Click on the above“Visual Learning for Beginners” to selectStar or “Top”
Important information delivered promptly
The Attention mechanism is a very important and effective technique in deep learning. This article will briefly introduce the basic principles of Attention, focusing on its variants and recent research. Below is the structure of the article:
-
Review of Attention
-
Related Work
-
Variants of Attention
-
Conclusion
1. Review of Attention
This section briefly reviews the basic knowledge of Attention.
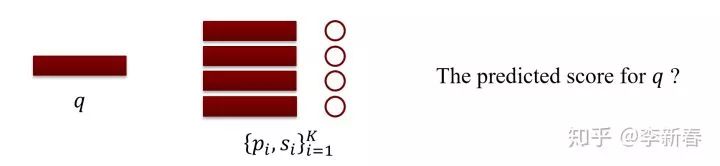
The essence of Attention is to obtain a new representation through linear weighting based on the relationships between things. For analogy, suppose we need to score a piece of text, where each text has a corresponding vector representation. Now we have a retrieval database, which consists of pairs of vector representations and scores. Given a text that needs to be scored, how do we calculate its corresponding score?
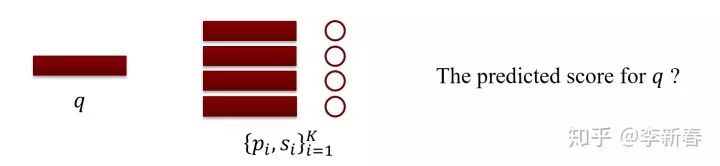
First, we need to calculate the similarity between the query text and each text in the retrieval database, denoted as , and then predict the score based on the weighted similarity: .
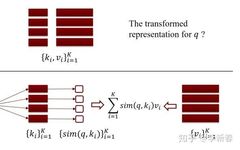
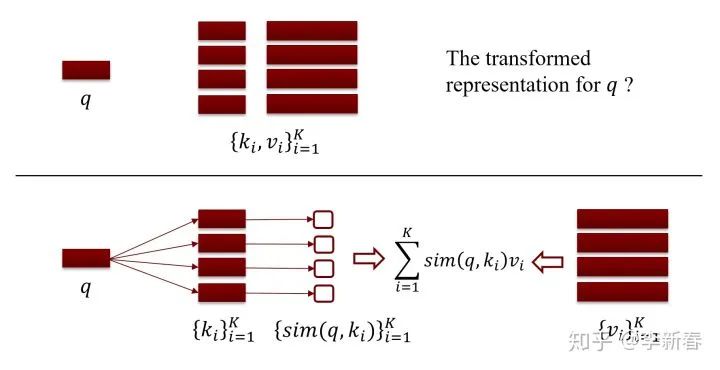
Correspondingly, Attention is given a query vector representation and the corresponding retrieval database, where represents the vector representation corresponding to the keyword. To utilize the knowledge in the retrieval database, we need to transform the representation to: .
Based on the method of calculating similarity, there are different types of Attention, including: dot product similarity, cosine similarity, and concatenated similarity, etc.
Dot product similarity:
Cosine similarity:
Concatenated similarity:
In which concatenated similarity combines two vectors and uses a learnable weight to compute the dot product for similarity, also known as Additive Attention, which refers to .
Finally, a set of weights can be obtained based on the similarity: . Sometimes to limit the size of the weights, normalization or scaling is needed, for example:
or normalization separately:
In summary, Attention calculates a set of weights based on the relationships between things and then performs weighted representation to obtain a new representation, which can be understood as a method of feature transformation.
2. Related Work
Next, we introduce related work. Attention shares similarities with many terms, such as Pooling, Aggregation, Gating, Squeeze-Excitation, etc. Below are brief introductions to each.
Pooling
Pooling is a layer often used after the convolutional layer in neural networks. To date, there are many pooling methods, such as deterministic pooling methods: Sum pooling, Mean pooling, Max pooling, K-Max pooling, Chunk-Max pooling, etc. Another category is stochastic pooling.
First, let’s briefly introduce deterministic pooling methods: as shown in the figure below (Pooling by column), the corresponding Mean, Sum, Max take the average, sum, and maximum of the corresponding values of multiple vectors, respectively. K-Max refers to taking the top K largest values and concatenating them into a vector, while Chunk-Max divides the vector into groups and takes the maximum from each group.
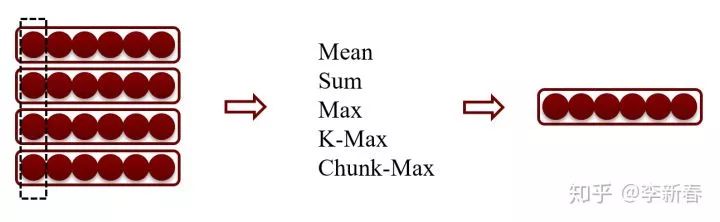
Deterministic pooling methods have many advantages, such as various invariances. However, Mean Pooling can reduce the activation value of a certain area due to averaging, while Max Pooling can be unstable.
Then, Stochastic Pooling is a method proposed in the paper “Stochastic Pooling for Regularization of Deep Convolutional Neural Networks”. It chooses a value based on the size of the activation values after ReLU according to a multinomial probability distribution, as illustrated below:
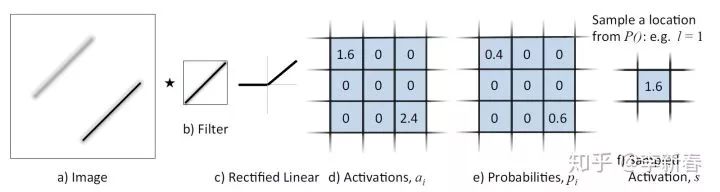
During testing, the corresponding pooling value is obtained based on the probability values, similar to the Dropout mechanism, which also serves a regularization purpose.
Aggregation
Some machine learning tasks require handling set-type datasets, which are order-invariant, such as counting crowds, point cloud classification, or multi-instance datasets. Common methods for order-invariant datasets include: 1) artificially setting an order; 2) using multiple orders to augment the training dataset; 3) processing each sample with a single function and then using an order-invariant function, such as Mean, Max, Sum, etc.
The paper “Deep Sets” provides a theorem: a function applied to a set of data is a reasonable set function (i.e., order-invariant) if and only if it can be decomposed into . This result tells us that we can process each sample with a separate transformation function and then use an aggregation function to process the obtained representations, followed by classification or regression.
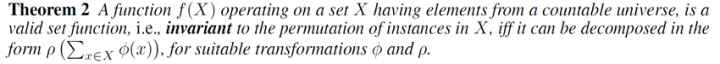
For corresponding applications, refer to PointNet, see “PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation”.
Gating
The gating technique is one of the most commonly used methods in LSTM. Taking GRU as an example, refer to the article “Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling”:
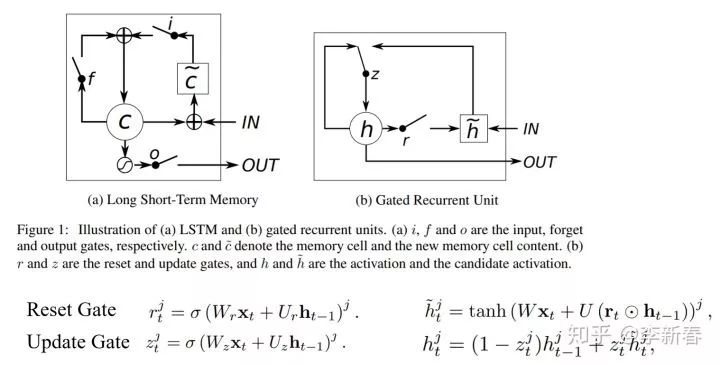
It includes a reset gate and an update gate. The Reset Gate calculates a set of values through the Sigmoid activation function for element-wise multiplication, effectively adding weights; the Update Gate calculates a set of values activated by the Sigmoid function to control whether to use new hidden layer values or old hidden layer values.
Squeeze-Excitation
This is a method proposed in CVPR 2018 “Squeeze-and-Excitation Networks” that utilizes channel information, as illustrated below:
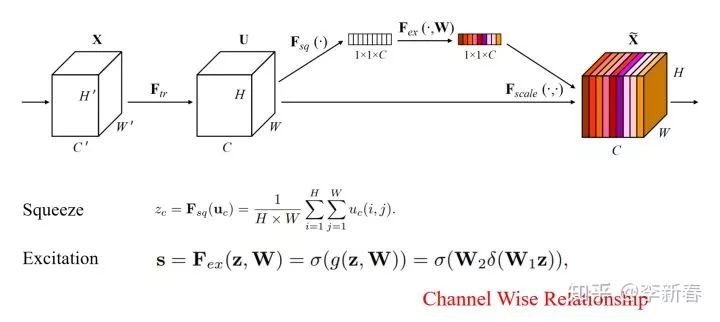
For image processing in CNNs, the output is essentially a “cube” of size: . Here, represents the channels. For each channel, we first perform Squeeze, i.e., Mean Pooling, and then use a parameterized activation function for Excitation to obtain a set of weights , which are applied to the corresponding channels.
3. Variants of Attention
This section introduces the variants of Attention, including: Feed forward attention, Self attention, Co attention, etc.
Feed forward attention
One of the most commonly used Attention mechanisms is Feed forward attention, where the query (Query) is set as a learnable parameter , and the Key and Value in the retrieval database are set to be the same, i.e., .

The resulting Attention mechanism is, and the actual implementation can use a neural network layer to compute the Attention weights:
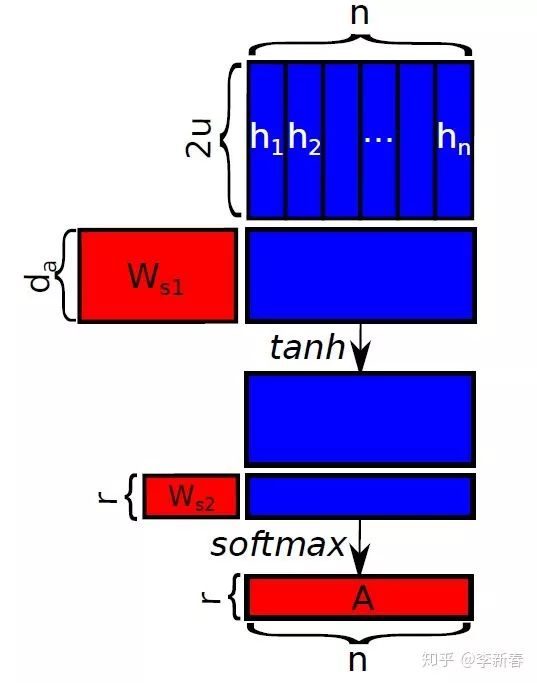
Finally, to make the Attention mechanism more complex, two neural network layers can be used to compute the Attention weights, i.e., setting multiple Queries, as shown below:

Then the calculation process is:
where calculates the dot product similarity between and S Queries, and then applies the tanh activation function to obtain S similarities, which are then weighted by another set of learnable parameters to obtain the final similarity.
Sometimes, to increase the differences between , a regularization term is added:
An illustrative diagram is shown below:
Self Attention
Self attention makes Query, Key, and Value the same, as illustrated below:

For the j-th sample, calculate its similarity with all other samples, then apply Softmax to obtain weights, and perform weighted aggregation to obtain a new representation:
For each , a Self Attention result can be obtained, so for all , the new representation is:
First calculate the pairwise dot products , then perform Softmax by rows to obtain weights, and then obtain the weighted results.
Sometimes, in some sequence-related data, additional prior positional relationships are added, such as a method in “Self-Attention with Relative Position Representations”:
Here, are a series of learnable parameters.
Multi Head Attention
In the paper “Attention Is All You Need” proposing the Transformer, Multi Head Attention was introduced, as shown below:
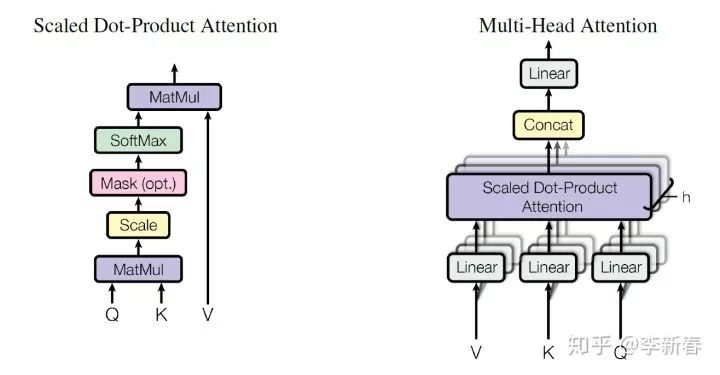
Scaled Dot Product Attention refers to:
Multi Head Attention uses multiple sets of Attention to obtain corresponding results and concatenates them:
Then in ACL 2019, there was a paper “Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned” that analyzed multiple Heads, with some interesting conclusions. Most of the roles of multiple Heads are redundant, many can be pruned, and the Heads can be classified.
The article ran experiments on multiple datasets and found that most Heads can be divided into the following types:
-
Positional Head: This Head usually computes weights that point to nearby words, with a rule that this Head assigns the largest weight to a word on the left or right in 90% of cases.
-
Syntactic Head: This Head usually computes weights that relate the relationships between words, such as the relationship between nouns and verbs.
-
Rare Head: This Head usually assigns large weights to rare words.
The article also analyzed how to prune Heads, with optimization methods as follows (adding weights to each Head, equivalent to gating):
Then optimize , adding a sparse regularization loss:
Finally, to approximate , the optimization of can use the Gumbel Softmax technique, so that each training iteration effectively samples from multiple Heads to perform calculations, with the sampling basis (parameter ) implemented via Gumbel Reparameterization.
Convolution Attention
In convolutional neural networks, Attention has many more variants, such as CBAM proposed in ECCV 2018 “CBAM: Convolutional Block Attention Module”:
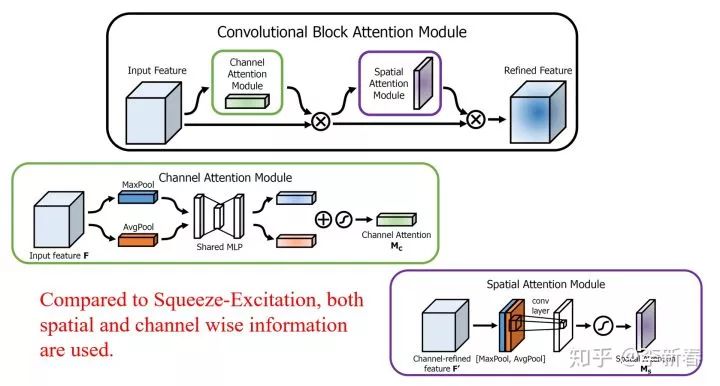
First, calculate the weights for each channel through Channel-wise computation, similar to Squeeze-Excitation, but this method also considers both Global Max Pool and Global Average Pool. Additionally, it weights the Spatial information.
Pyramid Attention
Next, we introduce Pyramid Attention, which originates from the Pyramid Pooling technique. For Pyramid Pooling, we recommend reading Kaiming He’s “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”, as illustrated below:
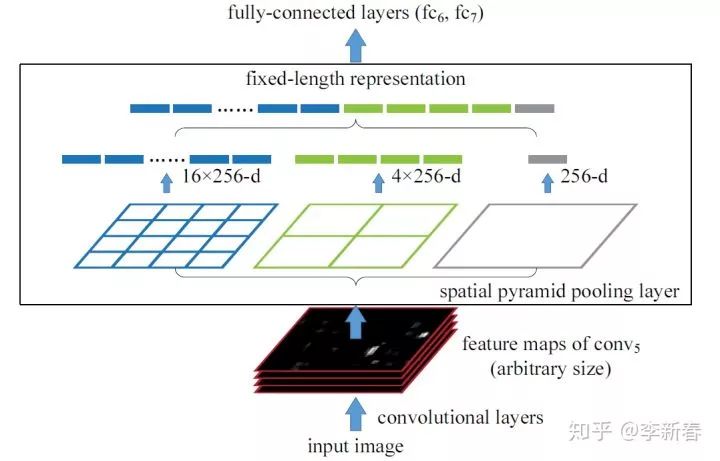
The input image goes through convolutional layers to obtain feature maps, then through a Spatial Pyramid Pooling layer to obtain pooling results of different sizes. For example, the rightmost pooling in the figure obtains 256 values (with 256 channels) through global pooling for each channel, while the middle one partitions each feature layer into four regions for pooling, thus obtaining 4 * 256 values, and so on. The pooling results from each level are then concatenated into a vector.
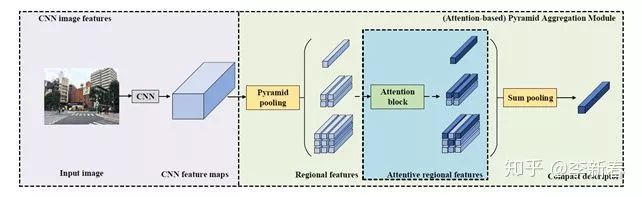
Regarding Pyramid Attention, similar to Pyramid Pooling, multiple levels of Attention can be used, and then the vectors concatenated to obtain a single vector, such as in the ACM MM 2018 paper “Attention-based Pyramid Aggregation Network for Visual Place Recognition”:
Co Attention
In various tasks, there may be paired inputs, such as Video Object Segmentation or Question Answering. Each input goes through a network to obtain a set of vectors, and then the two sets of vectors attend to each other, which is Co Attention.
For example, in the CVPR 2019 paper “See More, Know More: Unsupervised Video Object Segmentation With Co-Attention Siamese Networks”, for the Video Segmentation task, two frames of images are processed through Siamese Networks to obtain corresponding multi-channel representations, and then the two attend to each other:
Then Softmax is applied row-wise and column-wise to obtain weights, and the Attention results are concatenated with the original features, forming the Co Attention framework:
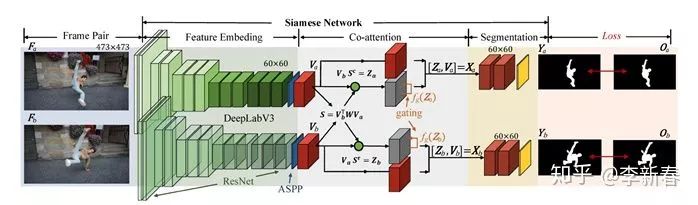
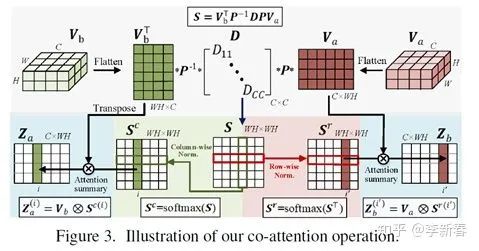
Cross Attention
Cross Attention is similar to Co Attention, as in the recent NeurIPS 2019 paper “Cross Attention Network for Few-shot Classification”:
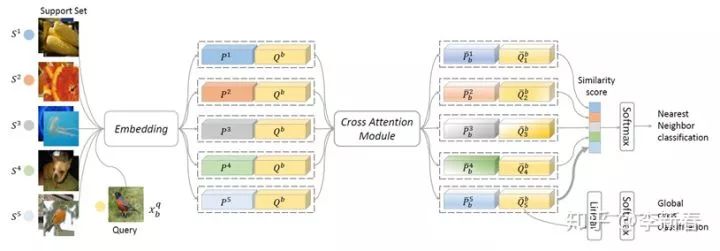
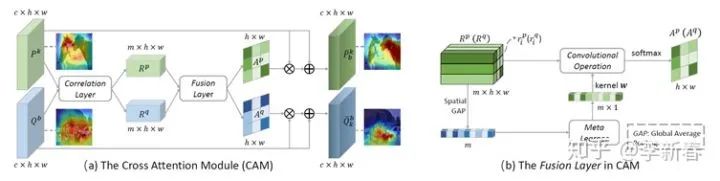
In this case, each image in the Query and Support Set goes through a network to extract features, obtaining corresponding features, and then they attend to each other to obtain reorganized features, followed by similarity calculation for Meta Training.
Soft vs. Hard Attention
As mentioned above, Attention is a process based on a set of weights for weighting. Usually, the weights are based on continuous values after Softmax, i.e., Soft Attention; however, to better exclude unnecessary interference, sparse or even One-Hot weights can be used for weighting, i.e., Hard Attention.
The differences between Soft and Hard are discussed in the ICML 2015 paper “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”. Hard Attention is more difficult to train because the optimization process involves optimizing discrete weights, hence the article employs reinforcement learning methods for optimization, namely REINFORCE.
In Image Captioning, the input is an image and the output is a sentence. Let the image feature be , and the target sentence be , thus the optimization goal is to maximize the likelihood , where is a sequence. Let denote the hidden variable, which refers to the attended position, such as indicating that when generating the k-th word, the position attended is the m-th position. The derivation of the optimization goal is:
During the training process, based on the image feature and the previous , a polynomial probability distribution parameter is generated, denoted as the parameters required for the generation process:
Then sampling is performed based on the polynomial distribution:
According to the generated attended position, combined with the corresponding image features, the sentence is generated, the likelihood is calculated, and the loss is computed, noting that this part of the parameter is . The derivative of the optimization goal can yield (where ):
Using Monte Carlo estimation, the gradient estimate can be obtained:
The above gradient comprises two parts, the first part is the optimization of the polynomial distribution parameters, which can be seen as optimized by REINFORCE, where the reward ; the second part optimizes the sentence generation process, with parameters , and normal optimization is used, with the likelihood function gradient.
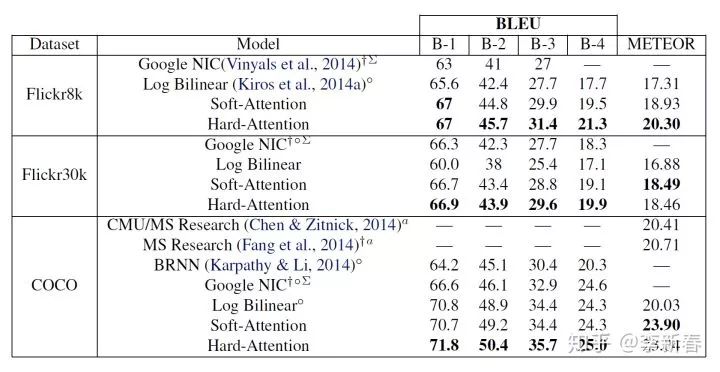
Notably, the effect of Hard in this article is slightly better than Soft:
Global vs. Local Attention
Global Attention is a global attention mechanism that utilizes all sequences to compute weights. However, if the sequence length is too long, the Soft-based weights tend to converge to small values, thus requiring Local Attention for processing, where a region for attention computation is pre-selected, similar to Pointer Networks.
Local Attention is a mechanism that lies between Soft and Hard Attention, introduced in the EMNLP 2015 paper “Effective Approaches to Attention-based Neural Machine Translation”. It is quite simple; the difference between Global and Local Attention can be well explained by the following two figures:
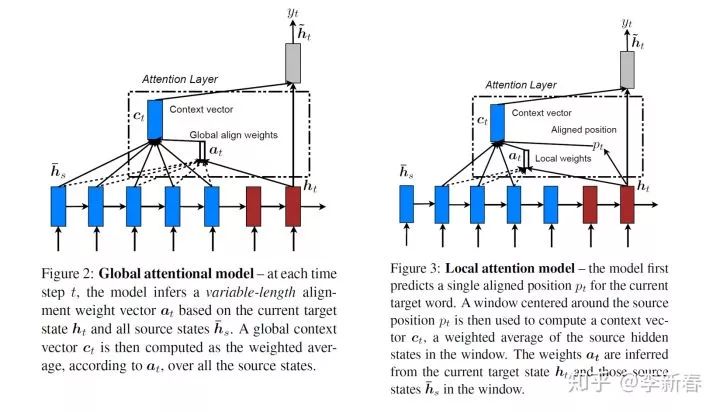
The blue part in the figure represents the sequence of the Encoder, while the brown part represents the sequence of the Decoder. On the left is Global Attention, which computes weights based on and all Encoder sequences, then performs weighting to obtain ; on the right is Local Attention, which first generates an Aligned position based on , then selects a portion (the right figure selected three) for weighting.
Compositional Attention
At NeurIPS 2019, the paper “Compositional De-Attention Networks” proposed the following framework:
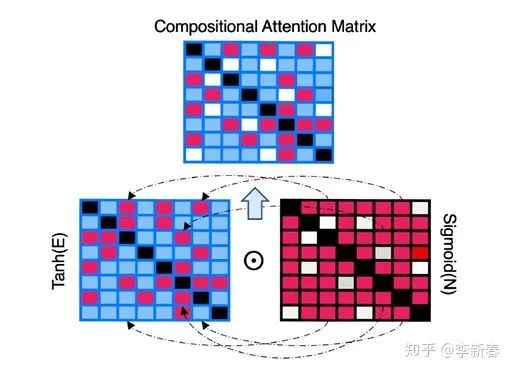
The article combines two types of similarities: Pairwise Affinity & Distance Dissimilarity.
Pairwise Affinity refers to , and Distance Dissimilarity refers to , where is the encoding function and is the scaling factor. The final Attention calculation method is:
Thus, it can be seen that the core of CoDA lies in constructing similarities, employing two calculation methods and two different activation functions in combination.
Dual Attention
In fact, the idea of Compositional Attention did not emerge in NeurIPS 2019; many earlier articles have utilized various forms of Attention to construct models. For example, the combination of Local Attention and Global Attention, as well as the combination of Positional Attention and Channel Attention in convolutional networks, etc.
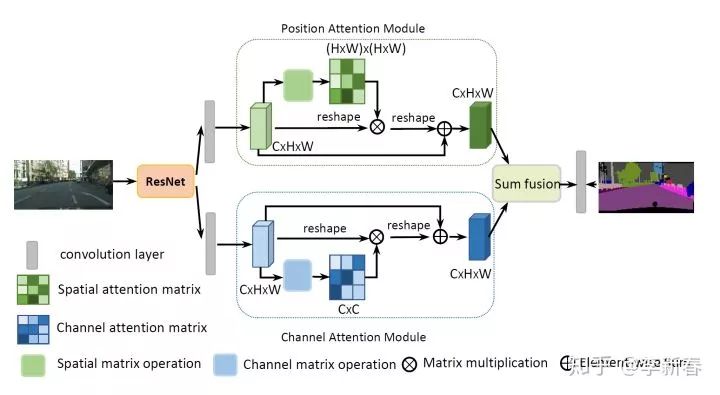
For example, in the CVPR 2019 paper “Dual Attention Network for Scene Segmentation”:
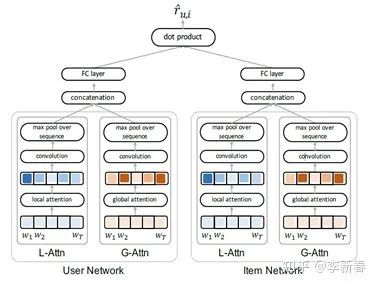
As well as the article RecSys 2017 “Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction”:
4. Conclusion
In conclusion, the essence of Attention is weighting, where the weights reflect the points the model focuses on. With the development of various technologies, the variants of Attention are increasing and are gradually being applied to various tasks in computer vision, natural language processing, few-shot learning, recommendation systems, and more.
Good news!
Visual Learning for Beginners Knowledge Community
is now open to the public 👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Visual Learning for Beginners" public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Project 52 Lectures
Reply "Python Visual Practical Project" in the background of the "Visual Learning for Beginners" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, adding eyeliner, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the background of the "Visual Learning for Beginners" public account to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
You are welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually subdivide in the future). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for remarks, otherwise, entry will not be granted. After successful addition, invitations will be sent to relevant WeChat groups based on research directions. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~