
Why summarize Transformers through eighteen questions?
There are two reasons:
First, Transformer is the fourth major feature extractor after MLP, RNN, and CNN, also known as the fourth foundational model; the recently popular chatGPT is also based on Transformer, highlighting its importance.
Second, I hope that by asking questions, we can better help everyone understand the content and principles of Transformers.
1. What was the major breakthrough in deep learning in 2017?
Transformer. There are two reasons:
1.1 On one hand, Transformer is the fourth major feature extractor in deep learning (also known as a foundational model). What is a feature extractor? The brain is how humans interact with the external world (images, text, speech, etc.); a feature extractor is a way for computers to mimic the brain and interact with the external world (images, text, speech, etc.), as shown in Figure 1. For example, the Imagenet dataset contains 1000 classes of images, and people have categorized one million images into these classes based on their experience, with each class of images (like a jaguar) having unique features. At this point, neural networks (like ResNet18) also aim to extract or recognize the unique features of each class of images as much as possible through this classification method. Classification is not the final goal; it is a means of extracting image features, and masking to complete images is also a way of feature extraction, as is shuffling the order of image blocks.
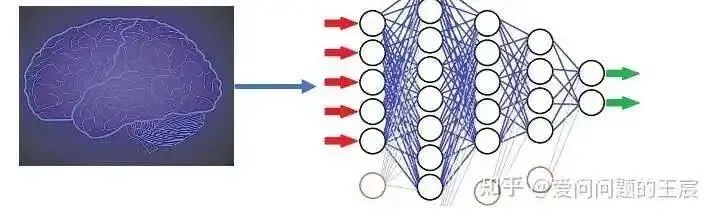
Figure 1 Neural networks mimic neurons in the brain
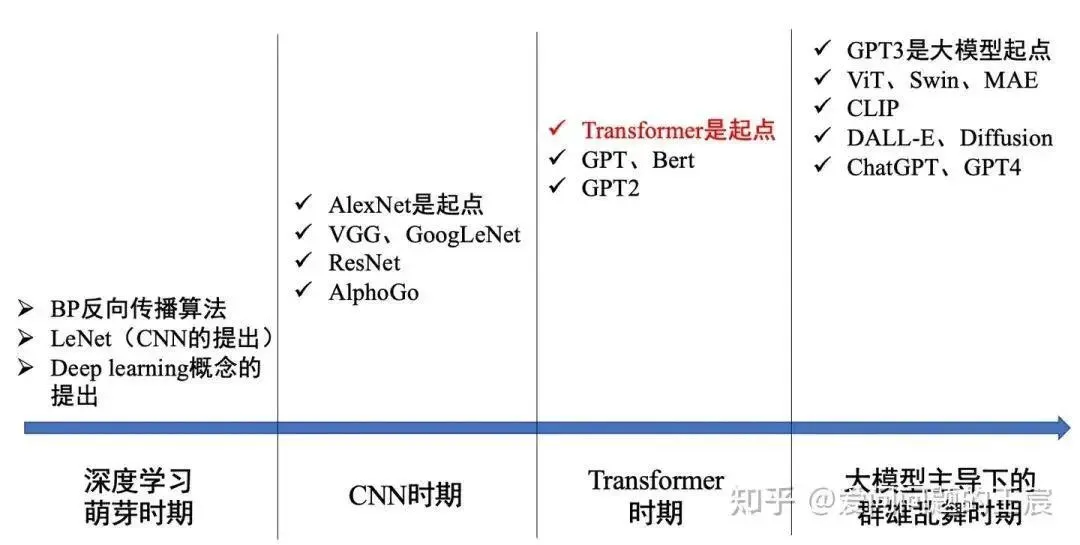
1.2 On the other hand, the role of Transformer in deep learning: the cornerstone of the third and fourth waves, as shown in Figure 2.
2. What is the background of the Transformer?
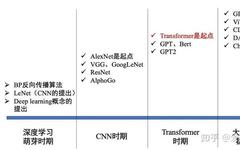
2.1 In terms of field development background: At that time in 2017, deep learning had been booming in the field of computer vision for several years. From AlexNet, VGG, GoogLenet, ResNet, DenseNet; from image classification, object detection to semantic segmentation; but there was not much impact in the field of natural language processing.
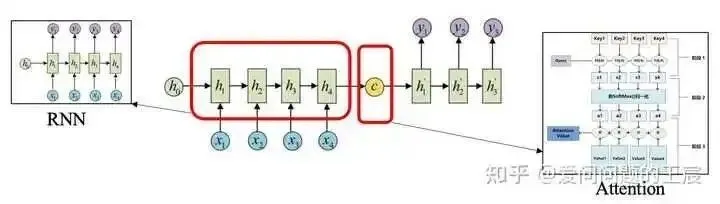
2.2 In terms of technology background: (1) The mainstream solutions for sequence transcription tasks (like machine translation) at that time are shown in Figure 3. Under the Sequence to Sequence architecture (a type of Encoder-Decoder), RNN extracts features, and the Attention mechanism efficiently transmits the features extracted by the Encoder to the Decoder. (2) This approach has two shortcomings: on one hand, the RNN’s inherent sequential structure from front to back means it cannot perform parallel computation; on the other hand, when the sequence length is too long, the information from the earliest part of the sequence may be forgotten. Therefore, it can be seen that within this framework, RNN is a relatively weak area that urgently needs improvement.
3. What exactly is a Transformer?
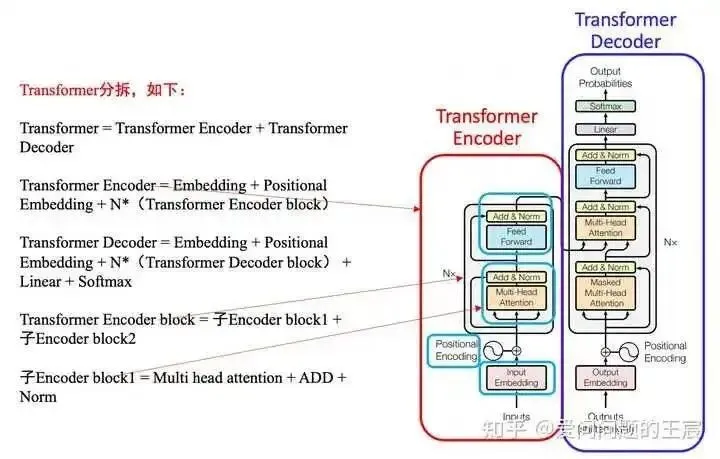
3.1 Transformer is an architecture composed of Encoder and Decoder. So what is architecture? The simplest architecture is A+B+C.
3.2 Transformer can also be understood as a function, where the input is “I love learning” and the output is “I love study”.
3.3 If we break down the architecture of Transformer, as shown in Figure 4.
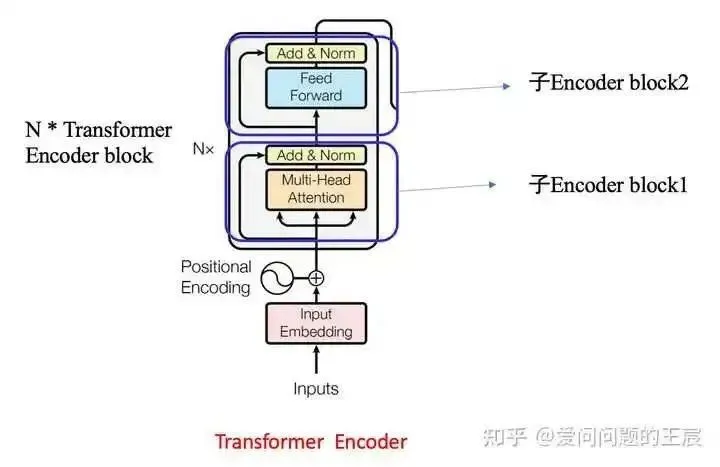
4. What is the Transformer Encoder?
4.1 From a functional perspective, the core role of the Transformer Encoder is to extract features, and the Transformer Decoder can also be used to extract features. For example, when a person learns to dance, the Encoder is watching others dance, while the Decoder is showcasing the learned experiences and memories.
4.2 From a structural perspective, as shown in Figure 5, the Transformer Encoder = Embedding + Positional Embedding + N*(Sub-Encoder block1 + Sub-Encoder block2);
Sub-Encoder block1 = Multi-head attention + ADD + Norm;
Sub-Encoder block2 = Feed Forward + ADD + Norm;
4.3 From the input-output perspective, the input of the first Encoder block in N Transformer Encoder blocks is a set of vectors X = (Embedding + Positional Embedding), where the vector dimension is usually 512*512. The inputs of the other N Transformer Encoder blocks are the outputs of the previous Transformer Encoder block, and the output vector dimension is also 512*512 (the input and output sizes are the same).
4.4 Why 512*512? The former refers to the number of tokens, for example, “I love learning” has 4 tokens, and here it is set to 512 to encompass different sequence lengths, with padding when insufficient. The latter refers to the vector dimension generated for each token, meaning each token is represented by a vector of length 512. It is commonly said that Transformers cannot exceed 512, otherwise the hardware may struggle; in fact, 512 refers to the former, the number of tokens, because each token must perform self-attention operations; however, the latter’s 512 should not be too large, otherwise computation will be slow.
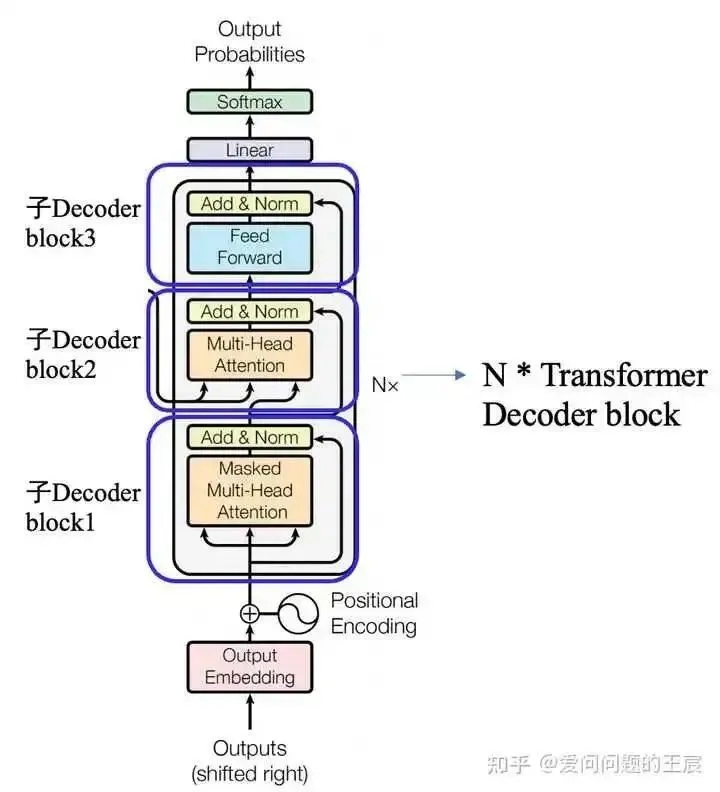
5. What is the Transformer Decoder?
5.1 From a functional perspective, compared to the Transformer Encoder, the Transformer Decoder is better at generative tasks, especially for natural language processing problems.
5.2 From a structural perspective, as shown in Figure 6, the Transformer Decoder = Embedding + Positional Embedding + N*(Sub-Decoder block1 + Sub-Decoder block2 + Sub-Decoder block3) + Linear + Softmax;
Sub-Decoder block1 = Mask Multi-head attention + ADD + Norm;
Sub-Decoder block2 = Multi-head attention + ADD + Norm;
Sub-Decoder block3 = Feed Forward + ADD + Norm;
5.3 From the perspective of the function of (Embedding + Positional Embedding) (N Decoder blocks) (Linear + Softmax):
Embedding + Positional Embedding: For example, in machine translation, the input “Machine Learning” outputs “机器学习”; here, Embedding converts “机器学习” into a vector format.
N Decoder blocks: The feature processing and transmission process.
Linear + Softmax: Softmax predicts the probability of the next word appearing, as shown in Figure 7, where the previous Linear layer is similar to the MLP layer before the classification layer in a classification network (ResNet18).
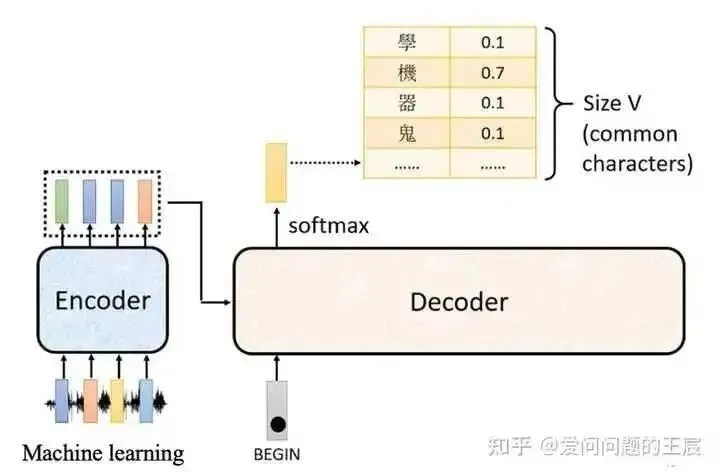
5.4 What are the inputs and outputs of the Transformer Decoder? They differ during training and testing.
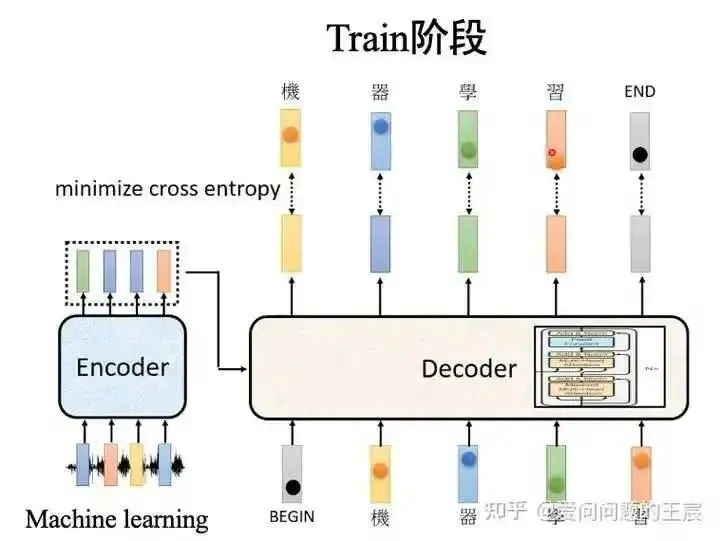
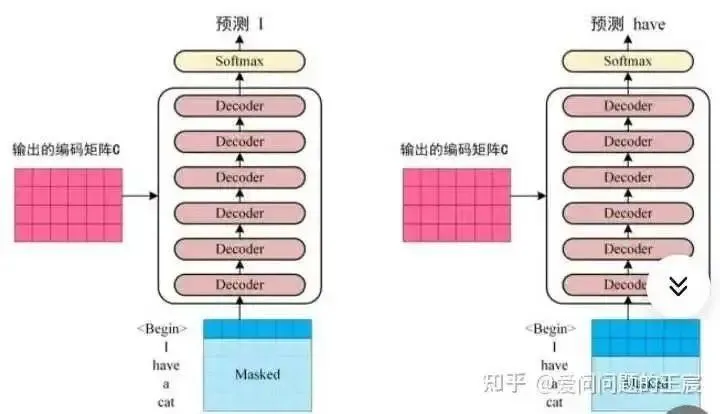
During the training phase, as shown in Figure 8, the labels are known. The first input to the decoder is the begin character, and the output of the first vector is compared with the first character in the label using cross-entropy loss. The second input to the decoder is the label of the first vector, and the Nth input corresponds to the End character, marking the end. It can be seen that during the training phase, parallel training can be performed.
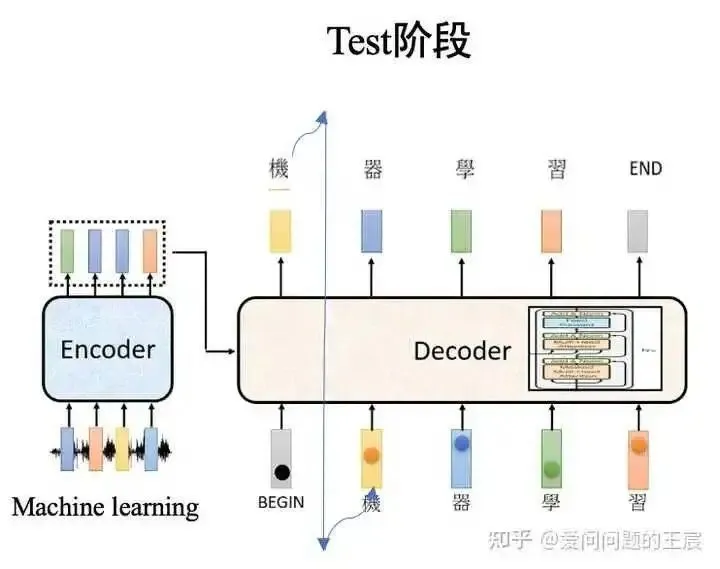
During the testing phase, the input for the next moment is the output from the previous moment, as shown in Figure 9. Therefore, during training and testing, there may be a mismatch in the input to the decoder. In testing, it is possible for one mistake to lead to a series of mistakes. There are two solutions: one is to occasionally introduce errors during training, and the other is Scheduled sampling.
5.5 What are the inputs and outputs of the Transformer Decoder block? The previous discussion was about the overall inputs and outputs during training and testing, but what are the inputs and outputs of the Transformer Decoder block inside the Transformer Decoder, as shown in Figure 10?
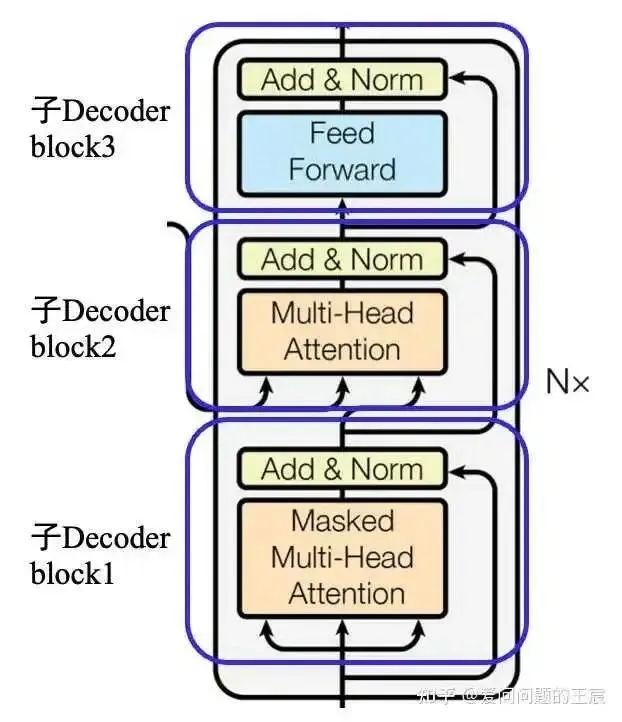
For the first iteration in N=6 (when N=1): the input to Sub-Decoder block1 is embedding + Positional Embedding; the input to Sub-Decoder block2’s Q comes from the output of Sub-Decoder block1, while the KV comes from the output of the last layer of the Transformer Encoder.
For the second iteration in N=6: the input to Sub-Decoder block1 is from N=1, and the output of Sub-Decoder block3 also comes from the last layer of the Transformer Encoder.
In summary, it can be seen that whether during training or testing, the input to the Transformer Decoder comes not only from (ground truth or the output from the previous decoder), but also from the last layer of the Transformer Encoder.
During training: the input for the ith decoder = encoder output + ground truth embedding.
During prediction: the input for the ith decoder = encoder output + the (i-1)th decoder output.
6. What are the differences between Transformer Encoder and Transformer Decoder?
6.1 In terms of function, the Transformer Encoder is commonly used to extract features, while the Transformer Decoder is often used for generative tasks. The Transformer Encoder and Decoder represent two different technical paths; Bert adopts the former while the GPT series models adopt the latter.
6.2 In terms of structure, the Transformer Decoder block includes 3 sub-Decoder blocks, while the Transformer Encoder block includes 2 sub-Encoder blocks, and the Transformer Decoder uses Mask multi-head Attention.
6.3 From the input-output perspective, the output of N Transformer Encoder operations is formally input into the Transformer Decoder as K and V in QKV. So how is the output of the last layer of the Transformer Encoder sent to the Decoder? As shown in Figure 11.
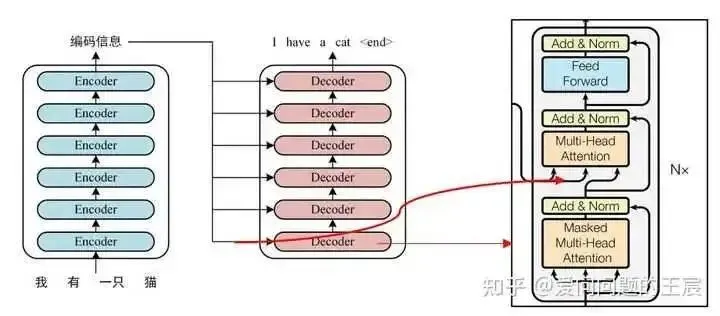
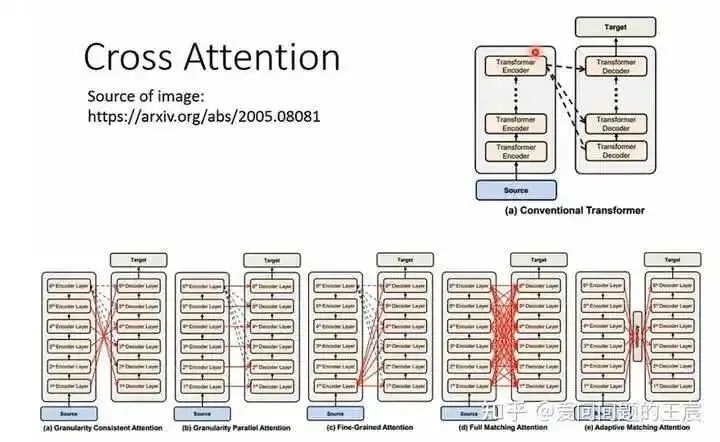
So why must the Encoder and Decoder use this interaction method? It is not strictly necessary; different interaction methods have been proposed subsequently, as shown in Figure 12.
7. What is Embedding?
7.1 The position of Embedding in the Transformer architecture is shown in Figure 13.
7.2 Background: Computers cannot directly process a word or a Chinese character; a token must be converted into a vector that the computer can recognize, which is the embedding process.
7.3 Implementation: The simplest embedding operation is the one-hot vector, but the one-hot vector has the disadvantage of not considering the relationships between words. Subsequently, Word Embedding was developed, as shown in Figure 13.

8. What is Positional Embedding?
8.1 The position of Positional Embedding in the Transformer architecture is shown in Figure 14.
8.2 Background: RNN, as a feature extractor, inherently carries information about the order of words; however, the Attention mechanism does not consider the order, which significantly impacts semantics. Therefore, it is necessary to add positional information to the input embedding through Positional Embedding.
8.3 Implementation: Traditional positional encoding and automatically trained neural networks.

9. What is Attention?
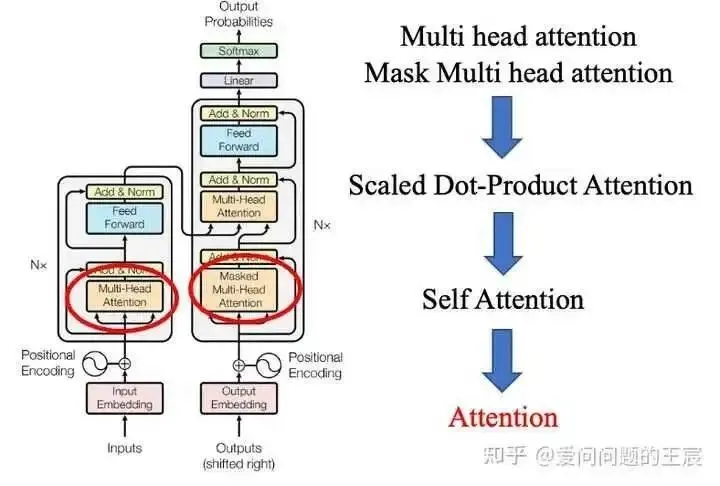
9.1 Why introduce Attention when discussing Transformers? Because the most prevalent multi-head attention and Mask multi-head attention in Transformers come from Scaled dot product attention, which in turn comes from self-attention. Therefore, it is essential to understand Attention, as shown in Figure 15.
9.2 What does Attention mean?
For images, attention refers to the key areas that people focus on in the image, the highlights of the image, as shown in Figure 16. For sequences, the Attention mechanism is essentially to find the relationships between different tokens in the input, finding the relationships between words through a weight matrix.

9.3 How is Attention implemented?
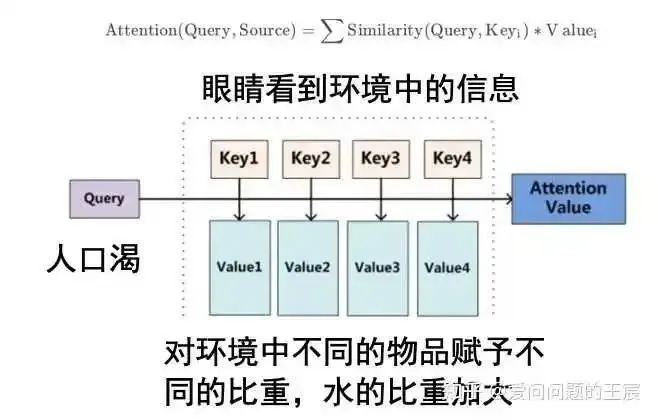
It is implemented through QKV.
So what is QKV? Q is query, K is keys, and V is values. For example, Q is the signal sent by the brain when I feel thirsty; K is the environmental information that my eyes see; V is assigning different weights to different items in the environment, increasing the weight of water.
In summary, Attention is achieved by calculating the similarity between Q and K and multiplying it with V to get the attention value.
9.4 Why must there be Q, K, and V?
Why not just Q? Because the relationship weight between Q1 and Q2 requires not only a12 but also a21. You might ask, can we set a12 = a21? It is possible, but theoretically, the effect should not be as good as having both a12 and a21.
Why not just Q and K? The obtained weight coefficient needs to be incorporated into the input, which can be multiplied by either Q or K, but why multiply by V? This might introduce an additional set of trainable parameters WV, enhancing the network’s learning capability.
10. What is Self Attention?
10.1 Why introduce self-attention when discussing Transformers? Because the most prevalent multi-head attention and Mask multi-head attention in Transformers come from Scaled dot product attention, which in turn comes from self-attention, as shown in Figure 15.
10.2 What is self-attention? Self-attention, local attention, and stride attention are all types of attention; self-attention calculates the attention coefficient for each Q with each K sequentially, as shown in Figure 18, while local attention only calculates the attention coefficient for Q with adjacent Ks, and stride attention calculates the attention coefficient for Q with Ks at intervals.
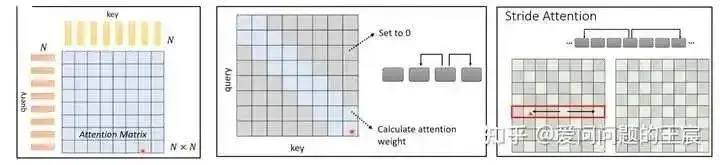
10.3 Why can self-attention be used to process sequence data like machine translation?
Each position’s data in the input sequence can attend to information from other positions, thus extracting features or capturing the relationships between each token in the input sequence through Attention scores.
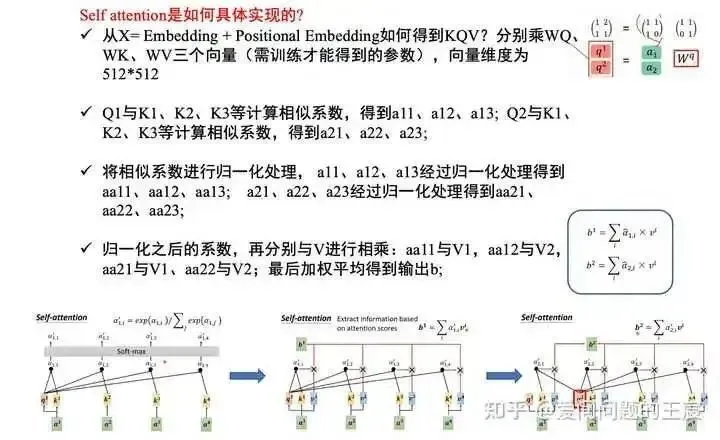
10.4 How is self-attention specifically implemented? It is divided into 4 steps, as shown in Figure 19.
11. What is Scaled Dot Product Attention?
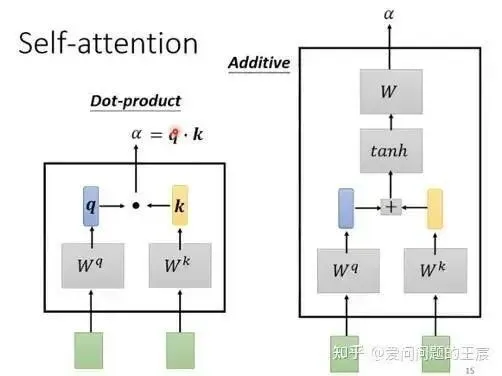
11.1 The most common types of self-attention are dot product attention and additive attention, as shown in Figure 20, with the former being more computationally efficient.
11.2 What is Scaled?
The specific implementation of scaled is shown in Figure 21. This operation aims to prevent the inner product from becoming too large, avoiding close-to-1 gradients for easier training; it has some similar functions to batch normalization.
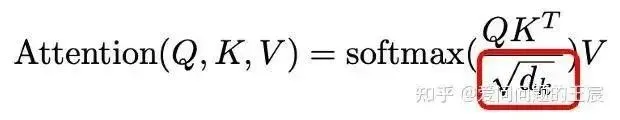
12. What is Multi-head Attention?
12.1 The position of Multi-head attention in the Transformer architecture is shown in Figure 15.
12.2 Background: CNN has multiple channels, which can extract feature information from multiple dimensions of an image. Can self-attention have a similar operation to extract information from multiple dimensions of tokens at different distances?
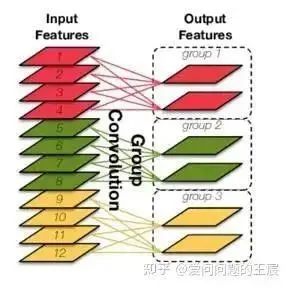
12.3 What is group convolution? As shown in Figure 22, it separates the input features into several groups for independent convolution, which is then concatenated.
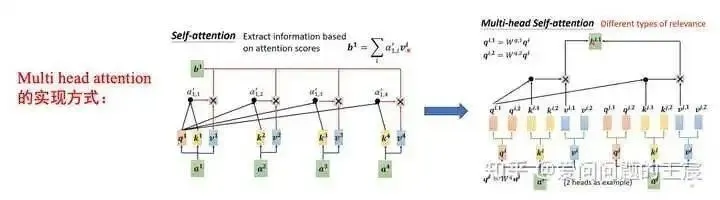
12.4 What is the implementation method of Multi-head attention? How is it fundamentally different from self-attention?
As shown in Figure 23, taking 2 heads as an example, the input Q, K, and V are divided into two parts, and each small part operates with the corresponding K and V. The resulting vectors are then concatenated. This shows that Multi-head attention has a similar implementation method to group convolution.
12.5 How can we understand Multi-head attention from the perspective of input-output dimensions? As shown in Figure 24.

13. What is Mask Multi-head Attention?
13.1 The position of Mask Multi-head attention in the Transformer architecture is shown in Figure 15.
13.2 Why is there a Mask operation?
The Transformer predicts the output at time T without seeing the inputs after time T, ensuring consistency between training and prediction.
The Mask operation prevents the ith word from knowing the information of the i+1th word and beyond, as shown in Figure 25.
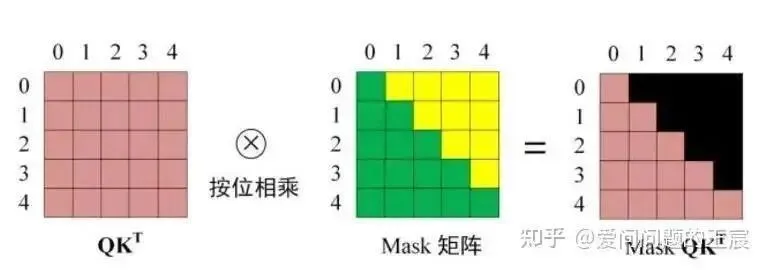
13.3 How is the Mask operation specifically implemented?
Q1 only calculates with K1, Q2 only calculates with K1 and K2, while for K3, K4, etc., a very large negative number is given before softmax, resulting in zero after softmax. The matrix calculation principle is shown in Figure 26.
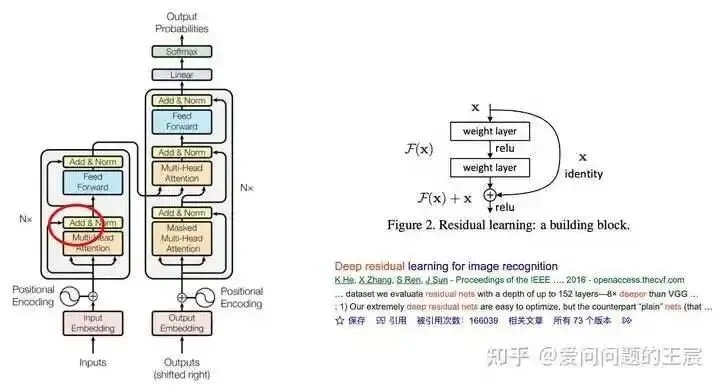
14. What is ADD?
14.1 Add refers to residual connections, popularized by the 2015 ResNet paper (which has been cited over 160,000 times). The difference from Skip connection is that the dimensions must match.
14.2 As an embodiment of the principle of simplicity, almost every deep learning model utilizes this technique to prevent network degradation and is commonly used to solve the problem of difficult training in multi-layer networks.
15. What is Norm?
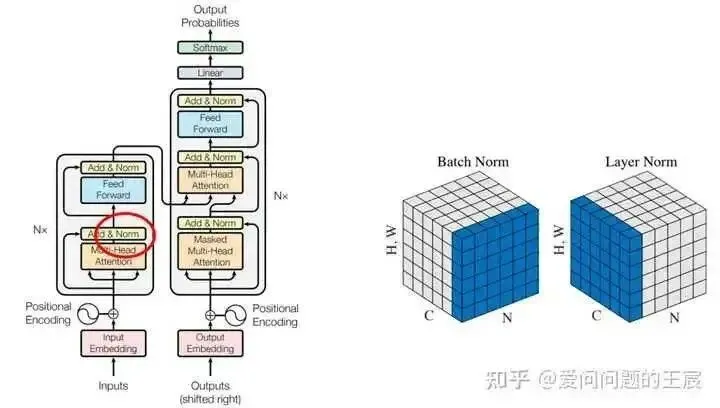
15.1 Norm refers to layer normalization.
15.2 Core function: to make training more stable, serving a similar purpose as batch normalization, which is to make the mean of the input samples zero and the variance one.
15.3 Why use layer normalization instead of batch normalization? Because for sequential data, the input sentence lengths vary. If batch normalization is used, it can easily lead to “training instability” due to the differing lengths of samples. BN operates on the same feature data across all data in a single batch, while LN operates on individual samples.
16. What is FFN?
16.1 FFN refers to feed forward networks.
16.2 Why have FFN when there is a self-attention layer? The attention layer already captures the desired sequence information features, and the MLP serves to project the information into a specific space and perform a nonlinear mapping, alternating with self-attention.
16.3 Structure: includes two layers of MLP, where the first layer has dimensions of 512*2048, and the second layer has dimensions of 2048*512, and the second layer MLP does not use an activation function, as shown in Figure 29.

17. How is the Transformer trained?
17.1 In terms of data, the Transformer paper mentions using 4.5M and 36M pairs of translation sentences.
17.2 In terms of hardware, the base model was trained on 8 P100 GPUs for 12 hours, while the large model was trained for 3.5 days.
17.3 In terms of model parameters and tuning:
First, trainable parameters include WQ, WK, WV, WO, including parameters from the FFN layer.
Second, tunable parameters include: the dimension of each token vector representation (d_model), the number of heads, the repetition count of blocks in Encoder and Decoder, the dimension of the intermediate layer in FFN, label smoothing (confidence 0.1), and dropout (0.1).
18. Why is the Transformer effective?
18.1 Although the title is “Attention is all you need”, subsequent research indicates that Attention, residual connections, layer normalization, and FFN all contribute to the success of Transformer.
18.2 Advantages of Transformer include:
First, it is the fourth major feature extractor after MLP, CNN, and RNN.
Second, initially used in machine translation, it has since expanded significantly with the advent of GPT and Bert; it marks a turning point, after which the NLP field rapidly developed, leading to the rise of multimodal models, large models, and vision Transformers.
Third, it instills confidence that there can be effective feature extractors beyond CNNs and RNNs.
18.3 What are the shortcomings of Transformer?
First, it has high computational demands and requires robust hardware.
Second, due to the lack of inductive bias, it requires a large amount of data to achieve good performance.
This article is reprinted from the WeChat public account “Artificial Intelligence Scientist”.
(End)
More exciting:
Yan Shi│The Impact of Generative AI on Computer Science Education and Countermeasures
Principal Interview|Rooted in Border Ethnic Areas, Focusing on Teacher Education to Cultivate High-Quality Applied Talents——Interview with Principal Chen Benhui of Lijiang Normal University
Yan Shi│A Review and Prospect of Computer System Capability Cultivation
Discussion on the Concept of “Student-Centered” Teaching and Its Implementation Path
Principal Interview|Promoting Interdisciplinary Integration to Cultivate Innovative Talents in the New Era——Interview with Professor Ni Mingxuan, Founding President of Hong Kong University of Science and Technology (Guangzhou)
New Year Message from the Seventh Editorial Committee
Teaching Guidelines for Ideological and Political Education in Computer Courses
Academician Chen Guoliang|Cultural Construction of Virtual Teaching and Research Office for Computer Courses
Professor Chen Daozhu of Nanjing University|Change and Constancy: The Dialectics in the Learning Process
Yan Shi│Reflections and Suggestions on the “Predicament” of Young Teachers in Colleges
Xu Xiaofei et al.|Metaverse Education and Its Service Ecosystem
【Table of Contents】 “Computer Education” 2024 Issue 10
【Table of Contents】 “Computer Education” 2024 Issue 9
【Table of Contents】 “Computer Education” 2024 Issue 8
【Editorial Message】 Professor Li Xiaoming from Peking University: Thoughts from the “Classroom Teaching Improvement Year”…
Professor Chen Daozhu from Nanjing University: Teaching students to ask questions and teaching students to answer questions, which is more important?
【Yan Shi Series】: Development Trends in Computer Science and Their Impact on Computer Education
Professor Li Xiaoming from Peking University: From Interesting Mathematics to Interesting Algorithms to Interesting Programming—A Path for Non-Major Learners to Experience Computational Thinking?
Reflections on Several Issues in Building a First-Class Computer Science Discipline
The New Engineering and Big Data Professional Construction
Learning from Others: A Compilation of Research Articles on Computer Education at Home and Abroad