, the most powerful aspect of attention is that it can serve as a basic module to build very complex (watered-down) models.
Here are some simple variants of attention [13]. First, there is global attention and local attention.
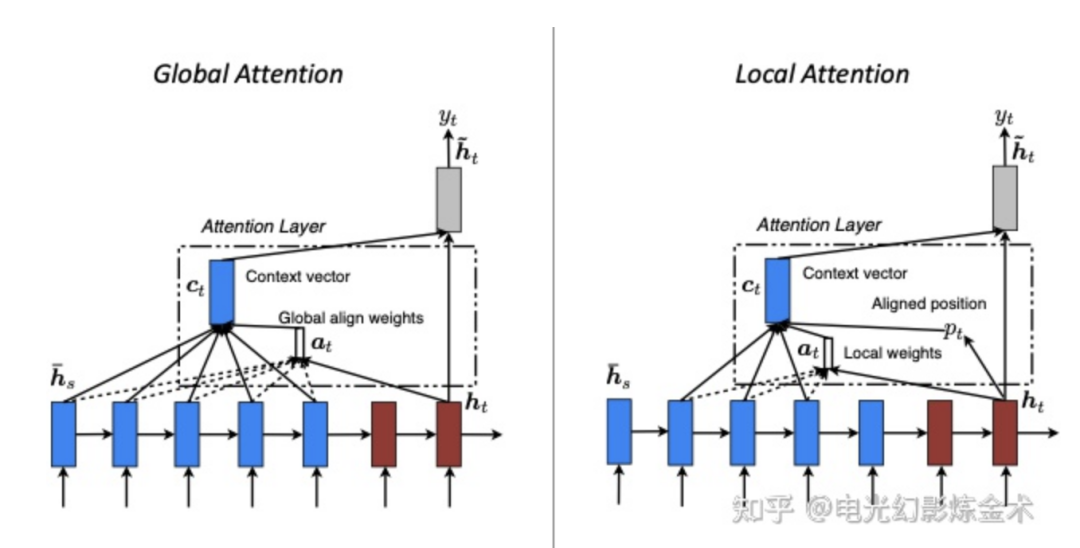
Global attention refers to what has been discussed above, while local attention allows certain features to fuse before performing attention.
The recently popular Swin Transformer can be seen as an expansion of this variant.
Video: A soul painter will help you understand in a minute how the Swin Transformer beats CNN.
https://www.zhihu.com/zvideo/1359837715438149632
Next, there is hard attention and soft attention.

What we have discussed previously is mainly soft attention. However, from a sampling perspective, we can consider hard attention, treating probabilities as a distribution and then performing polynomial sampling. This may have enlightening implications in reinforcement learning.
Recently, there have been many works suggesting that MLPs are also quite strong [14]. The author believes that they are also inspired by the attention model, adopting different structures to achieve the same effect. Of course, it is possible that attention will eventually be outperformed by MLPs.
However, the concept of attention will never become obsolete. Attention, as the simplest yet most powerful basic module for modeling data relationships, will undoubtedly become a fundamental skill for every AI practitioner.
What will also never become obsolete is the ability to understand and analyze data. The above introduced a large number of models, but what truly enables us to solve a specific problem well comes from a thorough understanding of the problem’s structure. We can discuss this topic slowly when the opportunity arises.
By now, you have reached the ninth layer of Mountain and Water Unified. All phenomena return to spring; all models merely serve to deepen our understanding of data.
Author: Top 1 Answerer in the Zhihu Graduate Student Section @Electric Light Phantom Alchemy
https://www.zhihu.com/people/zhao-ytc
References:
-
^Sukhbaatar, Sainbayar, et al. “End-to-end memory networks.” arXiv preprint arXiv:1503.08895 (2015).
-
^Vaswani, Ashish, et al. “Attention is all you need.” arXiv preprint arXiv:1706.03762 (2017). -
^http://nlp.seas.harvard.edu/2018/04/03/attention.html -
^https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention -
^Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018). -
^Wang, Xiaolong, et al. “Non-local neural networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. -
^Fu, Jun, et al. “Dual attention network for scene segmentation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019. -
^Dosovitskiy, Alexey, et al. “An image is worth 16×16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020). -
^Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European Conference on Computer Vision. Springer, Cham, 2020: 213-229. -
^Veličković, Petar, et al. “Graph attention networks.” arXiv preprint arXiv:1710.10903 (2017). -
^https://arxiv.org/abs/2002.12327 -
^https://ai.facebook.com/blog/dino-paws-computer-vision-with-self-supervised-transformers-and-10x-more-efficient-training -
^https://towardsdatascience.com/attention-in-neural-networks-e66920838742 https://towardsdatascience.com/attention-in-neural-networks-e66920838742 -
^https://arxiv.org/abs/2105.02723
Recommended Reading:
H.T. Kung's Useful Suggestions for Research
What is Transformer Position Encoding?
17 PyTorch Implementations of Attention Mechanism, Including MLP, Re-Parameter Series Hot Papers