
Background
The XGBoost model, known as a powerful “weapon” in machine learning, is widely used in data science competitions and industrial applications. The official XGBoost also provides runnable code for various platforms and environments, such as XGBoost on Spark for distributed training. However, in the official implementation of XGBoost on Spark, there exists an instability issue caused by the handling of missing values in XGBoost and the sparse representation mechanism of Spark.
The issue originated from feedback from a colleague using a machine learning platform within Meituan. The XGBoost model trained on this platform produced inconsistent results when called locally (Java engine) versus on the platform (Spark engine) using the same model and test data. However, when this colleague ran both engines locally (Python engine and Java engine), the results were consistent. This raised concerns about whether the XGBoost predictions from the platform could be erroneous.
The platform had conducted multiple targeted optimizations on the XGBoost model, and during testing, there had never been a case where the local call (Java engine) produced inconsistent results compared to the platform (Spark engine). Moreover, both the version running on the platform and the one used locally by the colleague were derived from the official Dmlc version, and the JNI low-level calls should be executed from the same code, theoretically resulting in completely consistent outcomes, yet in practice, they were different.
Upon reviewing the test code provided by the colleague, no issues were identified:
// A line in the test results, 41 columns
double[] input = new double[]{1, 2, 5, 0, 0, 6.666666666666667, 31.14, 29.28, 0, 1.303333, 2.8555, 2.37, 701, 463, 3.989, 3.85, 14400.5, 15.79, 11.45, 0.915, 7.05, 5.5, 0.023333, 0.0365, 0.0275, 0.123333, 0.4645, 0.12, 15.082, 14.48, 0, 31.8425, 29.1, 7.7325, 3, 5.88, 1.08, 0, 0, 0, 32];
// Convert to float[]
float[] testInput = new float[input.length];
for(int i = 0, total = input.length; i < total; i++){
testInput[i] = new Double(input[i]).floatValue();
}
// Load model
Booster booster = XGBoost.loadModel("${model}");
// Convert to DMatrix, one row, 41 columns
DMatrix testMat = new DMatrix(testInput, 1, 41);
// Call model
float[][] predicts = booster.predict(testMat);
The result of executing the above code locally is 333.67892, while the result on the platform is 328.1694030761719.
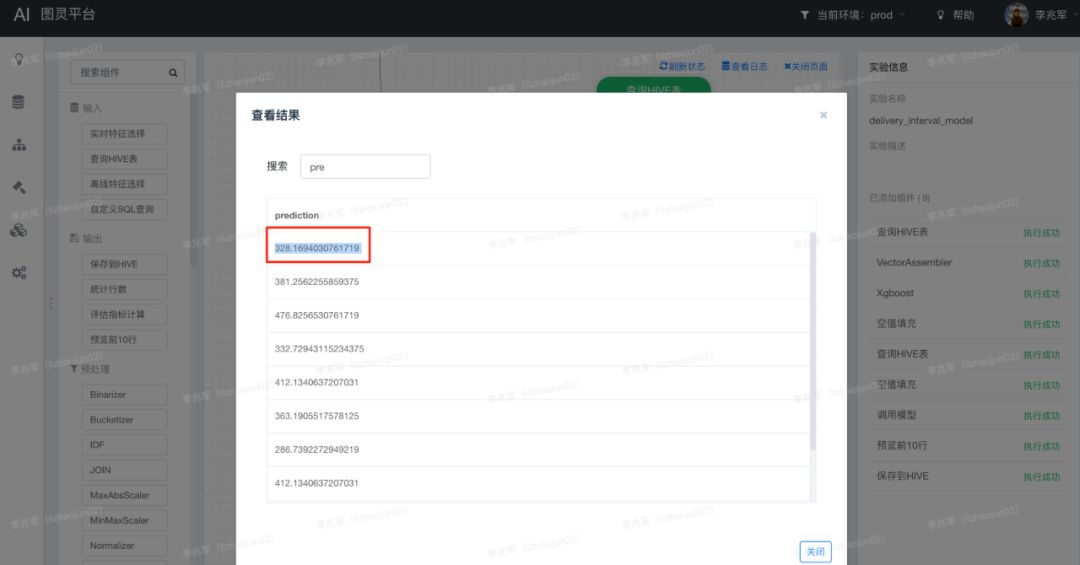
Why are the two results different? Where does the problem lie?
Investigation of Inconsistent Execution Results
How to investigate? The first thought is to check if the input field types are inconsistent between the two processing methods. If the field types or decimal precisions are different, it would explain the different results. Upon careful analysis of the model input, I noticed that the array contains a value of 6.666666666666667; could it be the cause?
After debugging and carefully comparing the input data and field types on both sides, they were found to be completely consistent.
This ruled out the possibility of inconsistencies in field types and precision between the two processing methods.
The second investigation thought is that XGBoost on Spark provides two upper-level APIs, XGBoostClassifier and XGBoostRegressor, based on the model’s functionality. These two APIs add many hyperparameters and encapsulate a lot of upper-level capabilities on top of JNI. Could it be that some newly added hyperparameters in these encapsulations have special handling for input results, leading to inconsistent outcomes?
After communicating with the colleague who reported this issue, I learned that the hyperparameters set in their Python code were completely consistent with those set on the platform. A thorough review of the source code for XGBoostClassifier and XGBoostRegressor revealed that neither made any special handling of the output results.
This further ruled out the possibility of issues with hyperparameter encapsulation in XGBoost on Spark.
Once again, I checked the model input, this time focusing on whether there were any special values in the input, such as NaN, -1, or 0. Indeed, there were several occurrences of 0 in the input array; could this be related to missing value handling?
I quickly located the source code for both engines and discovered that their handling of missing values is indeed inconsistent!
Missing Value Handling in XGBoost4j
In XGBoost4j, the handling of missing values occurs during the construction of DMatrix, which by default sets 0.0f as the missing value:
/**
* create DMatrix from dense matrix
*
* @param data data values
* @param nrow number of rows
* @param ncol number of columns
* @throws XGBoostError native error
*/
public DMatrix(float[] data, int nrow, int ncol) throws XGBoostError {
long[] out = new long[1];
// 0.0f as missing value
XGBoostJNI.checkCall(XGBoostJNI.XGDMatrixCreateFromMat(data, nrow, ncol, 0.0f, out));
handle = out[0];
}
Missing Value Handling in XGBoost on Spark
In contrast, XGBoost on Spark treats NaN as the default missing value.
/**
* @return A tuple of the booster and the metrics used to build training summary
*/
@throws(classOf[XGBoostError])
def trainDistributed(
trainingDataIn: RDD[XGBLabeledPoint],
params: Map[String, Any],
round: Int,
nWorkers: Int,
obj: ObjectiveTrait = null,
eval: EvalTrait = null,
useExternalMemory: Boolean = false,
// NaN as missing value
missing: Float = Float.NaN,
hasGroup: Boolean = false): (Booster, Map[String, Array[Float]]) = {
//...
}
This means that when constructing the DMatrix in the local Java call, if no missing value is set, the default value of 0 is treated as a missing value. In contrast, in XGBoost on Spark, NaN is treated as the missing value. The reason for the inconsistent execution results between the Java engine and the XGBoost on Spark engine is due to the differing definitions of missing values!
By modifying the test code to set the missing value to NaN in the Java engine code, the execution result was 328.1694, which matched the platform’s computation result perfectly.
// A line in the test results, 41 columns
double[] input = new double[]{1, 2, 5, 0, 0, 6.666666666666667, 31.14, 29.28, 0, 1.303333, 2.8555, 2.37, 701, 463, 3.989, 3.85, 14400.5, 15.79, 11.45, 0.915, 7.05, 5.5, 0.023333, 0.0365, 0.0275, 0.123333, 0.4645, 0.12, 15.082, 14.48, 0, 31.8425, 29.1, 7.7325, 3, 5.88, 1.08, 0, 0, 0, 32];
float[] testInput = new float[input.length];
for(int i = 0, total = input.length; i < total; i++){
testInput[i] = new Double(input[i]).floatValue();
}
Booster booster = XGBoost.loadModel("${model}");
// One row, 41 columns
DMatrix testMat = new DMatrix(testInput, 1, 41, Float.NaN);
float[][] predicts = booster.predict(testMat);
Unstable Issues Introduced by Missing Values in XGBoost on Spark Source Code
However, the situation is not so simple. Spark ML also has hidden logic for handling missing values: SparseVector.
SparseVector and DenseVector are both used to represent a vector; the only difference is in their storage structure.
DenseVector is a standard vector storage that stores each value in order.
In contrast, SparseVector is a sparse representation used for data storage in scenarios where there are many zero values in the vector.
The storage method of SparseVector is to only record all non-zero values, ignoring all zero values. Specifically, it uses one array to record the positions of all non-zero values and another array to store the corresponding values. With these two arrays and the total length of the current vector, the original array can be restored.
Therefore, for a dataset with many zero values, SparseVector can significantly save storage space.
For a visual representation of SparseVector storage, see the image below:
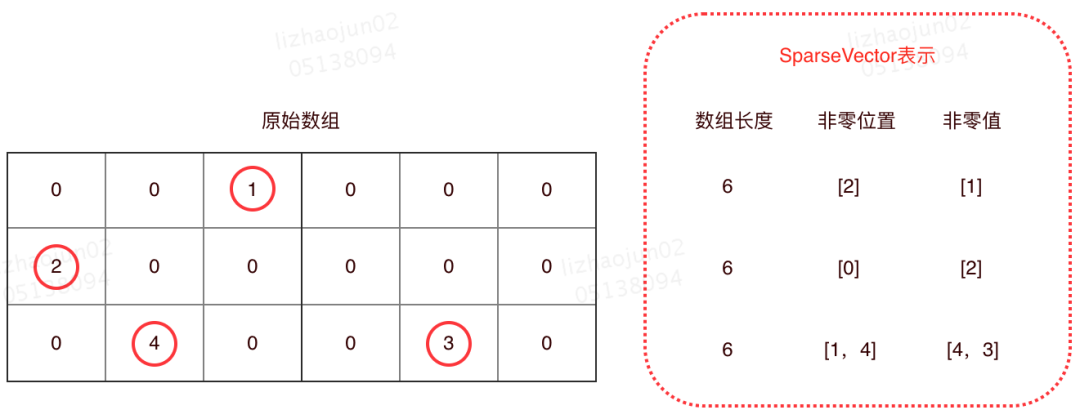
As shown in the image above, SparseVector does not save the parts of the array that are zero values; it only records the non-zero values. The following code is the implementation of VectorAssembler in Spark ML, which shows that if the value is 0, it is not recorded in SparseVector.
private[feature] def assemble(vv: Any*): Vector = {
val indices = ArrayBuilder.make[Int]
val values = ArrayBuilder.make[Double]
var cur = 0
vv.foreach {
case v: Double =>
// 0 is not saved
if (v != 0.0) {
indices += cur
values += v
}
cur += 1
case vec: Vector =>
vec.foreachActive { case (i, v) =>
// 0 is not saved
if (v != 0.0) {
indices += cur + i
values += v
}
}
cur += vec.size
case null =>
throw new SparkException("Values to assemble cannot be null.")
case o =>
throw new SparkException(s"$o of type ${o.getClass.getName} is not supported.")
}
Vectors.sparse(cur, indices.result(), values.result()).compressed
}
Values that do not occupy storage space can also be seen as a form of missing value. SparseVector, as the array storage format in Spark ML, is used by all algorithm components, including XGBoost on Spark. In fact, XGBoost on Spark does treat the zero values in the Sparse Vector as missing values:
val instances: RDD[XGBLabeledPoint] = dataset.select(
col($(featuresCol)),
col($(labelCol)).cast(FloatType),
baseMargin.cast(FloatType),
weight.cast(FloatType)
).rdd.map { case Row(features: Vector, label: Float, baseMargin: Float, weight: Float) =>
val (indices, values) = features match {
// SparseVector format, only non-zero values are used for XGBoost computation
case v: SparseVector => (v.indices, v.values.map(_.toFloat))
case v: DenseVector => (null, v.values.map(_.toFloat))
}
XGBLabeledPoint(label, indices, values, baseMargin = baseMargin, weight = weight)
}
Why does treating zero values in SparseVector as missing values introduce instability in XGBoost on Spark?
The key point is that Spark ML optimizes the storage of Vector types; it automatically selects whether to store them as SparseVector or DenseVector based on the contents of the Vector array. This means that for a Vector type field, the same column in Spark can have two storage formats: SparseVector and DenseVector. Furthermore, for a particular column in a dataset, both formats can coexist, with some rows stored as Sparse and others as Dense. The choice of which format to use is determined by the following code:
/**
* Returns a vector in either dense or sparse format, whichever uses less storage.
*/
@Since("2.0.0")
def compressed: Vector = {
val nnz = numNonzeros
// A dense vector needs 8 * size + 8 bytes, while a sparse vector needs 12 * nnz + 20 bytes.
if (1.5 * (nnz + 1.0) < size) {
toSparse
} else {
toDense
}
}
In the context of XGBoost on Spark, NaN is treated as the missing value by default. If a certain row in the dataset is stored as a DenseVector, the missing value for that row during execution is Float.NaN. However, if that row is stored as a SparseVector, since XGBoost on Spark only uses the non-zero values from the SparseVector, the missing values for that row become both Float.NaN and 0.
This means that for some rows in the dataset, the missing values are represented as Float.NaN and 0, while for others, they are represented solely as Float.NaN! In other words, in XGBoost on Spark, the value 0 can have two meanings simultaneously due to the underlying data storage structure, which is entirely determined by the dataset.
Because serving in production can only set one missing value, datasets selected in SparseVector format may lead to discrepancies between the computed results and the expected results during online serving.
Problem Resolution
I checked the latest source code of XGBoost on Spark, and the problem still hasn’t been resolved.
I promptly reported this issue to XGBoost on Spark and simultaneously modified our own XGBoost on Spark code.
val instances: RDD[XGBLabeledPoint] = dataset.select(
col($(featuresCol)),
col($(labelCol)).cast(FloatType),
baseMargin.cast(FloatType),
weight.cast(FloatType)
).rdd.map { case Row(features: Vector, label: Float, baseMargin: Float, weight: Float) =>
// Here we need to modify the return format of the original code
val values = features match {
// Convert SparseVector data to Dense
case v: SparseVector => v.toArray.map(_.toFloat)
case v: DenseVector => v.values.map(_.toFloat)
}
XGBLabeledPoint(label, null, values, baseMargin = baseMargin, weight = weight)
}
/**
* Converts a [[Vector]] to a data point with a dummy label.
*
* This is needed for constructing a [[ml.dmlc.xgboost4j.scala.DMatrix]]
* for prediction.
*/
def asXGB: XGBLabeledPoint = v match {
case v: DenseVector =>
XGBLabeledPoint(0.0f, null, v.values.map(_.toFloat))
case v: SparseVector =>
// Convert SparseVector data to Dense
XGBLabeledPoint(0.0f, null, v.toArray.map(_.toFloat))
}
The problem was resolved, and the model trained with the new code showed some improvement in evaluation metrics, which was a pleasant surprise. I hope this article can help those encountering missing value issues in XGBoost, and I welcome everyone to discuss and exchange ideas.
Author Introduction
Zhao Jun, Technical Expert in the Algorithm Platform Team of Meituan Delivery Division.———- END ———- Recruitment Information
The Algorithm Platform Team of Meituan Delivery Division is responsible for building Meituan’s one-stop large-scale machine learning platform, the Turing platform. It defines the model training and prediction process using a visual drag-and-drop approach, providing powerful model management, online model prediction, and feature service capabilities, as well as multi-dimensional AB testing support and online effect evaluation support. The team’s mission is to provide a unified, end-to-end, one-stop self-service platform for algorithm-related colleagues, helping them reduce algorithm development complexity and improve algorithm iteration efficiency.
We are currently recruiting senior R&D engineers/technical experts/direction leaders in fields such as data engineering, data development, algorithm engineering, and algorithm applications (machine learning platform/algorithm platform). Interested candidates are welcome to join us. Resumes can be sent to: [email protected] (Note: Meituan Delivery Division)