

There are many algorithms in machine learning, but today we will focus on one called XGBoost.
This tool is quite a big deal in the data science community, with many experts saying it is fast, accurate, and hassle-free.
But don’t be afraid, it may sound fancy, but it’s basically a tool that helps us find patterns in data.
What is XGBoost
To be honest, XGBoost is short for “Extreme Gradient Boosting”.
This name sounds intimidating, but it’s just an enhanced version of the gradient boosting algorithm.
For example, if we compare other algorithms to bicycles, XGBoost is like a sports car—fast and stable.
import xgboost as xgb<br/>from sklearn.datasets import load_boston<br/>from sklearn.model_selection import train_test_split
Loading the Boston Housing Price Data
boston = load_boston()<br/>X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target)
Friendly reminder: to install XGBoost, just use pip, don’t overthink it:pip install xgboost
What Makes XGBoost Great
When we say it’s great, it’s not just talk. This tool has some impressive features:
1. Extremely fast, capable of parallel computation using multi-core CPUs
2. High accuracy, with flexible model tuning
3. Built-in regularization to prevent overfitting
4. Can handle missing values, saving us trouble
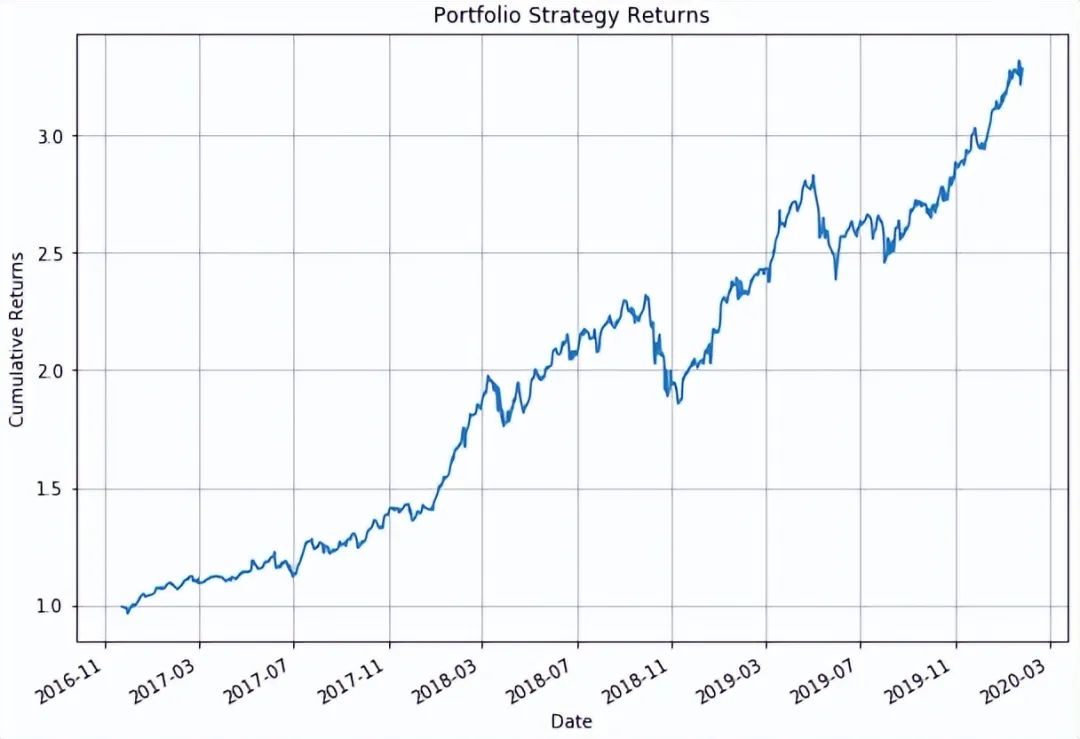
Creating a Model
model = xgb.XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100)
Training the Model
model.fit(X_train, y_train)
Practical Tips
When using XGBoost, there are a few key points to remember:
Custom Evaluation Metric
def custom_error(preds, dtrain):<br/> labels = dtrain.get_label()<br/> return 'custom-error', float(sum(labels != (preds > 0.5)))
Training with Evaluation
eval_set = [(X_test, y_test)]<br/>model.fit(X_train, y_train, eval_set=eval_set, eval_metric='rmse', early_stopping_rounds=10)
There are many ways to tune parameters, but remembering these common ones is enough:
learning_rate: the learning rate, smaller is more stable
max_depth: the depth of the tree, usually 3 to 6 is sufficient
n_estimators: the number of iterations, adjust as needed
Common Pitfalls
After many years of working with XGBoost, I’ve encountered several pitfalls, so here are some reminders:
1. Is your data too large for your memory?
Try using DMatrix format.
2. Is training too slow?
Try reducing max_depth and n_estimators.
3. Experiencing overfitting?
Increase min_child_weight or decrease learning_rate.
Handling Large Datasets
dtrain = xgb.DMatrix(X_train, label=y_train)<br/>dtest = xgb.DMatrix(X_test, label=y_test)
Remember, no matter how powerful XGBoost is, it is still just a tool; the key is how we use it. If we handle data well and have a good tuning strategy, the model performance will naturally be excellent. When writing code, practice often and don’t be timid; if something goes wrong, just start over.
After writing a lot of code, you’ll find that XGBoost is simple to use and powerful, which is why so many people love it.
Mastering this skill can really help solve practical problems.
Previous Articles
◆ PyImageSearch, an unbeatable image processing tool!
◆ Dlib-Python, a must-have tool for machine learning
◆ Unittest, an unbeatable Python testing tool!
Like and Share

LetMoney and Love Flow to You