Machine Learning Algorithms and Natural Language Processing(ML-NLP) is one of the largest natural language processing communities both domestically and internationally, gathering over 500,000 subscribers, covering NLP master’s and doctoral students, university teachers, and corporate researchers.The Vision of the Communityis to promote communication and progress between the academic and industrial sectors of natural language processing and enthusiasts worldwide.
Reprinted from | Zhihu
Author | multimodel侠
Original link | https://zhuanlan.zhihu.com/p/423271790
This article is for academic sharing only. If there is any infringement, please contact the backend for deletion.
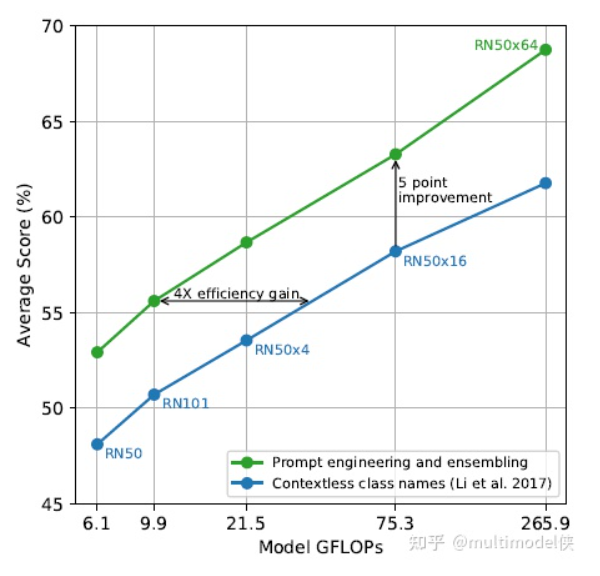
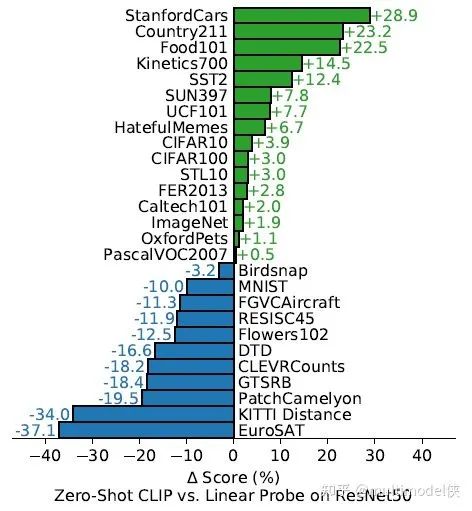
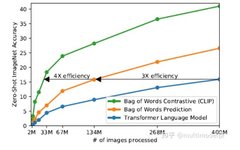
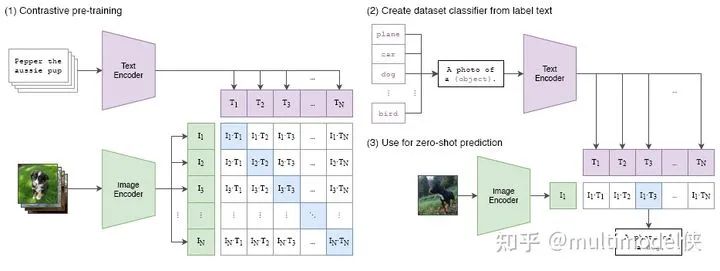
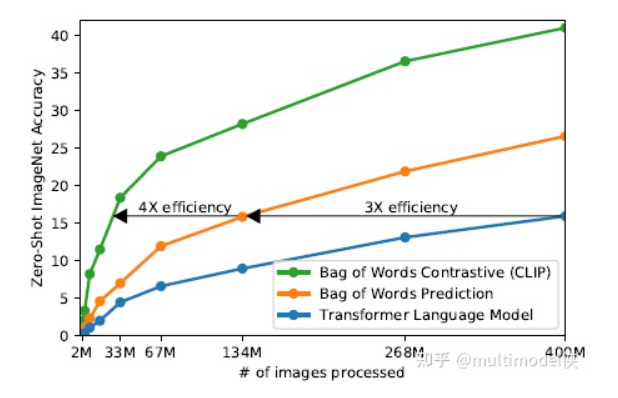
Recently, the fourth paradigm of prompt in NLP has become popular. It no longer transitions directly from pre-training to fine-tuning tasks, but uses prompts to transform fine-tuning tasks, making them closer to pre-training tasks. For example, using MLM to pre-train a language model, when subsequently performing a text sentiment classification task, instead of extracting the representation of the entire sentence for classification, a prompt (hint) is added at the end of the text, such as it is __, and then the blank needs to be filled in, which is equivalent to still being MLM. It seems cumbersome, but it is quite effective when there is sufficient pre-training data and insufficient fine-tuning data.As a mixed field, multimodal allows innovations from NLP and CV, which has led to the emergence of multimodal prompt articles. Today, we introduce CLIP: Learning Transferable Visual Models From Natural Language Supervision.The author first points out the motivation: current visual models can only predict within predefined object categories, and when encountering unannotated data during inference, the generalization performance is weak. Training on images with descriptions allows the model to gain broader supervision, thus achieving good performance in downstream few-shot and zero-shot learning. The author proposes CLIP: Contrastive Language-Image Pre-training. By using contrastive learning with text supervision for image representation, its performance in zero-shot learning can rival that of supervised models.Specific MethodsUsing language as supervisory information to train image representations is much easier than using crowd-sourced generated labels for image classification, as it allows for easy learning from a large amount of text available on the internet. Learning from natural language has another important advantage: it not only learns representations but also connects representations with language, enabling flexible zero-shot transfer.Create an effective large dataset by combining MSCOCO, VG, and YFCC100M, cleaning, generating a large number of image-text pairs, and also scraping a large amount of data from the internet to create a dataset called webimagetext.Pre-training method selection: First, use a pre-training task similar to image captioning, such as the blue line, which has very low learning efficiency and requires a lot of image data to achieve the same accuracy. The yellow line represents the basic training method, which is predicting the words of the descriptive text of the image. Both methods attempt to predict the exact words of the text attached to each image, but due to the variety, this is quite difficult. Contrastive learning can better learn representations by pairing the overall text with images as a target, further improving efficiency.Contrastive Learning: A batch contains N image-text pairs, calculating the similarity matrix, where the N pairs on the diagonal are positive samples, and the others are negative samples.Maximize the similarity of positive samples and minimize the similarity of negative samples, using a symmetric cross-entropy loss for optimization.Pseudocode: It is worth noting that when calculating cross-entropy, the label values are passed in, which are converted into one-hot vectors within the function.Model selection and training: Two types of image encoders are used: ResNet (which obtains the global representation of the entire image using attention pooling) and ViT. The text encoder uses a transformer, with masked self-attention to retain the ability initialized with a pre-trained language model.In zero-shot learning, taking classification tasks as an example, the prompt method converts the classification task into an image-text matching problem. That is, the label words and prompts form candidate sentences, and then the images are encoded into feature vectors, calculating similarities to find the most likely category.ExperimentsThe experiments first compare with other zero-shot learning models. Compared to Visual N-Grams, CLIP shows a significant improvement in accuracy across three image classification datasets.The author demonstrates the necessity of prompts through experiments. A word often has multiple meanings, and bringing the word into a specific contextual prompt can provide clearer meaning, aiding in classification. On the other hand, it can reduce the gap with pre-training tasks. Experiments have shown that using prompts is more effective.The blue line uses only the label text during (fine-tuning and) testing, while the green line uses prompts and ensemble. The prompt adds a hint to the label, and the ensemble refers to using multiple different contextual prompt statements simultaneously, generating multiple sentence embeddings for one label and then integrating them.Comparison of zero-shot learning CLIP with fully supervised training of ResNet50 across 27 classification datasets.This part of the experiments is relatively easy to understand. The original text on arXiv has about twenty pages just for the experimental section, but there is a simplified version on DBLP.About UsMachine Learning Algorithms and Natural Language Processing(ML-NLP) is a grassroots academic community jointly built by scholars in natural language processing both domestically and internationally. It has now developed into one of the largest natural language processing communities, gathering over 500,000 subscribers and includes well-known brands such as Ten Thousand Top Conference Exchange Group, AI Selection, AI Talent Exchange and AI Academic Exchange, aimed at promoting progress among the academic, industrial, and enthusiast communities of natural language processing.The community can provide an open exchange platform for practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.
Prompt—From CLIP to CoOp, New Paradigms of Visual-Language Models

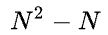 Maximize the similarity of positive samples and minimize the similarity of negative samples, using a symmetric cross-entropy loss for optimization.
Maximize the similarity of positive samples and minimize the similarity of negative samples, using a symmetric cross-entropy loss for optimization.